Aprendizado de máquina no trading: teoria, prática, negociação e não só - página 1258
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
um monte de fórmulas ((
Bem ) há um link para o pacote R. Eu próprio não uso R, eu compreendo as fórmulas.
se você usa R, experimente )
Bem ) há um link para o pacote R. Eu próprio não uso R, eu compreendo as fórmulas.
Se você usa R, tente )
O artigo desta manhã ainda está aberto: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
O facto mais decepcionante é que não consegui encontrar uma implementação Python deste algoritmo. Os autores criaram um pacote R(BayesTrees) que tinha alguns problemas óbvios - principalmente a falta de uma função "prever" - e outra implementação, mais amplamente utilizada, chamada bartMachine foi criada.
Se você tem experiência na implementação desta técnica ou conhece uma biblioteca Python, por favor deixe um link nos comentários!
Portanto, o primeiro pacote é inútil porque não pode prever.
O segundo link tem fórmulas de novo.
Aqui está uma árvore comum, fácil de entender. Tudo é simples e lógico. E sem fórmulas.
Talvez eu ainda não tenha chegado à libra. As árvores são apenas um caso especial de um enorme tópico Bayesiano, por exemplo, há muitos exemplos de livros e vídeos
Eu usei a otimização Bayesiana dos hiperparâmetros de NS de acordo com os artigos de Vladimir. Funciona bem.Como as árvores... existem redes neurais Bayesianas...
Inesperadamente!
NS trabalha com operações matemáticas + e * e pode construir qualquer indicador dentro de si mesmo, desde MA até filtros digitais.
Mas as árvores são divididas em partes direita e esquerda por simples if(x<v){ ramo esquerdo}else{ ramo direito}.
Ou também é if(x<v){sector esquerdo}else{ramo direito}?
Mas se há muitas variáveis a optimizar, é demasiado longo.
Inesperadamente!
NS trabalha com operações matemáticas + e * e pode construir qualquer indicador dentro - desde MA a filtros digitais.
As árvores são divididas em partes direitas e esquerdas por simples if(x<v){ ramo esquerdo}else{ ramo direito}.
Ou a baisian NS também é se(x<v){sector esquerdo}else{do sector direito}?
é, sim, lento, por isso puxar daí conhecimentos úteis até agora, dá uma compreensão de algumas coisas
Não, em Bayesian NS, os pesos são simplesmente otimizados pela amostragem dos pesos das distribuições, e a saída é também uma distribuição que contém um monte de escolhas, mas tem uma média, variância, etc. Em outras palavras, ele captura muitas variantes que na verdade não estão no conjunto de dados de treinamento, mas elas são, a priori, assumidas. Quanto mais amostras são alimentadas em tais NS, mais perto converge para uma normal, ou seja, as abordagens Bayesianas são inicialmente para conjuntos de dados não muito grandes. Isto é o que eu sei até agora.
Ou seja, tais NS não precisam de conjuntos de dados muito grandes, os resultados convergirão para os convencionais. Mas o resultado após o treinamento não será uma estimativa de ponto, mas uma distribuição de probabilidade para cada amostra.
é lento, é por isso que estou tirando algum conhecimento útil dele até agora, dá uma compreensão de algumas coisas
Não, em Bayesian NS, os pesos são simplesmente otimizados pela amostragem dos pesos das distribuições, e a saída é também uma distribuição que contém um monte de escolhas, mas tem uma média, variância, etc. Em outras palavras, ele captura muitas variantes que na verdade não estão no conjunto de dados de treinamento, mas elas são, a priori, assumidas. Quanto mais amostras são alimentadas em tais NS, mais perto converge para uma normal, ou seja, as abordagens Bayesianas são inicialmente para conjuntos de dados não muito grandes. Isto é o que eu sei até agora.
Ou seja, tais NS não precisam de conjuntos de dados muito grandes, os resultados convergirão para os convencionais. Mas o resultado após o treinamento não será uma estimativa de ponto, mas uma distribuição de probabilidade para cada amostra.
Andas por aí como se estivesses em velocidade, uma coisa de cada vez, outra coisa de cada vez... e é inútil.
Você parece ter muito tempo, como um cavalheiro, você precisa trabalhar, trabalhar duro e lutar pelo crescimento da carreira, em vez de se apressar das redes neuronais para o básico.
Acredite, ninguém em nenhuma corretora normal lhe dará dinheiro para verborreia científica ou artigos, apenas equidade confirmada pelos principais corretores do mundo.Eu não tenho pressa, mas estudo de forma consistente do simples ao complexo
Se você não tem um emprego, posso oferecer-lhe, por exemplo, para reescrever algo em mql.
Eu trabalho para o senhorio, assim como todos os outros, é estranho que você não trabalhe, você mesmo é um senhorio, um herdeiro, um menino de ouro, um homem normal se ele perder o emprego em 3 meses na rua, ele está morto em 6 meses.
Se não há nada sobre MO no comércio, então dê uma volta, você vai pensar que são os únicos mendigos aqui)
Mostrei a todos em RI, honestamente, sem segredos infantis, sem tretas, o erro no teste é de 10-15%, mas o mercado está em constante mudança, o comércio não vai, tagarelice perto de zero
Em resumo, vai-te embora, Vasya, não estou interessado em lamentar
Tudo o que você faz é choramingar, sem resultados, você cava garfos na água e é isso, mas você não tem coragem de admitir que está perdendo seu tempo.
Você deve se alistar no exército ou pelo menos trabalhar em um canteiro de obras com homens fisicamente, você melhoraria seu caráter.é, sim, lento, por isso puxar daí conhecimentos úteis até agora, dá uma compreensão de algumas coisas
Não, em Bayesian NS, os pesos são simplesmente otimizados pela amostragem dos pesos das distribuições, e a saída é também uma distribuição que contém um monte de escolhas, mas tem uma média, variância, etc. Em outras palavras, ele captura muitas variantes que na verdade não estão no conjunto de dados de treinamento, mas elas são, a priori, assumidas. Quanto mais amostras são alimentadas em tais NS, mais perto converge para uma normal, ou seja, as abordagens Bayesianas são inicialmente para conjuntos de dados não muito grandes. Isto é o que eu sei até agora.
Ou seja, tais NS não precisam de grandes conjuntos de dados, os resultados irão convergir para os convencionais.
Aqui estão os comentários de https://www.mql5.com/ru/forum/226219 sobre o artigo de Vladimir sobre otimização Bayesiana, como ele plota a curva em vários pontos. Mas então eles também não precisam de NS/floresta - você pode simplesmente procurar a resposta nesta curva.
Outro problema - se um otimizador não aprender, ele ensinará a NS algumas porcarias incompreensíveis.
 amostra ensinada
amostra ensinada 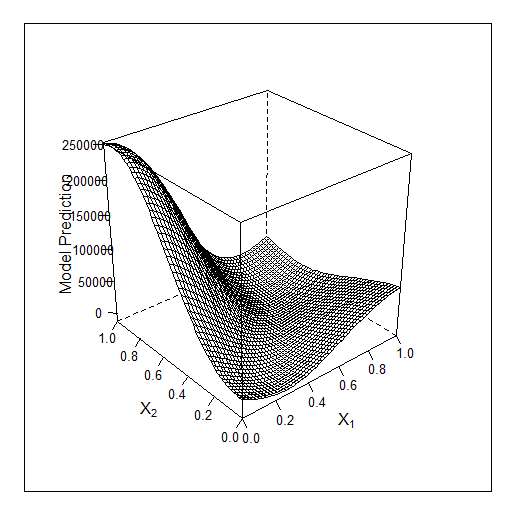
Aqui para 3 características trabalho de Bayes
São os imbecis no fio que não o tornam divertido de todo.
a choramingar para si mesmos.
Do que há para falar? Você apenas coleta links e diferentes resumos científicos para impressionar os recém-chegados, SanSanych escreveu tudo em seu artigo, não há muito a acrescentar, agora há diferentes vendedores e redatores de artigos que mancharam tudo com suas forquilhas de vergonha e repugnância. Eles se chamam "matemáticos", eles se chamam "quantum" .....
Quer que a matemática tente ler istohttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
E você não vai entender que não é um matemático, mas um floco.