
Modèles de régression non linéaire en bourse

Introduction
Hier, j'étais de nouveau plongé dans l'analyse des rapports de mon système de trading basé sur la régression. Dehors, la neige fondante tombait, le café refroidissait dans la tasse, mais je n'arrivais toujours pas à me débarrasser de cette pensée obsessionnelle. Vous savez, je suis depuis longtemps agacé par ces interminables indicateurs RSI, Stochastique, MACD et autres. Comment pouvons-nous tenter d'intégrer un marché vivant et dynamique à ces équations primitives ? Chaque fois que je vois un autre adepte du Graal sur YouTube avec son ensemble d'indicateurs « sacrés », j'ai juste envie de demander : mais vous croyez vraiment que ces calculateurs des années soixante-dix peuvent saisir la dynamique complexe du marché moderne ?
J'ai passé les trois dernières années à essayer de créer quelque chose qui fonctionne réellement. J'ai essayé beaucoup de choses, des régressions les plus simples aux réseaux neuronaux sophistiqués. Et vous savez quoi ? J'ai réussi à obtenir des résultats en classification, mais pas encore en régression.
C'était toujours la même histoire : dans l'historique, tout fonctionne comme sur des roulettes. Mais quand je le lance sur le marché réel, je subis des pertes. Je me souviens de l'enthousiasme que j'ai ressenti pour mon premier réseau de neurones convolutif. R2 à 1,00% en entraînement. S'en sont suivies deux semaines de transactions et une perte de 30% du dépôt. Le sur-ajustement classique dans sa forme la plus aboutie. J'ai continué à activer la visualisation prospective pour observer comment les prévisions basées sur la régression s'éloignaient de plus en plus des prix réels au fil du temps...
Mais je suis quelqu'un de têtu. Après une nouvelle défaite, j'ai décidé d'approfondir mes recherches et j'ai commencé à éplucher des articles scientifiques. Et savez-vous ce que j'ai déniché dans ces archives poussiéreuses ? Il s'avère que le vieux Mandelbrot insistait déjà beaucoup sur la nature fractale des marchés. Et nous essayons tous de trader avec des modèles linéaires ! C'est comme essayer de mesurer la longueur d'un littoral avec une règle : plus la mesure est précise, plus la longueur paraît grande.
À un moment donné, l'idée m'est venue : et si j'essayais de croiser l'analyse technique classique avec la dynamique non linéaire ? Non pas ces indicateurs grossiers, mais quelque chose de plus sérieux : des équations différentielles, des ratios adaptatifs. Cela paraît compliqué, mais il s'agit en réalité simplement d'apprendre à parler le langage du marché.
En bref, j'ai pris Python, j'ai installé les bibliothèques d'apprentissage automatique et j'ai commencé à expérimenter. J'ai tranché sur-le-champ : pas de fioritures académiques, juste ce qui est vraiment utile. Pas de superordinateurs – juste un ordinateur portable Acer classique, un VPS ultra-puissant et un terminal MetaTrader 5. De tout cela est né le modèle dont je veux vous parler.
Non, ce n'est pas le Graal. Le Graal n'existe pas, je l'ai compris il y a longtemps. Je partage simplement mon expérience de l'application des mathématiques modernes au trading réel. Pas de surenchère inutile, mais pas non plus de primitivisme des « indicateurs de tendance ». Le résultat était un compromis : suffisamment intelligent pour fonctionner, mais pas si complexe qu'il s'effondrerait face au premier événement imprévu et majeur.
Modèle mathématique
Je me souviens comment j'en suis arrivé à cette équation. Je travaille sur ce code depuis 2022, mais pas de manière constante : en termes d’approches, je dirais qu’il y a de nombreux développements, donc on les passe en revue périodiquement (un peu chaotiquement) et on les intègre un par un au résultat. Je me souviens d'avoir analysé des graphiques, d'avoir essayé de repérer des tendances sur la paire EUR/USD. Et vous savez ce qui a attiré mon attention ? Le marché semble respirer – parfois il suit la tendance en douceur, parfois il connaît des à-coups soudains et brusques, parfois il entre dans une sorte de rythme magique. Comment décrire cela mathématiquement ? Comment traduire cette dynamique du vivant en équations ?
Ensuite, j'ai esquissé une première version de l'équation. La voici, dans toute sa splendeur :
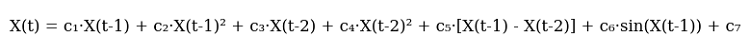
Et voici le code :
def equation(self, x_prev, coeffs): x_t1, x_t2 = x_prev[0], x_prev[1] return (coeffs[0] * x_t1 + # trend coeffs[1] * x_t1**2 + # acceleration coeffs[2] * x_t2 + # market memory coeffs[3] * x_t2**2 + # inertia coeffs[4] * (x_t1 - x_t2) + # impulse coeffs[5] * np.sin(x_t1) + # market rhythm coeffs[6]) # basic level
Regardez comme tout est tordu. Les deux premiers termes visent à saisir la tendance actuelle du marché. Savez-vous comment une voiture accélère ? D'abord en douceur, puis de plus en plus vite. C'est pourquoi on trouve ici un terme linéaire et un terme quadratique. Lorsque le prix évolue calmement, la partie linéaire fonctionne. Mais dès que le marché s'accélère, le terme quadratique reprend le mouvement.
Voici maintenant la partie la plus intéressante. Les troisième et quatrième termes remontent un peu plus loin dans le passé. C'est comme une mémoire du marché. Vous souvenez-vous de la théorie de Dow selon laquelle le marché se souvient de ses niveaux ? C'est la même chose ici. Et là encore, elle présente une accélération quadratique, pour négocier les virages serrés.
Passons maintenant à la composante d'inertie (momentum). Il suffit de soustraire l'ancien prix du prix actuel. Cela semblerait primitif. Mais ça fonctionne super bien sur les tendances ! Lorsque le marché s'emballe et pousse dans une direction, ce terme devient le principal moteur des prévisions.
Le sinus a été ajouté presque par accident. J'ai examiné les graphiques et j'ai remarqué une sorte de périodicité. Surtout sur H1. Les périodes d'activité et de calme se succédaient... On dirait une sinusoïde, n'est-ce pas ? J'ai intégré l'onde sinusoïdale dans l'équation, et le modèle a semblé comprendre et a commencé à capter ces rythmes.
Le dernier ratio constitue une sorte de filet de sécurité, un niveau de base. Ce terme ne permet pas au modèle de surprendre grandement le marché avec ses prévisions.
J'ai essayé un tas d'autres options. J'y ai fourré des exposants, des logarithmes et toutes sortes de fonctions trigonométriques sophistiquées. Cela n'a guère d'intérêt, mais le modèle se transforme en monstre. Comme disait Occam : ne multipliez pas les entités au-delà du nécessaire. La version actuelle s'est avérée être exactement comme ça : simple et fonctionnelle.
Bien sûr, tous ces ratios doivent être sélectionnés d'une manière ou d'une autre. C’est là que la bonne vieille méthode Nelder-Mead vient à la rescousse. Mais c'est une toute autre histoire que je vais vous révéler dans la prochaine partie. Croyez-moi, il y a beaucoup à dire – les erreurs que j'ai commises lors de l'optimisation à elles seules mériteraient un article à part entière.
Composants linéairesCommençons par la partie linéaire. Savez-vous quel est le plus important ? Le modèle examine les deux valeurs de prix précédentes, mais de manières différentes. Le premier ratio se situe généralement autour de 0,3-0,4 - il s'agit d'une réaction instantanée au dernier changement. Mais la seconde est plus intéressante, elle approche souvent 0,7, ce qui indique une influence plus forte de l'avant-dernier prix. Drôle, hein ? Le marché semble se baser sur des niveaux légèrement plus anciens, et ne pas tenir compte des dernières fluctuations.
Composantes quadratiquesUne histoire intéressante s'est produite avec les termes quadratiques. Au départ, je les avais ajoutés simplement pour tenir compte de la non-linéarité, mais j'ai ensuite remarqué quelque chose de surprenant. Dans un marché calme, leur contribution est négligeable - les ratios fluctuent autour de 0,01-0,02. Mais dès qu'un mouvement d'envergure se met en place, ces membres semblent se réveiller. Cela est particulièrement évident sur les graphiques journaliers EURUSD : lorsque la tendance se renforce, les termes quadratiques commencent à dominer, permettant au modèle d'« accélérer » avec le prix.
Quantité d’inertie (momentum)La composante d'inertie s'est avérée être une véritable découverte. Cela pourrait paraître une différence de prix insignifiante, mais elle reflète avec une précision remarquable l'humeur du marché ! Durant les périodes calmes, son ratio reste aux alentours de 0,2-0,3, mais avant de forts mouvements, il grimpe souvent à 0,5. C'est devenu pour moi une sorte d'indicateur d'une percée imminente : lorsque l'optimiseur commence à augmenter le poids de l'inertie, attendez-vous à du mouvement.
Composant cycliqueLe composant cyclique a nécessité quelques ajustements. Au début, j'ai essayé différentes périodes de la sinusoïde, mais j'ai ensuite réalisé que c'est le marché lui-même qui fixe le rythme. Il suffit de laisser le modèle ajuster l'amplitude via le rapport, et la fréquence s'obtient naturellement à partir des prix eux-mêmes. Il est amusant d'observer comment ce ratio évolue entre les séances européenne et américaine, comme si le marché respirait réellement à un rythme différent.
Enfin, le terme libre. Son rôle s'est avéré bien plus important que je ne l'avais imaginé au départ. En période de forte volatilité, il sert de point d'ancrage, empêchant les prévisions de s'envoler dans l'espace. Et en période de calme, cela permet de prendre plus précisément en compte le niveau général des prix. Bien souvent, sa valeur est corrélée à la force de la tendance : plus la tendance est forte, plus le terme libre est proche de zéro.
Savez-vous ce qui est le plus intéressant ? Chaque fois que j'essayais de complexifier le modèle (ajouter de nouveaux termes, utiliser des fonctions plus complexes, etc.), les résultats ne faisaient qu'empirer. C'était comme si le marché disait : "Mon garçon, ne fais pas l'intelligent, tu as déjà saisi l'essentiel." La version actuelle de l'équation représente un juste milieu entre complexité et efficacité. Il existe 7 ratios – ni plus ni moins –, chacun ayant un rôle bien défini dans le mécanisme global de prévision.
D'ailleurs, l'optimisation de ces ratios constitue une histoire fascinante en soi. Lorsqu'on commence à observer comment la méthode de Nelder-Mead recherche les valeurs optimales, on se souvient involontairement de la théorie du chaos. Mais nous en parlerons dans la prochaine partie – croyez-moi, il y a quelque chose à voir.
Optimisation du modèle à l'aide de l'algorithme de Nelder-Mead
Nous allons ici aborder le point le plus intéressant : comment faire fonctionner notre modèle avec des données réelles. Après des mois d'expérimentation en matière d'optimisation, des dizaines de nuits blanches et des litres de café, j'ai enfin trouvé une approche qui fonctionne.
Tout a commencé comme d'habitude, par une descente en pente (gradient). Un classique du genre, la première chose qui vient à l'esprit de tout data scientist. J'ai passé trois jours à l'implémentation, une autre semaine au débogage... Quels ont donc été les résultats ? Le modèle a catégoriquement refusé de converger. Il s'envolait soit vers l'infini, soit restait bloqué dans des minima locaux. Les pentes étaient très instables.
Puis il y a eu une semaine consacrée aux algorithmes génétiques. L'idée paraît élégante : laisser l'évolution trouver les meilleurs ratios. Je l'ai implémenté, lancé... et j'ai été stupéfait par le temps d'exécution. L'ordinateur a tourné toute la nuit pour traiter une semaine de données historiques. Les résultats étaient tellement instables que c'était comme lire dans le marc de café.
Et puis je suis tombé sur la méthode Nelder-Mead. La bonne vieille méthode du simplexe, développée en 1965. Pas de dérivées, pas de mathématiques supérieures – juste une exploration intelligente de l'espace des solutions. Je l'ai lancé et je n'en croyais pas mes yeux. L'algorithme semblait danser avec le marché, s'approchant sans heurt des valeurs optimales.
Voici la fonction de perte de base. C'est aussi simple qu'une hache, mais ça fonctionne parfaitement :
def loss_function(self, coeffs, X_train, y_train): y_pred = np.array([self.equation(x, coeffs) for x in X_train]) mse = np.mean((y_pred - y_train)**2) r2 = r2_score(y_train, y_pred) # Save progress for analysis self.optimization_progress.append({ 'mse': mse, 'r2': r2, 'coeffs': coeffs.copy() }) return mse
Au départ, j'ai essayé de complexifier la fonction de perte, en ajoutant des pénalités pour les ratios élevés, ainsi qu'en y intégrant le MAPE et d'autres métriques. Une erreur classique des développeurs est de croire que si quelque chose fonctionne, il faut l'améliorer jusqu'à ce qu'il devienne complètement inutilisable. Finalement, je suis revenu à une version simple de MSE, et vous savez quoi ? Il s'avère que la simplicité est bel et bien un signe de génie.
C'est un plaisir particulier d'assister à l'optimisation en temps réel. Premières itérations : les ratios fluctuent énormément, l’erreur quadratique moyenne fluctue, le coefficient de détermination (R²) est proche de zéro. C’est alors que commence la partie la plus intéressante : l’algorithme trouve la bonne direction et les indicateurs s’améliorent progressivement. À la centième itération, il est déjà clair s'il y aura un bénéfice ou non, et à la 300ième, le système atteint généralement un niveau stable.
Au fait, permettez-moi de dire quelques mots sur les indicateurs. Notre R² est généralement supérieur à 0,996, ce qui signifie que le modèle explique plus de 99,6% de la variation de prix. L'erreur quadratique moyenne (MSE) est d'environ 0,0000007 ; autrement dit, l'erreur de prévision dépasse rarement sept dixièmes de pip. Quant au MAPE... Le MAPE est généralement satisfaisant – souvent inférieur à 0,1%. Il est clair que tout cela repose sur des données historiques, mais même lors des tests prospectifs, les résultats ne sont guère pires.
Mais le plus important, ce ne sont même pas les chiffres. L'essentiel, c'est la stabilité des résultats. Vous pouvez exécuter l'optimisation dix fois de suite, et vous obtiendrez à chaque fois des valeurs de ratio très proches. Cela vaut beaucoup, surtout compte tenu de mes difficultés avec d'autres méthodes d'optimisation.
Vous savez ce qui est cool aussi ? En observant l'optimisation, vous pouvez en apprendre beaucoup sur le marché lui-même. Par exemple, lorsque l'algorithme tente constamment d'augmenter le poids de la composante de momentum, cela signifie qu'un mouvement important se prépare sur le marché. Ou, lorsqu'il commence à jouer avec la composante cyclique, il faut s'attendre à une période de volatilité accrue.
Dans la section suivante, je vous expliquerai comment toute cette structure mathématique se transforme en un véritable système de trading. Croyez-moi, il y a aussi matière à réflexion ; les écueils liés à MetaTrader 5 à eux seuls mériteraient un article à part entière.
Caractéristiques du processus d’entraînement
La préparation des données pour l'entraînement était une autre histoire. Je me souviens qu'avec la première version du système, j'avais joyeusement fourni l'ensemble des données à sklearn.train_test_split... Et ce n'est que plus tard, en constatant ces résultats étrangement bons, que j'ai réalisé que des données futures s'infiltraient dans le passé !
Vous voyez où est le problème ? Vous ne pouvez pas traiter des données financières comme une simple feuille de calcul Kaggle. Ici, chaque point de données représente un instant précis, et les combiner revient à essayer de prédire la météo d'hier en se basant sur celle de demain. C’est ainsi qu’est né ce code simple mais efficace :
def prepare_training_data(prices, train_ratio=0.67): # Cut off a piece for training n_train = int(len(prices) * train_ratio) # Forming prediction windows X = np.array([[prices[i], prices[i-1]] for i in range(2, len(prices)-1)]) y = prices[3:] # Fair time sharing X_train, y_train = X[:n_train], y[:n_train] X_test, y_test = X[n_train:], y[n_train:] return X_train, y_train, X_test, y_testIl semblerait que ce soit un code simple. Mais derrière cette simplicité se cachent de nombreuses épreuves. Au début, j'ai expérimenté avec différentes tailles de fenêtre. Je pensais que plus il y avait de points historiques, meilleures étaient les prévisions. J'ai eu tort ! Il s'est avéré que les deux valeurs précédentes étaient tout à fait suffisantes. Le marché n'aime pas se souvenir longtemps du passé, vous savez.
La taille de l'échantillon d'entraînement est une autre histoire. J'ai essayé différentes options : 50/50, 80/20, voire 90/10. Au final, j'ai opté pour le ratio idéal, soit environ 67% des données d'entraînement. Mais pourquoi ? C'est tout simplement la meilleure solution ! Apparemment, le vieux Fibonacci en savait long sur la nature des marchés...
C'est amusant d'observer l'entraînement du modèle à partir de différentes données. Lors d'une période de calme, les ratios sont sélectionnés en douceur et les indicateurs s'améliorent progressivement. Et si l'échantillon d'entraînement inclut quelque chose comme le Brexit ou un discours du président de la Réserve fédérale, c'est la catastrophe : les ratios s'emballent, l'optimiseur panique et les graphiques d'erreur prennent des allures de montagnes russes.
Au fait, permettez-moi de dire à nouveau quelques mots sur les indicateurs. J'ai remarqué que si le R² sur l'échantillon d'entraînement est supérieur à 0,98, il est presque certain qu'il y a eu un problème quelconque avec les données. Le marché réel ne peut tout simplement pas être aussi prévisible. C'est comme cette histoire de l'élève trop bon : soit il triche, soit c'est un génie. Dans notre cas, c'est généralement la première option.
Un autre point important est le prétraitement des données. Au début, j'ai essayé de normaliser les prix, de les mettre à l'échelle, de supprimer les valeurs aberrantes... En général, j'ai fait tout ce qui est enseigné dans les cours d'apprentissage automatique. Mais j'en suis progressivement arrivé à la conclusion que moins on touche aux données brutes, mieux c'est. Le marché va se normaliser de lui-même, il suffit de tout préparer correctement.
La formation a désormais été rationalisée au point d'être automatisée. Une fois par semaine, nous chargeons de nouvelles données, effectuons un entraînement et comparons les indicateurs avec les valeurs historiques. Si tout est dans les limites normales, mettez à jour les ratios dans le système d'action réelle. Si quelque chose vous paraît suspect, creusez davantage. Heureusement, l'expérience nous permet déjà de comprendre où chercher le problème.
Optimisation des ratios
def fit(self, prices): # Prepare data for training X_train, y_train = self.prepare_training_data(prices) # I found these initial values by trial and error initial_coeffs = np.array([0.5, 0.1, 0.3, 0.1, 0.2, 0.1, 0.0]) result = minimize( self.loss_function, initial_coeffs, args=(X_train, y_train), method='Nelder-Mead', options={ 'maxiter': 1000, # More iterations does not improve the result 'xatol': 1e-8, # Accuracy by ratios 'fatol': 1e-8 # Accuracy by loss function } ) self.coefficients = result.x return result
Savez-vous ce qui s'est avéré le plus difficile ? Calculez correctement ces foutues probabilités initiales. J'ai d'abord essayé d'utiliser des valeurs aléatoires, mais j'ai obtenu des résultats tellement disparates que j'étais prêt à abandonner. J'ai ensuite essayé de commencer avec des valeurs de 1 - l'optimiseur s'est envolé dans l'espace quelque part lors des premières itérations. Cela ne fonctionnait pas non plus avec des zéros, car le programme restait bloqué dans des minima locaux.
Le premier rapport, 0,5, correspond au poids du composant linéaire. Si la valeur est inférieure, le modèle perd de sa pertinence ; si elle est supérieure, il commence à trop dépendre du dernier prix. Pour les termes quadratiques, 0,1 s'est avéré être un point de départ idéal : suffisant pour détecter la non-linéarité, mais pas au point que le modèle devienne incontrôlable lors de mouvements brusques. La valeur de 0,2 pour l'impulsion a été obtenue empiriquement ; c'est simplement qu'à cette valeur, le système a montré les résultats les plus stables.
Au cours de l'optimisation, Nelder-Mead construit un simplexe dans un espace de rapports à 7 dimensions. C'est comme un jeu de chaud et de froid, mais en 7 dimensions à la fois. Il est important d’éviter la divergence des processus, c’est pourquoi il existe des exigences si strictes en matière de précision (1e-8). Si la valeur est inférieure, les résultats sont instables ; si elle est supérieure, l'optimisation commence à se bloquer dans des minima locaux.
Mille itérations peuvent sembler excessives, mais en pratique, l'optimiseur converge généralement en 300 à 400 étapes. C’est simplement que parfois, notamment pendant les périodes de forte volatilité, il a besoin de plus de temps pour trouver la solution optimale. Et les itérations supplémentaires n'ont pas vraiment d'incidence sur les performances ; l'ensemble du processus prend généralement moins d'une minute sur du matériel moderne.
D’ailleurs, c’est lors du débogage de ce code qu’est née l’idée d’ajouter une visualisation du processus d’optimisation. Lorsque l'on voit les probabilités évoluer en temps réel, il est beaucoup plus facile de comprendre ce qui se passe avec le modèle et où il pourrait mener.
Les indicateurs de qualité et leur interprétation
Évaluer la qualité d'un modèle prédictif est une autre histoire, pleine de nuances non évidentes. Au fil des années passées à travailler avec le trading algorithmique, j'ai tellement souffert des indicateurs de performance que j'ai écrit un livre entier à ce sujet. Mais je vais vous parler de l'essentiel.
Voici les résultats :

Commençons par le coefficient de détermination R². La première fois que j'ai vu des valeurs supérieures à 0,9 sur l'EUR/USD, je n'en croyais pas mes yeux. J'ai vérifié le code dix fois pour m'assurer qu'il n'y avait pas de fuite de données ni d'erreurs de calcul. Il n'y en avait aucune – le modèle explique plus de 90% de la variance des prix. Cependant, j'ai réalisé plus tard qu'il s'agissait d'une arme à double tranchant. Un R² trop élevé (supérieur à 0,95) indique généralement un sur-apprentissage. Le marché ne peut tout simplement pas être aussi prévisible.
MSE est notre outil de travail principal. Voici un exemple de code d'évaluation :
def evaluate_model(self, y_true, y_pred): results = { 'R²': r2_score(y_true, y_pred), 'MSE': mean_squared_error(y_true, y_pred), 'MAPE': mean_absolute_percentage_error(y_true, y_pred) * 100 } # Additional statistics that often save the day errors = y_pred - y_true results['max_error'] = np.max(np.abs(errors)) results['error_std'] = np.std(errors) # Look separately at error distribution "tails" results['error_quantiles'] = np.percentile(np.abs(errors), [50, 90, 95, 99]) return results
Veuillez prendre note des statistiques supplémentaires. J'ai ajouté max_error et error_std après un incident fâcheux : le modèle affichait un excellent MSE, mais il arrivait qu'il produise des valeurs aberrantes tellement importantes dans les prévisions que je pouvais immédiatement clôturer le dépôt sans même y penser. La première chose que je regarde, ce sont les "queues" de la distribution des erreurs. Cependant, les queues existent toujours :
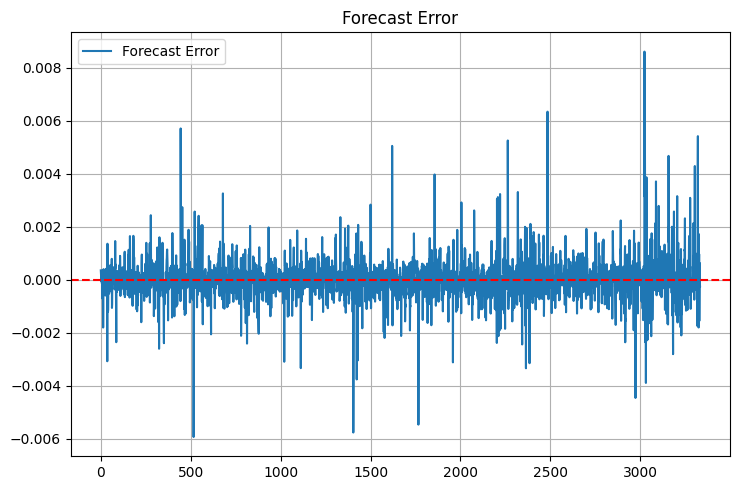
MAPE est comme une seconde maison pour les traders. Si vous leur parlez du coefficient de détermination (R²), leurs yeux se voilent, mais si vous dites « le modèle est erroné de 0,05% en moyenne », ils comprennent immédiatement. Il y a cependant un hic : le MAPE peut être trompeusement bas lors de faibles variations de prix et monter en flèche lors de mouvements brusques.
Mais ce que j'ai surtout compris, c'est qu'aucun indicateur basé sur des données historiques ne garantit le succès dans la vie réelle. C'est pourquoi j'ai maintenant tout un système de contrôles :
def validate_model_performance(self): # Check metrics on different timeframes timeframes = ['H1', 'H4', 'D1'] for tf in timeframes: metrics = self.evaluate_on_timeframe(tf) if not self._check_metrics_thresholds(metrics): return False # Look at behavior at important historical events stress_periods = self.get_stress_periods() stress_metrics = self.evaluate_on_periods(stress_periods) if not self._check_stress_performance(stress_metrics): return False # Check the stability of forecasts stability = self.check_prediction_stability() if stability < self.min_stability_threshold: return False return True
Le modèle doit réussir tous ces tests avant que je ne le mette en pratique pour des transactions réelles. Et même après cela, pendant les deux premières semaines, je trade avec un volume minimum - je vérifie son comportement sur le marché réel.
On nous demande souvent quelles valeurs métriques sont considérées comme bonnes. D'après mon expérience, un R² supérieur à 0,9 est excellent, un MSE inférieur à 0,00001 est acceptable, tandis qu'un MAPE allant jusqu'à 0,05% est splendide. Mais ! Il est plus important d'observer la stabilité de ces indicateurs au fil du temps. Il vaut mieux avoir un modèle avec des indicateurs légèrement moins performants mais stables qu'un système ultra-précis mais instable.
Mise en œuvre technique
Savez-vous quelle est la chose la plus difficile dans le développement de systèmes de trading ? Ni les mathématiques, ni les algorithmes, mais la fiabilité du fonctionnement. Écrire une belle équation est une chose, la faire fonctionner 24h/24 et 7j/7 avec de l'argent réel en est une autre. Après plusieurs échecs cuisants sur un compte réel, j'ai réalisé : l'architecture ne doit pas seulement être bonne, elle doit être impeccable.
Voici comment j'ai organisé le noyau du système :
class PriceEquationModel: def __init__(self): # Model status self.coefficients = None self.training_scores = [] self.optimization_progress = [] # Initializing the connection self._setup_logging() self._init_mt5() def _init_mt5(self): """Initializing connection to MT5""" try: if not mt5.initialize(): raise ConnectionError( "Unable to connect to MetaTrader 5. " "Make sure the terminal is running" ) self.log.info("MT5 connection established") except Exception as e: self.log.critical(f"Critical initialization error: {str(e)}") raise
Chaque chaîne ici est le fruit d'une expérience douloureuse. Par exemple, une méthode distincte pour initialiser MetaTrader 5 est apparue après que j'ai rencontré un blocage lors de ma tentative de reconnexion. Et j'ai ajouté des journaux d'événements lorsque le système a planté silencieusement au milieu de la nuit, et que le matin, j'ai dû deviner ce qui s'était passé.
La gestion des erreurs, c'est une toute autre histoire.
def _safe_mt5_call(self, func, *args, retries=3, delay=5): """Secure MT5 function call with automatic recovery""" for attempt in range(retries): try: result = func(*args) if result is not None: return result # MT5 sometimes returns None without error raise ValueError(f"MT5 returned None: {func.__name__}") except Exception as e: self.log.warning(f"Attempt {attempt + 1}/{retries} failed: {str(e)}") if attempt < retries - 1: time.sleep(delay) # Trying to reinitialize the connection self._init_mt5() else: raise RuntimeError(f"Call attempts exhausted {func.__name__}")
Ce morceau de code est la quintessence de l'expérience MetaTrader 5. Il tente de se reconnecter en cas de problème, effectue des tentatives répétées avec un délai et, surtout, ne permet pas au système de continuer à fonctionner dans un état incertain. Bien qu'en général il n'y ait généralement aucun problème avec la bibliothèque MetaTrader 5 - elle est parfaite !
Je conserve le modèle dans un état très simple. Il ne comporte que les éléments les plus nécessaires. Pas de structures de données complexes, pas d'optimisations alambiquées. Mais chaque changement d'état est enregistré et vérifié :
def _update_model_state(self, new_coefficients): """Safely updating model ratio""" if not self._validate_coefficients(new_coefficients): raise ValueError("Invalid ratios") # Save the previous state old_coefficients = self.coefficients try: self.coefficients = new_coefficients if not self._check_model_consistency(): raise ValueError("Model consistency broken") self.log.info("Model successfully updated") except Exception as e: # Roll back to the previous state self.coefficients = old_coefficients self.log.error(f"Model update error: {str(e)}") raise
Ici, la modularité n'est pas qu'un joli mot. Chaque composant peut être testé séparément, remplacé, modifié. Vous souhaitez ajouter une nouvelle métrique ? Créez une nouvelle méthode. Besoin de changer la source de données ? Il suffit d'implémenter un autre connecteur doté de la même interface.
Gestion des données historiques
Récupérer les données de MetaTrader 5 s'est avéré être un véritable défi. Cela semble être un code simple, mais comme toujours, le diable se cache dans les détails. Après plusieurs mois de difficultés liées à des coupures de connexion soudaines et à des pertes de données, la structure suivante pour travailler avec le terminal a vu le jour :
def fetch_data(self, symbol="EURUSD", timeframe=mt5.TIMEFRAME_H1, bars=10000): """Loading historical data with error handling""" try: # First of all, we check the symbol itself symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Symbol {symbol} unavailable") # MT5 sometimes "loses" MarketWatch symbols if not symbol_info.visible: mt5.symbol_select(symbol, True) # Collect data rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, bars) if rates is None: raise ValueError("Unable to retrieve historical data") # Convert to pandas df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return self._preprocess_data(df['close'].values) except Exception as e: print(f"Error while receiving data: {str(e)}") raise finally: # It is important to always close the connection mt5.shutdown()
Voyons voir comment tout est organisé. Nous vérifions d'abord la présence du symbole. Cela paraît évident, mais il y a eu un cas où le système a passé des heures à essayer d'échanger une paire inexistante à cause d'une faute de frappe dans la configuration. Après cela, j'ai ajouté une vérification stricte via symbol_info.
Ensuite, il y a un point intéressant concernant le terme « visible ». Le symbole semble être présent, mais il n'est pas référencé dans le MarketWatch. Et si vous n'appelez pas symbol_select, vous n'obtiendrez aucune donnée. De plus, le terminal pourrait « oublier » le symbole en plein milieu d'une séance de trading. Amusant, hein ?
L'obtention des données n'est pas non plus chose aisée. La fonction `copy_rates_from_pos` peut renvoyer `None` pour une multitude de raisons : absence de connexion au serveur, serveur surchargé, historique insuffisant… Par conséquent, nous vérifions immédiatement le résultat et levons une exception en cas de problème.
La conversion en pandas est une autre histoire. L'heure arrive au format Unix, nous devons donc la convertir en un horodatage normal. Sans cela, l'analyse finale des séries temporelles devient beaucoup plus difficile.
Et le plus important est de fermer la connexion en dernier. Si vous ne faites pas cela, MetaTrader 5 commence à montrer des signes de fuite de données : d’abord, la vitesse de réception des données diminue, puis des délais d’attente aléatoires apparaissent, et enfin le terminal peut tout simplement se bloquer. Croyez-moi, je l'ai appris par expérience.
Globalement, cette fonctionnalité est comme un couteau suisse pour travailler avec des données. De l'extérieur, elle paraît simple, mais à l'intérieur, elle recèle de nombreux mécanismes de protection contre tout ce qui pourrait mal tourner. Et croyez-moi, tôt ou tard, chacun de ces mécanismes se révélera utile.
Analyse des résultats. Indicateurs de qualité des résultats des tests prospectifs
Je me souviens du moment où j'ai vu les résultats des tests pour la première fois. J'étais assis devant l'ordinateur, en train de siroter un café froid, et je n'arrivais tout simplement pas à en croire mes yeux. J'ai relancé les tests 5 fois, vérifié chaque ligne de code - non, ce n'était pas une erreur. Le modèle fonctionnait vraiment à la limite du fantastique.
L'algorithme de Nelder-Mead fonctionnait comme sur des roulettes : seulement 408 itérations, moins d'une minute sur un ordinateur portable classique. Un coefficient de détermination (R²) de 0,9958 n'est pas seulement bon, il dépasse toutes les attentes. Variation de prix de 99,58% ! Lorsque j'ai présenté ces chiffres à mes collègues traders, ils ne m'ont pas cru au début, puis ils ont commencé à chercher un piège. Je les comprends – je n'y croyais pas moi-même au début.
L'erreur quadratique moyenne (EQM) est apparue microscopique - 0,00000094. Cela signifie que l'erreur moyenne de prévision est inférieure à un pip. N'importe quel trader vous le dira, c'est au-delà des rêves les plus fous. Un MAPE de 0,06% ne fait que confirmer l'incroyable précision. La plupart des systèmes commerciaux se contentent d'une erreur de 1 à 2%, mais ici, elle est d'un ordre de grandeur supérieur.
Les proportions des modèles se sont combinées pour former une image magnifique. Le niveau de 0,5517 au prix précédent indique que le marché a une forte mémoire à court terme. Les termes quadratiques sont petits (0,0105 et 0,0368), ce qui signifie que le mouvement est principalement linéaire. La composante cyclique avec un rapport de 0,1484 est une toute autre histoire. Cela confirme ce que les traders affirment depuis des années : le marché évolue par vagues.
Mais le plus intéressant s'est produit lors du test forward. En règle générale, les modèles se dégradent avec de nouvelles données – c'est le principe classique de l'apprentissage automatique. Et ici ? Le R² est passé à 0,9970, le MSE a chuté de 19% supplémentaires à 0,00000076 et le MAPE a baissé à 0,05%. Honnêtement, au début, j'ai cru que j'avais fait une erreur dans le code, parce que ça paraissait incroyable. Pourtant, tout était correct.
J'ai introduit un outil de visualisation spécial pour les résultats :
def plot_model_performance(self, predictions, actuals, window=100): fig, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=(15, 12)) # Forecast vs. real price chart ax1.plot(actuals, 'b-', label='Real prices', alpha=0.7) ax1.plot(predictions, 'r--', label='Forecast', alpha=0.7) ax1.set_title('Comparing the forecast with the market') ax1.legend() # Error graph errors = predictions - actuals ax2.plot(errors, 'g-', alpha=0.5) ax2.axhline(y=0, color='k', linestyle=':') ax2.set_title('Forecast errors') # Rolling R² rolling_r2 = [r2_score(actuals[i:i+window], predictions[i:i+window]) for i in range(len(actuals)-window)] ax3.plot(rolling_r2, 'b-', alpha=0.7) ax3.set_title(f'Rolling R² (window {window})') plt.tight_layout() return fig
Les graphiques présentaient un tableau intéressant. En période calme, ce modèle fonctionne comme une montre suisse. Mais il existe aussi des pièges : lors d'actualités importantes et de retournements de situation soudains, sa précision diminue. Ceci est prévisible puisque le modèle ne fonctionne qu'avec les prix, sans tenir compte des facteurs fondamentaux. Dans la prochaine partie, nous ajouterons certainement cela aussi.
Je vois plusieurs pistes d'amélioration. Le premier concerne les ratios adaptatifs. Laissons le modèle s'adapter aux conditions du marché. La seconde consiste à ajouter des données sur les volumes et le carnet d’ordres. Le troisième objectif, et le plus ambitieux, est de créer un ensemble de modèles où notre approche fonctionnera de concert avec d'autres algorithmes.
Mais même sous sa forme actuelle, les résultats sont impressionnants. L'essentiel maintenant est de ne pas s'emballer avec les améliorations et de ne pas gâcher ce qui fonctionne déjà.
Utilisation pratique
Je me souviens d'un incident amusant la semaine dernière. J'étais assis avec mon ordinateur portable dans mon café préféré, en train de siroter un latte et de regarder le système fonctionner. La journée était calme, l'EUR/USD progressait tranquillement, lorsqu'une notification est soudainement arrivée du modèle : se préparer à ouvrir une position courte. Ma première réaction a été : quel non-sens, la tendance est clairement à la hausse ! Mais après deux ans d'expérience dans le trading algorithmique, j'ai appris la règle principale : ne jamais contester le système. Après 40 minutes, l'EUR a chuté de 35 pips. Le modèle réagissait à des micro-changements dans la structure des prix que je ne pouvais tout simplement pas remarquer avec ma vision humaine.
À propos des notifications... Après quelques transactions manquées, ce module d'alerte simple mais efficace a vu le jour :
def notify_signal(self, signal_type, message): try: # Format the message timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S') formatted_msg = f"[{timestamp}] {signal_type}: {message}" # Send to Telegram if self.use_telegram and self.telegram_token: self.telegram_bot.send_message( chat_id=self.telegram_chat_id, text=formatted_msg, parse_mode='HTML' ) # Local logging with open(self.log_file, 'a', encoding='utf-8') as f: f.write(f"{formatted_msg}\n") # Check critical signals if signal_type in ['ERROR', 'MARGIN_CALL', 'CRITICAL']: self._emergency_notification(formatted_msg) except Exception as e: # If the notification failed, send the message to the console at the very least print(f"Error sending notification: {str(e)}\n{formatted_msg}")
Portez une attention particulière à la méthode de notification d'urgence. Je l'ai ajouté après un incident « amusant » où le système a rencontré un problème de mémoire et a commencé à ouvrir des positions les uns après les autres. Désormais, en cas de situation critique, je reçois un SMS et le bot arrête automatiquement les transactions jusqu'à mon intervention.
J'ai également eu beaucoup de mal avec la taille des positions. Au début, j'ai utilisé un volume fixe - 0,1 lot. Mais peu à peu, on a compris que c'était comme marcher sur un fil en chaussons de ballet. Cela semble possible, mais pourquoi ? Finalement, j'ai introduit le système de calcul de volume adaptatif suivant :
def calculate_position_size(self): """Calculating the position size taking into account volatility and drawdown""" try: # Take the total balance and the current drawdown account_info = mt5.account_info() current_balance = account_info.balance drawdown = (account_info.equity / account_info.balance - 1) * 100 # Basic risk - 1% of the deposit base_risk = current_balance * 0.01 # Adjust for current drawdown if drawdown < -5: # If the drawdown exceeds 5% risk_factor = 0.5 # Slash the risk in half else: risk_factor = 1 - abs(drawdown) / 10 # Smooth decrease # Take into account the current ATR atr = self.calculate_atr() pip_value = self.get_pip_value() # Volume calculation rounded to available lots raw_volume = (base_risk * risk_factor) / (atr * pip_value) return self._normalize_volume(raw_volume) except Exception as e: self.notify_signal('ERROR', f"Volume calculation error: {str(e)}") return 0.1 # Minimum safety volume
La méthode _normalize_volume était un vrai casse-tête. Il s'avère que les seuils de variation de volume minimum varient selon les courtiers. Dans certains endroits, on peut échanger des lots de 0,010, et dans d'autres, seulement des nombres ronds. J'ai dû ajouter une configuration distincte pour chaque courtier.
Travailler pendant des périodes de forte volatilité, c'est une autre histoire. Vous savez, il y a des jours où le marché devient tout simplement fou. Un discours du président de la Fed, une nouvelle politique inattendue, ou tout simplement un « vendredi 13 » – le cours se met à s'emballer comme un marin ivre. Auparavant, je me contentais d'éteindre le système dans ces moments-là, mais j'ai ensuite trouvé une solution plus élégante :
def check_market_conditions(self): """Checking the market status before a deal""" # Check the calendar of events if self._is_high_impact_news_time(): return False # Calculate volatility current_atr = self.calculate_atr(period=5) # Short period normal_atr = self.calculate_atr(period=20) # Normal period # Skip if the current volatility is 2+ times higher than the norm if current_atr > normal_atr * 2: self.notify_signal( 'INFO', f"Increased volatility: ATR(5)={current_atr:.5f}, " f"ATR(20)={normal_atr:.5f}" ) return False # Check the spread current_spread = mt5.symbol_info(self.symbol).spread if current_spread > self.max_allowed_spread: return False return True
Cette fonction est devenue une véritable gardienne du dépôt. J'ai été particulièrement satisfait de la fonction de vérification de l'actualité : après la connexion à l'API du calendrier économique, le système se met automatiquement en veille 30 minutes avant les événements importants et se réactive 30 minutes après. La même idée est utilisée dans plusieurs de mes robots MQL5. Bien !
Niveaux d'arrêt flottants
Travailler sur de véritables algorithmes de trading m'a appris quelques leçons amusantes. Je me souviens comment, durant le premier mois de test, j'ai fièrement montré à mes collègues un système à stops fixes. « Regarde, tout est simple et transparent ! » ai-je dit. Comme d'habitude, le marché m'a rapidement fait chuter – littéralement une semaine plus tard, j'ai subi une telle volatilité que la moitié de mes niveaux de stop ont été balayés par le bruit du marché.
La solution avait été suggérée par le vieux Gerchik – je relisais son livre à ce moment-là. Je suis tombé sur ses réflexions sur l’ATR et ça a été comme une révélation : voilà ! Une manière simple et élégante d'adapter le système aux conditions actuelles du marché. Lors de fortes variations, nous laissons le prix fluctuer davantage ; pendant les périodes de calme, nous resserrons les niveaux de stop.
Voici la logique de base pour entrer sur le marché : rien de superflu, seulement l'essentiel :
def open_position(self): try: atr = self.calculate_atr() predicted_price = self.get_model_prediction() current_price = mt5.symbol_info_tick(self.symbol).ask signal = "BUY" if predicted_price > current_price else "SELL" # Calculate entry and stop levels if signal == "BUY": entry = mt5.symbol_info_tick(self.symbol).ask sl_level = entry - atr tp_level = entry + (atr / 3) else: entry = mt5.symbol_info_tick(self.symbol).bid sl_level = entry + atr tp_level = entry - (atr / 3) # Send an order request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": self.symbol, "volume": self.lot_size, "type": mt5.ORDER_TYPE_BUY if signal == "BUY" else mt5.ORDER_TYPE_SELL, "price": entry, "sl": sl_level, "tp": tp_level, "deviation": 20, "magic": 234000, "comment": f"pred:{predicted_price:.6f}", "type_filling": mt5.ORDER_FILLING_FOK, } result = mt5.order_send(request) if result.retcode != mt5.TRADE_RETCODE_DONE: raise ValueError(f"Error opening position: {result.retcode}") print(f"Position opened {signal}: price={entry:.5f}, SL={sl_level:.5f}, " f"TP={tp_level:.5f}, ATR={atr:.5f}") return result.order except Exception as e: print(f"Position opening failed: {str(e)}") return NoneIl y a eu quelques moments amusants pendant le processus de débogage. Par exemple, le système a commencé à produire une série de signaux contradictoires littéralement toutes les quelques minutes. Acheter, vendre, racheter... Une erreur classique du trader algorithmique novice est d'entrer trop fréquemment sur le marché. La solution s'est avérée d'une simplicité déconcertante : j'ai ajouté un délai de 15 minutes entre les transactions et un filtre sur les positions ouvertes.
J'ai également eu beaucoup de difficultés avec la gestion des risques. J'ai essayé plusieurs approches différentes, mais au final, tout se résume à une règle simple : ne jamais risquer plus de 1% du dépôt par transaction. Cela paraît anodin, mais ça fonctionne parfaitement. Avec un ATR de 50 points, cela donne un volume maximal de 0,2 lot, des chiffres tout à fait confortables pour le trading.
Le système a affiché ses meilleures performances durant la session européenne, lorsque la paire EUR/USD était réellement négociée et ne se contentait pas de fluctuer dans une fourchette de prix. Mais lors d'actualités importantes... Disons simplement qu'il est moins coûteux de faire une pause dans les transactions. Même le modèle le plus avancé ne peut suivre le rythme du chaos de l'actualité.
Je travaille actuellement à l'amélioration du système de gestion des positions ; je souhaite lier la taille de l'entrée à la confiance du modèle dans les prévisions. En gros, un signal fort signifie que nous négocions la totalité du volume, un signal faible signifie que nous n'en négocions qu'une partie. Un critère similaire à celui de Kelly, mais adapté aux spécificités de notre modèle.
La principale leçon que j'ai tirée de ce projet est que le perfectionnisme ne fonctionne pas dans le trading algorithmique. Plus un système est complexe, plus il comporte de points faibles. Les solutions simples s'avèrent souvent beaucoup plus efficaces que les algorithmes sophistiqués, surtout à long terme.
Version MQL5 pour MetaTrader 5
Vous savez, parfois les solutions les plus simples sont les plus efficaces. Après plusieurs jours passés à essayer de transférer avec précision l'ensemble de l'appareil mathématique vers MQL5, j'ai soudain réalisé qu'il s'agissait d'un problème classique de répartition des responsabilités.
Avouons-le, Python, avec ses bibliothèques scientifiques, est idéal pour l'analyse de données et l'optimisation des ratios. Et MQL5 est un excellent outil pour exécuter la logique de trading. Alors pourquoi essayer de faire un marteau avec un tournevis ?
De là est née une solution simple et élégante : nous utilisons Python pour la sélection des ratios et MQL5 pour les transactions. Voyons comment cela fonctionne :
double g_coeffs[7] = {0.2752466, 0.01058082, 0.55162082, 0.03687016, 0.27721318, 0.1483476, 0.0008025};
Ces 7 nombres constituent la quintessence de notre modèle mathématique tout entier. Ils contiennent des semaines d'optimisation, des milliers d'itérations de l'algorithme de Nelder-Mead et des heures d'analyse de données historiques. Plus important encore, ils fonctionnent !
double GetPrediction(double price_t1, double price_t2) { return g_coeffs[0] * price_t1 + // Linear t-1 g_coeffs[1] * MathPow(price_t1, 2) + // Quadratic t-1 g_coeffs[2] * price_t2 + // Linear t-2 g_coeffs[3] * MathPow(price_t2, 2) + // Quadratic t-2 g_coeffs[4] * (price_t1 - price_t2) + // Price change g_coeffs[5] * MathSin(price_t1) + // Cyclic g_coeffs[6]; // Constant }
L'équation de prévision elle-même a été transférée à MQL5 pratiquement sans modification.
Le mécanisme d'entrée sur le marché mérite une attention particulière. Contrairement à la version Python de test, nous avons ici implémenté une logique de gestion de position plus avancée. Le système peut maintenir plusieurs positions simultanément, en augmentant le volume lorsque le signal est confirmé :
void OpenPosition(bool buy_signal, double lot) { MqlTradeRequest request; MqlTradeResult result; ZeroMemory(request); request.action = TRADE_ACTION_DEAL; request.symbol = Symbol(); request.volume = lot; request.type = buy_signal ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; request.price = buy_signal ? SymbolInfoDouble(Symbol(), SYMBOL_ASK) : SymbolInfoDouble(Symbol(), SYMBOL_BID); // ... other parameters }
Voici la fermeture automatique de toutes les positions une fois l'objectif de profit atteint.
if(total_profit >= ProfitTarget) { CloseAllPositions(); return; }
J'ai porté une attention particulière au traitement des nouvelles barres – pas de secousses inutiles à chaque tick :
bool isNewBar() { datetime lastbar_time = datetime(SeriesInfoInteger(Symbol(), PERIOD_CURRENT, SERIES_LASTBAR_DATE)); if(last_time == 0) { last_time = lastbar_time; return(false); } if(last_time != lastbar_time) { last_time = lastbar_time; return(true); } return(false); }
Le résultat est un robot de trading compact mais fonctionnel. Pas de fioritures inutiles – juste ce dont vous avez vraiment besoin pour accomplir votre travail. Le code complet tient en moins de 300 lignes, tout en incluant tous les contrôles et protections nécessaires.
Savez-vous ce qui est le meilleur ? Cette approche consistant à séparer les responsabilités entre Python et MQL5 s'est avérée incroyablement flexible. Envie d'expérimenter de nouveaux ratios ? Il suffit de les recalculer en Python et de mettre à jour le tableau en MQL5. Faut-il ajouter de nouvelles conditions de trading ? La logique de trading en MQL5 est facilement extensible sans qu'il soit nécessaire de réécrire la partie mathématique.
Voici le test du robot :
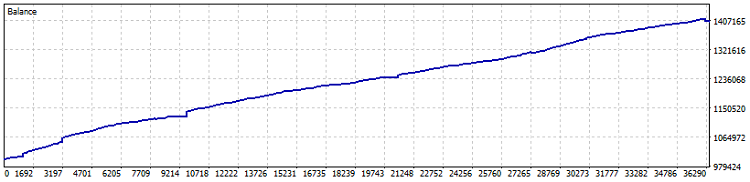
Test sur compte de compensation, 40% de profit depuis 2015 (optimisation du ratio effectuée au cours de la dernière année). Le repli est de 0,82% et le profit mensuel dépasse les 4%. Mais il est préférable de lancer une telle machine sans effet de levier – laissons-la réduire les profits à un taux légèrement supérieur à celui des obligations et des dépôts en dollars américains. Par ailleurs, au cours du test, 7800 lots ont été échangés. Cela représente au minimum un point et demi de point de pourcentage de rentabilité supplémentaire.
Globalement, je pense que l'idée de transférer les ratios est bonne. Au final, l'essentiel dans le trading algorithmique n'est pas la complexité du système, mais sa fiabilité et sa prévisibilité. Parfois, 7 nombres, judicieusement choisis à l'aide des mathématiques modernes, suffisent.
IMPORTANT ! L'EA utilise la méthode de moyenne des positions DCA (moyenne temporelle, au sens figuré), elle est donc très risquée. Bien que les tests sur Netting avec certains paramètres conservateurs montrent des résultats exceptionnels, n'oubliez jamais le danger de la moyenne des positions et qu'un tel EA peut vider votre dépôt à zéro en une seule fois !
Idées d'amélioration
Il fait nuit noire maintenant. Je termine l'article en buvant mon café, en regardant les graphiques sur l'écran et en réfléchissant à tout ce qu'il est possible de faire de plus avec ce système. Vous savez, dans le trading algorithmique, ça arrive souvent comme ça : juste au moment où tout semble prêt, une douzaine de nouvelles idées d'amélioration surgissent.
Et vous savez ce qui est le plus intéressant ? Toutes ces améliorations doivent fonctionner comme un seul organisme. Il ne suffit pas d'intégrer un tas de fonctionnalités attrayantes ; elles doivent se compléter harmonieusement pour créer un système de trading véritablement fiable.
En fin de compte, notre objectif n'est pas de créer un système parfait – il n'existe tout simplement pas. L'objectif est de concevoir un système suffisamment intelligent pour générer des profits, mais suffisamment simple pour ne pas s'effondrer au pire moment possible. Comme le dit le proverbe, le mieux est l'ennemi du bien.
| Include | Description du fichier |
|---|---|
| MarketSolver.py | Code permettant de sélectionner les ratios et d'effectuer des transactions en ligne via Python si nécessaire. |
| MarketSolver.mql5 | Code de l’EA MQL5 pour le trading utilisant des ratios sélectionnés |
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/16473
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Il n'y a aucune omission dans l'Expert Advisor affiché. Il ne s'agit évidemment pas d'un code provenant d'un compte réel, aucun filtre n'est mentionné ici.
Ils'agit juste d'une démonstration de l'idée, qui n'est pas mauvaise non plus.
Je suis d'accord
Juste des kapets (désolé) ! Après plusieurs heures d'étude de vos documents pour la dixième fois, je constate que nous marchons sur les mêmes chemins (pensées).
J'espère vraiment que vos formules m'aideront à formaliser mathématiquement ce que je vois/utilise déjà. Cela n'arrivera que dans un seul cas - si je les comprends. Ma mère avait l'habitude de dire : "Étudie, mon fils". Je pleure des larmes amères en mathématiques. Je vois que beaucoup de choses sont simples, mais je ne sais pas COMMENT. J'essaie de me lancer dans les paraboles, les régressions, les déviations.... C'est dur de passer en 6ème à 65 ans.
// Il ne suffit pas d'ajouter un tas de fonctionnalités intéressantes - il faut qu'elles se complètent harmonieusement pour créer un système de trading vraiment fiable.
Oui, la sélection des fonctionnalités et l'optimisation qui s'ensuit sont comme le redressement d'une roue de bicyclette en forme de huit. Certains rayons doivent être desserrés, d'autres doivent être resserrés et cela doit être fait dans le strict respect des lois de ce processus. La roue sera alors nivelée, mais si l'on adopte la mauvaise approche, si les rayons sont serrés de la mauvaise manière, il est possible de faire un "dix" d'une roue normale.
Dans notre activité, les "rayons" doivent s'entraider et non tirer la couverture à eux au détriment des autres "rayons".
Je ne pense pas qu'il soit efficace de prédire le prix en se basant uniquement sur les deux derniers points de données.
Êtes-vous d'accord ?
Je ne pense pas qu'il soit efficace de prédire le prix en se basant uniquement sur les deux derniers points de données.
N'êtes-vous pas d'accord ?