Показатель Херста - страница 22
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Меня смущает ваше "Ни одного работоспособного." после слов "... и в литературе". В литературе много разных подходов, которые дают незначительно отличающиеся друг от друга результаты, что не удивительно, т.к. это все оценки. Однако, правда и то, что чем больше выборка, тем точнее должны быть эти оценки и тем "равнее" они друг другу. Соглашусь только с тем, что на форумах работоспособный алгоритм Херста найти трудно.
Что же до того, что подавать на вход алгоритма, то тут алгоритму все равно. Подайте цену - получите что-то около единицы. Ещё бы, для сути алгоритма цена имеет сильную долговременную память, т.к. сравнительно далеко не уходит от первоначальных значений. Подайте приращения цены - получите нечто вроде 0,5, что опять-таки оправдано, т.к. их сравнительные изменения велики и практически случайны. Подйте тренды и/или циклы - получите персистентность. Шумы в общем случае уменьшают показатель. Вижу, что вопрос: "зашумленная у нас цена или честная рыночная?" - это не предмет алгоритма Херста, это уже другое царство.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Вообще, чем больше, тем лучше. По алгоритму из книжки Петерса - лучше длина, которая имеет наибольшее количество целочисленных делителей.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Различают две модели:
1. Процесс обладает "стабильным" показателем Херста. Т.е. показатель - константа и никак не меняется во времени (на протяжении существования всего процесса). В этом случае, для его определения берут как минимум - статистически значимый участок, т.е. такой участок, который позволяет провести уверенную оценку распределения процесса. Или не заморачиваясь - как можно больший отрезок.
2. Показатель представляет собой некую функцию, возможно очень сложную, возможно случайную. В этом случае, нет никаких объективных критериев выбора длины ВР. Оценка показателя для общего случая - невозможна ни во временной ни в частотных областях, если Вы не экстрасенс.
Важно, RS анализ - это один из самых грубейших методов, его оценка всегда смещена и величина выборки никак не поможет. Для получения корректного расчета показателя Херста, используйте оценку на основе вейвлетов (алгоритм можно найти, например, в mathlab).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Херст для цены ~1, а тут что?
Единственное, чем могу помочь в данном случае, так это указанием на то, что в файле _hurst_classik ни Херста, ни R/S анализа нет. Суть самого названия "R/S" в перемаштабировании ряда. В тексте же _hurst_classik, имеющего претензию на _RS_Analiz никакого перемастабирования не проводится, а, к примеру, банально берется разница между максимальной и минимальной ценой.
Более того, R/S анализ, чтобы добраться до Херста, вычисляет наклон кривой, а для этого ему на каждом баре необходимо множество точек на плоскости log(R/S) - log(n), а не одна. В этом же чудо _RS_Analiz'е такого и в помине нет.
Основное в моем посте было"идентифцировать модель ВР", но это не привлекло Вашего внимания.
Если речь идет моделях класса ARFIMA(параметы) или типа того, то действительно, это мне не интересно, т.к. эти модели растут "накуи", цель которой собрать деньги в инвестфонды. Такие "науки" называют кабинетными, т.к. они созданы только ради подгонки научной основы под заведомо желаемый результат, как правило, прогнозирование цены.
Если речь идет моделях класса ARFIMA(параметы) или типа того, то действительно, это мне не интересно, т.к. эти модели растут "накуи", цель которой собрать деньги в инвестфонды. Такие "науки" называют кабинетными, т.к. они созданы только ради подгонки научной основы под заведомо желаемый результат, как правило, прогнозирование цены.
Не будем давать оценки. Сейчас речь идет о подходах, использующих модель ВР и не использующих вовсе.ПОМОГИТЕ РАССЧИТАТЬ ИНДИКАТОР ХЕРСТА!!!*
*маленькое замечание: как у Петерса
Прочитал всю ветку от начала и до конца: да уж, не ожидал что все, начиная от уважаемых ученых мужей и заканчивая обычными зеваками имеют свое собственное мнение о том, что такое Херст, и как его надо считать и интерпретировать. Наиболее близким к оригиналу оказался Эрик Найман в своей статье и книге. Но... у нас (в России так точно) по-прежнему нет адекватного инструмента генерирующие графики, что представлены в книге Петерса.
Итак, я постарался максимально близко сымитировать последовательность действий Петерса, описанной в его первой книге: "Хаос и порядок в мире капитала", для рассчета R/S статистики для S&P 500.
1. Берем месячные биржевые графики S&P 500 c 01.01.1950 по 01.07.1988.
