Artikel über die Automatisierung von Handelssystemen in MQL5
Lesen Sie Artikel über Handelssysteme, in denen unterschiedlichste Ideen vorgestellt sind. Sie erfahren, wie man statistische Methoden und Muster auf japanischen Kerzen verwendet, wie man Signale filtern kann und wofür man Semaphor-Indikatoren braucht.
Mit dem Meister MQL5 lernen Sie, wie man einen Roboter ohne Programmieren zur schnellen Überprüfung von Handelsideen erstellen kann sowie was genetische Algorithmen sind.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Entwicklung eins Replay Systems (Teil 49): Die Dinge werden kompliziert (I)
In diesem Artikel werden wir die Dinge ein wenig komplizierter machen. Anhand der in den vorangegangenen Artikeln gezeigten Vorgehensweise werden wir die Vorlagendatei öffnen, damit der Nutzer seine eigene Vorlage verwenden kann. Ich werde jedoch nach und nach Änderungen vornehmen, da ich auch den Indikator verfeinern werde, um die Belastung des MetaTrader 5 zu verringern.

Entwicklung eines Replay Systems (Teil 48): Das Konzept eines Dienstes verstehen
Wie wäre es, etwas Neues zu lernen? In diesem Artikel erfahren Sie, wie Sie Skripte in Dienste umwandeln können und warum dies sinnvoll ist.

Entwicklung eines Wiedergabesystems (Teil 47): Chart Trade Projekt (VI)
Schließlich beginnt unser Indikator Chart Trade mit dem EA zu interagieren, sodass die Informationen interaktiv übertragen werden können. Daher werden wir in diesem Artikel den Indikator verbessern, sodass er funktional genug ist, um zusammen mit jedem EA verwendet zu werden. Dadurch können wir auf den Indikator Chart Trade zugreifen und mit ihm arbeiten, als ob er tatsächlich mit einem EA verbunden wäre. Aber wir werden es auf eine viel interessantere Weise tun als bisher.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 36): Q-Learning mit Markov-Ketten
Reinforcement Learning ist neben dem überwachten und dem unüberwachten Lernen eine der drei Hauptrichtungen des maschinellen Lernens. Es geht also um die optimale Steuerung oder das Erlernen der besten langfristigen Strategie, die der Zielfunktion am besten entspricht. Vor diesem Hintergrund untersuchen wir die mögliche Rolle, die ein MLP für den Lernprozess eines von einem Assistenten zusammengestellten Expertenberaters spielt.

Erstellen eines integrierten MQL5-Telegram Expert Advisors (Teil 4): Modularisierung von Codefunktionen für bessere Wiederverwendbarkeit
In diesem Artikel wird der bestehende Code für das Senden von Nachrichten und Screenshots (screenshot des Terminals) von MQL5 zu Telegram refaktorisiert, indem er in wiederverwendbare, modulare Funktionen aufgeteilt wird. Dadurch wird der Prozess rationalisiert, was eine effizientere Ausführung und eine einfachere Codeverwaltung über mehrere Instanzen hinweg ermöglicht.

