
Множественный регрессионный анализ: генератор стратегий и тестер в одном флаконе

Введение
Один мой знакомый, посещая учебные курсы о торговле на форекс, получил домашнее задание - построить торговую систему. Повозившись с этим с недельку, он сказал, что эта задача, пожалуй, сложнее, чем написать диссертацию. Тогда я предложил ему попробовать множественный регрессионный анализ. В итоге за вечер была создана "с нуля" торговая система, успешно прошедшая проверку экзаменатора.
Успех применения множественной регрессии состоял в том, что с помощью этого анализа можно быстро найти связи между индикаторами и ценой. Обнаруженные связи позволяют предсказать с некоторой долей вероятности значение цены на основе значений индикаторов. Современные статистические программы дают возможность "просеивать" одновременно тысячи показателей в поисках таких связей. Это можно сравнить с промышленным просеиванием породы в поисках крупиц золота.
В результате, загружая данные индикаторов во множественный регрессионный анализ, на выходе мы получим готовую стратегию, а манипулируя данными, мы получим генератор стратегий.
В статье будет продемонстрировано создание торговой стратегии с помощью множественного регрессионного анализа.
1. Что нам стоит робота построить
В ходе упомянутой вечерней работы была сделана торговая система, сердцем которой стало одно единственное уравнение:
Reg=22.7+205.2(buf_DeMarker[1]-buf_DeMarker[2])-14619.5*buf_BearsPower[1]+22468.8*buf_BullsPower[1]-139.3*buf_DeMarker[1]-41686*(buf_AC[1]-buf_AC[2])
где, если Reg >0 , то покупаем, а если Reg < 0, то продаем.
Уравнение стало итогом множественного регрессионного анализа, в который загрузили выборку данных от стандартных индикаторов. На основе уравнения был сделан советник. Фрагмент кода, принимающий решение о сделках, фактически содержал всего 15 строчек. Советник с полным исходным кодом прилагается (R_check).
//--- проверяем диапазон изменения цены double price=(mrate[2].close-mrate[1].close)/_Point; //--- если диапазон велик, то сделки не выполняем, а текущие позиции закрываем if(price>250 || price<-250) { ClosePosition(); return; } //--- регрессионное уравнение double Reg=22.7+205.2*(buf_DeMarker[1]-buf_DeMarker[2]) -14619.5*buf_BearsPower[1]+22468.8*buf_BullsPower[1] -139.3*buf_DeMarker[1] -41686*(buf_AC[1]-buf_AC[2]); //--- проверяем наличие открытых позиций if(myposition.Select(_Symbol)==true) //--- открытые позиции есть { if(myposition.PositionType()==POSITION_TYPE_BUY) { Buy_opened=true; // длинная позиция (Buy) } if(myposition.PositionType()==POSITION_TYPE_SELL) { Sell_opened=true; //--- короткая позиция (Sell) } } //--- если открытая позиция совпадает с направлением, предсказанным по уравнению, то ничего не делаем. if(Reg>0 && Buy_opened==true) return; if(Reg<=0 && Sell_opened==true) return; //--- если открытая позиция не совпадает с предсказанным направлением, то закрываем позицию. if(Reg<=0 && Buy_opened==true) ClosePosition(); if(Reg>0 && Sell_opened==true) ClosePosition(); //--- открываем позицию в направлении, предсказанном по уравнению. //--- используем уровень 20 для фильтрации сигнала. if(Reg>20) BuyOrder(1); if(Reg<-20) SellOrder(1);
Выборка данных для регрессионного анализа была собрана на EURUSD H1 на двухмесячном интервале с 1 июля 2011 по 31 августа 2011.
На рис. 1 показан результат работы советника на интервале данных, на котором он создавался. Любопытно, что на обучающих данных не наблюдалась сверхприбыль, как это часто происходит в тестере. Вероятно, это свидетельствовало об отсутствии переоптимизации.
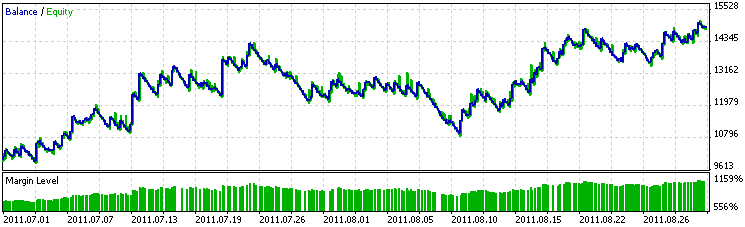
Рис. 1. График работы советника на обучающем периоде
На рис. 2 представлены результаты советника, полученные на тестовых данных (с 1 сентября по 1 ноября 2011). Получилось, что двухмесячного набора данных было достаточно, чтобы советник оставался прибыльным еще два следующих месяца. При этом на тестовом периоде советник заработал столько же, сколько и на обучающем.
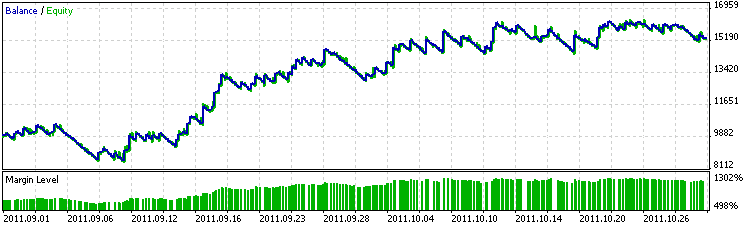
Рис. 2. График работы советника на тестовом периоде
Таким образом, на основе множественного регрессионного анализа был создан сравнительно простой советник, показавший прибыль вне обучающих данных. Следовательно, регрессионный анализ может быть успешно применен для построения торговых систем.
Вместе с тем, не следует переоценивать возможности регрессионного анализа. Далее будет рассказано как о его сильных сторонах, так и о слабых.
2. Множественный регрессионный анализ
Общее назначение множественной регрессии состоит в анализе связи между несколькими независимыми переменными и одной зависимой переменной. В нашем случае, это анализ связи между значениями индикаторов и движением цены.
В самом простом виде такое уравнение может иметь вид:
Изменение цены = a * RSI + b * MACD + с
Построить регрессионное уравнение можно только при наличии корреляции между независимыми переменными и зависимой. Поскольку значения индикаторов, как правило, имеют связь друг с другом, то вклад индикаторов в предсказание может существенно меняться, если мы добавим или уберем какой-либо индикатор из анализа. Обратите внимание, что регрессионное уравнение – это только демонстрация числовой зависимости, а не описание причинных связей. Коэффициенты (a, b) показывают вклад каждой независимой переменной в связь с зависимой.
Регрессионное уравнение выражает идеальную зависимость переменных. Однако, на форекс такое невозможно, поэтому прогноз всегда будет отличаться от реальности. Разница между прогнозируемым значением и реальным называется остатком. Анализ остатков позволяет определить, в том числе, наличие нелинейной зависимости между индикатором и ценой. В нашем случае мы предполагаем, что между индикаторами и ценой есть только линейная зависимость. К счастью, регрессионный анализ устойчив к малым отклонениям от линейности.
Регрессионный анализ может быть использован только для анализа количественных показателей. Качественные показатели, которые не имеют переходных значений, не подходят для этого анализа.
Поскольку регрессионный анализ может "перемолоть" любое число показателей, то возникает соблазн включить в него их как можно больше. Однако если число независимых показателей будет больше, чем число наблюдений их взаимодействия с зависимым показателем, тогда есть большая вероятность получить уравнения с хорошими предсказаниями, но основанными на случайных колебаниях.
Число наблюдений должно быть в 10-20 раз больше, чем число независимых показателей.
В нашем случае количество индикаторов, которое содержит наша выборка данных, должно быть в 10-20 раз больше, чем число сделок в нашей выборке. Тогда полученное уравнение будет считаться надежным. В выборке, на основе которой был сделан робот в разделе 1, содержалось 33 показателя и 836 наблюдений. В результате число показателей было в 25 раз больше, чем число наблюдений. Это требование является общим правилом для статистики. Оно же действует и для оптимизатора тестера стратегий терминала MetaTrader 5.