2. Загружаем их в программу тех анализа (Я использую WealthLab и C#, здесь и далее буду приводить код WL/C#)
3. Преобразуем цены в доходности по формуле представленной в книге Петерса: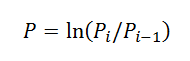
4. Сам Петерс не упоминает, что после того, как рассчитываются доходности, они снова преобразуются в накопленный ряд: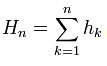 . Однако это очевидно, исходя из тех значений R/S размаха которые у него присутствуют, к тому же в источнике также явно сказано об этом, я цитирую: "Для каждого натурального n составим величины (формула см. выше) и вычислим следующие числовые характеристики получившейся подпоследовательности".
. Однако это очевидно, исходя из тех значений R/S размаха которые у него присутствуют, к тому же в источнике также явно сказано об этом, я цитирую: "Для каждого натурального n составим величины (формула см. выше) и вычислим следующие числовые характеристики получившейся подпоследовательности".
5. Делим получившийся ряд на k периодов, длинна каждого периода равна N от 6 до 231 месяцев или наблюдений.
6. Теперь важный момент. Если целое количество периодов не получается (остаются неиспользованные данные) то они отбрасываются. Однако если остаток слишком большой (например 462 / 232 = 233 и 230 в остатке) получается некорректное значение. Как я понял, Петерс использует сдвижки, однако это очень кропотливый вариант в плане программирования и я просто отбрасываю период, если его остаток больше 6. Так как смежные периоды имеют практически одно и тоже значение R/S то это корректный вариант.
7. Далее рассчитывается R по формуле:
8. R делиться на стандартное отклонение (рассчитывается индикатором WL) и логарифмируется: log10(R/S).
9. Текущий период логарифмируется: log10(N);
10. Полученное отношение log10(R/S) к log10(N) заноситься в файл.
Если в оптимизаторе перебрать N от 6 (как у Петерса) до 231 (минимальное количество экспериментов 2), то получиться таблица из двух столбцов в двойном логарифмическом масштабе: 1. период 2. значение R/S.
Теперь начинается самое интересное. Если построить эту таблицу в ексель, выйдет следующее:
Оригинал представлен справа. Как видно, некая похожесть есть, но все равно не то. В частности, первоначальный показатель получается несколько завышенным (0,33 против примерно 0,31), во-вторых, конечные значения вдруг сильно начинают падать, чего быть в принципе не должно. По его графику в конце ряда должен поменяться лишь угол наклона, говоря нам о том, что эффект памяти ограничен.
Пока остановился на этом. Применять U/V статистику пока не решился, учитывая лишь частичное совпадение с оригиналом.
Конвертация R/S оценок в Херста также дает несколько завышенные результаты. Если показатель Херста это: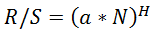 , тогда по формуле екселя получим LOG(СТЕПЕНЬ(10;B1);C1*0,5), где B1 текущая оценка R/S.
, тогда по формуле екселя получим LOG(СТЕПЕНЬ(10;B1);C1*0,5), где B1 текущая оценка R/S.
Ниже приведен код WL/C# реализующий рассчет R/S статистики:
p.s. Забавно, в MQL4 нет ключевых слов типа overide и using, а синтаксис их все равно подсвечивает:)есть ли расчет показателя Херста в маткаде (нужны формулы в дискретном виде)?
У себя нашол пока только вот это
Файл с подходами к анализу временных рядов прилагаю. Эти формулы взял от туда.
Извините, конечно.
И что - это интересно? Глядя на формулы - не вижу смысла вообще в применении их на Форекс.
Легче самому накидать ряд, который опишет Форекс. Да он уже есть так то, люди за него нобелевскую взяли. Но результат очень и очень даже усредненный получается. Нужно же сначала всегда усреднение прикинуть - ошибку то есть, потом попробовать минусы вытащить из вероятности в связи с ошибками, а потом уже заморачиваться.
Извините, конечно.
И что - это интересно? Глядя на формулы - не вижу смысла вообще в применении их на Форекс.
Легче самому накидать ряд, который опишет Форекс. Да он уже есть так то, люди за него нобелевскую взяли. Но результат очень и очень даже усредненный получается. Нужно же сначала всегда усреднение прикинуть - ошибку то есть, потом попробовать минусы вытащить из вероятности в связи с ошибками, а потом уже заморачиваться.
Извиняю. Но на будущее давайте договоримся, не постить в этой ветке досужие размышления. Кому-то интересен "ряд Форекс", кому-то статистика Херста. Пусть у каждого будет своя ветка.
Выкладываю таблицу типа CSV в двойном логарифмическом масштабе: оценка R/S к периоду.