
Python ve MQL5'te bir robot geliştirme (Bölüm 2): Model seçimi, oluşturulması ve eğitimi, özel Python sınayıcısı

Önceki makalenin kısa özeti
Önceki makalede, makine öğrenimi hakkında biraz konuştuk, veri artırımı gerçekleştirdik, gelecekteki model için özellikler geliştirdik ve bunlardan en iyilerini seçtik. Şimdi devam etme ve özelliklerimizden öğrenecek ve alım-satım yapacak (umarım başarılı bir şekilde) çalışan bir makine öğrenimi modeli oluşturma zamanı. Modeli değerlendirmek için, modelin performansını ve test grafiklerinin güzelliğini değerlendirmemize yardımcı olacak özel bir Python sınayıcısı yazacağız. Daha güzel test grafikleri ve daha fazla model kararlılığı için, yol boyunca bir dizi klasik makine öğrenimi özelliği de geliştireceğiz.
Nihai hedefimiz, fiyat tahmini ve alım-satım için çalışan ve maksimum karlı bir model oluşturmaktır. Tüm kodlar Python dilinde olacak ve MQL5 kütüphanesini içerecektir.
Python sürümü ve gerekli modüller
Çalışmamda Python 3.10.10 sürümünü kullandım. Aşağıda ekli kod, veri ön işleme, özellik çıkarma ve bir makine öğrenimi modelini eğitmek için çeşitli fonksiyonlar içerir. Şu fonksiyonlar yer alır:
- sklearn kütüphanesinden Gauss Karışım Modeli (Gaussian Mixture Model, GMM) kullanan özellik kümeleme fonksiyonu
- sklearn kütüphanesinden Çapraz Doğrulama ile Yinelemeli Özellik Eleme (Recursive Feature Elimination with Cross-Validation, RFECV) kullanan özellik çıkarma fonksiyonu
- XGBoost sınıflandırıcıyı eğitme fonksiyonu
Kodu çalıştırmak için aşağıdaki Python modüllerini yüklemeniz gerekir:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader 5
- tqdm
Bunları Python paket yükleme aracı olan 'pip' kullanarak yükleyebilirsiniz. Gerekli tüm modülleri yüklemek için örnek bir komut aşağıda verilmiştir:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Hadi başlayalım!
Sınıflandırma mı yoksa regresyon mu?
Bu, veri tahminindeki daimi sorulardan biridir. Sınıflandırma, net bir evet-hayır cevabının gerekli olduğu ikili problemler için daha uygundur. Ayrıca çok sınıflı sınıflandırma da vardır. Modelleri önemli ölçüde güçlendirebileceği için bunu serinin gelecek makalelerinde tartışacağız.
Regresyon, bir fiyat serisi de dahil olmak üzere sürekli bir serinin gelecekteki belirli bir değerinin spesifik bir tahmini için uygundur. Bir yandan bu çok daha kullanışlı olabilir, ancak diğer yandan regresyon için veri etiketleme, tıpkı etiketlerin kendileri gibi, zorlu bir konudur, çünkü enstrümanın gelecekteki fiyatını edinmekten başka yapabileceğimiz çok az şey vardır.
Ben şahsen sınıflandırmayı daha çok seviyorum çünkü veri etiketleme ile çalışmayı kolaylaştırıyor. Birçok şey evet-hayır koşullarına dönüştürülebilirken, çok sınıflı sınıflandırma Akıllı Para (Smart Money) konsepti gibi tüm karmaşık manuel alım-satım sistemlerine uygulanabilir. Veri etiketleme kodunu serinin bir önceki makalesinde zaten görmüştünüz ve ikili sınıflandırma için açıkça uygundur. Bu nedenle bu model yapısını esas alacağız.
Geriye modelin kendisine karar vermek kalıyor.
Bir sınıflandırma modeli seçme
Seçilen özelliklere sahip verilerimiz için uygun bir sınıflandırma modeli seçmemiz gerekir. Seçim, özellik sayısına, veri türlerine ve sınıf sayısına bağlıdır.
Popüler modeller ikili sınıflandırma için lojistik regresyon, yüksek boyutlar ve doğrusal olmayan durumlar için rastgele orman, karmaşık problemler için sinir ağlarıdır. Seçenekler çok fazla. Birçok şey denedikten sonra, günümüz koşullarında en etkili olanın güçlendirme (boosting) ve buna dayalı modeller olduğu sonucuna vardım.
Gelişmiş XGBoost modelini kullanmaya karar verdim - düzenlileştirme, paralellik ve çok sayıda ayar ile karar ağaçları üzerinde güçlendirme gerçekleştirir. XGBoost, yüksek doğruluğu nedeniyle sık sık veri bilimi yarışmalarını kazanır. Bu, model seçiminde ana kriter haline gelmiştir.
Sınıflandırma modeli kodunu oluşturma
Kod, gelişmiş XGBoost modelini kullanır - karar ağaçları üzerinde gradyan güçlendirme. XGBoost'un önemli bir özelliği de optimizasyon için ikinci türevlerin kullanılmasıdır, bu da diğer modellere kıyasla verimliliği ve doğruluğu artırır.
train_xgboost_classifier fonksiyonu verileri ve güçlendirme turlarının sayısını alır. Verileri X özelliklerine ve y etiketlerine böler, hiperparametre ayarlı XGBClassifier modelini oluşturur ve fit() metodunu kullanarak eğitir.
Veriler eğitim/test olarak ayrılır, model fonksiyon kullanılarak eğitim verileri üzerinde eğitilir. Model kalan veriler üzerinde test edilir ve tahminlerin doğruluğu hesaplanır.
XGBoost'un ana avantajları, gradyan güçlendirme kullanarak birden fazla modeli yüksek doğrulukta bir modelde birleştirmek ve verimlilik için ikinci türevleri optimize etmektir.
Bunu kullanmak için OpenMP runtime kütüphanesini de yüklememiz gerekecektir. Windows için, Python sürümünüzle eşleşen Microsoft Visual C++ Redistributable’ı indirmeniz gerekir.
Şimdi kodun kendisine geçelim. Kodun başında xgboost kütüphanesini aşağıdaki şekilde içe aktarıyoruz:
import xgboost as xgb Kodun geri kalanı:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Modeli eğitelim ve doğruluk oranını %52 olarak görelim.
Sınıflandırma doğruluğumuz şu anda %53 karlı etiket düzeyindedir. Lütfen burada, fiyatın TP seviyesinden (200 pip) daha fazla değiştiği ve kuyruğuyla SL seviyesine (100 pip) dokunmadığı durumları tahmin etmekten bahsettiğimizi unutmayın. Pratikte, karlı alım-satım için oldukça yeterli olan yaklaşık 3’lük bir kar faktörüne sahip olacağız. Bir sonraki adım, modellerin karlılığını USD cinsinden (puan olarak değil) analiz etmek için Python'da özel bir sınayıcı yazmaktır. Modelin, markup’ı dikkate alarak para kazanıp kazanmadığını veya fonları tüketip tüketmediğini anlamak gerekir.
Özel Python sınayıcısının fonksiyonunu yazma
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
Kod, makine öğrenimi modelini test verileri üzerinde test etmek ve markup’ı dikkate alarak karlılığını analiz etmek için bir fonksiyon oluşturur (markup, makaslardaki kayıpları ve çeşitli komisyon türlerini içermelidir). Swaplar dinamik olduklarından ve faiz oranlarına bağlı olduklarından dikkate alınmazlar. Bunlar, markup’a sadece birkaç pip eklenerek dikkate alınabilir.
Fonksiyon bir model, test verileri, markup ve başlangıç bakiyesi alır. Alım-satım, model tahminleri kullanılarak simüle edilir: 1'de alış, 0'da satış. Kar, markup’ı aşarsa pozisyon kapatılır ve kar bakiyeye eklenir.
