
Come utilizzare i modelli ONNX in MQL5

Introduzione
Gli autori dell'articolo A CNN-LSTM-Based Model to Forecast Stock Prices (Wenjie Lu, Jiazheng Li, Yifan Li, Aijun Sun, Jingyang Wang, Complexity magazine, vol. 2020, Article ID 6622927, 10 pagine, 2020) hanno confrontato vari modelli di previsione dei prezzi delle azioni:
I dati sui prezzi delle azioni hanno le caratteristiche delle serie temporali.
Allo stesso tempo, basandosi sull'apprendimento automatico della memoria a lungo termine (LSTM) che presenta il vantaggio di analizzare le relazioni tra i dati delle serie temporali attraverso la sua funzione di memoria, proponiamo un metodo di previsione del prezzo delle azioni basato su CNN-LSTM.
Nel frattempo, utilizziamo MLP, CNN, RNN, LSTM, CNN-RNN e altri modelli di previsione per prevedere il prezzo delle azioni uno per uno. Inoltre, i risultati previsionali di questi modelli vengono analizzati e confrontati.
I dati utilizzati in questa ricerca riguardano i prezzi giornalieri delle azioni dal 1 luglio 1991 al 31 agosto 2020, inclusi 7127 giorni di negoziazione.
In termini di dati storici, scegliamo otto caratteristiche, tra cui prezzo di apertura, prezzo massimo, prezzo minimo, prezzo di chiusura, volume, controvalore, alti e bassi e cambiamento.
In primo luogo, adottiamo la CNN per estrarre in modo efficiente le caratteristiche dai dati, ovvero gli elementi dei 10 giorni precedenti. Quindi, adottiamo LSTM per prevedere il prezzo delle azioni con i dati delle caratteristiche estratti.
Secondo i risultati sperimentali, la CNN-LSTM può fornire una previsione affidabile del prezzo delle azioni con la massima precisione di previsione.
Questo metodo di previsione non solo fornisce una nuova idea di ricerca per la previsione dei prezzi delle azioni, ma fornisce anche esperienza pratica ai ricercatori per studiare i dati delle serie temporali finanziarie.
Tra tutti i modelli considerati, i modelli CNN-LSTM hanno generato i migliori risultati durante gli esperimenti. In questo articolo, considereremo come creare un modello di questo tipo per prevedere le serie temporali finanziarie e come utilizzare il modello ONNX creato in un Expert Advisor MQL5.
1. Costruire un modello
Python offre una serie di librerie specializzate e quindi fornisce ampie funzionalità per lavorare con modelli ML. Le biblioteche facilitano notevolmente la preparazione e l'elaborazione dei dati.
Ti consigliamo di utilizzare le risorse GPU per massimizzare l'efficienza dei progetti ML. Molti utenti Windows hanno riscontrato problemi nel tentativo di installare l'attuale versione di TensorFlow (vedi commenti sulla videoguida e sulla sua versione testuale). Così, abbiamo testato TensorFlow 2.10.0 e consigliamo di utilizzare questa versione. I calcoli della GPU sono stati eseguiti sulla scheda grafica NVIDIA GeForce RTX 2080 Ti utilizzando le librerie CUDA 11.2 e CUDNN 8.1.0.7.
1.1. Installazione di Python e librerie
Se non hai Python, dovresti installarlo. Abbiamo utilizzato la versione 3.9.16.
Inoltre, installa le librerie (se stai utilizzando Conda/Anaconda, esegui questi comandi nel prompt di Anaconda):
python.exe -m pip install --upgrade pip pip install --upgrade pandas pip install --upgrade scikit-learn pip install --upgrade matplotlib pip install --upgrade tqdm pip install --upgrade metatrader5 pip install --upgrade onnx==1.12 pip install --upgrade tf2onnx pip install --upgrade tensorflow==2.10.0
1.2. Controllo della versione TensorFlow e della GPU
Il codice seguente controlla la versione di TensorFlow installata e verifica se è possibile utilizzare la GPU per calcolare i modelli:
#check tensorflow version print(tf.__version__) #check GPU support print(len(tf.config.list_physical_devices('GPU'))>0)
Se la versione richiesta è installata correttamente, vedrai il seguente risultato:
True
Abbiamo utilizzato uno script Python per creare e addestrare il modello. Le fasi di questo processo sono brevemente descritte di seguito.
1.3. Costruzione e addestramento del modello
Lo script inizia importando le librerie Python che verranno utilizzate nel modello.
#Python libraries import matplotlib.pyplot as plt import MetaTrader5 as mt5 import tensorflow as tf import numpy as np import pandas as pd import tf2onnx from sklearn.model_selection import train_test_split from sys import argv
Controlla la versione di TensorFlow e la disponibilità della GPU:
#check tensorflow version print(tf.__version__)
2.10.0
#check GPU support print(len(tf.config.list_physical_devices('GPU'))>0)
True
Inizializza MetaTrader 5 per le operazioni da Python:
#initialize MetaTrader5 for history data if not mt5.initialize(): print("initialize() failed, error code =",mt5.last_error()) quit()
Informazioni sul terminale MetaTrader 5:
#show terminal info terminal_info=mt5.terminal_info() print(terminal_info)
TerminalInfo(community_account=True, community_connection=True, connesso=True, dlls_allowed=False, trade_allowed=False, tradeapi_disabled=False, email_enabled=False, ftp_enabled=False, notifications_enabled=False, mqid=False, build=3640, maxbars=100000, codepage=0, ping_last=58768, community_balance=1.0, retransmission=0.015296317559440137, company='MetaQuotes Software Corp.', name='MetaTrader 5', language='English', path='C:\\Program Files\\MetaTrader 5', data_path='C:\\Users\\user\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075', commondata_path='C:\\Users\\user\\AppData\\Roaming\\MetaQuotes\\Terminal\\Common')
#show file path file_path=terminal_info.data_path+"\\MQL5\\Files\\" print(file_path)
Stampa il percorso per salvare il modello (in questo esempio, lo script viene eseguito in Jupyter Notebook):
#data path to save the model data_path=argv[0] last_index=data_path.rfind("\\")+1 data_path=data_path[0:last_index] print("data path to save onnx model",data_path)
percorso dati per salvare il modello onnx C:\Users\user\AppData\Roaming\Python\Python39\site-packages\
Preparare le date per richiedere i dati storici. Nel nostro esempio, richiediamo 120 barre EURUSD H1 dalla data corrente:
#set start and end dates for history data from datetime import timedelta,datetime end_date = datetime.now() start_date = end_date - timedelta(days=120) #print start and end dates print("data start date=",start_date) print("data end date=",end_date)
data end date= 28-03-2023 12:28:39.870685
Richiedi dati storici EURUSD:
#get EURUSD rates (H1) from start_date to end_date eurusd_rates = mt5.copy_rates_range("EURUSD", mt5.TIMEFRAME_H1, start_date, end_date)
Output dei dati scaricati:
#check print(eurusd_rates)

#create dataframe df = pd.DataFrame(eurusd_rates)
Mostra l'inizio e la fine del dataframe:
#show dataframe head df.head()
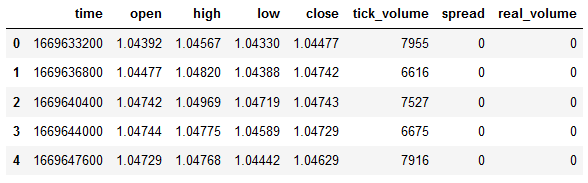
#show dataframe tail df.tail()
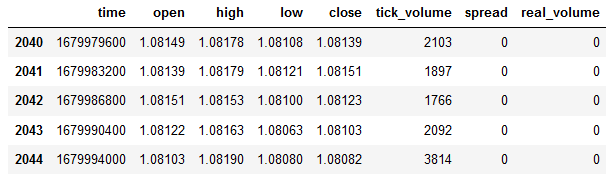
#show dataframe shape (the number of rows and columns in the data set) df.shape
(2045, 8)
Seleziona solo i prezzi di chiusura:
#prepare close prices only data = df.filter(['close']).values
output dei dati:
#show close prices plt.figure(figsize = (18,10)) plt.plot(data,'b',label = 'Original') plt.xlabel("Hours") plt.ylabel("Price") plt.title("EURUSD_H1") plt.legend()

Ridimensiona i dati del prezzo di origine nell'intervallo [0,1] utilizzando MinMaxScaler:
#scale data using MinMaxScaler from sklearn.preprocessing import MinMaxScaler scaler=MinMaxScaler(feature_range=(0,1)) scaled_data = scaler.fit_transform(data)
Il primo 80% dei dati verrà utilizzato per l’addestramento.
