Есть ли закономерность в хаосе? Попробуем поискать! Машинное обучение на примере конкретной выборки. - страница 11
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
В том и дело, что лучше раза в 2, чем на 5000+ фичах.
Получается, что все остальные 5000+ фичей только ухудшают результат. Хотя если отбирать, то наверняка найдутся улучшающие.
Интересно сравнить, что ваша модель покажет на этих 2х.
У меня мат. ожидание чуть больше единицы, прибыль в пределах 5 тысяч, точность пишет 51% - т.е. результаты явно хуже.
Да и на выборке test получился убыток во всех 100 моделях.У меня мат. ожидание чуть больше единицы, прибыль в пределах 5 тысяч, точность пишет 51% - т.е. результаты явно хуже.
Да и на выборке test получился убыток во всех 100 моделях.А на первой - тоже сливает.
На второй выборке по Н1? На ней у меня улучшения.
А на первой - тоже сливает.
Да, про выборку H1 я говорю. Я же изначально обучаюсь на выборке train.csv, остановка по test.csv, ну и независимая проверка на exam.csv, так вот вариант с двумя столбцами сливает на выборке test.csv. Вчерашние варианты так же многие там лили, но были и те, что немного зарабатывали.
Так что там за чудо графики у Вас получились?А вот так валкинг форвардом с обучением на 20000 строках через 10000. Т.е. на графике не 2 года, а 5. Года 2 из них в просадке придется посидеть, потом еще год без прибыли, за счет этого средний выигрыш снова опустился до 0,00002 на сделку. Тоже для торговли не годится.
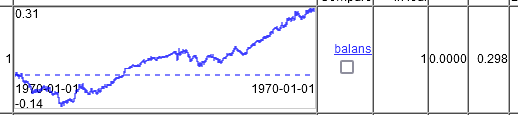
Только на 2 столбцах времени.
Те же настройки на всех 5000+ столбцах. Чуть получше. 0,00003 на сделку.
Прибыль 0,20600, в среднем по 0,00004 на сделку. Соизмеримо со спредом
Да, цифра уже внушительна получилась. Однако, целевая размечена на продажу, а там весь период exam на крупном ТФ продажа, думаю, что это так же искусственно улучшает результат.
Это больше чем 0,00002 по все столбцам, но как я говорил ранее " Спредом, проскальзываниями и т.п. весь выигрыш съестся". Териминал показывает минимальный спред на бар (т.е. в течении всего часа), а в момент сделки он может быть и 5 - 10 пт, а на новостях и 20 и выше.
Так разметка же у меня снимается на минутных барах, спреды расширяют обычно за какое то время т.е. в течении минуты вероятно всё время будет большой спред, или теперь не так? Я как то даже не разобрался, как спред в пятерке работает - по мне в четверке это удобней для тестов.
Надо искать модели с средним выигрышем хотя бы 0,00020 на сделку. Тогда в реальной торговле может 0,00010 и получится. Это для EURUSD, на др парах типа AUD NZD и 50 пт будет мало, там спреды 20-30 пт.
Согласен. Первая выборка в этой ветке дает мат ожидание в районе 30 пунктов. Поэтому я всё же придерживаюсь мнения, что разметка должна быть с умом.
Ну и опять же это лучший график на экзаминационной выборке. Как по трейну выбрать настройки, которые потом дадут лучший баланс на экзаменационной - вопрос без решения. Вы по тестовой выбираете. Я обучал на трейн+тест. По сути, то что у вас экзамен, у меня тест.
Думаю, что в начале надо добиться того, что бы порог отбора проходило большая часть выборки. Дальше, возможно есть смысл выбирать менее обученную модель из всех - в ней меньше подгонки.
А вот так валкинг форвардом с обучением на 20000 строках через 10000. Т.е. на графике не 2 года, а 5. Года 2 из них в просадке придется посидеть, потом еще год без прибыли, за счет этого средний выигрыш снова опустился до 0,00002 на сделку. Тоже для торговли не годится.
Только на 2 столбцах времени.
Те же настройки на всех 5000+ столбцах. Чуть получше. 0,00003 на сделку.
И всё же, получается, что от остальных предикторов так же может быть прок. Можно попробовать группами их добавлять, можно сперва просеять на корреляцию и чуть уменьшить.
По поводу мат ожидания, может в этой стратегии выгодней входить не по открытия свечи, а по отступу от цены открытия на те же 30 пунктов - редко же свечи без хвостов бывают.
Так разметка же у меня снимается на минутных барах, спреды расширяют обычно за какое то время т.е. в течении минуты вероятно всё время будет большой спред, или теперь не так? Я как то даже не разобрался, как спред в пятерке работает - по мне в четверке это удобней для тестов.
И на М1 тоже минимальный спред за время бара сохраняется. На ЕКН счетах почти все М1 бары имеют 0,00001...0,00002 редко больше. Все старшие бары строятся из М1, т.е. тот же мин. спред будет. К ним еще 4 пт. комиссии на круг надо самому прибавлять (у др. ДЦ может быть др. комиссия).
И всё же, получается, что от остальных предикторов так же может быть прок. Можно попробовать группами их добавлять, можно сперва просеять на корреляцию и чуть уменьшить.
Пожалуй, надо отбирать. Но если к 2м добавление 5000+ дает небольшое улучшение, возможно быстрее будет отобрать штук 10 полным перебором с обучением моделью. Думаю будет быстрее, чем ждать корелляцию сутками. Только надо автоматизировать переобучение в цикле прямо из терминала.