İşlemler ve her pozisyondan elde edilen kar/zarar kaydedilir. Bakiye grafiği oluşturulur. Birikmiş toplam kar/zarar hesaplanır.
Sonunda, test verilerini elde ederiz ve gereksiz sütunları kaldırırız. xgb_clf modeli, girilen markup ve başlangıç bakiyesi ile test edilir. Hadi test edelim!

Sınayıcı genel olarak başarılı bir şekilde çalışıyor ve çok güzel bir karlılık grafiği görüyoruz. Bu, markup ve etiketleri dikkate alarak bir makine öğrenimi alım-satım modelinin karlılığını analiz etmek için özel bir sınayıcıdır.
Çapraz doğrulamayı modele uygulama
Bir makine öğrenimi modelinin kalitesine ilişkin daha güvenilir bir değerlendirme elde etmek için çapraz doğrulama kullanmamız gerekir. Çapraz doğrulama, bir modelin birden fazla veri alt kümesi üzerinde değerlendirilmesine olanak tanıyarak aşırı uyumun önlenmesine yardımcı olur ve daha objektif bir değerlendirme sağlar.
Bizim durumumuzda, XGBoost modelini değerlendirmek için 5 katlı çapraz doğrulama kullanacağız. Bunu yapmak için sklearn kütüphanesindeki cross_val_score fonksiyonunu kullanacağız.
train_xgboost_classifier fonksiyonunun kodunu aşağıdaki gibi değiştirelim:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
Modeli eğitirken, train_xgboost_classifier fonksiyonu 5 katlı çapraz doğrulama gerçekleştirecek ve ortalama tahmin doğruluğunu verecektir. Eğitim, FORWARD tarihine kadar olan örneklemi içermeye devam edecektir.
Çapraz doğrulama, modeli eğitmek için değil, yalnızca değerlendirmek için kullanılır. Eğitim, çapraz doğrulama olmadan FORWARD tarihine kadar olan tüm veriler üzerinde gerçekleştirilir.
Çapraz doğrulama, model kalitesinin daha güvenilir ve objektif bir şekilde değerlendirilmesini sağlar ve bu da teorik olarak modelin yeni fiyat verilerine karşı dayanıklılığını artıracaktır. Yoksa öyle değil mi? Sınayıcının nasıl çalıştığını kontrol edelim ve görelim.
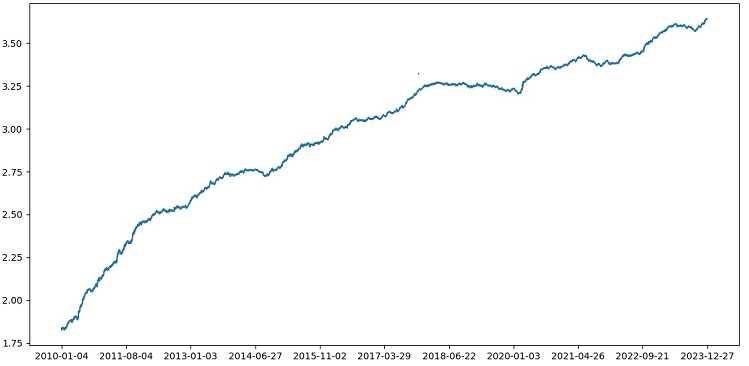
XGBoost'un 1990-2024 yılları arasındaki veriler üzerinde çapraz doğrulama ile test edilmesi, 2010'dan sonraki testte %56 doğruluk sağladı. Model, ilk denemede yeni verilere karşı iyi bir sağlamlık gösterdi. Doğruluk da oldukça iyileşti, bu da iyi bir haber.
Model hiperparametrelerinin ızgara (grid) üzerinde optimizasyonu
Hiperparametre optimizasyonu, doğruluğunu ve performansını en üst düzeye çıkarmak için bir makine öğrenimi modeli oluşturmada önemli bir adımdır. MQL5 Uzman Danışmanlarını optimize etmeye benzer, sadece bir Uzman Danışman yerine bir makine öğrenimi modeliniz olduğunu hayal edin. Izgara aramayı (grid search) kullanarak en iyi performansı gösterecek parametreleri buluruz.
Scikit-learn kullanarak ızgara tabanlı XGBoost hiperparametre optimizasyonuna bakalım.
Modeli ızgaranın tüm hiperparametre setlerinde çapraz doğrulamak için Scikit-learn'den GridSearchCV kullanacağız. Çapraz doğrulamada en yüksek ortalama doğruluğa sahip set seçilecektir.
Optimizasyon kodu:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Burada param_grid hiperparametrelerinden oluşan bir ızgara tanımlıyoruz, XGBoost clf modelini oluşturuyoruz ve GridSearchCV metodunu kullanarak ızgara üzerinde optimum hiperparametreleri arıyoruz. Daha sonra en iyi hiperparametreleri (grid_search.best_params_) ve ortalama çapraz doğrulama tahmin doğruluğunu (grid_search.best_score_) yazdırıyoruz.
Bu kodda hiperparametreleri optimize etmek için çapraz doğrulama kullandığımızı unutmayın. Bu, model kalitesinin daha güvenilir ve objektif bir değerlendirmesini elde etmemizi sağlar.
Bu kodu çalıştırdıktan sonra, XGBoost modelimiz için en iyi hiperparametreleri ve çapraz doğrulamada ortalama tahmin doğruluğunu elde ederiz. Daha sonra modeli en iyi hiperparametreleri kullanarak tüm veriler üzerinde eğitebilir ve yeni veriler üzerinde test edebiliriz.
Bu nedenle, model hiperparametrelerini bir ızgara üzerinde optimize etmek, makine öğrenimi modelleri oluştururken önemli bir görevdir. Scikit-learn kütüphanesindeki GridSearchCV metodunu kullanarak bu süreci otomatikleştirebilir ve belirli bir model ve veri için en iyi hiperparametreleri bulabiliriz.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Model topluluğu oluşturma (ensembling)
Modelimizi daha da iyi hale getirmenin zamanı geldi! Model topluluğu oluşturma (ensembling), makine öğreniminde tahmin doğruluğunu artırmak için birden fazla modeli birleştiren güçlü bir yaklaşımdır. Popüler yöntemler arasında torbalama (bagging) (farklı veri alt örneklemleri üzerinde modeller oluşturma) ve güçlendirme (boosting) (önceki modellerin hatalarını düzeltmek için modelleri sırayla eğitme) yer alır.
Görevimizde, torbalama ve güçlendirme ile XGBoost topluluk oluşturmayı kullanıyoruz. Farklı alt örneklemler üzerinde eğitilmiş birkaç XGBoost oluşturuyor ve tahminlerini birleştiriyoruz. Ayrıca GridSearchCV ile her modelin hiperparametrelerini optimize ediyoruz.
Topluluk oluşturmanın faydaları: daha yüksek doğruluk, azaltılmış varyans, iyileştirilmiş genel model kalitesi.
Nihai model eğitim fonksiyonu çapraz doğrulama, topluluk oluşturma ve ızgara torbalama hiperparametre seçimini kullanır.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Torbalama yoluyla model topluluğu oluşturmayı uygulayalım, testi gerçekleştirelim ve aşağıdaki test sonucunu elde edelim:
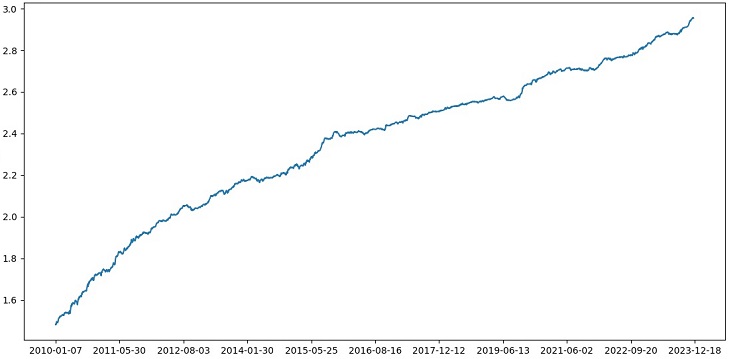
Risk-kazanç oranı 1:8 olan işlemleri sınıflandırma doğruluğu %73'e yükseldi. Başka bir deyişle, topluluk oluşturma ve ızgara arama, kodun önceki sürümüne kıyasla sınıflandırma doğruluğunda bize büyük bir artış sağladı. Bunu mükemmelden de öte bir sonuç olarak görüyorum ve modelin ileriye dönük performansının önceki grafiklerinden, kodun gelişimi sırasında ne kadar güçlendiği açıkça anlaşılabilir.
