Есть ли закономерность в хаосе? Попробуем поискать! Машинное обучение на примере конкретной выборки. - страница 18
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Рандом то фиксированный :) Там видимо хитро считается этот seed, т.е. возможно участвуют все предикторы допустимые для построения модели, а изменение их числа так же изменяет результат отбора.
Стартовый - фиксирован. А потом с каждым вызовом ГСЧ новое число появляется. Поэтому при разном числе предиктров и числа ГСЧ будут попадать не на тот же предиктор, что и при полном числе предикторов.
Почему это подгонка, точней в чём её видите? Я склоняюсь к тому, что выборка test отличается от exam больше, чем exam от train, т.е. там разные вероятностные распределения у предикторов.
Ну вы же берете лучшие по exam варианты, надеясь, что и на тесте они будут хороши. Предикторы отбираете по лучшему exam-у. Но они лучшие только для exam-а.
А что за метрика то "err_"?
err_ oob - ошибка на ООБ (у вас она exam), err_trn - ошибка на трейне. По формуле получим некую ошибку общую для обоих участков выборки.
Кстати, в обсуждении у нас поменялись местами test и exam. Поначалу планировались промежуточные проверки на test и окончательные на exam. Но по контексту понятно что есть что, хоть и поменяли названия.
Стартовый - фиксирован. А потом с каждым вызовом ГСЧ новое число появляется. Поэтому при разном числе предиктров и числа ГСЧ будут попадать не на тот же предиктор, что и при полном числе предикторов.
Не, там варианты воспроизводятся, если используемые предикторы для обучения оставить в том же количестве.
Ну вы же берете лучшие по exam варианты, надеясь, что и на тесте они будут хороши. Предикторы отбираете по лучшему exam-у. Но они лучшие только для exam-а.
Так получилось, что этот вариант был самый сбалансированный - с приличной прибылью по test и exam. Ниже на рисунке первично отобранная модель - "Было" и лучшая по сбалансированности после 10к обученей - "Стало". В целом результат лучше, а предикторов использовано меньше, значит отброшен шум. И тут вопрос в том, как избегать этого шума до начала обучения.
А так логика такая, что по test останавливается обучение, значит там с большей вероятностью должен быть положительный результат, чем в выборке, которая вообще не участвует в обучении, поэтому акцент и делается на последнюю.
err_ oob - ошибка на ООБ (у вас она exam), err_trn - ошибка на трейне. По формуле получим некую ошибку общую для обоих участков выборки.
Я про то, что не знаю как считается "err" - это Accuracy? И почему exam, а не test, ведь при базовом подходе exam мы как бы не будет знать.
Кстати, в обсуждении у нас поменялись местами test и exam. Поначалу планировались промежуточные проверки на test и окончательные на exam. Но по контексту понятно что есть что, хоть и поменяли названия.
У меня ничего не менялось (может где описался?) - так всё и есть - на train - обучение, test - контроль остановки обучения, и exam - участок не участвующий в каком либо роде при обучении.
Я как раз оцениваю эффективность подхода по средним показателям всех моделей, в том числе средней прибыли - её получить больше всё же вероятность, чем края с хорошим результатом.
И тут вопрос в том, как избегать этого шума до начала обучения.
Видимо никак. В этом и задача отсеять шум и научиться на правильных данных.
Я про то, что не знаю как считается "err" - это Accuracy?
Это способ получения комбинированной/суммарной ошибки на трейне с тестом. Суммировать можно любые ошибки. И (1-accuracy) и RMS и AvgRel и AvgCE и т.д.
У меня ничего не менялось (может где описался?) - так всё и есть - на train - обучение, test - контроль остановки обучения, и exam - участок не участвующий в каком либо роде при обучении.
Мне по картинкам это показалось, что exam имеется в виду test
Например тут
И в таблице выше результаты exam лучше теста. Это конечно вероятно, но скорее всего должно быть наоборот.
Видимо никак. В этом и задача отсеять шум и научиться на правильных данных.
Не, способ должен быть, иначе всё это бесполезно/рандомно.