При этом в оптимизаторе каждое заданное значение индикатора фактически является отдельным показателем. Другими словами, если мы тестируем 10 значений для индикатора, то это 10 независимых показателей, это следует учитывать, чтобы избежать переоптимизации. Возможно, в отчет оптимизатора следует добавить показатель: среднее количество сделок/количество значений всех оптимизируемых параметров. Если значение показателя будет меньше десяти, то высока вероятность переоптимизации.
Другое, что нужно учитывать, это выбросы в данных. Редкие, но сильные события (в нашем случае скачки цены) могут внести ложные зависимости в уравнение. Например, после выхода какой-либо неожиданной новости на рынке произошло сильное движение, продлившееся несколько часов. В этом случае значения технических индикаторов имели малую значимость в прогнозе, но регрессионный анализ припишет им высокую значимость, поскольку было сильное изменение цены. Поэтому желательно фильтровать данные в выборке или проверять наличие выбросов в данных.
3. Делаем свою стратегию
Мы подошли к главной части, где разберем, как построить регрессионное уравнение из собственных данных. Выполнение регрессионного анализа сходно с ранее описанным дискриминантным анализом. Регрессионный анализ включает в себя следующее.
- Подготовка данных для анализа;
- Выбор лучших переменных из подготовленных данных;
- Получение регрессионного уравнения.
Множественный регрессионный анализ включен во многие современные программы, предназначенные для статистического анализа данных. Наиболее популярными программами являются Statistica (StatSoft Inc.) и SPSS (IBM Corporation). Далее мы будем рассматривать применение регрессионного анализа с помощью программы Statistica 8.0.
3.1. Подготовка данных для анализа
Нашей задачей является построение регрессионного уравнения, в котором по значениям индикаторов на текущем баре можно будет прогнозировать движение цены на следующем баре.
Для сбора данных будет использоваться тот же советник, что был использован для подготовки данных для дискриминантного анализа. Расширим его функционал, добавив сохранение значений индикаторов с другими периодами. Расширенный набор показателей будет использован для оптимизации стратегии на основе анализа одних и тех же индикаторов, но с разными периодами.
Файл для загрузки данных в Statistica должен быть в формате CSV и иметь следующую структуру. Переменные должны быть расположены в столбик, т.е. каждому столбику соответствует какой-либо один индикатор. В строках должны располагаться последовательные измерения (случаи), т.е. значения индикаторов для конкретных баров. Другими словами, в заголовках таблицы по горизонтали расположены индикаторы, по вертикали последовательные бары.
Индикаторы, которые будут анализироваться:
- Accelerator Oscillator;
- Bears Power;
- Bulls Power;
- Awesome Oscillator;
- Commodity Channel Index;
- DeMarker;
- Fractal Adaptive Moving Average;
- MACD;
- Relative Strength Index;
- Money Flow Index;
- Stochastic;
- Williams Percent Range.
В нашем файле в каждой строке данных будут содержаться:
- Изменение цены между Open и Close на баре;
- Значения индикаторов, которые были на предшествующем баре.
Таким образом, мы будем искать уравнение, описывающее будущее поведение цены на основе известных значений индикаторов.
Помимо абсолютного значения индикаторов сохраняем их разницу со своими предыдущими значениями, чтобы учитывать направление изменения индикаторов. Такие показатели в предложенном примере будут иметь в названии префикс "d". Для индикаторов с сигнальной линией также сохраняем разницу между главной и сигнальной линией, а также ее динамику. Данные, собранные индикаторами с другими периодами, имеют в названиях окончание «_p».
Для демонстрации оптимизации был добавлен только один период, который в два раза длиннее стандартного периода индикатора. Дополнительно сохраняем время поступления бара и значение часа для него. Сохраняем разницу между Open и Close для бара, на котором рассчитываем индикаторы. Это будет использовано для фильтрации выбросов. В результате мы будем анализировать 33 показателя, чтобы построить уравнение множественной регрессии. Описанный сбор данных реализован в советнике R_collection, который приложен к статье.
После запуска советника в папке: каталог_данных_терминала/MQL5/Files будет создан файл MasterData.CSV. При запуске советника в тестере он будет располагаться в каталоге каталог_данных_терминала/tester/Agent-127.0.0.1-3000/MQL5/Files. Полученный файл можно загружать в Statistica.
Пример такого файла приложен в MasterDataR.CSV. Данные были собраны при помощи тестера стратегий по валютной паре EURUSD на участке с 3 января 2011 по 11 ноября 2011 на периоде H1. В анализе были использованы только данные с августа и сентября. Остальные данные были сохранены в файле, чтобы вы могли потренироваться на них.
Для загрузки CSV-файла в Statistica делаем следующее.
- В Statistica откройте File, потом Open, выберите тип файла “Data files” и открывайте наш CSV-файл.
- В окне Text File Import Type оставьте Delimited и нажмите OK.
- В открывшемся окне включите подчеркнутые пункты.
- В поле Decimal separator character нужно обязательно поставить точку независимо от того, есть она там уже или нет.

Рис. 3. Импорт файла в Statistica
Нажав OK, получаем таблицу с нашими данными. Данные готовы для выполнения множественного регрессионного анализа. Пример полученного файла для Statistica приложен в MasterDataR.STA.
3.2. Автоматический отбор индикаторов
Запустите Регрессионный анализ (Statistics->Multiple Regression).

Рис. 4. Запуск регрессионного анализа
В открывшемся окне перейдите на вкладку Advanced и включите отмеченные пункты. Нажмите кнопку Variables.
В первом поле выберите зависимую (Dependent) переменную, во втором поле выберите независимые (Independent) переменные, на основе которых мы будем строить уравнение. В нашем случае: в первом поле укажите показатель Price, во втором поле - показатели с Price2 по dWPR.

Рис. 5. Подготовка к выбору показателей
Нажмите кнопку Select Cases (Рис. 5).
Откроется окно для выбора случаев (строк данных), которые мы будем использовать для анализа. Включите пункты, указанные на рис. 6.

Рис. 6. Выбор случаев
Укажем для анализа только данные, относящиеся к июлю и августу. Это случаи с 3590 по 4664. Номера случаев задаются через переменную V0. Чтобы избежать влияния выбросов и скачков цены, добавим фильтрацию данных по цене.
Включим в анализ только те значения индикаторов, для которых на последнем баре разница между Open и Close была не больше 250 пунктов. Указав здесь правила выбора случаев для анализа, мы задали выборку данных для построения регрессионного уравнения. Далее нажмите OK здесь и в окне подготовки к выбору (рис. 5).
Откроется окно выбора метода для автоматического отбора данных. Выберите Forward Stepwise метод (рис. 7).

Рис. 7. Выбор метода
Нажмите OK. Откроется окно, информирующее о том, что регрессионный анализ успешно выполнен.

Рис. 8. Окно результатов регрессионного анализа
Когда выполняется автоматический отбор показателей, то выбираются те из них, которые вносят наибольший вклад во множественную корреляцию между показателями (независимые переменные) и зависимой переменной. В нашем случае будет выбран набор индикаторов, которые лучше всего обусловливают цену. Автоматический отбор, по сути, играет роль генератора стратегии. В генерируемое уравнение идут только те индикаторы, которые достоверно и наилучшим образом описывают поведение цены.
В окне результатов (рис. 8) в верхней части содержатся статистические характеристики полученного уравнения и снизу перечислены показатели, которые были включены в уравнение. Обратите внимание на подчеркнутые характеристики. Multiple R - это значение множественной корреляции между ценой и индикаторами, вошедшими в уравнение. "p" - это уровень статистической достоверности этой корреляции.
Достоверным считается уровень меньше 0.05. "No. of cases" - это количество случаев, использованных для анализа. В списке показателей красным отмечены показатели, вклад которых статистически достоверен. В идеале, все показатели должны быть отмечены красным.
Используемые в Statistica правила включения показателей в анализ не всегда оптимальны. Например, в регрессионное уравнение может быть включено много недостоверных показателей. Поэтому мы должны проявить творческий подход и помочь программе с выбором показателей.