Sınav örnekleminin uygulanması ve modelin sağlamlığının test edilmesi
Şimdi test için EXAMWARD tarihinden sonraki verileri kullanıyorum. Bu, modeli eğitmek ve test etmek için kullanılmayan tamamen yeni veriler üzerinde model performansını test etmeme olanak tanıyor. Bu şekilde modelin gerçek koşullarda nasıl performans göstereceğini objektif olarak değerlendirebiliyorum.
Bir sınav örneği üzerinde test yapmak, bir makine öğrenimi modelini doğrulamada önemli bir adımdır. Bu, modelin yeni veriler üzerinde iyi performans gösterdiğinden emin olunmasını sağlar ve gerçek dünyadaki performansı hakkında bir fikir verir. Burada örneklem büyüklüğünü doğru belirlememiz ve temsili olmasını sağlamamız gerekir.
Benim durumumda, EXAMWARD sonrası verileri kullanarak modeli, eğitim ve test dışındaki tamamen yabancı veriler üzerinde test ediyorum. Bu şekilde modelin verimliliği ve gerçek kullanıma hazır olup olmadığına dair objektif bir değerlendirme elde ediyorum.
2000-2010 yılları arasındaki veriler üzerinde eğitim, 2010-2019 yılları arasında test, 2019 yılından itibaren sınav yaptım. Sınav, bilinmeyen bir gelecekte alım-satım yapmayı simüle eder.
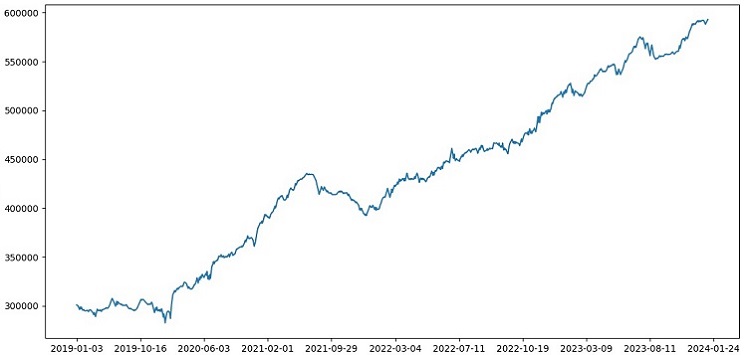
Genel olarak her şey iyi görünüyor. Sınavdaki doğruluk oranı %60'a düştü, ancak asıl önemli olan, modelin karlı ve oldukça sağlam olması ve ciddi düşüşler yaşamamasıdır. Modelin risk/kazanç kavramını öğrenmesi sevindiricidir - düşük riskli ve yüksek potansiyel karlı durumları tahmin ediyor (1:8 risk-kazanç kullanıyoruz).