Это способ получения комбинированной/суммарной ошибки на трейне с тестом. Суммировать можно любые ошибки. И (1-accuracy) и RMS и AvgRel и AvgCE и т.д.
Понял, ну это не работает на моих данных - должна быть корреляция хоть какая :)
Мне по картинкам это показалось, что exam имеется в виду test
Например тут
И в таблице выше результаты exam лучше теста.
Да, так получается, что на exam больше удается заработать моделькам - сам несколько не понимаю ситуацию до конца.
К сожалению, сейчас заметил, что в какой то момент я перемешал общую выборку (строки), и теперь в train попали примеры из 2022 года :(
Буду всё переделывать - думаю через пару недель будет результат - посмотрим, изменится ли общая картина.
К сожалению, сейчас заметил, что в какой то момент я перемешал общую выборку (строки), и теперь в train попали примеры из 2022 года :(
Буду всё переделывать - думаю через пару недель будет результат - посмотрим, изменится ли общая картина.
Да это без разницы, оценивали по exam или по test. Главное, что оценочный участок не использовался ни в обучении, ни в первичной оценке.
2 недели... я поражаюсь вашей выдержке. Меня и 3 часа расчетов раздражают... И в целом лет 5 уже на МО потратил, примерно как вы.
Короче, зарабатывать что-то начнем на пенсии ))) Может быть.
К сожалению, сейчас заметил, что в какой то момент я перемешал общую выборку (строки), и теперь в train попали примеры из 2022 года :(
У меня все склеено в 1 последовательный массив. И потом из него я отделяю нужное количество. Так ничего не перепутывается.
Да это без разницы, оценивали по exam или по test. Главное, что оценочный участок не использовался ни в обучении, ни в первичной оценке.
Я вот ещё думаю, как лучше делать при окончательном обучении - как Максим - для контроля беря доисторическую выборку, или лучше взять всю доступную выборку и ограничить число деревьев, как в среднем в лучших моделях.
2 недели... я поражаюсь вашей выдержке. Меня и 3 часа расчетов раздражают... И в целом лет 5 уже на МО потратил, примерно как вы.
Конечно всегда хочется получить результат побыстрей. Я стараюсь нагружать железо так, что бы мне вычисления не мешали заниматься другими делами - часто использую не основной рабочий компьютер. Параллельно можно реализовывать другие идеи в коде - придумываю быстрей, чем успеваю проверять в коде.
Короче, зарабатывать что-то начнем на пенсии ))) Может быть.
Согласен - перспектива печальная. Если бы я не видел прогресса в своих изысканиях, пусть и медленного, то наверное уже бы завершил работу.
У меня все склеено в 1 последовательный массив. И потом из него я отделяю нужное количество. Так ничего не перепутывается.
Да я конвертировал выборку в бинарный файл, и в скрипте поставил голочку случайно, видимо, отвечающую за перемешивание выборки -так то это не проблема, и для CatBoost требуется 3 отдельных выборки - не сделали они выделения по диапазону строк, хотя и имеется у них встроенная кросс валидация.
Я вот ещё думаю, как лучше делать при окончательном обучении - как Максим - для контроля беря доисторическую выборку, или лучше взять всю доступную выборку и ограничить число деревьев, как в среднем в лучших моделях.
Для меня предварительные обучения и тесты - возможность выбрать в среднем лучшие гиперпараметры (число деревьев и т.п.) и предикторы. А на них уже и без теста можно обучиться на трейне и сразу в торговлю.
Идея доисторической выборки будет работать если закономерности не меняются, возможно так и есть. Но есть риск, что поменяется. Поэтому предпочитаю не рисковать и тестить на будущей выборке.
Еще вопрос как давно была эта доисторическая выборка: полгода назад или 15 лет назад? Полгода - может и сойдет, а вот рынок 15 лет назад совсем не такой как сейчас. Но это не точно. Может и есть закономерности работающие десятки лет.Опишу полученные результаты по тому же алгоритму, что здесь описывал, но с выборкой не перемешанной, т.е. оставшейся в хронологическом порядке.