Если в списке есть недостоверные показатели, то нажмите кнопку Summary: Regression results.
Откроется окно с данными по каждому показателю (рис. 9).

Рис. 9. Отчет о показателях, включенных в регрессионное уравнение
Посмотрите, у какого недостоверного показателя самый большой уровень "p" (p-level) и запомните его наименование. Вернитесь на этап включения показателей в анализ (рис. 7) и уберите этот показатель из списка показателей, выбранных для анализа.
Для возврата нажмите Cancel в окне результатов анализа и повторите анализ. Постарайтесь таким образом исключить все недостоверные показатели. При этом ориентируйтесь на получаемое значение множественной корреляции (Multiple R), оно не должно значительно уменьшиться от первоначального. Можно убирать недостоверные показатели из анализа по одному, а можно все сразу. Первый способ предпочтительнее.
В итоге в таблице остались только достоверные показатели (рис. 10). При этом значение корреляции снизилось примерно на 20%, которые, вероятно, были обусловлены случайными совпадениями. Как известно, в бесконечно большом числовом ряде есть бесконечное количество случайных совпадений.
Поскольку мы обрабатываем большие выборки данных, то там тоже содержатся случайные совпадения и случайные связи. Поэтому важно использовать в своих стратегиях показатели, которые являются статистически достоверными.

Рис. 10. В уравнение включены только достоверные показатели
Если в результате отбора показателей не удается создать группу из нескольких индикаторов, достоверно коррелирующих с ценой, то, вероятно, в цене содержится мало информации о прошлых событиях. В таких случаях следует осторожно торговать на основе любого технического анализа или вовсе приостановить торговлю.
В нашем примере из 33 показателей только пять были признаны полезными для создания стратегии на основе регрессионного уравнения. Эта способность регрессионного анализа является удобной для выбора индикаторов для собственных стратегий.
3.3. Регрессионное уравнение и его анализ
Итак, мы сделали регрессионный анализ, получили список "правильных" индикаторов. Теперь переведем это в регрессионное уравнение. Коэффициенты уравнения для каждого индикатора указаны в результатах регрессионного анализа в столбике B (рис. 10). В той же таблице показатель Intercept является независимым членом уравнения и включается в уравнение в виде самостоятельного коэффициента.
Построим уравнение на основе этой таблицы (рис. 10), взяв коэффициенты из столбика B.
Price = 22.7 + 205.2*dDemarker - 41686.2*dAC - 139.3*DeMarker + 22468.8*Bulls - 14619.5*Bears
Это уравнение ранее приводилось в разделе 1 в виде кода на MQL5. Там же приводились полученные в тестере результаты работы советника, сделанного на основе этого уравнения. Как мы видим, регрессионный анализ достойно выступил в качестве генератора стратегии. Анализ предложил конкретную стратегию и выбрал для нее индикаторы из предложенного списка.
В случае если вы желаете дополнительно проанализировать устойчивость уравнения, то следует проверить:
- Выбросы в уравнении;
- Нормальность распределения остатков;
- Нелинейность влияния отдельных показателей внутри уравнения.
Эти проверки можно выполнить с помощью анализа остатков (Residual Analysis). Для перехода к этому анализу нужно нажать ОК в окне результатов (рис. 8). Если вы выполните указанные проверки для полученного уравнения, то обнаружите, что уравнение оказалось устойчивым к небольшому числу выбросов, устойчивым к небольшим отклонениям от нормального распределения в данных и устойчивым к наличию некоторой нелинейности в показателях.
Если нелинейность связи велика, то можно найти преобразование для приведения показателя к линейному виду. Для этих целей в Statistica есть анализ "Фиксированная нелинейная регрессия" (Fixed nonlinear regression). Анализ запускается в меню: Statistics -> Advanced Linear/Nonlinear Models -> Fixed Nonlinear Regression. В целом, сделанные проверки свидетельствовали о хорошей устойчивости множественного регрессионного анализа к умеренному числу помех в анализируемых данных.
4. Регрессионный анализ как оптимизатор стратегии
Поскольку регрессионный анализ может проверить тысячи показателей, то это можно использовать для оптимизации стратегии. Так, если есть потребность проверить 50 периодов для индикатора, то можно сохранить их в качестве отдельных 50 показателей и направить в регрессионный анализ все сразу. В таблицу Statistica вмещается 65536 показателей. Если для каждого индикатора проверять 50 периодов, то в анализ можно направить около 1300 индикаторов! Это превосходит возможности стандартного тестера MetaTrader 5.
Проведем такую оптимизацию на данных нашего примера. Как говорилось в разделе 4.1, для демонстрации оптимизации в данные добавлены значения индикаторов с периодом в два раза больше стандартного. В файлах данных эти показатели имеют в названиях окончание "_p". С учетом индикаторов на стандартных периодах в нашей выборке теперь 60 показателей. Выполнив для них действия, описанные в разделе 3.2, получим следующую таблицу (рис. 11).

Рис. 11. Результаты анализа индикаторов с разными периодами
В регрессионное уравнение вошло 11 показателей: шесть от индикаторов на стандартных периодах и пять от индикаторов на увеличенных периодах. Корреляция показателей с ценой увеличилась на четверть. В уравнение оказались включенными показатели индикатора MACD для обоих периодов.
Поскольку для регрессионного анализа значения одного и того же индикатора на разных периодах является разными показателями, то в уравнении могут комбинироваться значения индикаторов с разных периодов. Например, в результате анализа может обнаружиться, что значение RSI(7) имеет связь с повышением цены, а RSI(14) - связь со снижением цены. Стандартный тестер не делает подобного анализа.
Регрессионное уравнение, сделанное на основе расширенного анализа (рис. 11), имеет вид:
Price = 297 + 173*dDemarker - 65103*dAC - 177*DeMarker + 28553*Bulls_p - 24808*AO - 1057032*dMACDms_p + 2.41*WPR_p - 2.44*Stoch_m_p + 125536*MACDms + 18.65*dRSI_p - 0.768*dCCI
Проверим, какие результаты покажет это уравнение в советнике. На рис. 12 показан результат тестирования советника на данных с 1 июля по 1 сентября 2011 г., которые использовались для регрессионного анализа. График стал более плавным, а советник сделал больше прибыли.
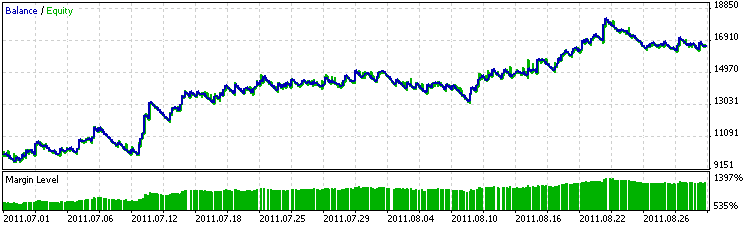
Рис. 12. График работы советника на обучающем периоде
Протестируем советник на тестовом периоде с 1 сентября по 1 ноября 2011 г. График прибыли стал хуже, чем был для советника только с индикаторами стандартных периодов. Возможно, для полученного уравнения следует сделать проверки на нормальность и нелинейность внутренних показателей.
Поскольку нелинейность наблюдалась на индикаторах стандартного периода, то на увеличенном периоде нелинейность могла стать критической. В таком случае приведение показателей к линейному виду улучшит работу уравнения. Так или иначе, советник "не слил" на тестовом периоде, а только не заработал. Таким образом, это характеризует найденную стратегию, как относительно устойчивую.
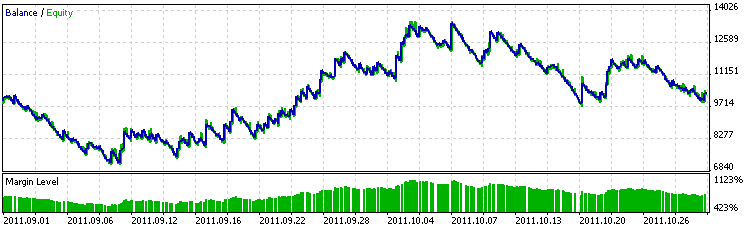
Рис. 13. График работы советника на тестовом периоде
Следует отметить, что MQL5 поддерживает вывод в файл в одну строку только 64 показателя. Для масштабного анализа индикаторов на разных периодах нужно будет объединять таблицы данных, это можно сделать в Statistica или в MS Excel.