Sonuç
Böylece Python'da bir alım-satım robotu oluşturma serisinin ikinci makalesini tamamlamış olduk. Şu anda, verilerle çalışma, özelliklerle çalışma, özelliklerin seçimi ve hatta oluşturulması ve model seçimi ve eğitimi problemlerini çözmeyi başardık. Ayrıca modeli test eden özel bir sınayıcı uyguladık ve her şey oldukça iyi çalışıyor gibi görünüyor. Bu arada, verileri basitleştirmek için en basit olanlar da dahil olmak üzere diğer özellikleri de denedim, ancak sonuç alamadım. Bu özelliklere sahip modeller sınayıcıdaki hesabı boşalttı. Bu, özelliklerin ve verilerin modelin kendisinden daha az önemli olmadığını bir kez daha teyit etmektedir. İyi bir model yapabilir ve çeşitli iyileştirmeler ve yöntemler uygulayabiliriz, ancak özellikler işe yaramazsa, bilinmeyen veriler üzerinde bakiyemizi acımasızca tüketecektir. Aksine, iyi özelliklerle vasat bir modelde bile istikrarlı bir sonuç elde edebilirsiniz.
Sonraki gelişmeler
Gelecekte, kullanışlılığı artırmak için doğrudan Python üzerinden alım-satım yapmak üzere MetaTrader 5 terminalinde çevrimiçi alım-satımın özel bir sürümünü oluşturmayı planlıyorum. Python için bir sürüm yapmak için ilk motivasyonum, özelliklerin MQL5'e aktarılmasıyla ilgili sorunlardı. Python'da özellikleri, bunların seçimini, veri etiketlemeyi ve veri artırmayı işlemek benim için hala çok daha hızlı ve kullanışlı.
Python için geliştirilen MQL5 kütüphanesinin yeterince değer görmediğine inanıyorum. Çok az kişinin kullandığı açıktır. Hem göze hem de cüzdana hitap eden gerçekten güzel modeller oluşturmak için kullanılabilecek güçlü bir çözümdür!
Ayrıca gerçek bir borsanın (CME veya MOEX) piyasa derinliği geçmiş verilerinden öğrenecek bir versiyonu da uygulamak istiyorum. Bu da umut verici bir girişimdir.
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/14910
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Eugene, makalelerinizden ML'yi ticaretle ilgili olarak incelemeye başladım, bunun için çok teşekkür ederim.
Aşağıdaki noktaları açıklayabilir misiniz?
label_data işlevi verileri işledikten sonra, hacmi önemli ölçüde azalır (işlevin koşullarını karşılayan rastgele bir çubuk kümesi elde ederiz). Daha sonra veri birkaç fonksiyondan geçer ve biz onu eğitme ve test örneklerine böleriz. Model, eğitim örneği üzerinde eğitilir. Bundan sonra, ['labels'] sütunları test örneğinden çıkarılır ve modeli tahmin etmek için değerlerini tahmin etmeye çalışırız. Test verilerinde kavram ikamesi yok mu? Sonuçta, testler için label_data işlevini geçen verileri kullanıyoruz (yani gelecekteki verileri dikkate alan bir işlev tarafından önceden seçilen sıralı olmayan çubuklar kümesi). Ve sonra test cihazında, anladığım kadarıyla, anlaşmanın kaç çubukla kapatılacağından sorumlu olması gereken 10 parametresi var, ancak sıralı olmayan bir çubuk setimiz olduğundan, ne elde ettiğimiz net değil.
Aşağıdaki sorular ortaya çıkıyor: Nerede yanlış yapıyorum? Neden tüm çubuklar >= FORWARD testler için kullanılmıyor? Ve tüm çubukları >= FORWARD kullanmazsak, geleceği bilmeden tahmin için gerekli çubukları nasıl seçebiliriz?
Teşekkürler.
Harika bir çalışma, çok ilginç, pratik ve gerçekçi. Sonuçları olmayan sadece teoriden ibaret olmayan, gerçek örneklerle bu kadar iyi bir makale görmek zor. Çalışmalarınız ve paylaşımlarınız için çok teşekkür ederim, bu seriyi takip ediyor ve dört gözle bekliyor olacağım.
Çok teşekkürler! Evet, bu makalenin ONNX'e çevrilerek genişletilmesi de dahil olmak üzere, önümüzde hala birçok fikir uygulaması var)
Kritik kusurlar:
İyileştirme için öneriler: