Феномены рынка - страница 33
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Не то что бы неправильно. Правильно, настолько правильно, как выражение "покупай дёшево, продавай дорого". Важна не только правильность, но и формализуемость. Нет смысла строить хитрые философские околорыночные построения, если от них (построений) как от козла молока.
Вы считаете что временной перерыв после принятия убытка трудно формализовать? Или что другое?
Спасибо. На досуге поразмышляю об SOM.
В статье по ссылке обзор методов сегментации временных рядов. Они все делают примерно одно и тоже. Не факт, что SOM это лучший метод для форекса, но и не худший, это факт ))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
Коллеги, к сожалению дела, не позволяют уделять больше времени трейдингу, но все же, нашлось немного времени, решил уточнить (скорее для себя, что бы не забыть :о, шоб потом вернуться, когда свободного времени станет побольше)
Суть феномена
Напомню суть этого феномена. Он был обнаружен во время анализа влияния «длинных хвостов» на будущие уклонения траектории цены. Если классифицировать «длинные хвосты» и посмотреть временной ряд без них, то можно наблюдать любопытные явления, причем уникальные для каждого котира, ну почти для каждого. Суть феномена – очень специфичная классификация, в основе которой лежит в некотором роде «нейронный» подход. Фактически, эта классификация «разваливает» первичные данные, т.е. сам котировочный процесс на два подпроцесса, которые условно назвал «alpha» и «betta». Вообще говоря, развалить исходный процесс можно и на большее количество подпроцессов.
Система со случайной структурой
Этот феномен очень хорошо ложиться на системы со случайной структурой. Сама модель будет выглядеть очень просто. Можно посмотреть на примере. Исходный ряд EURUSD M15 (нужна длинная выборка, и как можно меньшего фрейма), с какого то «сейчас»:
1 шаг: Классификация
Выполняется классификация, получаются два процесса «alpha» и «betta». Определяется параметры управляющего процесса (процесс, который занимается окончательной «сборкой» котировки)
2 шаг Идентификация
Для каждого подпроцесса определяется модель на основе сети Вольтерри:
Ох и за..ся можно их идентифицировать.
3 шаг Прогноз подпроцессов
Выполняется прогноз на 100 отсчетов для каждого процесса (для 15 минуток, т.е. чуть больше суток).
4 шаг: Имитационное моделирование
Собирается имитационная модель, которая и будет генерить х.тучу будущих реализаций. Схема системы простая:
Три случайности: ошибка для каждой модели и условия перехода от процесса к процессу. Вот сами реализации (от нуля):
5 шаг: Торговое решение
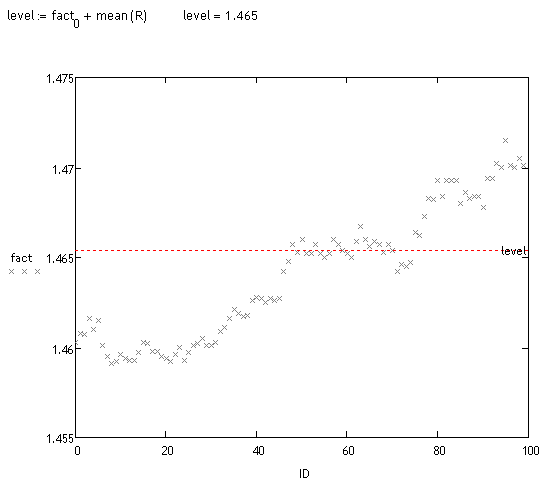
Выполняется анализ смещения этих реализаций. Выполнять можно по-разному. Визуально видно, что большая масса траекторий смещена. Смотрим факт:
<>
Предварительное тестирование
Взял наугад порядка 70 «замеров» (считает долго). Где то в 70% система определила уклонение верно, т.е. это пока ни о чем не говорит, но надеюсь, через пару месяцев вернуться к этому направлению, хотя, еще не закончил работы по основному проекту :о(.
to sayfuji
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
Да нет, все корректно. Это и было одним из предметов обсуждения на нескольких десятках страниц этой темы. Все, что счел нужным - написал, развивать тему дальше сейчас времени к сожалению нет. К тому же, конкретно этот феномен хоть и интересный, но мало перспективный. Феномен "длинных хвостов" проявляет себя на длинных горизонтах, т.е. там где проявляются большие уклонения траекторий, а для этого нужно далеко прогнозировать процессы alpha и betta (и другие процессы). А это невозможно. Нет таких технологий...
:о(
to All
Коллеги, оказывается есть посты, на которые не отвел. Прошу меня простить, сейчас уже дергаться смысла нет.
Прохвессор Франсфорт, ответьте пожалуйста, какую программу вы используете для своих исследований.
И еще...если у кого-нибудь инструкция на русском языке или русификатор к программе http://originlab.com/ (OriginPro 8.5.1)
Интересный результат.
Может ли быть обусловлен этот феномен тем, что исторические данные - это цены Bid? (Lambda в эксперименте сравнимо со спредом)
Не кажется ли вам разумнее тестировать качество получаемого процесса "тренда" при помощи линейной регрессии с кусочно-постоянными коэффициентами, если рассматривать их как функции времени?
Можно сложить отфильтрованные приращения, получаем два процесса: