
神经网络: 智能交易系统自我优化

概论
在我们定义好我们的策略, 并在智能交易系统中将之实现之后, 我们会面对两个可令我们的努力付诸流水的问题。
- 最合适的输入值是什么?
- 这些值的可靠性能保持多久?何时我们需要进行再次优化?
是否有可能开发一款能够根据定义的间隔来优化开仓和平仓条件的智能交易系统?
如果我们以模块化的形式实现一个神经网络 (NN) 来分析历史并提供策略, 会发生什么?是否有可能令 EA 每月(每周, 每天或每小时) 进行神经网络优化, 然后继续其工作?因此, 开发一款自我优化 EA 的想法降临了。
这并非首次在交易社区中提及 "MQL 和神经网络" 的话题。然而, 大多情况是讨论如何降低使用外部神经网络来获取数据 (有时手工), 或是通过 МetaTrader 4/МetaTrader 5 的优化器来进行优化。最后, EA 的输入被替换为网络, 譬如, 就像 这篇 文章。
在这篇文章中, 我们不会描述交易机器人。代之, 我们将会开发并实现 (模块化) 一个 EA 布局, 以 MQL5 开发并使用 ALGLIB 库的多层感知器 (MLP) 来执行上述算法。之后, 神经网络将尝试解决两个数学任务, 其结果可轻易地采用不同算法来检验。这将有助于我们根据其内部结构分析 MLP 计划的方案和任务, 并通过简单地更改数据输入模块来获得实现 EA 的准则。此布局应可解决自我优化问题。
我们假定读者熟悉神经网络的一般理论, 包括它们的结构和组织形式, 层数, 每层的神经元数量, 连接和权重, 等等。任何情况下, 必要的信息均可在相关文章中找到。
1. 基本算法
- 创建一个神经网络。
- 准备输入 (及相应的输出), 下载数据到数组。
- 在指定范围内规范化数据 (通常, [0, 1] 或 [-1, 1])。
- 训练并优化神经网络。
- 计算网络预测, 并依据 EA 策略来应用它。
- 自我优化: 返回第二步并在 OnTimer() 函数里包含重复迭代过程。
机器人将根据用户指定的时间段和描述的算法执行定期优化。用户无需为它担心。步骤 5 不包括在重复处理中。即使在优化期间, EA 始终具有预测值。我们看看这是怎么回事。
2. ALGLIB 库
软件库已在 Sergey Bochkanov 的 公告板 和 ALGLIB 项目的网站上发布并讨论, http://www.alglib.net/, 它被描述为一个 跨平台的数值分析和数据处理软件库。它可与各种编程语言 (C++, C#, Pascal, VBA) 和操作系统 (Windows, Linux, Solaris) 兼容。ALGLIB 具有广泛的功能。它包括:
- 线性代数 (直接算法, EVD/SVD)
- 线性和非线性方程解向导
- 插值
- 优化
- 快速傅立叶变换
- 数值积分
- 线性和非线性平方
- 常微分方程
- 特殊函数
- 统计 (描述性统计, 假设检验)
- 数据分析 (分类/回归, 包括神经网络)
- 实现线性代数, 插值和其它高精度算术算法 (使用 MPFR)
CAlglib 类的静态函数可用于操纵软件库。这个类包含所有的库函数。
它提供了 testclasses.mq5 和 testinterfaces.mq5 测试脚本, 并伴有一个简单的 usealglib.mq5 演示脚本。同名的包含文件 (testclasses.mqh 和 testinterfaces.mqh) 用于启动测试用例。它们应被放置于 \MQL5\Scripts\Alglib\Testcases\。
在数百个库文件和函数中, 以下是我们感兴趣的:
| 软件包 |
描述 |
|---|---|
| alglib.mqh |
包含自定义函数的主要库文件包。 这些函数应当在操纵库文件时调用。 |
| dataanalysis.mqh | 数据分析类:
|
当下载库文件时, 文件发送到 MQL5\Include\Math\Alglib\。在程序代码中包含以下命令来使用它:
#include <Math\Alglib\alglib.mqh>
CAlglib 类函数适用于所提解决方案。
//--- 创建神经网络 static void MLPCreate0(const int nin,const int nout,CMultilayerPerceptronShell &network); static void MLPCreate1(const int nin,int nhid,const int nout,CMultilayerPerceptronShell &network); static void MLPCreate2(const int nin,const int nhid1,const int nhid2,const int nout,CMultilayerPerceptronShell &network); static void MLPCreateR0(const int nin,const int nout,double a,const double b,CMultilayerPerceptronShell &network); static void MLPCreateR1(const int nin,int nhid,const int nout,const double a,const double b,CMultilayerPerceptronShell &network); static void MLPCreateR2(const int nin,const int nhid1,const int nhid2,const int nout,const double a,const double b,CMultilayerPerceptronShell &network); static void MLPCreateC0(const int nin,const int nout,CMultilayerPerceptronShell &network); static void MLPCreateC1(const int nin,int nhid,const int nout,CMultilayerPerceptronShell &network); static void MLPCreateC2(const int nin,const int nhid1,const int nhid2,const int nout,CMultilayerPerceptronShell &network)
MLPCreate 函数创建一个带线性输出的神经网络。我们将在本文的示例中创建此网络类型。
MLPCreateR 函数创建一个输出范围在 [a, b] 区间的神经网络。
MLPCreateC 函数创建一个输出分类 "classes" (例如, 0 或 1; -1, 0 或 1) 的神经网络。
//--- 神经网络的属性和错误处理 static void MLPProperties(CMultilayerPerceptronShell &network,int &nin,int &nout,int &wcount); static int MLPGetLayersCount(CMultilayerPerceptronShell &network); static int MLPGetLayerSize(CMultilayerPerceptronShell &network,const int k); static void MLPGetInputScaling(CMultilayerPerceptronShell &network,const int i,double &mean,double &sigma); static void MLPGetOutputScaling(CMultilayerPerceptronShell &network,const int i,double &mean,double &sigma); static void MLPGetNeuronInfo(CMultilayerPerceptronShell &network,const int k,const int i,int &fkind,double &threshold); static double MLPGetWeight(CMultilayerPerceptronShell &network,const int k0,const int i0,const int k1,const int i1); static void MLPSetNeuronInfo(CMultilayerPerceptronShell &network,const int k,const int i,int fkind,double threshold); static void MLPSetWeight(CMultilayerPerceptronShell &network,const int k0,const int i0,const int k1,const int i1,const double w); static void MLPActivationFunction(const double net,const int k,double &f,double &df,double &d2f); static void MLPProcess(CMultilayerPerceptronShell &network,double &x[],double &y[]); static double MLPError(CMultilayerPerceptronShell &network,CMatrixDouble &xy,const int ssize); static double MLPRMSError(CMultilayerPerceptronShell &network,CMatrixDouble &xy,const int npoints);
//--- 训练神经网络 static void MLPTrainLM(CMultilayerPerceptronShell &network,CMatrixDouble &xy,const int npoints,const double decay,const int restarts,int &info,CMLPReportShell &rep); static void MLPTrainLBFGS(CMultilayerPerceptronShell &network,CMatrixDouble &xy,const int npoints,const double decay,const int restarts,const double wstep,int maxits,int &info,CMLPReportShell &rep);
这些函数可令您创建并优化包含两层至四层 (输入层, 输出层, 零层, 以及一或二隐藏层) 的神经网络。主要输入的名称不言自明:
- nin: 输入层神经元数量。
- nout: 输出层。
- nhid1: 隐藏层 1。
- nhid2: 隐藏层 2。
- network: CMultilayerPerceptronShell 类对象是启用神经元及其激活函数之间的连接和权重的定义。
- xy: CMatrixDouble 类对象是启用输入/输出数据以便执行训练和优化神经网络。
训练/优化的执行, 使用 Levenberg-Marquardt (MLPTrainLM()) 或具有 (MLPTrainLBFGS()) 规则的 L-BFGS 算法。如果网络包含超过 500 个连接/权重, 则使用后一个: 函数数据会因 "网络拥有数百个权重" 而发出警告。这些算法比之 NN 中常用的所谓 "反向传播" 更有效。软件库还提供了其它优化函数。如果您在用了述两个函数之后依然未能实现您的目标, 您可深入研究它们。
3. MQL 的实现
我们来定义每层的神经元数量作为外部输入。我们还应定义包含规范化参数的变量。
input int nNeuronEntra= 35; //输入层的神经元数量 input int nNeuronSal= 1; //输出层的神经元数量 input int nNeuronCapa1= 45; //隐藏层 1 的神经元数量 (不能 <1) input int nNeuronCapa2= 10; //隐藏层 2 的神经元数量 (不能 <1) input string intervEntrada= "0;1"; //输入规范化: 期望的最小值和最大值 (空= 无规范化) input string intervSalida= ""; //输出规范化: 期望的最小值和最大值 (空= 无规范化)
其它外部变量:
input int velaIniDesc= 15; input int historialEntrena= 1500;
它们帮助您指明柱线索引 (velaIniDesc), 从哪一个历史数据来训练网络, 以及上载的柱线数据总量 (historialEntrena)。
定义网络对象和 "arDatosAprende" 双精度数组对象作为全局开放变量。CMultilayerPerceptronShell *objRed;
CMatrixDouble arDatosAprende(0, 0);
"arDatosAprende" 包含用于网络训练的输入/输出数据字符串。这是一个二维动态双精度类型矩阵 (MQL5 只允许创建一维动态数组。创建多维数组时, 请务必定义除第一维以外的所有数组维度)。
主要算法的关键点 1-4 在 "gestionRed()" 函数里实现。
//---------------------------------- 创建并优化神经网络 -------------------------------------------------- bool gestionRed(CMultilayerPerceptronShell &objRed, string simb, bool normEntrada= true , bool normSalida= true, bool imprDatos= true, bool barajar= true) { double tasaAprende= 0.001; //网络训练比率 int ciclosEntren= 2; //训练循环次数 ResetLastError(); bool creada= creaRedNeuronal(objRed); //创建神经网络 if(creada) { preparaDatosEntra(objRed, simb, arDatosAprende); //在 arDatosAprende 里下载输入/输出数据 if(imprDatos) imprimeDatosEntra(simb, arDatosAprende); //显示数据以评估可信度 if(normEntrada || normSalida) normalizaDatosRed(objRed, arDatosAprende, normEntrada, normSalida); //输入/输出数据规范化选项 if(barajar) barajaDatosEntra(arDatosAprende, nNeuronEntra+nNeuronSal); //遍历数据数组字符串 errorMedioEntren= entrenaEvalRed(objRed, arDatosAprende, ciclosEntren, tasaAprende); //执行训练/优化 salvaRedFich(arObjRed[codS], "copiaSegurRed_"+simb); //保存网络至磁盘文件 } else infoError(GetLastError(), __FUNCTION__); return(_LastError==0); }
此处我们在 (creaRedNeuronal(objRed)) 函数里创建一个 NN; 然后我们使用 preparaDatosEntra() 函数下载数据至 "arDatosAprende"。显示的数据可用于 imprimeDatosEntra() 函数来评估可信度。若是输入和输出数据应规范化, 使用 normalizaDatosRed() 函数。此外, 若您打算在优化之前遍历整个数据数组字符串, 执行 barajaDatosEntra()。执行训练使用 entrenaEvalRed(), 并返回获取的优化误差。最后, 将网络保存至磁盘, 以便 潜在的 恢复需求, 而无需再次创建和优化。
在 gestionRed() 函数的开始处, 有两个变量 (tasaAprende 和 ciclosEntrena) 定义 NN 比率和训练循环。ALGLIB 警告它们通常被用在函数反射的值。不过, 当我采用两个提议的优化算法进行多次测试时, 这些变量值的更改对结果几乎没有影响。首先, 我们引入这些变量作为输入, 但之后 (因为它们无关紧要) 我把它们移入函数内部。您可自行决定是否应该将它们视为输入。
normalizaDatosRed() 函数用于规范化预定义范围内的 NN 输入数据, 前提是请求 NN 预测所需的实际数据也位于此范围之内。否则, 没必要规范化。此外, 如果训练数据已经被规范化, 则预测请求之前不用进行实际数据的规范化。
3.1 创建一个神经网络 (NN)
//--------------------------------- 创建网络 -------------------------------------- bool creaRedNeuronal(CMultilayerPerceptronShell &objRed) { bool creada= false; int nEntradas= 0, nSalidas= 0, nPesos= 0; if(nNeuronCapa1<1 && nNeuronCapa2<1) CAlglib::MLPCreate0(nNeuronEntra, nNeuronSal, objRed); //线性输出 else if(nNeuronCapa2<1) CAlglib::MLPCreate1(nNeuronEntra, nNeuronCapa1, nNeuronSal, objRed); //线性输出 else CAlglib::MLPCreate2(nNeuronEntra, nNeuronCapa1, nNeuronCapa2, nNeuronSal, objRed); //线性输出 creada= existeRed(objRed); if(!creada) Print("创建神经网络错误 ==> ", __FUNCTION__, " ", _LastError); else { CAlglib::MLPProperties(objRed, nEntradas, nSalidas, nPesos); Print("创建网络的层数 nº", propiedadRed(objRed, N_CAPAS)); Print("输入层的神经元 Nº ", nEntradas); Print("隐藏层 1 的神经元 Nº ", nNeuronCapa1); Print("隐藏层 2 的神经元 Nº ", nNeuronCapa2); Print("输出层的神经元 Nº ", nSalidas); Print("权重 Nº", nPesos); } return(creada); }
以上函数创建所需层数和神经元的 NN (nNeuronEntra, nNeuronCapa1, nNeuronCapa2, nNeuronSal), 之后使用函数检查所创建网络的有效性:
//--------------------------------- 存在网络 -------------------------------------------- bool existeRed(CMultilayerPerceptronShell &objRed) { bool resp= false; int nEntradas= 0, nSalidas= 0, nPesos= 0; CAlglib::MLPProperties(objRed, nEntradas, nSalidas, nPesos); resp= nEntradas>0 && nSalidas>0; return(resp); }
如果网络设置正确, 函数通知用户其有关参数, 所有函数为 ALGLIB 中 CAlglib 类的 MLPProperties()。
正如第 2 节中所提到的, ALGLIB 拥有其它函数可以创建用于分类的 NN (所获分级标签作为结果), 或是用于解决回归任务的网络 (获取的特殊数值作为结果)。
创建 NN 之后, 您可在 EA 的其它部分定义 "propiedadRed()" 函数来获取它的一些参数:
enum mis_PROPIEDADES_RED {N_CAPAS, N_NEURONAS, N_ENTRADAS, N_SALIDAS, N_PESOS}; //---------------------------------- 网络属性 ------------------------------------------- int propiedadRed(CMultilayerPerceptronShell &objRed, mis_PROPIEDADES_RED prop= N_CAPAS, int numCapa= 0) { //如果请求神经元数量 N_NEURONAS, 设置层索引 numCapa int resp= 0, numEntras= 0, numSals= 0, numPesos= 0; if(prop>N_NEURONAS) CAlglib::MLPProperties(objRed, numEntras, numSals, numPesos); switch(prop) { case N_CAPAS: resp= CAlglib::MLPGetLayersCount(objRed); break; case N_NEURONAS: resp= CAlglib::MLPGetLayerSize(objRed, numCapa); break; case N_ENTRADAS: resp= numEntras; break; case N_SALIDAS: resp= numSals; break; case N_PESOS: resp= numPesos; } return(resp); }
3.2 准备输入/输出数据
所提议的函数可以根据数据量和类型而改变。
