
СОПРОВОЖДЕНИЕ ЭКСПЕРИМЕНТА ПО АНАЛИЗУ ДАННЫХ ФОРЕКСА: первое серьезное обучение модели и результаты

Начало по ссылкам:
https://www.mql5.com/ru/blogs/post/659572
https://www.mql5.com/ru/blogs/post/659929
https://www.mql5.com/ru/blogs/post/660386
https://www.mql5.com/ru/blogs/post/661062
Важно: я решил выложить в общий доступ обучающий и валидационный наборы данных для всех желающих поэкспериментировать. Если у кого-то получится воспроизвести и возможно улучшить результаты регрессии на валидации, прошу сообщить мне.
https://drive.google.com/open?id=0B_Au3ANgcG7CMmJvVGpXOEg3cGs
Сегодня я представлю результаты уже довольно обширного обучения GBM на все тех же данных, проведу анализ результатов и покажу, что будет сделано дальше.
В прошлый раз мы обучили пилотную модель, сделали это на скорую руку, горизонт предсказания был наименьший - 2 минуты. Результат валидации модели был отрицательный: то есть, метрика R^2 и улучшение суммы абсолютных ошибок относительно наивного прогноза были в отрицательной зоне.
После доработки инфраструктуры для обучения, как я обещал:
нужно будет протестировать не одну, а все 18 целевых переменных. Для каждой модели буду отбирать 10 лучших наборов параметров. Думаю, что где-то может и выстрелить.
Во-первых, позвольте напомнить, какие данные у нас на руках и как мы используем данные для кроссвалидации.
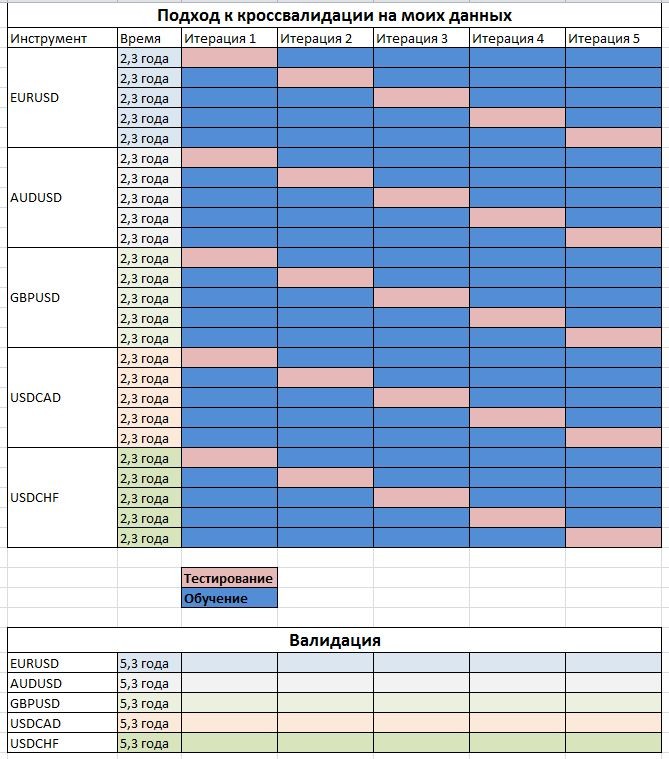
Таким образом я графически изобразил структуру данных.
У нас примерно 80 лет всего в массиве. Первые 2/3 из них идут на обучение и тестирование (первая часть истории каждой пары). Обучающий набор идет от 1999 г. и заканчивается примерно на 2010.09.22.
Последние 1/3 данных каждой пары идут на валидацию. Валидация начинается примерно с 23.09.2010 и заканчивается 01.02.2016.
Кроссвалидация.
Есть разные подходы к кроссвалидации временных рядов. Я остановился на таком, который, как я думаю в меру своего опыта, даст наибольшее количество данных для обучения и при этом изолирует данные для тестирования во времени. Как видно из таблицы, я 5 раз беру обособленный временной промежуток в каждой валютной паре для обучения, и меньший отрезок (4/5 длины ряда), который также хронологически изолирован и совпадает по времени для каждой пары - для тестирования.
Подход к отбору обученных моделей.
GBM - это ускоренные деревья решений. Их обучение задается рядом параметров. Я взял такие диапазоны:
# tuning GBM gbmGrid <- expand.grid(interaction.depth = seq(from = 1, to = 9, by = 4) , n.trees = seq(from = 100, to = 400, by = 100) , shrinkage = seq(from = 0.005, to = 0.015, by = 0.005) , n.minobsinnode = seq(from = 70, to = 150, by = 40))
Всего получается 108 наборов параметров. Для каждого набора обучается модель, кроссвалидируется на 5 отрезках и усредненное значение функции потерь - вместе с соответствующим набором параметров -сохраняется.
Затем, после сортировки массива по метрике потерь я выбираю 10 лучших наборов параметров и сохраняю их для обучения моделей, которые пройдут валидацию.
Такая процедура повторяется для 18 выходных переменных по очереди (горизонт предсказания приращения цены от 2 минут до 724 минут в будущее).
Таким образом я сохраняю на свой жесткий диск 180 результатов валидации моделей: по 10 моделей на каждый горизонт предсказания. Задача - посмотреть, на каких горизонтах предсказательная способность модели сохраняется в положительной зоне.
И да, забыл, весь цикл повторяется два раза: один раз GBM минимизирует Mean Squarred Error, второй раз - Mean Absolute Error. Можно будет посмотреть какая метрика более устойчива к проверке временем.
Выбор функции потерь обосновывается данными и целью. Данные у нас толстохвостые, то есть хвосты гораздо тяжелее, чем у нормального распределения. Использование квадратных ошибок может дать худшее качество регрессии из-за того, что наибольший вес будут иметь далекие наблюдения и квадраты их ошибок.
Результаты.
Сначала рассмотрим на результаты валидации моделей, в которых минимизировалась абсолютная ошибка.
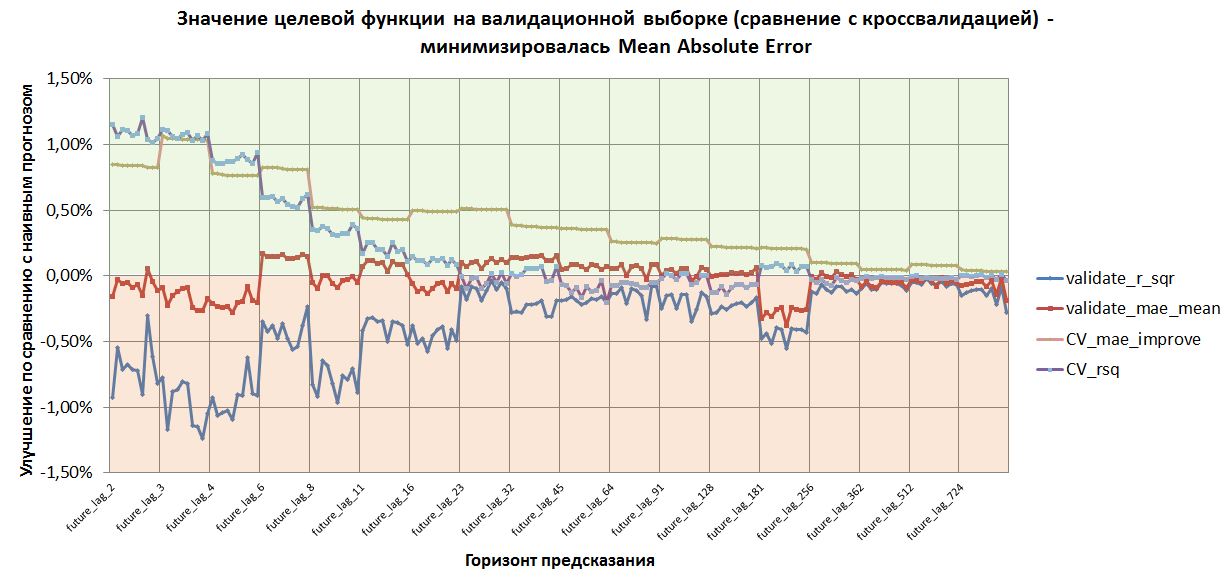
График validate_mae_mean - это метрика улучшения суммы абсолютных ошибок относительно среднего значения на валидационной выборке.