У катбуста разве нет DLL версии? DLL можно прямо из терминала вызывать. Статья с примерами тут была. https://www.mql5.com/ru/articles/18 и https://www.mql5.com/ru/articles/5798
Пожалуй, надо отбирать. Но если к 2м добавление 5000+ дает небольшое улучшение, возможно быстрее будет отобрать штук 10 полным перебором с обучением моделью. Думаю будет быстрее, чем ждать корелляцию сутками.
Да, лучше группами в начале - делать можно, допустим, 10 групп и обучаться их комбинациями, проводить оценку моделей, самые неудачные группы исключать, а с оставшимися делать перегруппировку, т.е. уменьшать число предикторов в группе и снова обучать. Я использовал такой метод раньше - эффект есть, но опять же не быстро.
Только надо автоматизировать переобучение в цикле прямо из терминала.
У катбуста разве нет DLL версии? DLL можно прямо из терминала вызывать. Статья с примерами тут была. https://www.mql5.com/ru/articles/18 и https://www.mql5.com/ru/articles/5798
Хех, хорошо бы получить полное управление обучением через терминал, но, как я понимаю, готового решения нет. Есть библиотека catboostmodel.dll , которая только применяет модель, но как её внедрить в MQL5 - не знаю. В теории можно конечно и для обучения сделать какой то интерфейс в виде библиотеки - код то открытый, но мне это явно не потянуть.
Да, лучше группами в начале - делать можно, допустим, 10 групп и обучаться их комбинациями, проводить оценку моделей, самые неудачные группы исключать, а с оставшимися делать перегруппировку, т.е. уменьшать число предикторов в группе и снова обучать. Я использовал такой метод раньше - эффект есть, но опять же не быстро.
Я другое предлагаю. Добавляем признаки в модель по одному. И отбираем лучшие.
1) Обучить 5000+ моделей на одном признаке: каждом из 5000+ признаков. Взять лучший по тесту.
2) Обучить (5000+ -1) моделей на 2-х признаках: на 1м лучшем признаке и( 5000+ -1) оставшихся. Найти второй лучший.
3) Обучить (5000+ -2) моделей на 3-х признаках: на 1м, 2м лучшем признаке и (5000+ -2) оставшихся. Найти третий лучший.
Повторяем пока модель улучшается.
У меня обычно после 6-10 добавленных признаков модель переставала улучшаться. Можно и просто до 10-20 или сколько вам хочется признаков добавить.
Но я думаю, что выбор признаков по тесту - является подгонкой модели под тестовый участок данных. Есть вариант отбора по трейну с весом 0,3 и тесту с весом 0,7. Но думаю тоже подгонка.
Хотелось сделать валкинг форвардом, тогда подгонка будет под множество тестовых участков, считать будет дольше, но мне представляется, что это лучший вариант.
Хотя у вас нет автоматизации по запуску катбуста... 50+ тыс раз будет сложно переобучить модели вручную для получения 10 признаков.Вот примерно поэтому я и предпочитаю свою поделку, а не Катбуст. Хоть и работает она раз в 5-10 медленнее Катбуста. У вас одна модель 3 мин считалась, у меня 22.
Я другое предлагаю. Добавляем признаки в модель по одному. И отбираем лучшие.
1) Обучить 5000+ моделей на одном признаке: каждом из 5000+ признаков. Взять лучший по тесту.
2) Обучить (5000+ -1) моделей на 2-х признаках: на 1м лучшем признаке и( 5000+ -1) оставшихся. Найти второй лучший.
3) Обучить (5000+ -2) моделей на 3-х признаках: на 1м, 2м лучшем признаке и (5000+ -2) оставшихся. Найти третий лучший.
Повторяем пока модель улучшается.
У меня обычно после 6-10 добавленных признаков модель переставала улучшаться. Можно и просто до 10-20 или сколько вам хочется признаков добавить.
Подходы разные могут быть - суть их одна в общем то, но минус конечно общий - слишком большие затраты на вычисления.
Но я думаю, что выбор признаков по тесту - является подгонкой модели под тестовый участок данных. Есть вариант отбора по трейну с весом 0,3 и тесту с весом 0,7. Но думаю тоже подгонка.
Хотелось сделать валкинг форвардом, тогда подгонка будет под множество тестовых участков, считать будет дольше, но мне представляется, что это лучший вариант.
Поэтому я ищу какое то рациональное зерно внутри признака, дабы обосновать его отбор. Пока остановился на периодичности повторения событий и смещении вероятности класса. В среднем эффект есть положительный, но такой метод оценивает фактически по первому сплиту, без учета корреспондирующих предикторов. Но, думаю попробуй и на второй сплит проверить таким же методом - убирая из выборки строки по показателям предиктора с сильной негативной предрасположенностью.
Хотя у вас нет автоматизации по запуску катбуста... 50+ тыс раз будет сложно переобучить модели вручную для получения 10 признаков.
Вот примерно поэтому я и предпочитаю свою поделку, а не Катбуст. Хоть и работает она раз в 5-10 медленнее Катбуста. У вас одна модель 3 мин считалась, у меня 22.
Всё же, прочтите мою статью... сейчас работает всё в виде полуавтомата - генерируются задания и запускается батник (в том числе задания на число признаков, которые нужно использовать при обучении, т.е. можно сгенерировать сразу все варианты и запустить). По сути нужно научить терминал запускать бат файл, что возможно я думаю, и контролировать окончание обучения, затем анализировать результат, и запускать другое задание по результатам.
Только за счет изменения темпов обучения смог получить две модели из 100, отвечающих поставленному критерию.
Первая.
Вторая.
Получается, что да, CatBoost способен на многое, но нужно видимо тюнить настройки агрессивней.
Вы эти модели отбираете по лучшей на тесте?
Или среди множества лучших на тесте - лучший и на экзамене?