//---------------------------------- 准备输入/输出数据 -------------------------------------------------- void preparaDatosEntra(CMultilayerPerceptronShell &objRed, string simb, CMatrixDouble &arDatos, bool normEntrada= true , bool normSalida= true) { int fin= 0, fila= 0, colum= 0, nEntras= propiedadRed(objRed, N_ENTRADAS), nSals= propiedadRed(objRed, N_SALIDAS); double valor= 0, arResp[]; arDatos.Resize(historialEntrena, nEntras+nSals); fin= velaIniDesc+historialEntrena; for(fila= velaIniDesc; fila<fin; fila++) { for(colum= 0; colum<NUM_INDIC; colum++) { valor= valorIndic(codS, fila, colum); arDatos[fila-1].Set(colum, valor); } calcEstrat(fila-nVelasPredic, arResp); for(colum= 0; colum<nSals; colum++) arDatos[fila-1].Set(colum+nEntras, arResp[colum]); } return; }
在此过程中, 我们将整个历史数据从 "velaIniDesc" 传递到 "velaIniDesc+historialEntrena", 并在每根柱线上接收策略中每个指标的值 (NUM_INDIC)。之后, 下载 CMatrixDouble 二维矩阵相应列的值。此外, 为每根柱线所对应的指定指标值输入策略结果 ("calcEstrat()")。变量 "nVelasPredic" 可以推断这些指标向前 n 根蜡烛的数值。"nVelasPredic" 通常作为外部参数定义。
这意味着每个 CMatrixDouble 类的 "arDatos" 数组字符串将包含与输入数量或策略中所用的指标值相匹配的列数, 以及由它定义的输出数据量。"arDatos" 是由 "historialEntrena" 值定义的字符串数量。
3.3打印输入/输出数据数组
如果您需要打印二维矩阵的内容以便检查输入和输出数据的精度, 使用 "imprimeDatosEntra()" 函数。
//---------------------------------- 显示输入/输出数据 -------------------------------------------------- void imprimeDatosEntra(string simb, CMatrixDouble &arDatos) { string encabeza= "indic1;indic2;indic3...;resultEstrat", //指标名称以 ";" 分隔 fichImprime= "dataEntrenaRed_"+simb+".csv"; bool entrar= false, copiado= false; int fila= 0, colum= 0, resultEstrat= -1, nBuff= 0, nFilas= arDatos.Size(), nColum= nNeuronEntra+nNeuronSal, puntFich= FileOpen(fichImprime, FILE_WRITE|FILE_CSV|FILE_COMMON); FileWrite(puntFich, encabeza); for(fila= 0; fila<nFilas; fila++) { linea= IntegerToString(fila)+";"+TimeToString(iTime(simb, PERIOD_CURRENT, velaIniDesc+fila), TIME_MINUTES)+";"; for(colum= 0; colum<nColum; colum++) linea= linea+DoubleToString(arDatos[fila][colum], 8)+(colum<(nColum-1)? ";": ""); FileWrite(puntFich, linea); } FileFlush(puntFich); FileClose(puntFich); Alert("下载文件= ", fichImprime); Alert("路径= ", TerminalInfoString(TERMINAL_COMMONDATA_PATH)+"\\Files"); return; }
函数将字符串以 ";" 分割后的每一列逐一传递到矩阵, 并在每一步创建 "línea" 字符串。然后将这些数据传递到使用 FileOpen() 函数创建的 a.csv 文件。我们不会在此停顿, 因为针对本文主题这是次要函数。您可以使用 Excel 来验证 .csv 文件。
3.4 在确定间隔内数据的规范化
通常, 在我们开始优化网络之前, 要考虑到输入数据应该适合所处的确定范围 (换言之, 已规范化)。若要实现这一点, 请使用以下函数将位于 CMatrixDouble 类中 "arDatos" 数组内的输入或输出数据 (根据您的选择) 进行规范化:
//------------------------------------ 规范化输入/输出数据------------------------------------- void normalizaDatosRed(CMultilayerPerceptronShell &objRed, CMatrixDouble &arDatos, bool normEntrada= true, bool normSalida= true) { int fila= 0, colum= 0, maxFila= arDatos.Size(), nEntradas= propiedadRed(objRed, N_ENTRADAS), nSalidas= propiedadRed(objRed, N_SALIDAS); double maxAbs= 0, minAbs= 0, maxRel= 0, minRel= 0, arMaxMinRelEntra[], arMaxMinRelSals[]; ushort valCaract= StringGetCharacter(";", 0); if(normEntrada) StringSplit(intervEntrada, valCaract, arMaxMinRelEntra); if(normSalida) StringSplit(intervSalida, valCaract, arMaxMinRelSals); for(colum= 0; normEntrada && colum<nEntradas; colum++) { maxAbs= arDatos[0][colum]; minAbs= arDatos[0][colum]; minRel= StringToDouble(arMaxMinRelEntra[0]); maxRel= StringToDouble(arMaxMinRelEntra[1]); for(fila= 0; fila<maxFila; fila++) //定义每个数据列的 maxAbs 和 minAbs { if(maxAbs<arDatos[fila][colum]) maxAbs= arDatos[fila][colum]; if(minAbs>arDatos[fila][colum]) minAbs= arDatos[fila][colum]; } for(fila= 0; fila<maxFila; fila++) //设置新的规范化值 arDatos[fila].Set(colum, normValor(arDatos[fila][colum], maxAbs, minAbs, maxRel, minRel)); } for(colum= nEntradas; normSalida && colum<(nEntradas+nSalidas); colum++) { maxAbs= arDatos[0][colum]; minAbs= arDatos[0][colum]; minRel= StringToDouble(arMaxMinRelSals[0]); maxRel= StringToDouble(arMaxMinRelSals[1]); for(fila= 0; fila<maxFila; fila++) { if(maxAbs<arDatos[fila][colum]) maxAbs= arDatos[fila][colum]; if(minAbs>arDatos[fila][colum]) minAbs= arDatos[fila][colum]; } minAbsSalida= minAbs; maxAbsSalida= maxAbs; for(fila= 0; fila<maxFila; fila++) arDatos[fila].Set(colum, normValor(arDatos[fila][colum], maxAbs, minAbs, maxRel, minRel)); } return; }
如果决定在确定间隔内规范化 NN 的训练输入数据, 则要执行重新迭代。确认用于请求 NN 预测的实际数据也在范围内。否则, 无需规范化。
记住, 作为输入, "intervEntrada" 和 "intervSalida" 被定义为字符串类型变量 (参阅 "MQL 的实现" 章节的开头)。它们也许如下所示, 例如 "0;1" 或 "-1;1", 即, 包括相关的最高/最低值。"StringSplit()" 函数将字符串传递到包含这些相关极值的数组。针对每列应如下完成:
- 定义绝对最高和最低 ("maxAbs" 和 "minAbs" 变量)。
- 在 "maxRel" 和 "minRel" 之间传递整个列的规范化数值: 参阅以下的 "normValor()" 函数。
- 使用 CMatrixDouble 类的 .set 方法在 "arDatos" 中设置新的规范化值。
//------------------------------------ 规范化函数 --------------------------------- double normValor(double valor, double maxAbs, double minAbs, double maxRel= 1, double minRel= -1) { double valorNorm= 0; if(maxAbs>minAbs) valorNorm= (valor-minAbs)*(maxRel-minRel))/(maxAbs-minAbs) + minRel; return(valorNorm); }
为了避免数据数组内潜在的数值继承, 我们可以任意改变 (迭代) 数组内部的字符串序列。为此, 应用 "barajaDatosEntra" 函数遍历整个 CMatrixDouble 数组字符串, 考虑每一行的数据位置为每个字符串定义一个新的目标字符串, 并使用冒泡方法 ("filaTmp" 变量) 移动数据。
//------------------------------------ 逐个遍历整个 输入/输出 字符串 ----------------------------------- void barajaDatosEntra(CMatrixDouble &arDatos, int nColum) { int fila= 0, colum= 0, filaDestino= 0, nFilas= arDatos.Size(); double filaTmp[]; ArrayResize(filaTmp, nColum); MathSrand(GetTickCount()); //重置随机后代序列 while(fila<nFilas) { filaDestino= randomEntero(0, nFilas-1); //以任意方式接收目标字符串 if(filaDestino!=fila) { for(colum= 0; colum<nColum; colum++) filaTmp[colum]= arDatos[filaDestino][colum]; for(colum= 0; colum<nColum; colum++) arDatos[filaDestino].Set(colum, arDatos[fila][colum]); for(colum= 0; colum<nColum; colum++) arDatos[fila].Set(colum, filaTmp[colum]); fila++; } } return; }
在重置随机 "MathSrand(GetTcikCount())" 后代序列之后, "randomEntero()" 函数负责将字符串移动到恰当的地方。
//---------------------------------- 随机移动 ------------------------------------------------------- int randomEntero(int minRel= 0, int maxRel= 1000) { int num= (int)MathRound(randomDouble((double)minRel, (double)maxRel)); return(num); }
3.6 神经网络的训练/优化
ALGLIB 允许使用网络配置算法, 与传统采用多层感知器的 "反向传播" 系统相比, 可显著降低训练和优化的工作量。正如我们所说, 我们要使用:
- Levenberg-Marquardt 算法 (MLPTrainLM()), 具有正则化和准确的计算, 或是
- L-BFGS 算法 (MLPTrainLBFGS()), 具有正则化。
第二种算法用于优化权重数超过 500 的网络。
//---------------------------------- 网络训练------------------------------------------- double entrenaEvalRed(CMultilayerPerceptronShell &objRed, CMatrixDouble &arDatosEntrena, int ciclosEntrena= 2, double tasaAprende= 0.001) { bool salir= false; double errorMedio= 0; string mens= "Entrenamiento Red"; int k= 0, i= 0, codResp= 0, historialEntrena= arDatosEntrena.Size(); CMLPReportShell infoEntren; ResetLastError(); datetime tmpIni= TimeLocal(); Alert("神经网络优化开始..."); Alert("依据所应用的历史数据等待若干分钟。"); Alert("...///..."); if(propiedadRed(objRed, N_PESOS)<500) CAlglib::MLPTrainLM(objRed, arDatosEntrena, historialEntrena, tasaAprende, ciclosEntrena, codResp, infoEntren); else CAlglib::MLPTrainLBFGS(objRed, arDatosEntrena, historialEntrena, tasaAprende, ciclosEntrena, 0.01, 0, codResp, infoEntren); if(codResp==2 || codResp==6) errorMedio= CAlglib::MLPRMSError(objRed, arDatosEntrena, historialEntrena); else Print("响应代码: ", codResp); datetime tmpFin= TimeLocal(); Alert("NGrad ", infoEntren.GetNGrad(), " NHess ", infoEntren.GetNHess(), " NCholesky ", infoEntren.GetNCholesky()); Alert("codResp ", codResp," 平均训练误差 "+DoubleToString(errorMedio, 8), " ciclosEntrena ", ciclosEntrena); Alert("tmpEntren ", DoubleToString(((double)(tmpFin-tmpIni))/60.0, 2), " min", "---> tmpIni ", TimeToString(tmpIni, _SEG), " tmpFin ", TimeToString(tmpFin, _SEG)); infoError(GetLastError(), __FUNCTION__); return(errorMedio); }
正如我们所见, 函数接收 "网络对象" 和已规范化的输入/输出数据矩阵作为输入。我们还要定义循环, 或训练期 ("ciclosEntrena"; 算法进行拟合搜索最小可能 "训练误差" 的次数); 文档中的建议值是 2。我们的测试没有迹象表明增加训练期的次数对结果有所改进。 我们还提及了 "训练比率" ("tasaAprende") 参数。
我们在函数的开头定义 "infoEntren" 对象 (CMLPReportShell 类), 它将收集训练结果数据。此后, 我们将使用 GetNGrad() 和 GetNCholesky() 方法来得到它。平均训练误差 (所有输出数据的均方差, 相对于算法处理后得到的输出数据) 使用 "MLPRMSError()" 函数获得。此外, 通知用户优化所花费的时间。变量 tmpIni 和 tmpFin 用来保存初始和结束时间。
这些优化函数返回的错误代码 ("codResp"), 取自一下数值:
- -2 如果训练样本的输出数据数量超过输出层神经元数量。
- -1 如果某些函数输入非法。
- 2 意味着执行正确。误差值小于停止标准 ("MLPTrainLM()")。
- 6 与 "MLPTrainLBFGS()" 函数相同。
因此, 执行正确时, 将根据优化网络的权重数量返回 2 或 6。
这些算法即便改变配置并重复训练循环 ("ciclosEntrena" 变量) 对于所获误差几乎没有影响, 不像 "反向传播" 算法那样重复训练能明显改变所获精度。由 35, 45, 10 和 2 个神经元组成的 4 层网络, 输入矩阵含 2000 个字符串, 采用所提函数可在 4-6 分钟内 (I5, 4 核, 内存 8 GB) 完成优化, 误差大约在 2-4 百万分之一 (4x10^-5)。
3.7将网络保存在文本文件或从中恢复
在这一刻, 我们已经创建了 NN, 准备好了输入/输出数据并执行了网络训练。出于安全原因, 应将网络保存到磁盘以避免 EA 操作期间发生意外错误。为此, 我们应该使用 ALGLIB 提供的函数来接收网络特征和内部值 (层数和每层的神经元数量, 权重, 等等), 并将这些数据写入位于磁盘中的文本文件。
//-------------------------------- 保存网络至磁盘 ------------------------------------------------- bool salvaRedFich(CMultilayerPerceptronShell &objRed, string nombArch= "") { bool redSalvada= false; int k= 0, i= 0, j= 0, numCapas= 0, arNeurCapa[], neurCapa1= 1, funcTipo= 0, puntFichRed= 9999; double umbral= 0, peso= 0, media= 0, sigma= 0; if(nombArch=="") nombArch= "copiaSegurRed"; nombArch= nombArch+".red"; FileDelete(nombArch, FILE_COMMON); ResetLastError(); puntFichRed= FileOpen(nombArch, FILE_WRITE|FILE_BIN|FILE_COMMON); redSalvada= puntFichRed!=INVALID_HANDLE; if(redSalvada) { numCapas= CAlglib::MLPGetLayersCount(objRed); redSalvada= redSalvada && FileWriteDouble(puntFichRed, numCapas)>0; ArrayResize(arNeurCapa, numCapas); for(k= 0; redSalvada && k<numCapas; k++) { arNeurCapa[k]= CAlglib::MLPGetLayerSize(objRed, k); redSalvada= redSalvada && FileWriteDouble(puntFichRed, arNeurCapa[k])>0; } for(k= 0; redSalvada && k<numCapas; k++) { for(i= 0; redSalvada && i<arNeurCapa[k]; i++) { if(k==0) { CAlglib::MLPGetInputScaling(objRed, i, media, sigma); FileWriteDouble(puntFichRed, media); FileWriteDouble(puntFichRed, sigma); } else if(k==numCapas-1) { CAlglib::MLPGetOutputScaling(objRed, i, media, sigma); FileWriteDouble(puntFichRed, media); FileWriteDouble(puntFichRed, sigma); } CAlglib::MLPGetNeuronInfo(objRed, k, i, funcTipo, umbral); FileWriteDouble(puntFichRed, funcTipo); FileWriteDouble(puntFichRed, umbral); for(j= 0; redSalvada && k<(numCapas-1) && j<arNeurCapa[k+1]; j++) { peso= CAlglib::MLPGetWeight(objRed, k, i, k+1, j); redSalvada= redSalvada && FileWriteDouble(puntFichRed, peso)>0; } } } FileClose(puntFichRed); } if(!redSalvada) infoError(_LastError, __FUNCTION__); return(redSalvada); }
正如我们看到的第六个代码字符串, 将 .red 扩展名分配给文件, 以简化将来的搜索和检查。我花了几个小时调试这个函数, 它开始工作了!
如果 EA 因事件而停止后需要继续工作, 我们使用与上述功能相反的函数从磁盘上的文件中恢复网络。此函数创建网络对象, 并从我们存储 NN 的文本文件中读取数据来填充它。
//-------------------------------- 从磁盘恢复网络 ------------------------------------------------- bool recuperaRedFich(CMultilayerPerceptronShell &objRed, string nombArch= "") { bool exito= false; int k= 0, i= 0, j= 0, nEntradas= 0, nSalidas= 0, nPesos= 0, numCapas= 0, arNeurCapa[], funcTipo= 0, puntFichRed= 9999; double umbral= 0, peso= 0, media= 0, sigma= 0; if(nombArch=="") nombArch= "copiaSegurRed"; nombArch= nombArch+".red"; puntFichRed= FileOpen(nombArch, FILE_READ|FILE_BIN|FILE_COMMON); exito= puntFichRed!=INVALID_HANDLE; if(exito) { numCapas= (int)FileReadDouble(puntFichRed); ArrayResize(arNeurCapa, numCapas); for(k= 0; k<numCapas; k++) arNeurCapa[k]= (int)FileReadDouble(puntFichRed); if(numCapas==2) CAlglib::MLPCreate0(nNeuronEntra, nNeuronSal, objRed); else if(numCapas==3) CAlglib::MLPCreate1(nNeuronEntra, nNeuronCapa1, nNeuronSal, objRed); else if(numCapas==4) CAlglib::MLPCreate2(nNeuronEntra, nNeuronCapa1, nNeuronCapa2, nNeuronSal, objRed); exito= existeRed(arObjRed[0]); if(!exito) Print("神经网络生成错误 ==> ", __FUNCTION__, " ", _LastError); else { CAlglib::MLPProperties(objRed, nEntradas, nSalidas, nPesos); Print("恢复网络层数 nº", propiedadRed(objRed, N_CAPAS)); Print("输入层的神经元 Nº ", nEntradas); Print("隐藏层 1 的神经元 Nº ", nNeuronCapa1); Print("隐藏层 2 的神经元 Nº ", nNeuronCapa2); Print("输出层的神经元 Nº ", nSalidas); Print("权重 Nº", nPesos); for(k= 0; k<numCapas; k++) { for(i= 0; i<arNeurCapa[k]; i++) { if(k==0) { media= FileReadDouble(puntFichRed); sigma= FileReadDouble(puntFichRed); CAlglib::MLPSetInputScaling(objRed, i, media, sigma); } else if(k==numCapas-1) { media= FileReadDouble(puntFichRed); sigma= FileReadDouble(puntFichRed); CAlglib::MLPSetOutputScaling(objRed, i, media, sigma); } funcTipo= (int)FileReadDouble(puntFichRed); umbral= FileReadDouble(puntFichRed); CAlglib::MLPSetNeuronInfo(objRed, k, i, funcTipo, umbral); for(j= 0; k<(numCapas-1) && j<arNeurCapa[k+1]; j++) { peso= FileReadDouble(puntFichRed); CAlglib::MLPSetWeight(objRed, k, i, k+1, j, peso); } } } } } FileClose(puntFichRed); return(exito); }
下载数据时, 调用 "respuestaRed()" 函数获取网络预测:
//--------------------------------------- 请求网络响应 --------------------------------- double respuestaRed(CMultilayerPerceptronShell &ObjRed, double &arEntradas[], double &arSalidas[], bool desnorm= false) { double resp= 0, nNeuron= 0; CAlglib::MLPProcess(ObjRed, arEntradas, arSalidas); if(desnorm) //如果输出数据规范化应改变 { nNeuron= ArraySize(arSalidas); for(int k= 0; k<nNeuron; k++) arSalidas[k]= desNormValor(arSalidas[k], maxAbsSalida, minAbsSalida, arMaxMinRelSals[1], arMaxMinRelSals[0]); } resp= arSalidas[0]; return(resp); }
此函数假定能够改变应用于训练矩阵中输出数据的归一化。
4. 自我优化
在 EA 对神经网络优化之后 (以及用于 EA 的输入), 在策略测试器里运行期间不会进行优化, 在第一节描述过的基本算法会重复。
此外, 我们有一个重要的任务: 在涉及大量计算资源的 NN 优化期间, EA 应能持续监视行情且不能失去控制。
我们来设置 mis_PLAZO_OPTIM 枚举类型, 描述用户可以选择的时间间隔 (每天, 有选择地或在周末) 来重复基本算法。我们还应设置另一个枚举, 允许用户决定 EA 是作为网络 "优化器" 还是策略 "执行器"。
enum mis_PLAZO_OPTIM {_DIARIO, _DIA_ALTERNO, _FIN_SEMANA}; enum mis_TIPO_EAred {_OPTIMIZA, _EJECUTA};
您也许还记得, МetaTrader 5 允许每个打开图表上的 EA 同时执行。因此, 我们在第一个图表上以执行模式启动 EA, 并在第二个图表上以优化模式运行它。在第一个图表上, EA 管理策略, 而第二个图表上只负责优化神经网络。因此, 解决了第二个所述问题。在第一个图表上, EA "使用" 的神经网络是从 "优化器" 模式每次生成的网络优化数据文本文件中 "读取" 的。
我们已注意到, 优化测试大约花费 4-6 分钟的计算时间。这种方法将处理所需时间略微增加到 8-15 分钟, 具体数值要取决于亚洲或欧洲市场活跃时间, 但策略管理从来不会停止。
为了达成这一点, 我们应该定义以下输入。
input mis_TIPO_EAred tipoEAred = _OPTIMIZA; //执行任务类型 input mis_PLAZO_OPTIM plazoOptim = _DIARIO; //网络优化的时间间隔 input int horaOptim = 3; //网络优化的本地时间
"horaOptim" 参数保存本地优化时间。时间应与较低或零市场活动时段相对应: 例如, 在欧洲, 应该是清晨 (省缺值为 03:00 h) 或周末。如果您打算每次启动 EA 时, 无需等待定义的时间和日期即刻执行优化, 请指定如下:
input bool optimInicio = true; //当 EA 启动时优化神经网络
为了定义网络是否考虑优化 ("优化器" 模式), 以及定义最后的网络文件读取时间 ("致动器" 模式), 我们应该定义以下开放变量:
double fechaUltLectura; bool reOptimizada= false;
为了解决第一个问题, 在 OnTimer() 函数中设置指定的方法处理块, 通过OnInit() 中的EventSetTimer(tmp) 开启, 它将根据 "tmp" 周期执行, 至少每小时一次。因此, 每隔 tmp 秒, "优化器" EA 检查网络是否应重新优化, 而 "致动器" EA 检查是否应该因 "优化器" 更新而再次读取网络文件。
/---------------------------------- 定时器 -------------------------------------- void OnTimer() { bool existe= false; string fichRed= ""; if(tipoEAred==_OPTIMIZA) //EA 工作于 "优化器" 模式 { bool optimizar= false; int codS= 0, hora= infoFechaHora(TimeLocal(), _HORA); //接收完整的当前时间 if(!redOptimizada) optimizar= horaOptim==hora && permReoptimDia(); fichRed= "copiaSegurRed_"+Symbol()+".red"; //定义神经网络文件名 existe= buscaFich(fichRed, "*.red"); //搜索神经网络文件保存的磁盘位置 if(!existe || optimizar) redOptimizada= gestionRed(objRed, simb, intervEntrada!="", intervSalida!="", imprDatosEntrena, barajaDatos); if(hora>(horaOptim+6)) redOptimizada= false; //评估时间 6 个小时以上, 实际优化的网络应认定过时 guardaVarGlobal(redOptimizada); //在磁盘上保存 "reoptimizada" (重新优化) 的值 } else if(tipoEAred==_EJECUTA) //EA 工作于 "致动器" 模式 { datetime fechaUltOpt= 0; fichRed= "copiaSegurRed_"+Symbol()+".red"; //定义神经网络文件名 existe= buscaFich(fichRed, "*.red"); //搜索神经网络文件保存的磁盘位置 if(existe) { fechaUltOpt= fechaModifFich(0, fichRed); //定义最后优化日期 (网络文件修改) if(fechaUltOpt>fechaUltLectura) //是否优化日期晚于最后一次读取 { recuperaRedFich(objRed, fichRed); //读取并生成新的神经网络 fechaUltLectura= (double)TimeCurrent(); guardaVarGlobal(fechaUltLectura); //在磁盘上保存新的读取日期 Print("Network restored after optimization... "+simb); //在屏幕上显示消息 } } else Alert("tipoEAred==_EJECUTA --> 神经网络文件未发现: "+fichRed+".red"); } return; }
以下紧跟的是未注明的额外函数:
//--------------------------------- 启用重新优化 --------------------------------- bool permReoptimDia() { int diaSemana= infoFechaHora(TimeLocal(), _DSEM); bool permiso= (plazoOptim==_DIARIO && diaSemana!=6 && diaSemana!=0) || //优化 [从周二到周六的每天] (plazoOptim==_DIA_ALTERNO && diaSemana%2==1) || //优化 [周二, 周四和周六] (plazoOptim==_FIN_SEMANA && diaSemana==5); //优化 [周六] return(permiso); } //-------------------------------------- 搜索文件 -------------------------------------------- bool buscaFich(string fichBusca, string filtro= "*.*", int carpeta= FILE_COMMON) { bool existe= false; string fichActual= ""; long puntBusca= FileFindFirst(filtro, fichActual, carpeta); if(puntBusca!=INVALID_HANDLE) { ResetLastError(); while(!existe) { FileFindNext(puntBusca, fichActual); existe= fichActual==fichBusca; } FileFindClose(puntBusca); } else Print("文件未发现!"); infoError(_LastError, __FUNCTION__); return(existe);
此算法目前用于测试 EA, 可令我们管理整个策略。每晚, 从凌晨 3:00 点钟。(本地时间) 网络依据 前 3 个月的一小时数据重新优化: 输入层 35 神经元, 第一个隐藏层 45 个, 第二个隐藏层 8 个, 以及输出层 2 个; 执行优化需要 35-45 分钟。
5. 任务 1: 二进制 - 十进制转换器
为了检查系统, 我们应解决已知解决方案的任务 (有适当的算法), 并与神经网络提供的进行比较。我们来创建二进制 - 十进制转换器。以下脚本可供测试:
#property script_show_confirm #property script_show_inputs #define FUNC_CAPA_OCULTA 1 #define FUNC_SALIDA -5 //1= 双曲正切; 2= e^(-x^2); 3= x>=0 raizC(1+x^2) x<0 e^x; 4= S 形函数; //5= 二项式 x>0.5?1: 0; -5= 线性函数 #include <Math\Alglib\alglib.mqh> enum mis_PROPIEDADES_RED {N_CAPAS, N_NEURONAS, N_ENTRADAS, N_SALIDAS, N_PESOS}; //--------------------------------- 输入 --------------------- sinput int nNeuronEntra= 10; //输入层神经元数量 //2^8= 256 2^9= 512; 2^10= 1024; 2^12= 4096; 2^14= 16384 sinput int nNeuronCapa1= 0; //第一个隐藏层的神经元数量 (不能 <1) sinput int nNeuronCapa2= 0; //第二个隐藏层的神经元数量 (不能 <1) //2^8= 256 2^9= 512; 2^10= 1024; 2^12= 4096; 2^14= 16384 sinput int nNeuronSal= 1; //输出层的神经元数量 sinput int historialEntrena= 800; //训练历史 sinput int historialEvalua= 200; //评估历史 sinput int ciclosEntrena= 2; //训练循环 sinput double tasaAprende= 0.001; //网络训练级别 sinput string intervEntrada= ""; //输入规范化: 期望的最小值和最大值 max (空= 无需优化) sinput string intervSalida= ""; //输出优化: 期望最小值和最大值 (空= 无需优化) sinput bool imprEntrena= true; //显示训练/评估数据 // ------------------------------ 全局变量 ----------------------------- int puntFichTexto= 0; ulong contFlush= 0; CMultilayerPerceptronShell redNeuronal; CMatrixDouble arDatosAprende(0, 0); CMatrixDouble arDatosEval(0, 0); double minAbsSalida= 0, maxAbsSalida= 0; string nombreEA= "ScriptBinDec"; //+------------------------------------------------------------------+ void OnStart() //二进制 - 十进制转换器 { string mensIni= "脚本转换器 二进制 - 十进制", mens= "", cadNumBin= "", cadNumRed= ""; int contAciertos= 0, arNumBin[], inicio= historialEntrena+1, fin= historialEntrena+historialEvalua; double arSalRed[], arNumEntra[], salida= 0, umbral= 0, peso= 0; double errorMedioEntren= 0; bool normEntrada= intervEntrada!="", normSalida= intervSalida!="", correcto= false, creada= creaRedNeuronal(redNeuronal); if(creada) { iniFichImprime(puntFichTexto, nombreEA+"-infRN", ".csv",mensIni); preparaDatosEntra(redNeuronal, arDatosAprende, intervEntrada!="", intervSalida!=""); normalizaDatosRed(redNeuronal, arDatosAprende, normEntrada, normSalida); errorMedioEntren= entrenaEvalRed(redNeuronal, arDatosAprende); escrTexto("-------------------------", puntFichTexto); escrTexto("RESPUESTA RED------------", puntFichTexto); escrTexto("-------------------------", puntFichTexto); escrTexto("numBinEntra;numDecSalidaRed;correcto", puntFichTexto); for(int k= inicio; k<=fin; k++) { cadNumBin= dec_A_baseNumerica(k, arNumBin, 2, nNeuronEntra); ArrayCopy(arNumEntra, arNumBin); salida= respuestaRed(redNeuronal, arNumEntra, arSalRed); salida= MathRound(salida); correcto= k==(int)salida; escrTexto(cadNumBin+";"+IntegerToString((int)salida)+";"+correcto, puntFichTexto); cadNumRed= ""; } } deIniFichImprime(puntFichTexto); return; }
在创建 NN 之后, 我们应该用前 800 个自然数的二进制形式 (10 个字符, 10 个输入神经元和 1 个输出神经元) 来训练它。之后, 我们应该将接下来的 200 个自然数转换为二进制形式 (从 801 到 1000 的二进制形式从), 并将实际结果与 NN 预测的结果进行比较。例如, 如果我们将 1100110100 设置为网络 (820 的二进制形式; 10 个字符, 10 个输入神经元), 则网络应接收 820 或接近它的一些其它数字。上述的 For 方法负责接收这 200 个数相关的网络预测, 并将期望结果与评估比较。
以指定参数 (NN 没有隐藏层, 10 个输入神经元和 1 个输出神经元) 执行脚本后, 我们得到了一个优异的结果。生成的 ScriptBinDec-infRN.csv 文件位于 Terminal\Common\Files 目录, 为我们提供了以下数据:
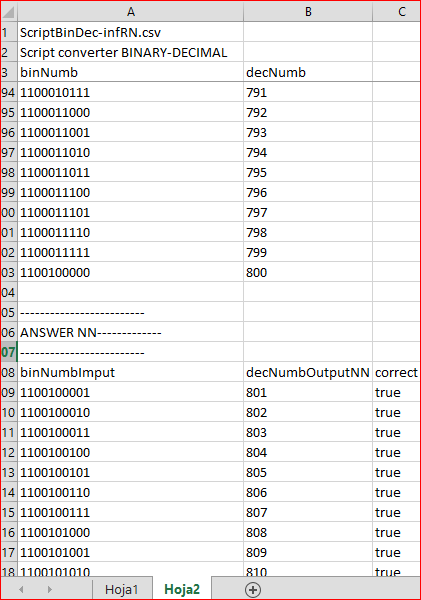
正如我们所见, 脚本以二进制 (输入) 和十进制 (输出) 形式打印出高达 800 个训练矩阵。NN 已经过训练, 我们打印出从 801 开始的答案。第三列包括 'true'。这是预期和实际结果之间的比较结果。正如所述, 这是一个优秀的结果。
不过, 如果我们将 NN 结构定义为 "10 个输入神经元, 第一隐藏层 20 个神经元, 第二隐藏层 8 个神经元, 1 个输出神经元", 我们获得以下:
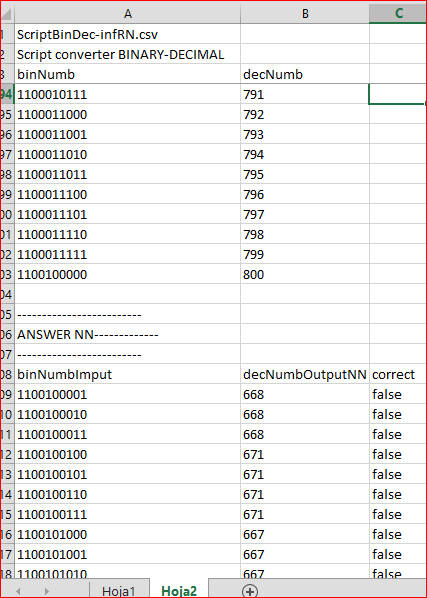
这是一个不可接受的结果!这里我们要面对处理神经网络时的一个严重问题: 最合适的内部配置 (层数, 神经元和激活函数) 是什么?这个问题只能通过扎实的经验来解决, 用户需经过数千次的测试并阅读相应的文章, 例如 "机器学习模型的评估及变量的选择"。此外, 我们还在 快速挖掘 统计分析软件里应用了训练矩阵数据, 以便在用 MQL5 处理之前发现最有效率的结构。
6. 任务 2: 质数检测器
我们来研究一个类似的任务。这次, NN 将定义它是否为质数。训练矩阵将包含 10 列, 其中高达 800 的自然数均变换为 10 个字符的二进制形式, 一列指示它是 ("1") 或不是 ("0") 素数。换言之, 我们将有 800 行和 11 列。接下来, 我们要让 NN 分析接下来 200 个自然数 (从 801 到 1000) 的二进制形式, 并定义哪个数是素数, 哪个不是。由于这个任务更加困难, 让我们打印出得到匹配的统计数据。
#include <Math\Alglib\alglib.mqh> enum mis_PROPIEDADES_RED {N_CAPAS, N_NEURONAS, N_ENTRADAS, N_SALIDAS, N_PESOS}; //--------------------------------- 输入 ----------------------- --------------------- sinput int nNeuronEntra= 10; //输入层神经元数量 //2^8= 256 2^9= 512; 2^10= 1024; 2^12= 4096; 2^14= 16384 sinput int nNeuronCapa1= 20; //第一个隐藏层的神经元数量 (不能 <1) sinput int nNeuronCapa2= 0; //第二个隐藏层的神经元数量 (不能 <1) //2^8= 256 2^9= 512; 2^10= 1024; 2^12= 4096; 2^14= 16384 sinput int nNeuronSal= 1; //输出层的神经元数量 sinput int historialEntrena= 800; //训练历史 sinput int historialEvalua= 200; //预测历史 sinput int ciclosEntrena= 2; //训练循环 sinput double tasaAprende= 0.001; //网络训练比率 sinput string intervEntrada= ""; //输入规范化: 期望的最小值和最大值 max (空= 无需优化) sinput string intervSalida= ""; //输出优化: 期望最小值和最大值 (空= 无需优化) sinput bool imprEntrena= true; //显示训练/评估数据 // ------------------------------ 全局变量 ---------------------------------------- int puntFichTexto= 0; ulong contFlush= 0; CMultilayerPerceptronShell redNeuronal; CMatrixDouble arDatosAprende(0, 0); double minAbsSalida= 0, maxAbsSalida= 0; string nombreEA= "ScriptNumPrimo"; //+----------------------- 质数检测器 -------------------------------------------------+ void OnStart() { string mensIni= "脚本 质数检测器", cadNumBin= "", linea= ""; int contAciertos= 0, totalPrimos= 0, aciertoPrimo= 0, arNumBin[], inicio= historialEntrena+1, fin= historialEntrena+historialEvalua; double arSalRed[], arNumEntra[], numPrimoRed= 0; double errorMedioEntren= 0; bool correcto= false, esNumPrimo= false, creada= creaRedNeuronal(redNeuronal); if(creada) { iniFichImprime(puntFichTexto, nombreEA+"-infRN", ".csv",mensIni); preparaDatosEntra(redNeuronal, arDatosAprende, intervEntrada!="", intervSalida!=""); normalizaDatosRed(redNeuronal, arDatosAprende, normEntrada, normSalida); errorMedioEntren= entrenaEvalRed(redNeuronal, arDatosAprende); escrTexto("-------------------------", puntFichTexto); escrTexto("RESPUESTA RED------------", puntFichTexto); escrTexto("-------------------------", puntFichTexto); escrTexto("numDec;numBin;numPrimo;numPrimoRed;correcto", puntFichTexto); for(int k= inicio; k<=fin; k++) { cadNumBin= dec_A_baseNumerica(k, arNumBin, 2, nNeuronEntra); esNumPrimo= esPrimo(k); ArrayCopy(arNumEntra, arNumBin); numPrimoRed= respuestaRed(redNeuronal, arNumEntra, arSalRed); numPrimoRed= MathRound(numPrimoRed); correcto= esNumPrimo==(int)numPrimoRed; if(esNumPrimo) { totalPrimos++; if(correcto) aciertoPrimo++; } if(correcto) contAciertos++; linea= IntegerToString(k)+";"+cadNumBin+";"+esNumPrimo+";"+(numPrimoRed==0? "false": "true")+";"+correcto; escrTexto(linea, puntFichTexto); } } escrTexto("成功 / 总数;"+DoubleToString((double)contAciertos/(double)historialEvalua*100, 2)+" %", puntFichTexto); escrTexto("发现质数;"+IntegerToString(aciertoPrimo)+";"+"总质数;"+IntegerToString(totalPrimos), puntFichTexto); escrTexto("成功 / 总质数;"+DoubleToString((double)aciertoPrimo/(double)totalPrimos*100, 2)+" %", puntFichTexto); deIniFichImprime(puntFichTexto); return; }
脚本依照指定参数 (NN 没有隐藏层, 10 个输入神经元, 第一个隐藏层 20 个神经元, 以及输出层 1 个神经元) 执行之后, 结果比前一个任务还糟糕。生成的 ScriptNumPrimo-infRN.csv 文件位于 Terminal\Common\Files 目录, 提供了以下数据:
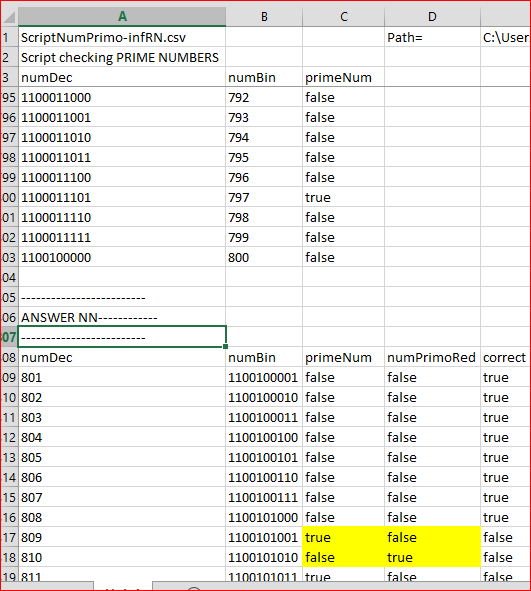
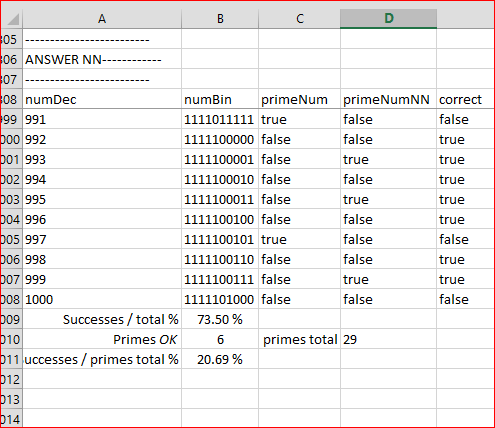
在此我们可以看到 800 (809) 之后的第一个素数没有被网络检测到 (true = 非 true)。以下是统计摘要:
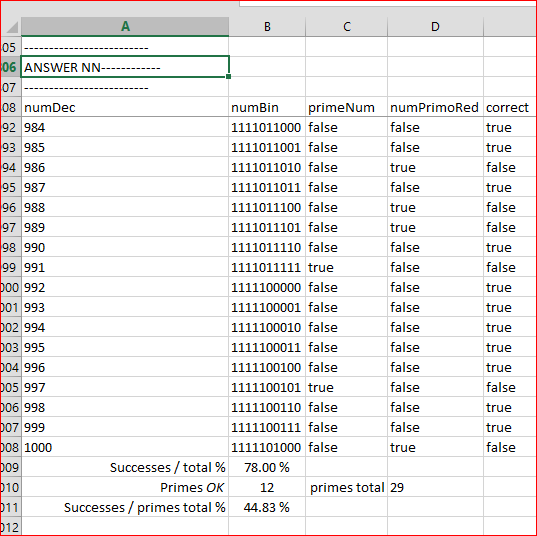
报告表明, NN 在评估区间 (801 到 1000) 上的 200 个数字中猜测出 78%。然而, 在区间内出现的 29 个素数中, 它只检测到 13 个 (44.83%)。
如果我们使用以下网络结构进行测试: "10 个输入层神经元, 第一隐藏层 35 个神经元, 第二隐藏层 10 个神经元, 和输出层 1 个神经元", 脚本在执行期间显示以下数据:
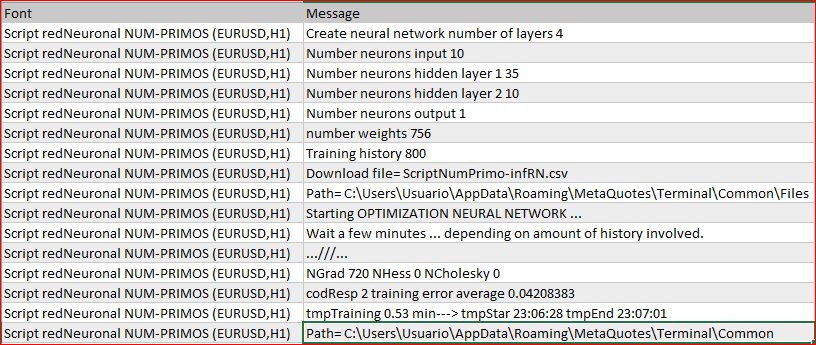
正如我们在下面的图片中可以看到的, 结果恶化, 时间 0.53 分钟, 而平均训练误差等于 0.04208383。
因此, 我们再次反思: 如何以最好的方式定义网络内部结构?
结论
在搜索自优化 EA 之时, 我们已用 MQL5 程序实现了调用 ALGLIB 库进行神经网络优化的代码。我们针对 EA 花费大量计算资源优化网络配置之时, 阻碍交易策略管理的问题提出了解决方案。
之后, 我们使用所提议的部分代码来解决 MQL5 程序的两个任务: 二进制 - 十进制转换, 检测质数并根据 NN 内部结构跟踪结果。
这种材料能否为实现有效的交易策略提供良好的基础?我们还不清楚, 但我们正在努力。在此阶段, 这篇文章似乎是一个好的开始。
本文由MetaQuotes Ltd译自西班牙语
原文地址: https://www.mql5.com/es/articles/2279
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 图形界面 X: 简单快速开发库的更新 (版本 2)
图形界面 X: 简单快速开发库的更新 (版本 2)


 MQL5 中的统计分布 - 充分利用 R 并使其更快
MQL5 中的统计分布 - 充分利用 R 并使其更快
关闭 MLP 时的测试结果。
打开 MLP 时的测试结果。
非常感谢你的文章。
三周模拟账户交易。手数 0.01。杠杆 1:100。
更新 MetaTrader 之后,智能交易系统停止学习。谁能帮助修复?
我可以破解代码...
问题已经解决。错误出在 preparaDatosEntra 函数中。
在旧程序库中是 arDatos[fila].Set(colum,valor);在新程序库中是 arDatos.Set(fila,colum,valor);
现在一切正常。还有一些新函数,如 MLPEBaggingLBFGS。有人知道如何使用集合吗?