Заключение
Проведенное в статье небольшое исследование показало, что регрессионный анализ дает возможность выбрать из множества индикаторов те, которые имеет наибольшую значимость в прогнозе цены. Также было показано, что регрессионный анализ может использоваться для поиска периодов индикаторов, которые являются оптимальными на заданной выборке.
Важно отметить, что регрессионные уравнения легко поддаются переводу на язык MQL5, а их использование не требует высокой квалификации в программировании. Таким образом, множественный регрессионный анализ может использоваться для разработки торговой стратегии. При этом уравнение регрессии может служить как основа торговой стратегии.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Интервью с Валерием Мазуренко (ATC 2011)
Интервью с Валерием Мазуренко (ATC 2011)
 MQL5-RPC - Удаленный вызов процедур из MQL5: доступ к Web-сервисам и анализ данных Automated Trading Championship 2011
MQL5-RPC - Удаленный вызов процедур из MQL5: доступ к Web-сервисам и анализ данных Automated Trading Championship 2011
 Интервью с Андреем Бобряшовым (ATC 2011)
Интервью с Андреем Бобряшовым (ATC 2011)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
очень похоже на нейронные сети
ЗЫ: и даже если это будет не НС, то результат такого инструмента будет схож с работой НС - на истории положительные результаты
очень похоже на нейронные сети
ЗЫ: и даже если это будет не НС, то результат такого инструмента будет схож с работой НС - на истории положительные результаты
Да, именно. Поэтому подобных методов недостаточно. (но таки необходимо!)
;-)
Integer:.
А какие факторы? Все индикаторы со всеми возможными наборами параметров со всех возможных символов?
Все не надо. Надо только перспективные. И потому решающий фактор - умение находить эти самые "перспективные".
А задача метода - гробить надежды, то бишь распознавать"ложную перспективность".
Что, строго говоря, тоже ценно.
// "Убей надежду вовремя!" (ц) я
Уважаемый господин,
Я ничего не знаю о том, как использовать этот или другие элементы, о которых вы писали.Я пытался написать дискриминационный советник, но не могу добиться того, чтобы советник позволял загружать мастер без загрузки индикаторов через мастер. При этом секция "int OnInit()" выглядит не так, как в вашей статье.Нужно ли мне стереть всю информацию из этой секции и сделать мои секции похожими на ваши? Где находится программа Statistica на MQL 5? Как ее открыть? Может быть, мне лучше спросить вас, поможете ли вы мне с тем, что я пытаюсь сделать, или вы знаете кого-то, кто может это сделать?Я буду делиться богатством идеи, но не хочу, чтобы она была опубликована или продана. В настоящее время план работает в 85% случаев, но мог бы быть лучше. Аналогично, когда он будет оптимизирован, торговать им будет проще через пользовательский индикатор, но я не знаю, как написать и его.Знаете ли вы что-нибудь о языке программирования платформы Thinkorswim компании TD Ameritrade? Видите ли, для того чтобы это работало, нам нужен доступ к базовым индикаторам валют, таким как DX, 6e, 6a, 6j, и другим экономическим индексам. Есть ли у TOS программа Statistica? Пожалуйста, свяжитесь со мной по электронной почте dennie3166@yahoo.com.
Большое спасибо,
Денни.
Уважаемый Артем,
Уважаемые трейдеры,
Я действительно впечатлен этой статьей, но, к сожалению, приложенные файлы "r_check.mq5" и "r_collection.mq5" не работают. На самом деле они даже не отображаются в моем MT5.
Кто-нибудь знает, в чем может быть причина. Буду очень благодарен!
Заранее спасибо!
С уважением,
Николай Христов.