И, ура-ура, мы видим, что для некоторых горизонтов предсказания данная метрика находится в плюсе, то есть, модель предсказывает лучше, чем наивное среднее значение. При этом можно видеть, что
CV_mae_improve - это та же метрика на кроссвалидации (она показана зеленоватой линией) падает по ходу роста горизонта. То есть, при тестировании предсказание более отдаленного будущего дается хуже.
Синими линиями показаны метрики R^2 на валидации и тестировании для сравнения.
Замечу, что минимизиация абсолютной ошибки не обязана приводить к минимизации квадратной ошибки, и наоборот. Поэтому, R^2 на валидации (validate_r_sqr) так и не вышел в положительную зону. Заметим, что на кроссвалидации R^2 также снижается с ростом глубины заглядывания в будущее.
А теперь посмотрим на результаты валидации GBM-моделей, в которых минимизировалась средне-квадратичная ошибка.
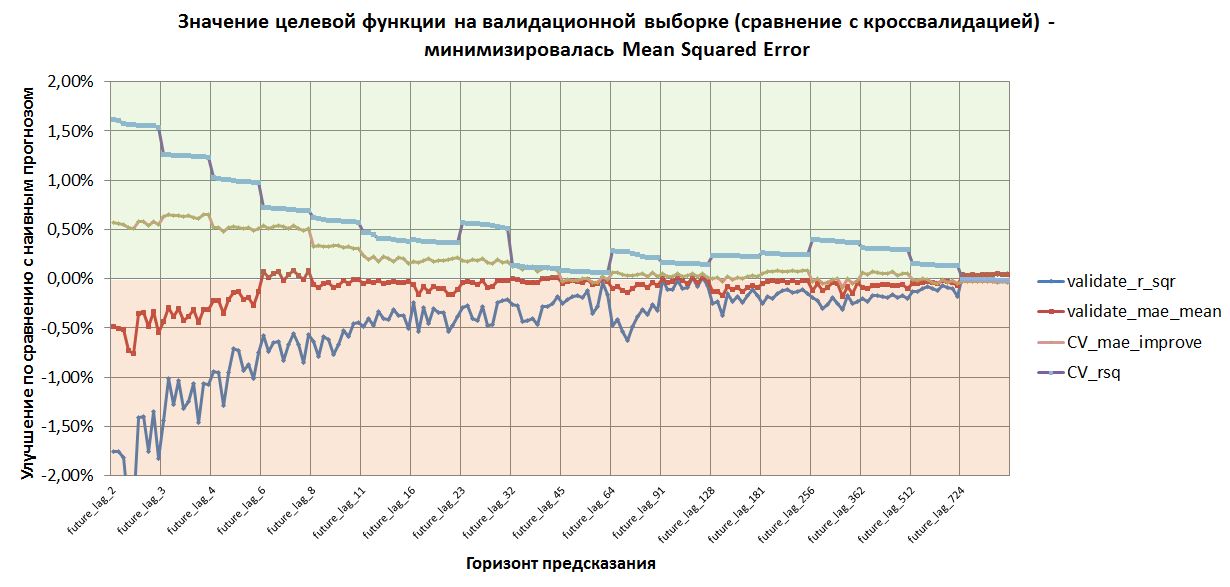
В этом случае R^2 на валидации смог выйти в положительную зону на последнем горизонте предсказаний - 724 минуты в будущее. А улучшение абсолютных ошибок не показывает заметного улучшения, кроме как на горизонте 6 минут (как и предыдущем случае) и также на максимальном горизонте.
Повторюсь, что уменьшение квадратичных ошибок не обязательно приведет к уменьшению абсолютных ошибок.
И для сравнения значения функций потерь на валидации для моделей, построенных минимизацией MAE и MSE.
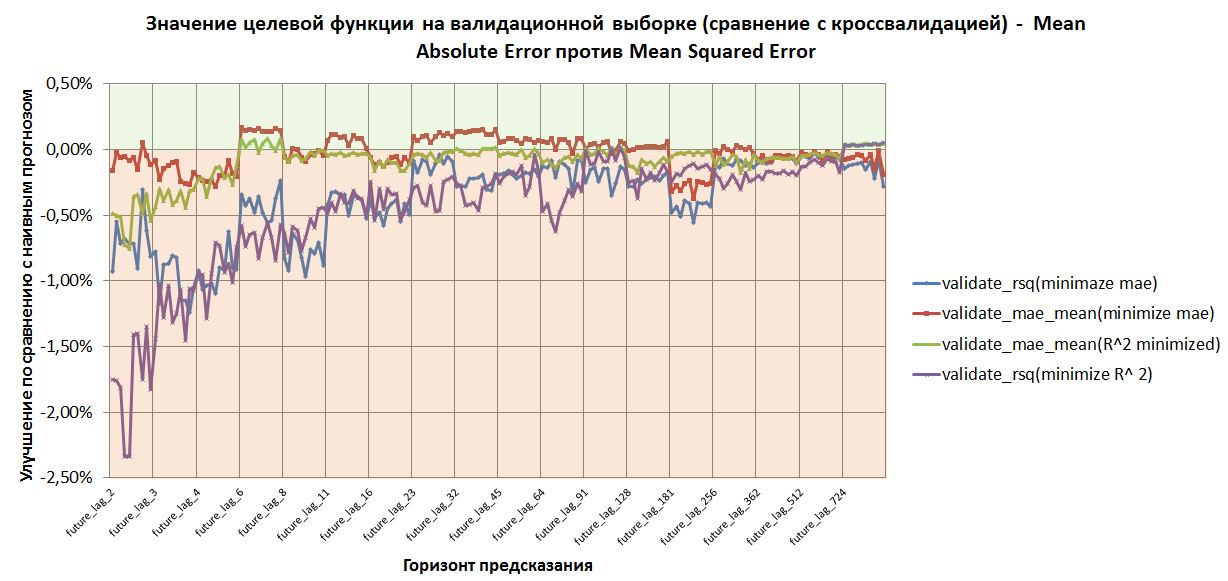
Выводы.
Я смог показать, что регрессия приращений цен методом GBM позволяет прогнозировать лучше, чем наивный прогноз. Иными словами, у меня уже есть модель, которая может прогнозировать форекс. При этом, лучшие показатели у моделей, которые строятся на основе минимизации средней абсолютной ошибки.
Много это или мало - 0.16 процента улучшения суммы абсолютных ошибок по сравнению со средним (наивным) предсказанием?
Прошу обратить внимание на результаты конкурса по предсказанию биржевых котировок на Kaggle, где в качестве функции потерь использовалась взвешенная средняя абсолютная ошибка.
https://www.kaggle.com/c/the-winton-stock-market-challenge/leaderboard
Победитель на первом месте (получивший 20 000 долларов) смог улучшить значение метрики на 0,06 процента... Думаю, это говорит о чем-то. Однако, также замечу, что на Каггле условия были более жесткие. Там было много стоков, возможно, сотни. И данные были зашумлены.
