
Le livre de recettes statistique du trader : Hypothèses

Introduction
Tout trader désireux de créer son propre système de trading deviendra tôt ou tard un analyste. Ils essaient en permanence de trouver les tendances du marché et de tester des idées de trading. Le test d'une idée peut être basé sur différentes approches - d'une recherche habituelle des meilleures valeurs de paramètre dans le mode d'optimisation du Testeur de stratégie à une étude de marché scientifique (parfois pseudo-scientifique).
Dans cet article, je suggère de considérer l'hypothèse statistique - un instrument d'analyse statistique pour la recherche et la vérification des inférences. Testons diverses hypothèses avec le package Statistica et la bibliothèque d'analyse numérique portée ALGLIB MQL5 à l'aide d'exemples.
1. Le concept d'hypothèse
Il existe plusieurs définitions du concept d'« hypothèse statistique ». Certains d'entre eux impliquent une supposition sur les propriétés statistiques de l'objet ou du phénomène considéré.
Une hypothèse statistique est une hypothèse sur les lois probabilistes auxquelles un phénomène en question adhère.
D'autres définitions indiquent que les propriétés statistiques doivent être liées à la distribution d'une variable aléatoire ou de paramètres de cette distribution.
L'hypothèse statistique est une supposition concernant les paramètres de la distribution statistique ou le principe de la distribution des variables aléatoires.
Dans la littérature sur les statistiques mathématiques, la notion d'« hypothèse » est interprétée autrement. On peut alors distinguer :
- Hypothèse paramétrique ( (hypothèse sur les valeurs des paramètres de distribution ou sur la valeur comparative des paramètres de deux distributions) ;
- Hypothèse non paramétrique (hypothèse sur le type d'une distribution de valeurs aléatoires).
Dans la section suivante, nous discuterons d'une méthode de vérification d'hypothèse.
2. Tester des hypothèses. Théorie
L'hypothèse à tester est dite hypothèse nulle (Н0). Une hypothèse concurrente (Н1) est son alternative. C'est le revers de la médaille de 0, c'est-à-dire qu'il refuse logiquement l'hypothèse nulle.
Imaginez qu'il existe une population de données sur les Stop Loss d'un système de trading. Nous allons énoncer deux hypothèses servant de base aux tests.
Н0 – la valeur Stop Loss moyenne est égale à 30 points ;
Н1 – la valeur moyenne du Stop Loss n'est pas égale à 30 points.
Variantes d'acceptation et de rejet des hypothèses :
- Н0 est vrai et il est accepté ;
- Н0 est faux et il est rejeté en faveur de Н1 ;
- Н0 est vrai mais il est rejeté en faveur de Н1 ;
- Н0 est faux mais il est accepté.
Les deux dernières variantes sont liées à des erreurs.
Maintenant, la valeur du seuil de signification doit être spécifiée. C'est la probabilité que l'hypothèse alternative soit acceptée alors que la vraie hypothèse est nulle (troisième variante). Cette probabilité est préférable car elle est minimisée.
Dans notre cas, une telle erreur se produira si nous supposons que le Stop Loss à la moyenne n'est pas égal à 30 points même s'il l'est réellement.
Habituellement, le niveau de signification (α) est égal à 0,05. Cela signifie que la valeur statistique de test de l'hypothèse nulle peut combler la partie critique dans pas plus de 5 cas sur 100.
Dans notre cas, la valeur de la statistique de test sera évaluée sur un graphique classique (Fig.1).

Fig.1. Tester la distribution des valeurs statistiques par la loi de probabilité normale
Pour que l'hypothèse nulle soit acceptée, les valeurs des statistiques de test ne sont pas censées atteindre les zones rouges. Pour des besoins d'exemple, supposons que les valeurs des statistiques de test sont distribuées normalement.
Chaque test a sa propre formule pour calculer la valeur statistique du test.
La variante 4 implique qu'il existe une erreur du deuxième type (β). Dans notre cas, une telle erreur se produira si nous supposons que le Stop Loss à la moyenne est égal à 30 points et qu'il n'est pas égal à ce nombre de points.
3. Exemples de tests d'hypothèses statistiques
Les données source utilisées pour les exemples sont stockées dans le fichier Data.xls.
3.1. Test d'échantillon dépendant
Imaginez la situation suivante. Supposons qu'il existe un système de trading générant beaucoup de transactions. Prenons un échantillon de transactions rentables avec un volume de 100 unités. Les données sources se trouvent dans la feuille « Profits ».
Les statistiques descriptives de l'échantillon Profits après suppression des cas aberrants sont présentées dans le Tableau 1 :

Table 1. Statistiques de l'échantillon Profits
L'histogramme de l'échantillon se présente comme suit (Fig.2).