Beispiel einer Kausalitätsnetzwerkanalyse (CNA) und eines Vektor-Autoregressionsmodells zur Vorhersage von Marktereignissen
Dieser Artikel enthält eine umfassende Anleitung zur Implementierung eines ausgeklügelten Handelssystems unter Verwendung der Kausalitätsnetzwerkanalyse (Causality Network Analysis, CNA) und der Vektorautoregression (VAR) in MQL5. Es deckt den theoretischen Hintergrund dieser Methoden ab, bietet detaillierte Erklärungen der Schlüsselfunktionen im Handelsalgorithmus und enthält Beispielcode für die Implementierung.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 35): Support-Vektor-Regression
Die Support-Vektor-Regression ist eine idealistische Methode, um eine Funktion oder „Hyperebene“ zu finden, die die Beziehung zwischen zwei Datensätzen am besten beschreibt. Wir versuchen, dies bei der Zeitreihenprognose innerhalb der nutzerdefinierten Klassen des MQL5-Assistenten auszunutzen.
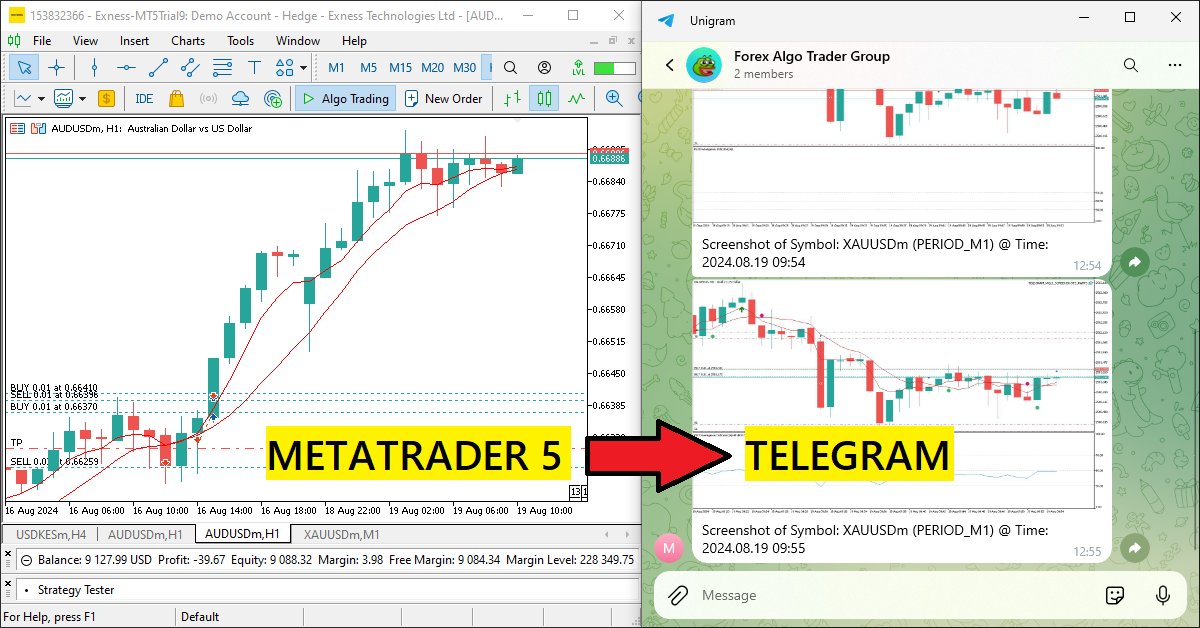
Erstellen eines integrierten MQL5-Telegram-Expertenberaters (Teil 3): Senden von Screenshots des Charts mit einer Legende von MQL5 an Telegram
In diesem Artikel erstellen wir einen MQL5 Expert Advisor, der Chart-Screenshots als Bilddaten kodiert und sie über HTTP-Anfragen an einen Telegram-Chat sendet. Durch die Integration von Fotocodierung und -übertragung erweitern wir das bestehende MQL5-Telegram-System um visuelle Handelseinblicke direkt in Telegram.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 34): Preiseinbettung mit einem unkonventionellen RBM
Restricted Boltzmann Machines sind eine Form von neuronalen Netzen, die Mitte der 1980er Jahre entwickelt wurde, als Rechenressourcen noch unerschwinglich waren. Zu Beginn stützte es sich auf Gibbs Sampling und kontrastive Divergenz, um die Dimensionalität zu reduzieren oder die verborgenen Wahrscheinlichkeiten/Eigenschaften über die eingegebenen Trainingsdatensätze zu erfassen. Wir untersuchen, wie Backpropagation eine ähnliche Leistung erbringen kann, wenn das RBM Preise für ein prognostizierendes Multi-Layer-Perceptron „embeds“ (einbettet).

Anwendung der Nash'schen Spieltheorie mit HMM-Filterung im Handel
Dieser Artikel befasst sich mit der Anwendung der Spieltheorie von John Nash, insbesondere des Gleichgewichts nach Nash, im Handel. Es wird erörtert, wie Händler Python-Skripte und MetaTrader 5 nutzen können, um Marktineffizienzen mit Hilfe der Nash-Prinzipien zu identifizieren und auszunutzen. Der Artikel enthält eine Schritt-für-Schritt-Anleitung zur Umsetzung dieser Strategien, einschließlich der Verwendung von Hidden-Markov-Modellen (HMM) und statistischer Analysen, um die Handelsleistung zu verbessern.

Automatisieren von Handelsstrategien mit Parabolic SAR Trend Strategy in MQL5: Erstellung eines effektiven Expertenberaters
In diesem Artikel werden wir die Handelsstrategien mit der Parabolic SAR Strategie in MQL5 automatisieren: Erstellung eines effektiven Expertenberaters. Der EA wird auf der Grundlage der vom Parabolic SAR-Indikator identifizierten Trends Trades durchführen.

Aufbau des Kerzenmodells Trend-Constraint (Teil 8): Entwicklung eines Expert Advisors (II)
Denken wir über einen unabhängigen Expert Advisor nach. Zuvor haben wir einen indikatorbasierten Expert Advisor besprochen, der auch mit einem unabhängigen Skript zum Zeichnen der Risiko- und Ertragsgeometrie zusammenarbeitet. Heute werden wir die Architektur eines MQL5 Expert Advisors besprechen, der alle Funktionen in einem Programm integriert.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 32): Regularisierung
Die Regularisierung ist eine Form der Bestrafung der Verlustfunktion im Verhältnis zur diskreten Gewichtung, die in den verschiedenen Schichten eines neuronalen Netzes angewendet wird. Wir sehen uns an, welche Bedeutung dies für einige der verschiedenen Regularisierungsformen in Testläufen mit einem vom Assistenten zusammengestellten Expert Advisor haben kann.

Integration von MQL5 in Datenverarbeitungspakete (Teil 2): Maschinelles Lernen und prädiktive Analytik
In unserer Serie über die Integration von MQL5 mit Datenverarbeitungspaketen befassen wir uns mit der leistungsstarken Kombination aus maschinellem Lernen und prädiktiver Analyse. Wir werden untersuchen, wie MQL5 nahtlos mit gängigen Bibliotheken für maschinelles Lernen verbunden werden kann, um anspruchsvolle Vorhersagemodelle für Finanzmärkte zu ermöglichen.

MQL5-Integration: Python
Python ist eine bekannte und beliebte Programmiersprache mit vielen Funktionen, insbesondere in den Bereichen Finanzen, Datenwissenschaft, künstliche Intelligenz und maschinelles Lernen. Python ist ein leistungsfähiges Werkzeug, das auch beim Handel nützlich sein kann. MQL5 ermöglicht es uns, diese leistungsstarke Sprache als Integration zu nutzen, um unsere Ziele effektiv zu erreichen. In diesem Artikel erfahren Sie, wie Sie Python in MQL5 integrieren und verwenden können, nachdem Sie einige grundlegende Informationen über Python gelernt haben.

Aufbau des Kerzenmodells Trend-Constraint (Teil 8): Entwicklung eines Expert Advisors (I)
In dieser Diskussion werden wir unseren ersten Expert Advisor in MQL5 erstellen, der auf dem Indikator basiert, den wir im vorherigen Artikel erstellt haben. Wir werden alle Funktionen abdecken, die erforderlich sind, um den Prozess zu automatisieren, einschließlich des Risikomanagements. Dies wird den Nutzern in hohem Maße zugute kommen, wenn sie von der manuellen Ausführung von Geschäften zu automatisierten Systemen übergehen.

Entwicklung eines Expertenberaters für mehrere Währungen (Teil 11): Automatisieren der Optimierung (erste Schritte)
Um einen guten EA zu erhalten, müssen wir mehrere gute Parametersätze von Handelsstrategie-Instanzen für ihn auswählen. Dies kann manuell erfolgen, indem die Optimierung für verschiedene Symbole durchgeführt und dann die besten Ergebnisse ausgewählt werden. Aber es ist besser, diese Arbeit an das Programm zu delegieren und sich produktiveren Tätigkeiten zu widmen.

Neuronale Netze leicht gemacht (Teil 88): Zeitreihen-Dense-Encoder (TiDE)
In dem Bestreben, möglichst genaue Prognosen zu erhalten, verkomplizieren die Forscher häufig die Prognosemodelle. Dies wiederum führt zu höheren Kosten für Training und Wartung der Modelle. Ist eine solche Erhöhung immer gerechtfertigt? In diesem Artikel wird ein Algorithmus vorgestellt, der die Einfachheit und Schnelligkeit linearer Modelle nutzt und Ergebnisse liefert, die mit den besten Modellen mit einer komplexeren Architektur vergleichbar sind.

Entwicklung eines Expertenberaters für mehrere Währungen (Teil 10): Erstellen von Objekten aus einer Zeichenkette
Der EA-Entwicklungsplan umfasst mehrere Stufen, wobei die Zwischenergebnisse in der Datenbank gespeichert werden. Sie können von dort nur als Zeichenketten oder Zahlen wieder abgerufen werden, nicht als Objekte. Wir brauchen also eine Möglichkeit, die gewünschten Objekte im EA anhand der aus der Datenbank gelesenen Strings neu zu erstellen.

Risikomanager für den algorithmischen Handel
Ziel dieses Artikels ist es, die Notwendigkeit des Einsatzes eines Risikomanagers zu beweisen und die Prinzipien der Risikokontrolle im algorithmischen Handel in einer eigenen Klasse zu implementieren, damit jeder die Wirksamkeit des Ansatzes der Risikostandardisierung im Intraday-Handel und bei Investitionen auf den Finanzmärkten überprüfen kann. In diesem Artikel werden wir eine Risikomanager-Klasse für den algorithmischen Handel erstellen. Dies ist eine logische Fortsetzung des vorangegangenen Artikels, in dem wir die Erstellung eines Risikomanagers für den manuellen Handel besprochen haben.

Entwicklung eines Replay Systems (Teil 46): Chart Trade Projekt (V)
Sind Sie es leid, Zeit mit der Suche nach genau der Datei zu verschwenden, die Ihre Anwendung zum Funktionieren braucht? Wie wäre es, alles in die ausführbare Datei aufzunehmen? Auf diese Weise müssen Sie nicht nach den Dingen suchen. Ich weiß, dass viele Menschen diese Form der Verteilung und Speicherung nutzen, aber es gibt einen viel geeigneteren Weg. Zumindest was die Verteilung von ausführbaren Dateien und deren Speicherung betrifft. Die hier vorgestellte Methode kann sehr nützlich sein, da Sie den MetaTrader 5 selbst als hervorragenden Assistenten verwenden können, ebenso wie MQL5. Außerdem ist es nicht so schwer zu verstehen.

MQL5-Assistent-Techniken, die Sie kennen sollten (Teil 31): Auswahl der Verlustfunktion
Die Verlustfunktion ist die wichtigste Kennzahl für Algorithmen des maschinellen Lernens, die eine Rückmeldung für den Trainingsprozess liefert, indem sie angibt, wie gut ein bestimmter Satz von Parametern im Vergleich zum beabsichtigten Ziel funktioniert. Wir untersuchen die verschiedenen Formate dieser Funktion in einer nutzerdefinierten MQL5-Assistenten-Klasse.

Erstellen eines integrierten MQL5-Telegram Expert Advisors (Teil 2): Senden von Signalen von MQL5 an Telegram
In diesem Artikel erstellen wir einen in MQL5-Telegram integrierten Expert Advisor, der Moving Average Crossover Signale an Telegram sendet. Wir erläutern den Prozess der Erzeugung von Handelssignalen aus gleitenden Durchschnittsübergängen, die Implementierung des erforderlichen Codes in MQL5 und die Sicherstellung der nahtlosen Integration. Das Ergebnis ist ein System, das Handelswarnungen in Echtzeit direkt an Ihren Telegram-Gruppenchat sendet.
MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 30): Spotlight auf Batch-Normalisierung beim maschinellen Lernen
Die Batch-Normalisierung ist die Vorverarbeitung von Daten, bevor sie in einen Algorithmus für maschinelles Lernen, z. B. ein neuronales Netz, eingespeist werden. Dies geschieht immer unter Berücksichtigung der Art der Aktivierung, die der Algorithmus verwenden soll. Wir untersuchen daher die verschiedenen Ansätze, die man mit Hilfe eines von einem Assistenten zusammengestellten Expert Advisors verfolgen kann, um die Vorteile dieses Ansatzes zu nutzen.