Также стоит отметить, что для генерации профита ($$$) будет важно, насколько хорошо модель способно попадать в направления приращений (по знаку). И минимизация ошибки регрессии не обязательно приведет к лучшей точности предсказания знака. Это будет проверено в следующих постах.
Дальнейшие шаги.
Но я, как незаинтересованное лицо, хочу убедиться, что результат не случаен. Аналитически это сделать, имея непараметрическую модель леса решений, очень сложно. Поэтому я попытаюсь сделать это численно. Для этого я пойду двумя путями:
1) Построю предсказательные модели с помощью других методов ML на тех же данных. Результаты, полученные при использовании другого инструмента, позволят валидировать выводы о способности машинного обучения давать прогнозы приращения цен форекса, превосходящие случайное гадание.
2) Я собираюсь построить несколько валидационных выборок, где примеры будут выбраны из массива случайно. Напомню, что примеры в моих наборах данных взяты по следующей логике:
### create final testing sample { set.seed(10) start <- round(runif(1, min = 2 ^ max_lag_power, max = 1440)) nrows <- numeric() nrows[1] <- start counter <- 2 while (start <= (nrow(dat_test) - (2 ^ max_lag_power) * 2)){ start <- start + round(2 ^ max_lag_power + runif(1, min = -50, max = 50)) nrows[counter] <- start counter <- counter + 1 } }
Выбирается случайно начальная точка данных в диапазоне с индексом от 725 до 1440 (внутри половины суток) - мой массив данных начитается с индекса 725, точки, идущие ранее нужны для расчета входов.
Далее, к этому индексу добавляется 724 (это максимальная глубина, с которой берется информация для входов и выходов) и случаное число от -50 до 50 - это нужно для равномерного распределения примеров по времени внутри суток.
Соответственно, можно сгенерировать огромное число случайных выборок. Но, эти выборки не будут независимыми, так как часть информации одной выборки всегда будет перехлестываться с информацией в наблюдениях другой выборки (артефакт взаимозависимости временных рядов).
Проведя валидацию лучших (уже известных) моделей на нескольких различных выборках, я получу представление о распределении функции потерь для каждого горизонта предсказания и сделать вывод о том, лежат ли результаты достаточно далеко от нуля - результата наивного прогноза.
Кроме того, еще не была затронута тема построения торговой системы на результатах работы предиктора. Данная тема будет развита в дальнейшем.
UPDATE
Я уже успел сгенерировать несколько дополнительных валидационных выборок для проверки гипотезы о том, что уменьшение суммы абсолютных ошибок на валидации действительно не случайно - значимо больше нуля.
Я сделал 49 дополнительных выборок. Каждая из них независимо от других равномерно покрывает временные точки внутри суток. Возможны межвыборочные перехлесты по заглядыванию в будущее, но они не должны быть велики и случайны.
Для каждого горизонта прогнозирования я выбрал лучшие параметры модели (не 10 моделей, как раньше, а одну), обучил модель на имеющемся обучающем множестве, а валидацию провел 49 раз на новых выборках.
Результат получился интересным.
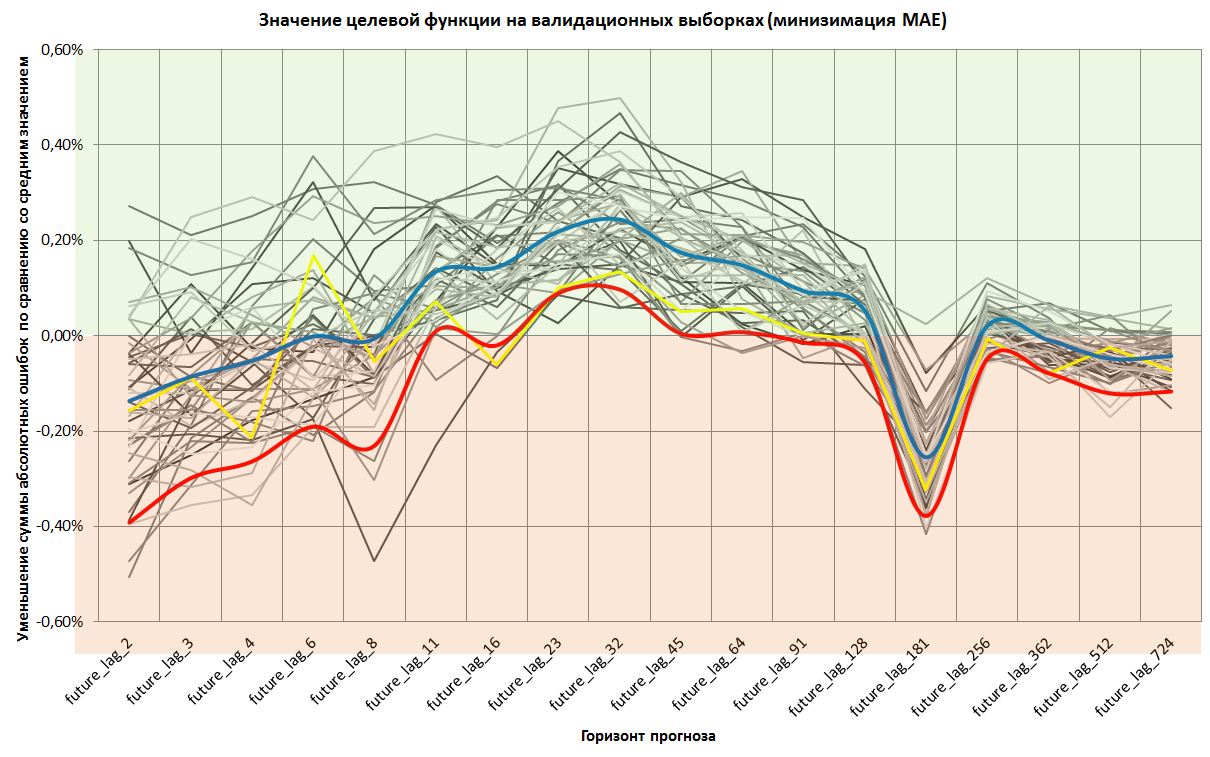
Серым цветом обозначены 49 дополнительных выборок.
Желтым цветом обозначены результаты на исходной выборке, по которой я уже рапортовал.
Синим цветом обозначено среднее значение validate_mae_ mean (1 - сумма абсолютных ошибок прогноза / сумму абсолютных ошибок от среднего значения на валидиционной выборке). То есть интересующая нас функция потерь.
Красным цветом обозначен 5%-квантиль значений целевой функции.
То есть, я провел оценку квантиля численно.
Мы видим теперь уже очень хорошо, что на горизонтах 23 и 32 минуты, а также похуже на 45 и 64 минуты, прогнозы уверенно лежат в положительном диапазоне.
Теперь можно уже с большой степенью уверенности сказать, что мы можем прогнозировать форекс надежно и наши оценки не случайны для определенных горизонтов прогноза.
Почему происходит резкий спад на 3-часовом горизонте прогнозирования пока сложно сказать. Это останется загадкой на размышление.
Файл с анализом этих данных также во вложении.
В следующий раз я также посмотрю как ведут себя модели, в которых минимизировалась сумма квадратичных ошибок, и, возможно, обучу еще одну машину (xGBoost).
Для любителей - подгрузил на Диск список (объект R), содержащий дополнительные 49 выборок. https://drive.google.com/open?id=0B_Au3ANgcG7COFlSOEpCTlBOUm8
))
Вложения.
Код с архитектурой для обучения.
Таблицы с результатами валидации моделей, с указанием параметров лучших моделей.
Таблица со сравнительным анализом.
Всем пока! Следите за обновлениями.



")
")
 на 22-06-2026")