Fig.2. L'histogramme de l'échantillon Profits
La valeur de la moyenne est de 83,4 points et la médiane est de 83 points.
Que se passera-t-il si le point d'entrée sur le marché est modifié de quelques points ? Par exemple, un ordre limite améliorant le prix d'entrée peut être placé après l'apparition d'un signal de trade.
Comment cela affectera-t-il les résultats? Cette question peut être répondue par des hypothèses statistiques.
Dans le package Statistica, nous vérifions formellement si les échantillons n'ont pas été prélevés sur une population :
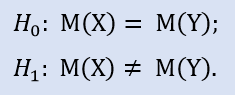
Si nous modifions le prix d'entrée de 15 points, nous recevrons l'échantillon NewProfits. Idéalement, l'image résultante devrait être la suivante (Fig.3).

Fig.3. Exemples de Graphique pour les échantillons Profits et NewProfits
La probabilité que l'hypothèse alternative soit acceptée est élevée car les médianes des échantillons diffèrent.
Cette image, cependant, sera difficile à obtenir car il pourrait ne pas y avoir de meilleurs prix sur le marché. Dans mon cas, le deuxième échantillon comprenait 84 transactions après la modification du prix d'entrée. Les 15 autres transactions n'ont tout simplement pas été exécutées. Cet échantillon corrigé sera nommé NewProfitsReal.
Sur le tracé de type «boîte et moustache», il n'y a pas beaucoup de différence entre deux échantillons.

Fig.4. Terrain pour les échantillons Profits et NewProfitsReal
Effectuons un test non paramétrique de rang signé de Wilcoxon pour l'échantillon connecté.
Les résultats sont dans le tableau 2 :

Table 2. Résultats des tests de Wilcoxon pour les échantillons Profits et NewProfitsReal
Le niveau de significativité est très élevé, ce qui favorise l'hypothèse nulle.
De cette façon, nous pouvons dire que le changement du point d'entrée n'a pas influencé le rendement du système. C'est en termes relatifs. Dans l'absolu, le système s'est avéré moins rentable en raison des points d'entrée manqués.
Le test de Wilcoxon peut être effectué par programmation dans MQL5. Bien qu'il compare la médiane de distribution avec la valeur spécifiée de m, cette différence n'est pas significative.
Nous allons vérifier :
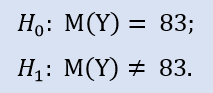
La bibliothèque ALGLIBcontient la procédure suivante : CAlglib::WilcoxonSignedRankTest(). Il donne un résultat pour trois types de tests : bilatéral, gauche et droit.
Le scripttest_profits.mq5 fournit un exemple de ce calcul. Le journal «Experts» a les résultats suivants pour l'échantillon NewProfitsReal :
OO 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the two-sided test: 0.7472 HD 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the left-sided test: 0.6285 CM 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the right-sided test: 0.3736
Le test du côté gauche a la forme de :
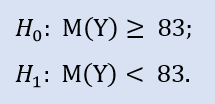
Ici, nous vérifions l'alternative car la médiane de l'échantillon NewProfitsReal peut être supérieure ou égale à 83. La probabilité d'erreur au rejet de H0 est de 0,63. Donc H0 est accepté.
Le test du côté droit ressemble à :
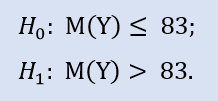
Dans ce test, nous vérifions l'alternative selon laquelle la médiane de l'échantillon NewProfitsReal peut être inférieure ou égale à 83. La probabilité d'erreur au rejet de H0 est égale à 0,37. Donc H0 est accepté.
3.2. Tester des échantillons indépendants
Supposons que nous devions vérifier à quelle vitesse les différents brokers traitent les ordres de trading et s'il existe une différence entre les brokers en ce qui concerne le temps d'exécution des ordres de trading.
Il y a donc deux échantillons de données sources à analyser. Chaque échantillon contenait initialement 50 observations. Après suppression des cas aberrants, 48 observations ont été laissées dans le premier échantillon (broker А) et 49 observations dans le second (broker B). Les données peuvent être trouvées dans la feuille «"ExecutionTime».
Nous allons vérifier :
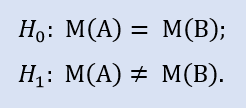
Représentons des exemples d'indices sur une image (Fig.5). Selon le graphique, les valeurs des médianes diffèrent mais pas de manière significative.

Fig.5. Tracé pour les échantillons de données des brokers A et B
Comme nous ne savons pas à quelle distribution appartient chaque échantillon, nous nous référerons à des tests non paramétriques pour la comparaison.
Par exemple, réalisons Mann — Whitney U-test (tableau 3). Il est considéré comme le plus informatif.

Table 3. Mann — Résultats du test U de Whitney pour les échantillons de données des brokers A et B
Conclusion : les résultats des tests diffèrent et donc les hypothèses nulles sur l'égalité des échantillons sont rejetées en faveur de Н1.
Mann — Whitney U-test peut être effectué par programmation dans MQL5. Dans la bibliothèque ALGLIBil y a le CAlgalib :: Procédure MannWhitneyUTest(). Il donne un résultat pour trois types de tests : bilatéral, gauche et droit.
Le script test_time_execution.mq5 fournit un exemple de calcul. Le journal «Expert» a le résultat suivant qui peut être utilisé pour comparer des échantillons :
MR 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the two sided test: 0.0001 QF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the left-sided test: 1.0000 PF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the right-sided test: 0.0001
Le test du côté gauche a la forme de :
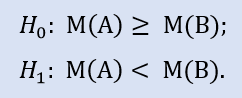
L'hypothèse nulle est que la médiane de l'échantillon de données du broker A peut être supérieure ou égale à la médiane de l'échantillon de données du broker B. L'alternative est son rejet. La probabilité d'erreur lors du rejet de H0 est de 1,0. Donc H0 est accepté.
Le test du côté droit ressemble à :
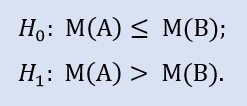
L'hypothèse nulle est que la médiane de l'échantillon de données du broker A peut être inférieure ou égale à la médiane de l'échantillon de données du broker B. L'alternative est son rejet.
La probabilité d'erreur au rejet de H0 est de 0,0. Par conséquent, H0 est rejeté en faveur de Н1.
3.3. Test de corrélation
Imaginez un portefeuille de stratégies. L'objectif est de réduire le nombre de stratégies dans le portefeuille.
Le critère de choix sera le suivant : si deux stratégies sont identiques pour comparer des séries Stop Loss, alors une des stratégies sera supprimée du portefeuille. Prenons deux échantillons avec les données Stop Loss de deux systèmes différents. Hypothèse : les systèmes réagissent à l'entrée sur le marché de la même manière et réagissent différemment à la sortie du marché.
Nous allons utiliser le test de corrélation rang-ordre de Spearman. Il y a trois échantillons dans la feuille «Correlation» du fichier de données.
Vérifiez si le coefficient de corrélation est égal à zéro :
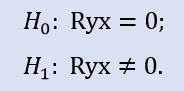
La comparaison de la paire d'échantillons Stops1-Stops2 donnera le résultat suivant (tableau 4).

Table 4. Test de corrélation rang-ordre de Spearman pour les échantillons Stops1 et Stops2
Dans ce cas, l'hypothèse nulle d'absence de connexion entre des éléments d'échantillons ne peut être rejetée en faveur de l'alternative. Elle est donc acceptée.
Le tracé de la Fig.6 montre que les données ne forment aucune configuration notable. Les données sont dispersées sur le plan du tracé.

Fig.6. Nuage de points pour les échantillons Stops1 et Stops2
Les résultats d'une vérification de la relation entre les échantillons Stops1-Stops3 sont présentés dans le tableau 5 :

Table 5. Résultats du test de corrélation rang-ordre de Spearman pour les échantillons Stops1 et Stops3
Dans ce cas, l'hypothèse nulle peut être rejetée car la probabilité d'erreur est très faible.
Par conséquent, l'alternative concernant une relation existante est acceptée. La relation ressemble à (Fig.7).

Fig.7. Nuage de points pour les échantillons Stops1 et Stops3
Confirmez le résultat avec le code en MQL5. Le test_correlation.mq5 contient un exemple de calcul.
La bibliothèque ALGLIB contient la procédure CAlglib::SpearmanRankCorrelationSignificance(), qui implémente le test de signification du coefficient de corrélation rang-ordre de Spearman.
Le journal contient les enregistrements suivants :
OO 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops2===--- GO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.9840 KK 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.4920 JJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.5080 DM 0 12:57:43.545 test_correlation (EURUSD.e,H1) HJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops3===--- NS 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.0002 RO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.9999 FG 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.0001
Le test du côté gauche a la forme de :
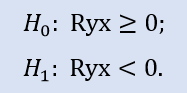
Dans ce test, l'hypothèse nulle selon laquelle il existe une corrélation non négative entre les variables (c'est-à-dire que la corrélation est soit nulle, soit négative) est vérifiée.
Le test de gauche montre que pour la paire d'échantillons Stops1-Stops2, l'hypothèse zéro est acceptée. Le test de gauche montre que pour la paire d'échantillons Stops1-Stops3, l'hypothèse nulle est également acceptée. Une question logique à poser sera « Pourquoi n'y a-t-il aucun lien entre les échantillons Stops1-Stops2 et il y en a un entre Stops1-Stops3? » La raison en est que la déclaration en échec est «supérieure ou égale à zéro». Dans le premier cas, «égal à zéro» est important pour H0, et dans le second cas il est «supérieur à zéro».
Le test du côté droit ressemble à :
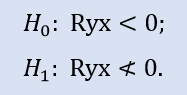
Ici, l'hypothèse nulle de ce qui est une corrélation négative est vérifiée.
Pour la paire d'échantillons Stops1-Stops2, le test de droite montre que l'hypothèse nulle est acceptée. Pour la paire d'échantillons Stops1-Stops3, le test de droite montre que l'hypothèse nulle est rejetée.
Un dernier commentaire. Le test a révélé qu'il existe une connexion probabiliste positive entre les échantillons de Stops1-Stops3. La force de cette connexion est moyenne. C'est donc au trader de décider s'il rejette la stratégie 1 ou 3.
Conclusion
Dans cet article, j'ai essayé de montrer sur des exemples que les variables quantitatives peuvent être évaluées à l'aide de statistiques mathématiques. J'espère que les développeurs novices trouveront cet article utile pour leurs futurs systèmes de trading. J'espère aussi que la série d'articles sur l'utilisation des méthodes de statistique mathématique sera poursuivie.
Les fichiers de la bibliothèque ALGLIBdoivent être téléchargés séparément.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/1240
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Programmation des modes d'EA à l'aide d'une approche orientée objet
Programmation des modes d'EA à l'aide d'une approche orientée objet
 Les bases de la programmation MQL5 : Variables globales du terminal
Les bases de la programmation MQL5 : Variables globales du terminal
 Principes de la tarification des changes à travers l'exemple du marché des dérivés de la Bourse de Moscou
Principes de la tarification des changes à travers l'exemple du marché des dérivés de la Bourse de Moscou
 Graphique Liquide
Graphique Liquide
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Il s'agit d'un paradoxe intéressant. Où puis-je en apprendre davantage à ce sujet ?
Paradoxe intéressant. Où puis-je trouver plus d'informations à ce sujet ?
Précisez ce que vous entendez par environnement ergodique .Votre article me donne une double impression.
D'une part. Dans ce forum, le fait même de poser des questions sur l'évaluation hypothétique des résultats est très important. Le forum est plein de gens qui dessinent une mashka et supposent que c'est le cas plutôt qu'une mashka dans l'intervalle.
Moins.
Je suis tout à fait d'accord avec Reshetov. Tout ce que vous avez dit - cela se réfère à des séries stationnaires ou proches de celles-ci - c'est-à-dire des séries avec peu de changement de mo et de variance dans le temps. Mais de telles séries n'existent pas sur les marchés financiers et toute l'application des statistiques sur les marchés financiers tourne autour de la stationnarité des séries temporelles. Les exemples les plus connus sont ARIMA, ARCH et tous les autres.
Votre série aléatoire, dont l'histogramme est illustré à la figure 2, montre que la série a une faible relation avec la série stationnaire, qu'elle est asymétrique et que ses queues sont très différentes. Cela se voit particulièrement bien par rapport à la courbe parfaitement normale que vous avez tracée. Ainsi, votre raisonnement ne s'applique pas du tout à votre exemple. Celui-ci n'est qu'une illustration de la pensée de Reshetov.
PS. Le concept le plus dangereux et le plus méprisable en statistique est la corrélation. Il est préférable de ne pas en parler du tout.
...Tout ce que vous avez dit - cela se réfère à des séries stationnaires ou proches de celles-ci - c'est-à-dire des séries avec peu de changement de mo et de variance dans le temps. Or, de telles séries n'existent pas sur les marchés financiers, et toute l'application des statistiques aux marchés financiers tourne autour de la stationnarité des séries temporelles. Les exemples les plus connus sont ARIMA, ARCH et tous les autres.
Votre série aléatoire, dont l'histogramme est présenté à la figure 2, montre que la série a une faible relation avec la série stationnaire, qu'elle est asymétrique et que ses queues sont très différentes. Cela se voit particulièrement bien par rapport à la courbe parfaitement normale que vous avez tracée. Ainsi, votre raisonnement ne s'applique pas du tout à votre exemple. Celui-ci est une illustration de la pensée de Reshetov.
Merci pour votre avis !
Je vais donner mes contre-arguments.
La stationnarité est une caractéristique d'une série temporelle. La figure 2 est une série de variations. L'article ne parle pas de séries temporelles! Bien que je sois d'accord pour dire que le temps est une caractéristique utile.....
D'après ce que j'ai compris, l'ergodicité signifie une certaine stabilité du système étudié....
J'aimerais donc souligner un point important. Si le système, disons une série chronologique financière, n'est pas stationnaire, nous pouvons toujours utiliser l'économétrie pour trouver un modèle stable (par exemple GARCH) décrivant le comportement du modèle. C'est là que je vois la constance du système - un comportement conforme au modèle.... mais à condition qu'il y ait une certaine probabilité que le système "casse" le modèle...
Merci de votre avis !
Voici mes contre-arguments.
La stationnarité est une caractéristique d'une série temporelle. La figure 2 est une série de variations. L'article ne parle pas de séries temporelles! Bien que je convienne que le temps est une caractéristique utile.....
D'après ce que j'ai compris, l'ergodicité signifie une certaine stabilité du système étudié....
J'aimerais donc souligner un point important. Si le système, disons une série chronologique financière, n'est pas stationnaire, nous pouvons toujours utiliser l'économétrie pour trouver un modèle stable (par exemple GARCH) décrivant le comportement du modèle. C'est là que je vois la constance du système - un comportement conforme au modèle.... mais à condition qu'il y ait une certaine probabilité que le système "casse" le modèle.....
Il y a quelques années, j'ai publié un article sur ce site dans lequel je justifiais une idée totalement inacceptable pour la plupart des gens. À savoir .
Il y a beaucoup d'indicateurs. Tout le monde pense que si un indicateur est dessiné, c'est qu'il est le même - après tout, c'est ce que nous voyons. En même temps, il ne vient pas à l'esprit de la plupart des gens que ce que nous voyons en réalité peut ne pas exister ! La raison en est banale. Si nous prenons la régression correspondant à l'indicateur, il peut facilement s'avérer que certains de ses coefficients ont des intervalles de confiance si larges qu'il est impossible de parler de la valeur d'un tel coefficient, et si nous éliminons un tel coefficient défectueux, le modèle de l'indicateur sera complètement différent. Lorsqu'on dit : il y a la vérité, il y a le mensonge et il y a les statistiques, on veut dire cette triste et très inhabituelle circonstance - rien n'est fiable, y compris les intervalles de confiance.
C'est pourquoi j'ai abandonné les modèles paramétriques et me suis impliqué dans les modèles basés sur l'apprentissage automatique. Il n'y a pas de problème de stationnarité, mais les problèmes de surentraînement sont en pleine gloire.
Et j'ai apprécié l'article.
Oui, les remarques de San Sanych et Reshetov sont légitimes - si le système (ou les systèmes) comparé(s) change(nt) ses paramètres, les résultats du test seront inutiles.
Mais la démonstration même de l'application des méthodes est plaisante. C'est rare pour le Forex !
Je dirais autre chose, en tant que personne qui applique des méthodes similaires exactement pour les prix de cotation. Il est possible de vérifier à l'avance si l'environnement est homogène (sur deux grands échantillons indépendants) et de se fier ensuite aux résultats des tests d'hypothèse avec une certaine sérénité. Cela peut également se faire grâce aux mêmes tests.