
СОПРОВОЖДЕНИЕ ЭКСПЕРИМЕНТА ПО АНАЛИЗУ ДАННЫХ ФОРЕКСА: доказательство значимости предсказаний

Начало по ссылкам:
https://www.mql5.com/ru/blogs/post/659572
https://www.mql5.com/ru/blogs/post/659929
https://www.mql5.com/ru/blogs/post/660386
https://www.mql5.com/ru/blogs/post/661062
https://www.mql5.com/ru/blogs/post/661499
В сегодняшней небольшой итерации блога я освещу статистическое доказательство солидности полученного предсказания. Иными словами, значимо ли отличается от нуля наша функция потери на валидационном отрезке.
Напомню, что было сделано.
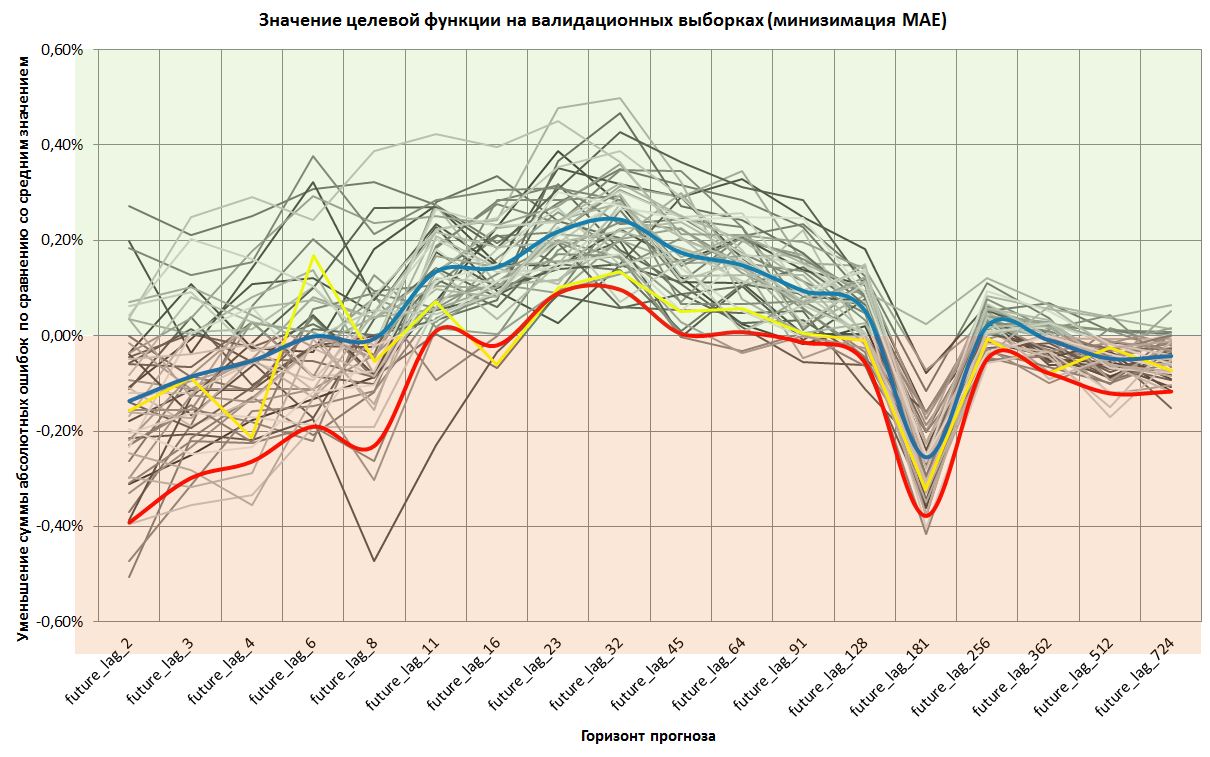
Серым цветом обозначены 49 дополнительных выборок.
Желтым цветом обозначены результаты на исходной выборке, по которой я уже рапортовал.
Синим цветом обозначено среднее значение validate_mae_ mean (1 - сумма абсолютных ошибок прогноза / сумму абсолютных ошибок от среднего значения на валидиционной выборке). То есть интересующая нас функция потерь.
Красным цветом обозначен 5%-квантиль значений целевой функции.
То есть, я провел оценку квантиля численно.
Приступим к доказательству.
Возьмем валдиацию на 50 выборках для горизонта 32 минуты. Получим значения validate_mae_mean (улучшение суммы абсолютных ошибок предсказаний по сравнению с ошибками от среднего значения).
Создадим вектор x, который наполним этими 50 значениями. Наша задача проверить гипотезу о том, что среднее значение этих величин значимо отличается от нуля.
x <- c(0.00147926979128488 ,0.00305379538922501 ,0.00180543804756583 ,0.00276319052311846 ,0.0013803018764994 ,0.00174796173488612 ,0.00198545076945178 ,0.00239007953058445 ,0.00205444716005154 ,0.00222904391925638 ,0.0026376652549549 ,0.00201407116595331 ,0.000577821692805736 ,0.00203061315792996 ,0.0034970223290558 ,0.00318366102177281 ,0.00346809796740821 ,0.00223150502279734 ,0.000608931955772274 ,0.00314516020028555 ,0.00234833489305408 ,0.00150617238226203 ,0.0014475347363998 ,0.00283711425462019 ,0.00467863380426847 ,0.0049867619740307 ,0.00292358147801608 ,0.00427635036550089 ,0.0016391130243989 ,0.00265629954700275 ,0.00167246259328191 ,0.00277080480189484 ,0.00359132902762815 ,0.00285042993770424 ,0.00202403195154166 ,0.00281237912554966 ,0.00166341111458757 ,0.00147722472894907 ,0.00278335833439169 ,0.00129940639922055 ,0.00298034525273416 ,0.0017214972321189 ,0.00219466590616701 ,0.00303852576490593 ,0.00365254533562032 ,0.003211699114959 ,0.00387225874952879 ,0.00271461976665699 ,0.000701323935946463 ,0.00135400315275536)
Для начала проверим на принадлежность выборки нормальному закону распределения, используя критерий Шапиро-Уилка:
shapiro.test(x) Shapiro-Wilk normality test data: x W = 0.97809, p-value = 0.4745
Мы получаем результат, который говорит о том, что нет оснований для отвержения нулевой гипотезы о том, что распределение нормально. То есть, данные нормальны.
Мы можем законно приименить Т-критерий для проверки гипотезы о том, что среднее значение по выборке не отличается от нуля.
> t.test(x + , alternative = "greater" + , mu = 0) One Sample t-test data: x t = 17.579, df = 49, p-value < 2.2e-16 alternative hypothesis: true mean is greater than 0 95 percent confidence interval: 0.002206747 Inf sample estimates: mean of x 0.002439395
Отлично, мы получили подверждение того, что средневыборочное значимо отличается от нуля (p-value близко к нулю) на уровне значимости 0,00000001 (очень высоком).
Перепроверимся. Используем непараметрический тест, который не предполагает нормальности выборочных значений.
Используем одновыборочный Т-критерий Вилкоксона (Wilcoxon signed rank), где нулевая гипотеза заключается в том, что среднее по выборке не отличается от mu = 0.
> wilcox.test(x + , alternative = "greater" + , mu = 0) Wilcoxon signed rank test with continuity correction data: x V = 1275, p-value = 3.895e-10 alternative hypothesis: true location is greater than 0
И также получим также очень низкое значение p-value, отвергаем нулевую гипотезу.
Отлично! Мы статистически доказали, что результаты валидации значительно отличаются от нуля (в большую сторону) на данных множества выборочных оценок функции потери.
Можно сказать, что первая задача эксперимента завершена успешно. Мы доказали, что данные форекса (в том виде, в котором я их использовал) успешно прогнозируются и прогноз устойчив относительно времени и даже нескольких разных инструментов.
Сразу внесу ясность, если вдруг будут читать люди с критическим складом ума и спексисом. Все эти доказательства имеют силу именно на исследуемом объекте, ограниченном во времени.
На самом деле, конечно, мы не можем гарантировать, что закономерности будут и в дальнейшем инвариантны по времени. Но мы убедительно показываем, что на 5 лет вперед для 5 пар найденные на обучении закономерности не выродились в шум. Это позволяет с большим оптимизмом ожидать, что обученная на прошлых данных модель сохранит предсказательную способность, отличную от случайного гадания.
Но если вдруг через год финансовые рынки будут потрясены или вообще как-либо поменяются, наши предсказания для них могут стать незначимыми - шумными.
Далее мы будем пробовать классифицировать направления движения цены.
Недели через 1,5-2 выложу новые материалы. Следите!
Пока.






")