Econometria: previsione a un passo avanti
Utilizzando l'indicatore KotirOut allegato all'articolo 2, ho campionato su D1
DATE, Kotir.
2011.08.01 00:00,1.4361
2011.08.02 00:00,1.4254
2011.08.03 00:00,1.4188
2011.08.04 00:00,1.4361
2011.08.05 00:00,1.4092
2011.08.08 00:00,1.4368
2011.08.09 00:00,1.4164
2011.08.10 00:00,1.4392
2011.08.11 00:00,1.4161
2011.08.12 00:00,1.4238
.
.
.
11.11.01 00:00,1.3842
2011.11.02 00:00,1.3662
2011.11.03 00:00,1.3725
2011.11.04 00:00,1.3824
2011.11.06 00:00,1.3828
2011.11.07 00:00,1.3816
2011.11.08 00:00,1.3766
2011.11.09 00:00,1.383
Ci sono 76 osservazioni in totale. L'ultima data è quella corrente. Avremo le previsioni per domani, 10 novembre.
Equazione di regressione:
Equazione di stima:
=========================
KOTIR = C(1)*HP1(-1) + C(2)*HP1_D(-1) + C(3)*HP1_D(-2)
Coefficienti sostituiti:
=========================
KOTIR = 0.999499248852*HP1(-1) - 0.0151635132798*HP1_D(-1) - 0.176713388909*HP1_D(-2)
Eseguiamo il programma MOD2_T in EViews e otteniamo il risultato:

Quindi: la previsione di domani dalle 00:00 hp 1.3798
Ma c'è una serie di difetti significativi: l'errore di previsione è di 97 pips. Un'esecuzione di prova ha dato cattivi risultati: Fattore di profitto = 0,89
Il risultato è disgustoso e dobbiamo cercare le ragioni.
Guardiamo i risultati della stima della regressione:
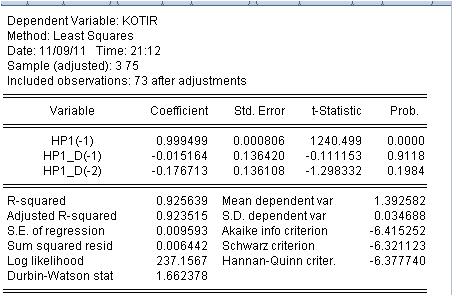
Bene. Non c'è voluto molto per scavare. La probabilità che gli ultimi due coefficienti siano uguali a zero è molto alta, cioè non possiamo rifiutare l'ipotesi che gli ultimi due coefficienti siano uguali a zero.
Questa equazione di regressione non va bene e deve essere cambiata. A proposito, si basa sull'indicatore Hedrick-Prescott. Non ha senso discutere la redditività di questo modello.
Aspetto suggerimenti.
Penso che dobbiamo prima scoprire l'argomento minimo richiesto di f(x). Può risultare che solo i prezzi del periodo attuale non sono sufficienti. Possiamo provare un altro approccio, riscriviamo la tua equazione f(x)=a*X1+b*X2+c*X3.... Ora useremo la genetica per trovare il massimo ottimizzando i coefficienti a,b,c.
Mi sembra che il suo approccio non sia molto buono. Cercate di prendere la parte esplicitamente piatta del grafico. Sembra che il prezzo in questa zona sia vicino a una variabile casuale distribuita normalmente.
faa1947:
Итак первый прогноз.
A proposito, si basa sull'indicatore Hedrick-Prescott. Non ha senso discutere la redditività di questo modello.
Sto aspettando un suggerimento.
Stranamente non hai modo di liquidare questo X-P... anche se è inutile.... ti stai aggrappando a questo H-P come se fossi ipnotizzato.... e va avanti da un po' di tempo ormai...
Ecco un suggerimento: se il prossimo modello non funziona, gettatelo nella spazzatura - senza pietà o rimpianto. Considerate altre opzioni - vi darà la possibilità di vedere le somiglianze e le differenze, le sottili sfumature.
Lo so per esperienza, e posso dirvi che in futuro potreste tornare su alcuni modelli precedentemente scartati - ma da una nuova prospettiva.
Qual è l'essenza della ST dell'articolo 2? Si prevede che il prezzo torni al valore smussato?
Estrapolato lisciato + rumore
Penso che dobbiamo prima scoprire l'argomento minimo richiesto di f(x). Potrebbe risultare che solo i prezzi del periodo attuale non sono sufficienti. Possiamo provare un altro approccio, riscriviamo la tua equazione f(x)=a*X1+b*X2+c*X3.... Ora useremo la genetica per trovare il massimo ottimizzando i coefficienti a,b,c.
Mi sembra che il suo approccio non sia molto buono. Cercate di prendere la parte esplicitamente piatta del grafico. Sembra che il prezzo su questa parte sia vicino a una variabile casuale normalmente distribuita non credo sia possibile scrivere l'equazione per le prossime teste o code.
Prima di tutto è necessario trovare il minimo necessario degli argomenti f(x). Potrebbe risultare che solo i prezzi del periodo attuale non sono sufficienti.
Nei miei termini: le variabili mancano. Si dovrebbe indagare se ci sono variabili mancanti. Lo farò di seguito.
Mi sembra che il suo approccio non sia molto buono. Prova a prendere una sezione del grafico di un evidente piatto
L'idea è diversa: qualsiasi sezione. Adattare una regressione e poi prevedere per la prossima candela. Arriva una nuova candela, ci regoliamo di nuovo (spostiamo la finestra) e di nuovo prevediamo la prossima candela, ecc.
Hai perso la testa? Hai letto le notizie? (solo per prendere in giro la gente). Comprate! (3650 max)
Stranamente non hai modo di rinunciare a questo X-P... anche se non ha senso.... ti aggrappi a questo H-P come se fossi ipnotizzato.... e va avanti da molto tempo...
Hodrift non c'entra niente.
Il modello che usiamo ha un'idea: isolare la componente deterministica e aggiungervi del rumore
Ci sono altre idee, e tu? C'è del gas nell'appartamento? O hai delle idee, per favore, e ti mostrerò i calcoli.
Il risultato della previsione precedente.
Le previsioni erano per un corto - avere un corto - previsioni di successo!
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
L'articolo #2 con un titolo simile è stato pubblicato. Questo articolo è una continuazione dell'altro articolo #1. Questi articoli sono una breve panoramica dell'econometria.
Utilizzando questi articoli propongo ai membri del forum di lavorare collettivamente alla creazione di modelli econometrici per prevedere le quotazioni delle coppie di valute un passo avanti. La dimensione di un passo corrisponde al timeframe a cui è collegato l'Expert Advisor descritto nell'articolo #2.
Prenderò il modello presentato nell'articolo 2 e farò due previsioni: su H1 e D1. Vedremo il risultato. Poi, spero che il collettivo suggerisca miglioramenti a questo modello o ai propri modelli. Prenderò i modelli di qualcun altro e farò una previsione e posterò il risultato. Sono pronto a rispondere alle domande e a commentare i post man mano che vado avanti.
Il modello è una funzione arbitraria (regressione) della forma y = f(x1, x2, .... xn). La funzione y è, per esempio, la coppia EURUSD o qualsiasi altra coppia di valute. xi sono gli argomenti della funzione (variabili indipendenti, regressori) - qualsiasi altra quotazione disponibile nel terminale. Per esempio, registrare:
EURUSD EURUSD(-1) GBRUSD(-1)
significa che calcoliamo il valore di EURUSD per altre due coppie di valute, e prendiamo i valori precedenti di queste coppie in relazione alla funzione (variabile dipendente EURUSD). È ovvio che possiamo costruire un modello su una coppia di valute, sui suoi valori di ritardo - questo è un approccio classico dell'AT, e possiamo costruire modelli multivaluta - in contrasto con l'AT non c'è differenza in termini di complessità. Ma vedremo in tutta la sua gloria cos'è la correlazione e il suo valore nel trading.
I file in MQL4 e EViews sono allegati a questo articolo.