Erstellen eines integrierten MQL5-Telegram Expert Advisors (Teil 1): Senden von Nachrichten von MQL5 an Telegram
In diesem Artikel erstellen wir einen Expert Advisor (EA) in MQL5, um mit einem Bot Nachrichten an Telegram zu senden. Wir richten die erforderlichen Parameter ein, einschließlich des API-Tokens und der Chat-ID des Bots, und führen dann eine HTTP-POST-Anforderung aus, um die Nachrichten zu übermitteln. Später kümmern wir uns um die Beantwortung der Fragen, um eine erfolgreiche Zustellung zu gewährleisten, und beheben alle Probleme, die im Falle eines Fehlers auftreten. Dies stellt sicher, dass wir Nachrichten von MQL5 an Telegram über den erstellten Bot senden.

Implementierung des Deus EA: Automatisierter Handel mit RSI und gleitenden Durchschnitten in MQL5
Dieser Artikel beschreibt die Schritte zur Implementierung des Deus EA, der auf den Indikatoren RSI und Gleitender Durchschnitt zur Steuerung des automatisierten Handels basiert.

Datenwissenschaft und ML (Teil 28): Vorhersage mehrerer Futures für EURUSD mithilfe von KI
Bei vielen Modellen der künstlichen Intelligenz ist es üblich, einen einzigen Zukunftswert vorherzusagen. In diesem Artikel werden wir uns jedoch mit der leistungsstarken Technik der Verwendung von maschinellen Lernmodellen zur Vorhersage mehrerer zukünftiger Werte befassen. Dieser Ansatz, der als mehrstufige Prognose bekannt ist, ermöglicht es uns, nicht nur den Schlusskurs von morgen, sondern auch den von übermorgen und darüber hinaus vorherzusagen. Durch die Beherrschung mehrstufiger Prognosen können Händler und Datenwissenschaftler tiefere Einblicke gewinnen und fundiertere Entscheidungen treffen, was ihre Vorhersagefähigkeiten und strategische Planung erheblich verbessert.

Ihrer eigenes LLM in einen EA integrieren (Teil 5): Handelsstrategie mit LLMs(I) entwickeln und testen – Feinabstimmung
Angesichts der rasanten Entwicklung der künstlichen Intelligenz sind Sprachmodelle (language models, LLMs) heute ein wichtiger Bestandteil der künstlichen Intelligenz, sodass wir darüber nachdenken sollten, wie wir leistungsstarke LLMs in unseren algorithmischen Handel integrieren können. Für die meisten Menschen ist es schwierig, diese leistungsstarken Modelle auf ihre Bedürfnisse abzustimmen, sie lokal einzusetzen und sie dann auf den algorithmischen Handel anzuwenden. In dieser Artikelserie werden wir Schritt für Schritt vorgehen, um dieses Ziel zu erreichen.

Implementierung einer Handelsstrategie der Bollinger Bänder mit MQL5: Ein schrittweiser Leitfaden
Eine Schritt-für-Schritt-Anleitung zur Implementierung eines automatisierten Handelsalgorithmus in MQL5, der auf der Bollinger-Band-Handelsstrategie basiert. Ein detailliertes Tutorial zur Erstellung eines Expert Advisors, der für Händler nützlich sein kann.

Preisgesteuertes CGI-Modell: Erweiterte Datennachbearbeitung und Implementierung
In diesem Artikel befassen wir uns mit der Entwicklung eines vollständig anpassbaren Skripts für den Preisdatenexport mit MQL5, das einen neuen Fortschritt in der Simulation des CGI-Modells Price Man darstellt. Wir haben fortschrittliche Verfeinerungstechniken implementiert, um sicherzustellen, dass die Daten nutzerfreundlich und für Animationszwecke optimiert sind. Außerdem werden wir die Möglichkeiten von Blender 3D bei der effektiven Arbeit mit und der Visualisierung von Preisdaten kennenlernen und sein Potenzial für die Erstellung dynamischer und ansprechender Animationen demonstrieren.

Integration von MQL5 in Datenverarbeitungspakete (Teil 1): Fortgeschrittene Datenanalyse und statistische Verarbeitung
Die Integration ermöglicht einen nahtlosen Arbeitsablauf, bei dem Finanzrohdaten aus MQL5 in Datenverarbeitungspakete wie Jupyter Lab für erweiterte Analysen einschließlich statistischer Tests importiert werden können.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 29): Fortsetzung zu Lernraten mit MLPs
Zum Abschluss unserer Betrachtung der Empfindlichkeit der Lernrate für die Leistung von Expert Advisors untersuchen wir in erster Linie die adaptiven Lernraten. Diese Lernraten sollen für jeden Parameter in einer Schicht während des Trainingsprozesses angepasst werden, und so bewerten wir die potenziellen Vorteile gegenüber der erwarteten Leistungsgebühr.
Erstellen eines Dashboards in MQL5 für den RSI-Indikator von mehreren Symbolen und Zeitrahmen
In diesem Artikel entwickeln wir ein dynamisches RSI-Indikator-Dashboard in MQL5, das Händlern Echtzeit-RSI-Werte für verschiedene Symbole und Zeitrahmen anzeigt. Das Dashboard bietet interaktive Schaltflächen, Echtzeit-Updates und farbkodierte Indikatoren, die Händlern helfen, fundierte Entscheidungen zu treffen.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 28): GANs überarbeitet mit einer Anleitung zu Lernraten
Die Lernrate ist eine Schrittgröße in Richtung eines Trainingsziels in den Trainingsprozessen vieler maschineller Lernalgorithmen. Wir untersuchen die Auswirkungen, die die vielen Zeitpläne und Formate auf die Leistung eines Generative Adversarial Network haben können, eine Art neuronales Netz, das wir in einem früheren Artikel untersucht haben.

Vom Neuling zum Experten: Die wesentliche Reise durch den MQL5-Handel
Entfalten Sie Ihr Potenzial! Sie sind von Möglichkeiten umgeben. Entdecken Sie die 3 wichtigsten Geheimnisse, um Ihre MQL5-Reise in Gang zu bringen oder auf die nächste Stufe zu heben. Lassen Sie uns in die Diskussion über Tipps und Tricks für Anfänger und Profis gleichermaßen eintauchen.

Klassische Strategien neu interpretieren (Teil II): Bollinger-Bänder Ausbrüche
Dieser Artikel untersucht eine Handelsstrategie, die die lineare Diskriminanzanalyse (LDA) mit Bollinger-Bändern integriert und kategorische Zonenvorhersagen für strategische Markteinstiegssignale nutzt.

Selbstoptimierende Expert Advisors mit MQL5 und Python erstellen
In diesem Artikel werden wir erörtern, wie wir Expert Advisors erstellen können, die in der Lage sind, Handelsstrategien auf der Grundlage der vorherrschenden Marktbedingungen eigenständig auszuwählen und zu ändern. Wir werden etwas über Markov-Ketten lernen und wie sie algorithmischen Händler helfen können.
Aufbau des Kerzenmodells Trend-Constraint (Teil 7): Verfeinerung unseres Modells für die EA-Entwicklung
In diesem Artikel werden wir uns mit der detaillierten Vorbereitung unseres Indikators für die Entwicklung von Expert Advisor (EA) befassen. Unsere Diskussion wird weitere Verfeinerungen der aktuellen Version des Indikators umfassen, um seine Genauigkeit und Funktionsweise zu verbessern. Außerdem werden wir neue Funktionen einführen, die Ausstiegspunkte markieren und damit eine Einschränkung der Vorgängerversion beheben, die nur Einstiegspunkte kennzeichnete.

Neuronale Netze leicht gemacht (Teil 87): Zeitreihen-Patching
Die Vorhersage spielt eine wichtige Rolle in der Zeitreihenanalyse. Im neuen Artikel werden wir über die Vorteile des Zeitreihen-Patchings sprechen.

Entwicklung eines Expertenberaters für mehrere Währungen (Teil 9): Sammeln von Optimierungsergebnissen für einzelne Handelsstrategie-Instanzen
Schauen wir uns die wichtigsten Phasen der EA-Entwicklung an. Eine der ersten Aufgaben besteht darin, eine einzelne Instanz der entwickelten Handelsstrategie zu optimieren. Versuchen wir, alle notwendigen Informationen über die Testergebnisse während der Optimierung an einem Ort zu sammeln.