Единственно, что я изменил - теперь обучение 10000 моделей происходило не на всей выборке с исключением предикторов принимающих в ней участие, а на переформированной выборке в которой были удалены столбцы с исключенными предикторами, что в разу ускорило процесс обучения (видимо прокачка большого файла много отнимает времени). За счет этих изменений мне удалось последовательно проделать 6 шагов отсеивания предикторов.
Рисунок 1. Гистограмма прибыли по выборке exam после обучения 100 моделей на всех предикторах выборки.
Рисунок 2. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 1.
Рисунок 3. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 2.
Рисунок 4. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 3.
Рисунок 5. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 4.
Рисунок 6. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 5.
Рисунок 7. Гистограмма прибыли по выборке exam после обучения 10к моделей на отобранных предикторах выборки - шаг 6.
Рисунок 8. Таблица с характеристиками моделей которые были выбраны для формирования последующих выборок с уменьшением числа предикторов (признаков).
Рассмотрим, модель со следующими характеристиками, полученную на 6 шаге отбора предикторов.
Рисунок 9. Характеристики модели.
Рисунок 10. Визуализация модели по выборке exam в виде распределения по вероятности классификации - ось x - вероятности полученные от модели, а y - процент от всех выборки.
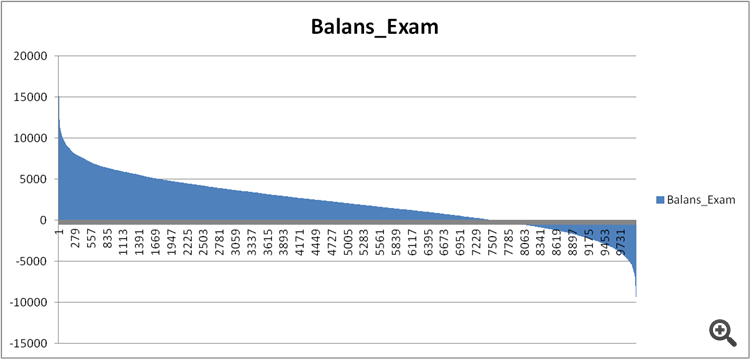
Рисунок 11. Баланс модели по выборке exam.
А теперь сравним предикторы в достаточно хорошей и крайне плохой моделях, полученными на 6 шаге отбора предикторов.
Рисунок 12. Сравнение характеристик моделей.
Быть может мы сейчас увидим, какие предикторы столь плохо влияют на финансовый результат и портят обучение?
Рисунок 13. Вес предикторов в двух моделях.
Как видно из рисунка 13, что предикторы используются почти все из имеющихся, за исключением одного, но я сомневаюсь, что в нём кроется корень зла. Значит дело не столько в использовании, сколько в последовательности использования при построении модели?
Я сделал сравнение двух таблиц, присвоив вместо индекса порядковый номер значимости и посмотрел на сколько по разному ранжирована эта значимость в моделях.
Рисунок 14. Таблица сравнения значимости (использования) предикторов в двух моделях.
Ну и гистограмма для лучшей визуализации - отклонения в минус означает, что предикторой второй (убыточной) модели применялся позже, а плюс - раньше.
Рисунок 15. Отклонения значимости предикторов в моделях.
Видно, что есть сильные отклонения, может в них дело, а как узнать/доказать? Возможно нужен какой то комплексный подход сравнения моделей с эталоном - есть идеи?
Есть ли какой то индекс запутанности для описания общего отклонения, возможно нужно с учетом значимости предикторов для первой модели - т.е. с коэффициентом понижающим?
Какие можно сделать выводы?
Я думаю так:
1. На прошлой выборке результаты были значительно лучше, предположу, что дело в информации, которая "просачилась" о событиях из будущего за счет перемешивания хронологии выборки. Будут модели устойчивей, полученные на перемешанной выборке или на обычной - вопрос.
2. Необходимо выстраивать структуру значимости предикторов для последующего их применения в моделях, т.е. кроме цифр нужно закладывать и логику, иначе разброс результатов моделей слишком велик даже на небольшом числе предикторов.