#training size is 80% of the data training_size = int(len(scaled_data)*0.80) print("training size:",training_size)
dimensione dell'addestramento: 1636
#create train data and check size train_data_initial = scaled_data[0:training_size,:] print(len(train_data_initial))
1636
#create test data and check size test_data_initial= scaled_data[training_size:,:1] print(len(test_data_initial))
409
La seguente funzione crea sequenze di addestramento:
#split a univariate sequence into samples def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): #find the end of this pattern end_ix = i + n_steps #check if we are beyond the sequence if end_ix > len(sequence)-1: break #gather input and output parts of the pattern seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return np.array(X), np.array(y)
Costruisci i set:
#split into samples time_step = 120 x_train, y_train = split_sequence(train_data_initial, time_step) x_test, y_test = split_sequence(test_data_initial, time_step) #reshape input to be [samples, time steps, features] which is required for LSTM x_train =x_train.reshape(x_train.shape[0],x_train.shape[1],1) x_test = x_test.reshape(x_test.shape[0],x_test.shape[1],1)
Tensor shapes per l'addestramento e il test:
#show shape of train data x_train.shape
(1516, 120, 1)
#show shape of test data x_test.shape
(289, 120, 1)
#import keras libraries for the model import math from keras.models import Sequential from keras.layers import Dense,Activation,Conv1D,MaxPooling1D,Dropout from keras.layers import LSTM from keras.utils.vis_utils import plot_model from keras.metrics import RootMeanSquaredError as rmse from keras import optimizers
Imposta il modello:
#define the model model = Sequential() model.add(Conv1D(filters=256, kernel_size=2,activation='relu',padding = 'same',input_shape=(120,1))) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(100, return_sequences = True)) model.add(Dropout(0.3)) model.add(LSTM(100, return_sequences = False)) model.add(Dropout(0.3)) model.add(Dense(units=1, activation = 'sigmoid')) model.compile(optimizer='adam', loss= 'mse' , metrics = [rmse()])
Mostra le proprietà del modello:
#show model model.summary()

Addestramento del modello:
#measure time import time time_calc_start = time.time() #fit model with 300 epochs history=model.fit(x_train,y_train,epochs=300,validation_data=(x_test,y_test),batch_size=32,verbose=1) #calculate time fit_time_seconds = time.time() - time_calc_start print("fit time =",fit_time_seconds," seconds.")
Epoch 1/300
48/48 [==============================] - 8s 49ms/step - loss: 0.0129 - root_mean_squared_error: 0,1136 - val_loss: 0.0065 - val_root_mean_squared_error: 0,0804
...
Epoch 299/300
48/48 [==============================] - 2s 35ms/step - loss: 4.5197e-04 - root_mean_squared_error: 0,0213 - val_loss: 4.2535e-04 - val_root_mean_squared_error: 0,0206
Epoch 300/300
48/48 [==============================] - 2s 32ms/step - loss: 4.2967e-04 - root_mean_squared_error: 0,0207 - val_loss: 4.4040e-04 - val_root_mean_squared_error: 0,0210
tempo di adattamento = 467,4918096065521 secondi.
La formazione è durata circa 8 minuti.
#show training history keys history.history.keys()
Dinamiche di ottimizzazione nei set di dati di training e testing:
#show iteration-loss graph for training and validation plt.figure(figsize = (18,10)) plt.plot(history.history['loss'],label='Training Loss',color='b') plt.plot(history.history['val_loss'],label='Validation-loss',color='g') plt.xlabel("Iteration") plt.ylabel("Loss") plt.title("LOSS") plt.legend()

#show iteration-rmse graph for training and validation plt.figure(figsize = (18,10)) plt.plot(history.history['root_mean_squared_error'],label='Training RMSE',color='b') plt.plot(history.history['val_root_mean_squared_error'],label='Validation-RMSE',color='g') plt.xlabel("Iteration") plt.ylabel("RMSE") plt.title("RMSE") plt.legend()

#evaluate training data model.evaluate(x_train,y_train, batch_size = 32)
[0.00029911252204328775, 0.01729486882686615]
#evaluate testing data model.evaluate(x_test,y_test, batch_size = 32)
10/10 [==============================] - 0s 31ms/step - loss: 4.4040e-04 - root_mean_squared_error: 0,0210
[0.00044039846397936344, 0.020985672250390053]
Formare la previsione sul set di dati di addestramento:
#prediction using training data train_predict = model.predict(x_train) plot_y_train = y_train.reshape(-1,1)
Genera i grafici effettivi e previsti per l'intervallo di addestramento:
#show actual vs predicted (training) graph plt.figure(figsize=(18,10)) plt.plot(scaler.inverse_transform(plot_y_train),color = 'b', label = 'Original') plt.plot(scaler.inverse_transform(train_predict),color='red', label = 'Predicted') plt.title("Prediction Graph Using Training Data") plt.xlabel("Hours") plt.ylabel("Price") plt.legend() plt.show()

Formare la previsione sul set di dati di test:
#prediction using testing data test_predict = model.predict(x_test) plot_y_test = y_test.reshape(-1,1)
11/11 [==============================] - 0s 11ms/step
Per calcolare le metriche, dobbiamo convertire i dati dall'intervallo [0,1]. Ancora una volta, utilizziamo MinMaxScaler.
#calculate metrics from sklearn import metrics from sklearn.metrics import r2_score #transform data to real values value1=scaler.inverse_transform(plot_y_test) value2=scaler.inverse_transform(test_predict) #calc score score = np.sqrt(metrics.mean_squared_error(value1,value2)) print("RMSE : {}".format(score)) print("MSE :", metrics.mean_squared_error(value1,value2)) print("R2 score :",metrics.r2_score(value1,value2))
RMSE: 0,0015151631684117558
MSE: 2.295719426911551e-06
Punteggio R2: 0,9683533377809039
#show actual vs predicted (testing) graph plt.figure(figsize=(18,10)) plt.plot(scaler.inverse_transform(plot_y_test),color = 'b', label = 'Original') plt.plot(scaler.inverse_transform(test_predict),color='g', label = 'Predicted') plt.title("Prediction Graph Using Testing Data") plt.xlabel("Hours") plt.ylabel("Price") plt.legend() plt.show()

Esporta il modello in un file onnx:
# save model to ONNX output_path = data_path+"model.eurusd.H1.120.onnx" onnx_model = tf2onnx.convert.from_keras(model, output_path=output_path) print(f"model saved to {output_path}") output_path = file_path+"model.eurusd.H1.120.onnx" onnx_model = tf2onnx.convert.from_keras(model, output_path=output_path) print(f"saved model to {output_path}") # finish mt5.shutdown()
Il codice completo dello script Python è allegato all'articolo in un Jupyter Notebook.
Nell'articolo A CNN-LSTM-Based Model to Forecast Stock Prices, il miglior risultato R^2=0.9646 è stato ottenuto per i modelli con architettura CNN-LSTM. Nel nostro esempio, la rete CNN-LSTM ha generato il miglior risultato di R^2=0,9684. In base ai risultati, modelli di questo tipo possono essere efficienti nella risoluzione di problemi di previsione.
Abbiamo considerato un esempio di uno script Python che costruisce e addestra modelli CNN-LSTM per prevedere le serie temporali finanziarie.
2. Utilizzo del modello in MetaTrader 5
2.1. Buono a sapersi prima di iniziare
Esistono due modi per creare un modello: È possibile utilizzare OnnxCreate per creare un modello da un file onnx o OnnxCreateFromBuffer per crearlo da un array di dati.
Se un modello ONNX viene utilizzato come risorsa in un EA, sarà necessario ricompilare l'EA ogni volta che si modifica il modello.
Non tutti i modelli hanno dimensioni di ingresso e/o di uscita del tensore completamente definite. Questa è normalmente la prima dimensione responsabile della dimensione del pacchetto. Prima di eseguire un modello, è necessario specificare in modo esplicito le dimensioni utilizzando le funzioni OnnxSetInputShape e OnnxSetOutputShape . I dati di input del modello dovrebbero essere preparati nello stesso modo in cui è stato fatto durante l'addestramento del modello.
Per i dati di input e output, si consiglia di utilizzare array, matrici e/o vettori dello stesso tipo che sono stati utilizzati nel modello. In questo caso, non sarà necessario convertire i dati durante l'esecuzione del modello. Se i dati non possono essere rappresentati nel tipo richiesto, i dati verranno convertiti automaticamente.
Utilizza OnnxRun per inferenza (eseguire) il tuo modello. Tieni presente che un modello può essere eseguito più volte. Dopo aver utilizzato il modello, rilascialo utilizzando la funzione OnnxRelease .
Documentazione completa per i modelli ONNX in MQL5.
2.2. Leggere un file onnx e ottenere informazioni su input e output
Per utilizzare il nostro modello, dobbiamo conoscere la posizione del modello, il tipo e la forma dei dati di input, come il tipo e la forma dei dati di output. Secondo lo script creato in precedenza, model.eurusd.H1.120.onnx si trova nella stessa cartella con lo script Python che ha generato il file onnx. L'input è float32, 120 prezzi di chiusura normalizzati (per lavorare con dimensioni batch pari a 1); l'output è float32, che è un prezzo normalizzato previsto dal modello.
Abbiamo anche creato il file onnx nella cartella MQL5\Files per ottenere i dati di input e output del modello utilizzando uno script MQL5.
//+------------------------------------------------------------------+ //| OnnxModelInfo.mq5 | //| Copyright 2023, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #define UNDEFINED_REPLACE 1 //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string file_names[]; if(FileSelectDialog("Open ONNX model",NULL,"ONNX files (*.onnx)|*.onnx|All files (*.*)|*.*",FSD_FILE_MUST_EXIST,file_names,NULL)<1) return; PrintFormat("Create model from %s with debug logs",file_names[0]); long session_handle=OnnxCreate(file_names[0],ONNX_DEBUG_LOGS); if(session_handle==INVALID_HANDLE) { Print("OnnxCreate error ",GetLastError()); return; } OnnxTypeInfo type_info; long input_count=OnnxGetInputCount(session_handle); Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(session_handle,i); Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(session_handle,i,type_info)) PrintTypeInfo(i,"input",type_info); } long output_count=OnnxGetOutputCount(session_handle); Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(session_handle,i); Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(session_handle,i,type_info)) PrintTypeInfo(i,"output",type_info); } OnnxRelease(session_handle); } //+------------------------------------------------------------------+ //| PrintTypeInfo | //+------------------------------------------------------------------+ void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info) { Print(" type ",EnumToString(type_info.type)); Print(" data type ",EnumToString(type_info.element_type)); if(type_info.dimensions.Size()>0) { bool dim_defined=(type_info.dimensions[0]>0); string dimensions=IntegerToString(type_info.dimensions[0]); for(long n=1; n<type_info.dimensions.Size(); n++) { if(type_info.dimensions[n]<=0) dim_defined=false; dimensions+=", "; dimensions+=IntegerToString(type_info.dimensions[n]); } Print(" shape [",dimensions,"]"); //--- not all dimensions defined if(!dim_defined) PrintFormat(" %I64d %s shape must be defined explicitly before model inference",num,layer); //--- reduce shape uint reduced=0; long dims[]; for(long n=0; n<type_info.dimensions.Size(); n++) { long dimension=type_info.dimensions[n]; //--- replace undefined dimension if(dimension<=0) dimension=UNDEFINED_REPLACE; //--- 1 can be reduced if(dimension>1) { ArrayResize(dims,reduced+1); dims[reduced++]=dimension; } } //--- all dimensions assumed 1 if(reduced==0) { ArrayResize(dims,1); dims[reduced++]=1; } //--- shape was reduced if(reduced<type_info.dimensions.Size()) { dimensions=IntegerToString(dims[0]); for(long n=1; n<dims.Size(); n++) { dimensions+=", "; dimensions+=IntegerToString(dims[n]); } string sentence=""; if(!dim_defined) sentence=" if undefined dimension set to "+(string)UNDEFINED_REPLACE; PrintFormat(" shape of %s data can be reduced to [%s]%s",layer,dimensions,sentence); } } else PrintFormat("no dimensions defined for %I64d %s",num,layer); } //+------------------------------------------------------------------+
Nella finestra di selezione file, abbiamo selezionato il file onnx salvato in MQL5\Files, creato un modello dal file utilizzando OnnxCreate e ottenuto le seguenti informazioni.
Create model from model.eurusd.H1.120.onnx with debug logs ONNX: Creating and using per session threadpools since use_per_session_threads_ is true ONNX: Dynamic block base set to 0 ONNX: Initializing session. ONNX: Adding default CPU execution provider. ONNX: Total shared scalar initializer count: 0 ONNX: Total fused reshape node count: 0 ONNX: Removing NodeArg 'Gather_out0'. It is no longer used by any node. ONNX: Removing NodeArg 'Gather_token_1_out0'. It is no longer used by any node. ONNX: Total shared scalar initializer count: 0 ONNX: Total fused reshape node count: 0 ONNX: Removing initializer 'sequential/conv1d/Conv1D/ExpandDims_1:0'. It is no longer used by any node. ONNX: Use DeviceBasedPartition as default ONNX: Saving initialized tensors. ONNX: Done saving initialized tensors ONNX: Session successfully initialized. model has 1 input(s) 0 input name is conv1d_input type ONNX_TYPE_TENSOR data type ONNX_DATA_TYPE_FLOAT shape [-1, 120, 1] 0 input shape must be defined explicitly before model inference shape of input data can be reduced to [120] if undefined dimension set to 1 model has 1 output(s) 0 output name is dense type ONNX_TYPE_TENSOR data type ONNX_DATA_TYPE_FLOAT shape [-1, 1] 0 output shape must be defined explicitly before model inference shape of output data can be reduced to [1] if undefined dimension set to 1
Dato che la modalità debug è stata abilitata
long session_handle=OnnxCreate(file_names[0],ONNX_DEBUG_LOGS);
abbiamo i log con il prefisso ONNX.
Vediamo che il modello effettivamente ha un input e un output. Qui, la prima dimensione del tensore di input e la prima dimensione del tensore di output non sono definite. Si presuppone che queste dimensioni siano responsabili della dimensione del batch. Pertanto, prima di inferire il modello, dobbiamo specificare esplicitamente con quali dimensioni lavoreremo (OnnxSetInputShape e OnnxSetOutputShape). Di solito nel modello viene inserito un solo set di dati. Un esempio dettagliato è fornito nel paragrafo successivo "Un esempio di utilizzo di un modello ONNX in un EA per il trading".
Quando si preparano i dati, non è necessario utilizzare un array con dimensioni [1, 120, 1]. Possiamo inserire un array unidimensionale o un vettore di 120 elementi.
2.3. Un esempio di utilizzo di un modello ONNX in un EA per il trading
Dichiarazioni e definizioni
#include <Trade\Trade.mqh> input double InpLots = 1.0; // Lots amount to open position #resource "Python/model.120.H1.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 120 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; float ExtMin=0.0; float ExtMax=0.0; CTrade ExtTrade; //--- price movement prediction #define PRICE_UP 0 #define PRICE_SAME 1 #define PRICE_DOWN 2
Funzione OnInit
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("model must work with EURUSD,H1"); return(INIT_FAILED); } //--- create a model from static buffer ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ",GetLastError()); return(INIT_FAILED); } //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) const long input_shape[] = {1,SAMPLE_SIZE,1}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("OnnxSetInputShape error ",GetLastError()); return(INIT_FAILED); } //--- since not all sizes defined in the output tensor we must set them explicitly //--- first index - batch size, must match the batch size of the input tensor //--- second index - number of predicted prices (we only predict Close) const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("OnnxSetOutputShape error ",GetLastError()); return(INIT_FAILED); } //--- return(INIT_SUCCEEDED); }
Lavoriamo solo con EURUSD, H1, perché utilizziamo i dati del simbolo/periodo corrente.
Il nostro modello è incluso nell'EA come risorsa. L'EA è completamente autosufficiente e non richiede la lettura di un file onnx esterno. Viene creato un modello dall'array della risorsa.
Le forme dei dati di input e output devono essere definite in modo esplicito.
La funzione OnTick:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- check new day if(TimeCurrent()>=ExtNextDay) { GetMinMax(); //--- set next day time ExtNextDay=TimeCurrent(); ExtNextDay-=ExtNextDay%PeriodSeconds(PERIOD_D1); ExtNextDay+=PeriodSeconds(PERIOD_D1); } //--- check new bar if(TimeCurrent()<ExtNextBar) return; //--- set next bar time ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); //--- check min and max double close=iClose(_Symbol,_Period,0); if(ExtMin>close) ExtMin=close; if(ExtMax<close) ExtMax=close; //--- predict next price PredictPrice(); //--- check trading according to prediction if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); }
Definiamo l'inizio di un nuovo giorno. L'inizio del giorno viene utilizzato per aggiornare i valori Minimo e Massimo della sequenza di 120 giorni per normalizzare i prezzi nella sequenza di 120 ore. Il modello è stato addestrato in queste condizioni, che dobbiamo seguire durante la preparazione dei dati di input.
//+------------------------------------------------------------------+ //| Get minimal and maximal Close for last 120 days | //+------------------------------------------------------------------+ void GetMinMax(void) { vectorf close; close.CopyRates(_Symbol,PERIOD_D1,COPY_RATES_CLOSE,0,SAMPLE_SIZE); ExtMin=close.Min(); ExtMax=close.Max(); }
Se necessario, possiamo modificare Minimo e Massimo durante la giornata.
Funzione di previsione:
//+------------------------------------------------------------------+ //| Predict next price | //+------------------------------------------------------------------+ void PredictPrice(void) { static vectorf output_data(1); // vector to get result static vectorf x_norm(SAMPLE_SIZE); // vector for prices normalize //--- check for normalization possibility if(ExtMin>=ExtMax) { ExtPredictedClass=-1; return; } //--- request last bars if(!x_norm.CopyRates(_Symbol,_Period,COPY_RATES_CLOSE,1,SAMPLE_SIZE)) { ExtPredictedClass=-1; return; } float last_close=x_norm[SAMPLE_SIZE-1]; //--- normalize prices x_norm-=ExtMin; x_norm/=(ExtMax-ExtMin); //--- run the inference if(!OnnxRun(ExtHandle,ONNX_NO_CONVERSION,x_norm,output_data)) { ExtPredictedClass=-1; return; } //--- denormalize the price from the output value float predicted=output_data[0]*(ExtMax-ExtMin)+ExtMin; //--- classify predicted price movement float delta=last_close-predicted; if(fabs(delta)<=0.00001) ExtPredictedClass=PRICE_SAME; else { if(delta<0) ExtPredictedClass=PRICE_UP; else ExtPredictedClass=PRICE_DOWN; } }
Per prima cosa controlliamo se possiamo normalizzare. La normalizzazione è implementata come nella funzione Python MinMaxScaler.
#scale data from sklearn.preprocessing import MinMaxScaler scaler=MinMaxScaler(feature_range=(0,1)) scaled_data = scaler.fit_transform(data)
Quindi, il codice di normalizzazione è molto semplice e diretto.
I vettori per i dati di input e per la ricezione del risultato sono organizzati come statici. Ciò garantisce un buffer non ricollocabile che esiste per l'intera durata del programma. Pertanto, i tensori di input e output del modello ONNX non vengono ricreati ogni volta che eseguiamo il modello.
La funzione chiave è OnnxRun. Il flag ONNX_NO_CONVERSION indica che i dati di input e di output non devono essere convertiti poiché il tipo float MQL5 corrisponde esattamente a ONNX_DATA_TYPE_FLOAT. Il flag ONNX_DEBUG non è impostato.
Successivamente, denormalizziamo i dati ottenuti nel prezzo previsto e determiniamo la classe: se il prezzo salirà, scenderà o non cambierà.
La strategia di trading è semplice. All'inizio di ogni ora controlliamo la previsione del prezzo per la fine di quell'ora. Se il prezzo previsto sale, compriamo. Se il modello prevede un movimento al ribasso, vendiamo.
//+------------------------------------------------------------------+ //| Check for open position conditions | //+------------------------------------------------------------------+ void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; //--- check signals if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; // sell condition else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; // buy condition } //--- open position if possible according to signal if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) price=bid; else price=ask; ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,0.0,0.0); } } //+------------------------------------------------------------------+ //| Check for close position conditions | //+------------------------------------------------------------------+ void CheckForClose(void) { bool bsignal=false; //--- position already selected before long type=PositionGetInteger(POSITION_TYPE); //--- check signals if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) bsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) bsignal=true; //--- close position if possible if(bsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); //--- open opposite CheckForOpen(); } }
Ora controlliamo le prestazioni dell'EA nello Strategy Tester. Per testare l'EA dall'inizio dell'anno, il modello dovrebbe essere addestrato utilizzando dati precedenti. Perciò, abbiamo leggermente modificato lo script Python rimuovendo le parti inutilizzate e modificando la data di fine addestramento in modo che non si sovrapponga al periodo di test.
Lo script ONNX.eurusd.H1.120.Training.py si trova nella sottocartella Python e viene eseguito direttamente in MetaEditor. Il modello ONNX risultante verrà salvato nella stessa sottocartella Python e verrà utilizzato come risorsa durante la compilazione dell'EA.
# Copyright 2023, MetaQuotes Ltd. # https://www.mql5.com # python libraries import MetaTrader5 as mt5 import tensorflow as tf import numpy as np import pandas as pd import tf2onnx # input parameters inp_model_name = "model.eurusd.H1.120.onnx" inp_history_size = 120 if not mt5.initialize(): print("initialize() failed, error code =",mt5.last_error()) quit() # we will save generated onnx-file near our script to use as resource from sys import argv data_path=argv[0] last_index=data_path.rfind("\\")+1 data_path=data_path[0:last_index] print("data path to save onnx model",data_path) # set start and end dates for history data from datetime import timedelta, datetime #end_date = datetime.now() end_date = datetime(2023, 1, 1, 0) start_date = end_date - timedelta(days=inp_history_size) # print start and end dates print("data start date =",start_date) print("data end date =",end_date) # get rates eurusd_rates = mt5.copy_rates_range("EURUSD", mt5.TIMEFRAME_H1, start_date, end_date) # create dataframe df = pd.DataFrame(eurusd_rates) # get close prices only data = df.filter(['close']).values # scale data from sklearn.preprocessing import MinMaxScaler scaler=MinMaxScaler(feature_range=(0,1)) scaled_data = scaler.fit_transform(data) # training size is 80% of the data training_size = int(len(scaled_data)*0.80) print("Training_size:",training_size) train_data_initial = scaled_data[0:training_size,:] test_data_initial = scaled_data[training_size:,:1] # split a univariate sequence into samples def split_sequence(sequence, n_steps): X, y = list(), list() for i in range(len(sequence)): # find the end of this pattern end_ix = i + n_steps # check if we are beyond the sequence if end_ix > len(sequence)-1: break # gather input and output parts of the pattern seq_x, seq_y = sequence[i:end_ix], sequence[end_ix] X.append(seq_x) y.append(seq_y) return np.array(X), np.array(y) # split into samples time_step = inp_history_size x_train, y_train = split_sequence(train_data_initial, time_step) x_test, y_test = split_sequence(test_data_initial, time_step) # reshape input to be [samples, time steps, features] which is required for LSTM x_train =x_train.reshape(x_train.shape[0],x_train.shape[1],1) x_test = x_test.reshape(x_test.shape[0],x_test.shape[1],1) # define model from keras.models import Sequential from keras.layers import Dense, Activation, Conv1D, MaxPooling1D, Dropout, Flatten, LSTM from keras.metrics import RootMeanSquaredError as rmse model = Sequential() model.add(Conv1D(filters=256, kernel_size=2, activation='relu',padding = 'same',input_shape=(inp_history_size,1))) model.add(MaxPooling1D(pool_size=2)) model.add(LSTM(100, return_sequences = True)) model.add(Dropout(0.3)) model.add(LSTM(100, return_sequences = False)) model.add(Dropout(0.3)) model.add(Dense(units=1, activation = 'sigmoid')) model.compile(optimizer='adam', loss= 'mse' , metrics = [rmse()]) # model training for 300 epochs history = model.fit(x_train, y_train, epochs = 300 , validation_data = (x_test,y_test), batch_size=32, verbose=2) # evaluate training data train_loss, train_rmse = model.evaluate(x_train,y_train, batch_size = 32) print(f"train_loss={train_loss:.3f}") print(f"train_rmse={train_rmse:.3f}") # evaluate testing data test_loss, test_rmse = model.evaluate(x_test,y_test, batch_size = 32) print(f"test_loss={test_loss:.3f}") print(f"test_rmse={test_rmse:.3f}") # save model to ONNX output_path = data_path+inp_model_name onnx_model = tf2onnx.convert.from_keras(model, output_path=output_path) print(f"saved model to {output_path}") # finish mt5.shutdown()
Test di un EA basato sul modello ONNX
Ora testiamo l'EA sui dati storici nello Strategy Tester. Specifichiamo gli stessi parametri che abbiamo utilizzato per addestrare il modello: il simbolo EURUSD e il timeframe H1.
L'intervallo di prova non comprende il periodo di addestramento: decorre dall'inizio dell'anno (01/01/2023).

Secondo la strategia, i segnali vengono controllati una volta, all'inizio di ogni ora (l'EA monitora l’inizio di una nuova barra), quindi la modalità di modellazione del tick non ha importanza. OnTick verrà elaborato nel tester una volta per barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- check new day if(TimeCurrent()>=ExtNextDay) { GetMinMax(); //--- set next day time ExtNextDay=TimeCurrent(); ExtNextDay-=ExtNextDay%PeriodSeconds(PERIOD_D1); ExtNextDay+=PeriodSeconds(PERIOD_D1); } //--- check new bar if(TimeCurrent()<ExtNextBar) return; //--- set next bar time ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); //--- check min and max float close=(float)iClose(_Symbol,_Period,0); if(ExtMin>close) ExtMin=close; if(ExtMax<close) ExtMax=close; //--- predict next price PredictPrice(); //--- check trading according to prediction if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); }
Con questa elaborazione il test del trimestre dura solo pochi secondi. Di seguito sono riportati i risultati.

Ora, modifichiamo la strategia di trading per consentire l'apertura della posizione tramite un segnale e la chiusura tramite Stop Loss (SL) o Take Profit (TP).
input double InpLots = 1.0; // Lots amount to open position input bool InpUseStops = true; // Use stops in trading input int InpTakeProfit = 500; // TakeProfit level input int InpStopLoss = 500; // StopLoss level //+------------------------------------------------------------------+ //| Check for open position conditions | //+------------------------------------------------------------------+ void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; //--- check signals if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; // sell condition else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; // buy condition } //--- open position if possible according to signal if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } //+------------------------------------------------------------------+ //| Check for close position conditions | //+------------------------------------------------------------------+ void CheckForClose(void) { //--- position should be closed by stops if(InpUseStops) return; bool bsignal=false; //--- position already selected before long type=PositionGetInteger(POSITION_TYPE); //--- check signals if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) bsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) bsignal=true; //--- close position if possible if(bsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); //--- open opposite CheckForOpen(); } }
InpUseStops = true, il che significa che i livelli SL e TP sono impostati all'apertura della posizione.

I risultati dei test con i livelli SL/TP per lo stesso periodo:

Il codice sorgente completo dell'EA e il modello addestrato (fino all'inizio dell'anno 2023) sono forniti in allegato.
Conclusioni
L'articolo mostra che non c'è nulla di difficile nell'utilizzare i modelli ONNX nei programmi MQL5. In realtà l'applicazione dei modelli è la parte più semplice, mentre è molto più difficile ottenere un modello ONNX adeguato.
Tieni presente che il modello utilizzato nell'articolo viene fornito solo a scopo dimostrativo, per mostrare come lavorare con i modelli ONNX utilizzando il linguaggio MQL5. L'Expert Advisor presentato in questo articolo non è destinato al trading reale.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/12373
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.

 Sviluppare un Expert Advisor per il trading da zero (Parte 23): Nuovo sistema di ordini (VI)
Sviluppare un Expert Advisor per il trading da zero (Parte 23): Nuovo sistema di ordini (VI)
 Sviluppare un Expert Advisor per il trading da zero (Parte 22): Nuovo sistema di ordini (V)
Sviluppare un Expert Advisor per il trading da zero (Parte 22): Nuovo sistema di ordini (V)
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Sbagliato: l'etichetta contiene i valori della classe e il tensore contiene le probabilità. Quindi la dimensione di output è essenzialmente 2,2, ma dato che la struttura viene restituita, si dovrebbe mettere 1.
Grazie
Grazie
Il preprocessing, che tu non rispetti, serve a questo :) a separare prima i grani dalla pula, e poi ad addestrarla a prevedere i grani separati.
Se la preelaborazione è buona, anche l'output non è del tutto scadente.
C'è qualche possibilità di aggiustare questo script per farlo funzionare con le nuove versioni di python (3.10-3.12)?
Ho un sacco di problemi nel cercare di farlo funzionare con la 3.9.
tx