Discusión sobre el artículo "Estimación de la densidad del kernel de la función de densidad de probabilidad desconocida"
Para el autor. Se obtienen resultados aún mejores si estimamos no la densidad de la distribución, sino la función de distribución, es decir, la integral de la densidad: en primer lugar, es más fácil construirla sobre los datos, y como siempre es no decreciente y está acotada entre 0 y 1, la sensibilidad a la elección del algoritmo de suavizado, ya sea kernel, spline, regresión o cualquier otro, es mucho menor. Los requisitos sobre la cantidad de datos disponibles también se reducen, y en un orden de magnitud.
Además, la densidad puede obtenerse fácilmente por diferenciación numérica, si es necesario.
Bueno, la densidad se puede obtener fácilmente por diferenciación numérica si es necesario.
Tal vez. No puedo decir nada al respecto. Ni siquiera he intentado evaluar el pdf mediante la cdf . Lo más probable es que haya funcionado el prejuicio de que el uso de la diferenciación requeriría un aumento significativo de la precisión de la estimación de la cdf. Además, no he encontrado ninguna publicación que evalúe el método cdf->pdf o que lo compare con otros métodos. Si puedes compartir enlaces, te lo agradecería.
La idea original era no utilizar ninguna herramienta externa, es decir, se suponía que todo debía ser implementado únicamente por las herramientas MQL5.
Esta es la idea de todos los inventores de bicicletas sin excepción.
Mire lo que tienen los paquetes correspondientes en este sentido y compárelo con lo que usted ha proporcionado: una cantidad infinitesimal de lo que se necesita cuando se aplican la matemática y la econometría en el trading.
Tal vez. No puedo decir nada al respecto. Ni siquiera he intentado estimar el pdf mediante la cdf . Lo más probable es que haya funcionado el prejuicio de que el uso de la diferenciación requeriría un aumento significativo de la precisión de la estimación de cdf. Además, no he encontrado ninguna publicación que evalúe el método cdf->pdf o que lo compare con otros métodos. Si compartes enlaces, te lo agradecería.
No puedo aportar referencias porque no las tengo. En su lugar daré estas consideraciones.
Cuando evaluamos un pdf directamente, tenemos que dividir el dominio de la definición en intervalos de antemano, y hay dos problemas: primero, no sabemos en cuántos intervalos es mejor dividir el dominio, y segundo, no sabemos qué tipo de rejilla(uniforme, ... ?) sería mejor. Y si la segunda pregunta la gente todavía de alguna manera trató de resolver, por ejemplo, utilizando la partición cuantil, a continuación, para la primera, en mi opinión, no hay métodos universales en absoluto: todos los conocidos para mí tienen limitaciones que los hacen de poca utilidad en las tareas de automatización, cuando no podemos permitirnos el método de poke.
La estimación cdf carece de estos inconvenientes. En este caso, los pasos de la función se sitúan exactamente donde caen los datos de entrada, por lo que el problema de elegir una rejilla para el interpolante desaparece por sí solo. Una vez creada la rejilla, no es difícil elegir el número de intervalos: ya conocemos el número máximo de intervalos (¡¡y su ubicación!!), por lo tanto, mediante el adelgazamiento podemos establecer cualquier precisión requerida, y cada vez en una rejilla natural que mejor se ajuste a la estructura de los datos de entrada.
En la práctica, he utilizado esta técnica para buscar modos locales de distribuciones empíricas cuando el número de muestras de datos no exceda de 100, y he obtenido resultados muy suaves, y visualmente la precisión de la búsqueda se define como bastante cualitativa, al menos 2-4 modos principales se encuentran casi sin desviaciones. Pero yo uso un algoritmo de suavizado diferente, no me gustan los de kernel por varias razones.
Todo perfectamente justo. Pero como me parece a mí, salvo un punto, al que aparentemente no prestaste atención.
Una expresión bien conocida para Kernel smoother es "Kernel smooth".
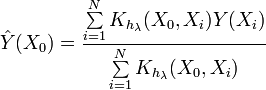
Un método basado en dicho suavizado para estimar la pdf podría tener este aspecto (simplificado):
- Particionamos la secuencia de entrada en intervalos (clustering, Binning)
- Suavizamos el histograma resultante.
Si no te gusta el suavizado kernel, puedes usar, por ejemplo, p-spline. (Probablemente es mejor elegir p-spline de inmediato).
Con este enfoque para la estimación de pdf todo lo que has dicho resulta ser absolutamente justo. Pero incluso en este caso este método de estimación para secuencias de gran longitud (>1000000) da excelentes resultados. A medida que la longitud de la secuencia de entrada disminuye, todos esos encantos que has mencionado empiezan a aparecer cada vez con más fuerza.
Veamos ahora la expresión de la estimación de densidad Kernel (KDE)
![]()
Esta expresión es diferente de la anterior. Como vemos, esta expresión determina directamente el valor de la función de densidad de probabilidad en un punto dado. Y lo que es importante en este caso, no hay partición en intervalos. Se utilizan directamente los valores de la secuencia de entrada.
Al menos, así es como yo veo la situación con KDE. El algoritmo de estimación de pdf dado en el artículo a primera vista se las arregla bien con secuencias de 20-30 elementos de longitud. A veces es posible que desee reducir el grado de suavizado. Puede hacerlo fácilmente sustituyendo en el código
h=0.9*a/MathPow(N,0.2); // Regla de Silvermanpor
h=0.7*a/MathPow(N,0.2); // Regla de Silverman
La idea original era no utilizar ninguna herramienta externa, es decir, se suponía que todo debía ser implementado únicamente por las herramientas MQL5.
Esta es la idea de todos los inventores de bicicletas sin excepción.
Mire lo que tienen los paquetes correspondientes en este sentido y compárelo con lo que usted ha proporcionado: una cantidad infinitesimal de lo que se necesita cuando se aplica la matemática y la econometría en el trading.
Estimado Alex,
Es fácil para ti razonar desde la altura de tu vuelo. Pero piensa por un segundo en lo siguiente:
Este recurso se llama"www.mql5.com - Automated Trading and Testing of Trading Strategies". Como puedes ver, el sitio se llama mql5, no EViews ni siquiera MQ o MT5. Por lo tanto, es fácil suponer que este sitio se centra principalmente en la popularización, depuración y desarrollo del lenguaje de programación MQL5. Esto se confirma por la presencia del servicedesk y la colocación de información de referencia MQL5 en el sitio.
Si este sitio se llamara, por ejemplo, "una colección de estrategias de trading" y no perteneciera a MQ. En este caso, uno esperaría que las publicaciones que describen soluciones en Exel, R, EVievs, Gauss, Stata y demás aparecieran en dicho sitio.
Si hubiera publicado este artículo en el sitio de EViews, tal vez habría intentado comprender la esencia de su reproche. Pero usted y yo no estamos en EViews en este momento.
Este sitio es visitado por personas con antecedentes muy diferentes. Son personas de diferentes edades, con diferentes niveles educativos y diferentes especialidades. Creo que la mayoría tiene poca o ninguna experiencia con paquetes econométricos. ¿Cree usted que todas estas personas deberían ser desterradas de este sitio, por ejemplo, que aprendan primero EViews?
Puesto que te has autopublicado, deberías estar familiarizado con el procedimiento de publicación de artículos en este sitio. Es imposible autopublicar un artículo. Sólo puede enviar un artículo para su consideración. La propia administración del sitio selecciona los artículos adecuados a su concepto general. Y en algunos casos, la propia administración encarga artículos sobre temas de su interés. Como ya he dicho, la administración tiene un concepto general y estadísticas sobre el número de solicitudes de tal o cual publicación. En esta situación, creo que no es muy correcto dirigirse a mí con afirmaciones sobre el tema del artículo. ¿Quizá debería discutir estas cuestiones con los representantes de MQ?
Hay artículos publicados en este sitio que no me interesan. Insisto, no son malos artículos, sino que simplemente no me interesan. No suelo leerlos ni escribir comentarios sobre ellos. ¿Quizás deberías elegir una línea de conducta similar para ti? Aunque no me atrevo a dar consejos, haz lo que te parezca más cómodo.
Querido Alex,
Es fácil para ti razonar desde la altura de tu vuelo. Pero piensa en lo siguiente por un segundo:
Este recurso se llama"www.mql5.com - Automated Trading and Testing of Trading Strategies". Como puedes ver, el sitio se llama mql5, no EViews ni siquiera MQ o MT5. Por lo tanto, es fácil suponer que este sitio se centra principalmente en la popularización, depuración y desarrollo del lenguaje de programación MQL5. Esto se confirma por la presencia del servicedesk y la colocación de información de referencia MQL5 en el sitio.
Si este sitio se llamara, por ejemplo, "una colección de estrategias de trading" y no perteneciera a MQ. En este caso, uno esperaría que las publicaciones que describen soluciones en Exel, R, EVievs, Gauss, Stata y demás aparecieran en dicho sitio.
Si hubiera publicado este artículo en el sitio de EViews, tal vez habría intentado comprender la esencia de su reproche. Pero usted y yo no estamos en EViews en este momento.
Este sitio es visitado por personas con antecedentes muy diferentes. Son personas de diferentes edades, con diferentes niveles educativos y diferentes especialidades. Creo que la mayoría tiene poca o ninguna experiencia con paquetes econométricos. ¿Cree usted que todas estas personas deberían ser desterradas de este sitio, por ejemplo, que aprendan primero EViews?
Puesto que te has autopublicado, deberías estar familiarizado con el procedimiento de publicación de artículos en este sitio. Es imposible autopublicar un artículo. Sólo puede enviar un artículo para su consideración. La propia administración del sitio selecciona los artículos adecuados a su concepto general. Y en algunos casos, la propia administración encarga artículos sobre temas de su interés. Como ya he dicho, la administración tiene un concepto general y estadísticas sobre el número de solicitudes de tal o cual publicación. En esta situación, creo que no es muy correcto dirigirse a mí con afirmaciones sobre el tema del artículo. ¿Quizá debería discutir estas cuestiones con los representantes de MQ?
Hay artículos publicados en este sitio que no me interesan. Insisto, no son malos artículos, sino que simplemente no me interesan. No suelo leerlos ni escribir comentarios sobre ellos. ¿Quizás deberías elegir una línea de conducta similar para ti? Aunque no me atrevo a dar consejos, haz lo que te parezca más cómodo.
No puedo aceptar tu respuesta, ya que no se ajusta en absoluto a la esencia de mi post. Intentaré explicar mi punto de vista.
1. Metaquotes no tiene nada que ver en absoluto - han proporcionado una herramienta muy decente y lo están haciendo.
2. No tengo conocimiento de ninguna restricción en los temas de los artículos. Por supuesto, dentro de los límites del trading. Este sitio tiene una sección "Estadísticas", es decir, que entienden el tema del sitio mucho más amplio que usted, en plena conformidad con el contenido y los problemas del comercio. No nos refiramos a Metaquotes y pasar a la sustancia.
3. mi post no trata de QUÉ desarrollar, sino de CÓMO hacerlo. Para mí, esto es lo fundamental en relación con su artículo. No estaba haciendo campaña a favor de EViews, del que tengo una mala opinión - es bueno para fines de demostración y formación, pero no creo que se pueda operar con él. Mi enlace es a paquetes para demostrar la amplitud del problema.
4. Llevo mucho tiempo en la programación. Hace 40 años aparecieron las primeras librerías de programas e inmediatamente, hace 40 años, se criticaba a los aficionados que reescribían algún programa a partir de un paquete existente. Usted no es el primero. Pero este sitio está lleno de aficionados a los que les gusta volver a construir una bicicleta, de ahí mi reacción hipertrofiada.
5. El tema de la evaluación nuclear es un tema muy masticado. Y si cogieras la biblioteca de otro, tendrías la oportunidad de elevarte por encima de las dificultades técnicas que resolviste en tu trabajo y quizás ofrecer una solución a las cuestiones planteadas por el practicante alsu, o recordar que la evaluación visual de las distribuciones juega un papel muy importante en su evaluación formal, o ampliar funcionalmente, etc. - de cualquier forma estarías un peldaño más arriba.
No he querido expresar nada ofensivo hacia ti. Tu artículo y desarrollo es respetable, pero no puedo estar de acuerdo con el enfoque metodológico de la técnica de aplicación de tus ideas.
Mi post sobre tu artículo está dictado por la esperanza de que alguien complemente sistemáticamente el terminal Metaquot con medios de estadística y econometría. Te remito a tales personas.
Extremadamente interesante. Muy interesante.
¿Aceptan solicitudes?
No sólo código abierto, pero código orientado a estadísticas es deseable. Por favor, preste atención a R.
Extremadamente interesante. Muy interesante.
¿Aceptan solicitudes?
No sólo código abierto, pero código orientado a estadísticas es deseable. Por favor, preste atención a R.
Se aceptan peticiones aquí: https://www.mql5.com/ru/forum/6505. Escribe lo que quieras. :)
- www.mql5.com
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Estimación de la densidad del kernel de la función de densidad de probabilidad desconocida:
Este artículo trata sobre la creación de un programa en el que se permite la estimación de la densidad del kernel de la función de densidad de probabilidad desconocida. Se ha elegido el método de estimación de la densidad del kernel para realizar la tarea. El artículo contiene códigos fuente de la implementación del software del método y ejemplos de su uso e ilustraciones.
Autor: Victor