
트레이더의 통계 도우미: 가설들

들어가며
자신만의 매매 시스템을 만들고자 하는 트레이더라면 늦건 빠르건 언젠가는 애널리스트가 되기 마련입니다. 애널리스트가 되면 시장의 흐름을 분석하고 매매 아이디어를 테스트해보게 됩니다. 아이디어 테스트는 전략 테스터의 최적화 모드에서 최상의 패러미터 값에 대한 일반적인 검색으로부터, 과학적(때때로 의사 과학적인) 시장 조사에 이르기까지 다양한 접근 방식을 기반으로 시험해볼 수 있습니다.
이 문서에서는 연구 및 추론 검증을 위한 통계 분석 도구인 통계적 가설을 고려해보시길 추천드립니다. 이제부터 Statistica 패키지와 포팅된 수리분석 라이브러리 ALGLIB MQL5 를 이용하여 예제들을 분석하는 방법으로 다양한 가설을 검증해보겠습니다.
1. 가설의 개념
"통계적 가설" 개념의 정의에는 여러가지가 있습니다. 그들 중 일부는 고려 중인 대상이나 현상의 통계적 속성에 대한 가정을 포함합니다.
통계적 가설이란 알아보고자 하는 어떤 현상이 따르는 확률 법칙에 대하여 세우는 가정입니다.
다른 정의들에 의하면 이러한 통계적 속성은 일부 랜덤 변수나 패러미터의 분포와도 반드시 연관되어야합니다.
통계적 가설은 통계적 분포의 패러미터나 확률변수 분포의 원리에 관한 가정입니다.
수리통계 도서들에서 "가설"의 개념은 후자에 무게를 두고 있습니다. 따라서 아래와 같이 구분할 수 있습니다.
- 모수 통계(Parametric hypothesis) (분포 모수들의 값이나, 두 분포들의 모수들 간의 비교값에 대한 가설).
- 비모수 통계(Nonparametric hypothesis) (랜덤값 분포에 대한 가설).
다음 섹션에서 가설 검증 방법에 대하여 논해보겠습니다.
2. 가설 검증하기. 이론
검증 대상인 가설을 귀무 가설이라고 합니다 (Н0). 대립 가설 (Н1)은 그 대안이 되는 가설입니다. 이는 H0와 반대 편에 있는 가설과도 같습니다, 즉, 논리적으로 귀무 가설을 부정하는 가설입니다.
어떤 트레이딩 시스템에서 손절에 관한 데이터가 있다고 가정해보세요. 테스트용으로 두개의 가설을 만들어보겠습니다.
Н0 – 평균 손절값은 30 포인트이다.
Н1 – 평균 손절값은 30 포인트가 아니다.
각 가설을 받아들이고 기각하는 케이스는 다음과 같습니다.
- Н0은 참이고, 받아들여짐.
- Н0은 거짓이며, 기각되고 H1이 받아들여짐.
- Н0은 참이나 H1이 받아들여짐.
- Н0은 거짓이나 받아들여짐.
마지막 두 케이스는 오류로 이어집니다.
이제 유의 수준의 값이 설정됩니다. 유의 수준이란 귀무 가설이 참이지만 대립 가설이 받아들여질 가능성(세번째 케이스)의 확률입니다. 이 확률은 최소화시켜야합니다.
우리가 앞서 세운 예시를 가지고 들자면, 평균 손절값이 실제로는 30 포인트임에도 아니라고 가정하게 될 때에 해당합니다.
일반적으로 유의 구간 (α)은 0.05입니다. 이는 귀무가설의 시험 통계값 100 건 중 5 건 정도가 해당된다는 의미입니다.
시험 통계값은 차트 상에서 평가됩니다 (1번 그림).In our case the test statistic value will be evaluated on a classical chart (Fig.1).

1번 그림. 표준 확률 법칙에 의한 시험 통계값 분포
귀무 가설이 받아들여지려면 시험 통계값들이 적색 영역에 들어가지 않아야합니다. 다시 우리가 사용했던 예시로 돌아가서, 시험 통계값들이 표준 분포를 따른다고 가정하겠습니다.
각 테스트마다 시험 통계값을 산출하기 위한 공식이 있습니다.
4번 케이스는 2번 오류(β)가 발생했다는 의미입니다. 우리 예시의 경우엔 평균 손절값이 30포인트라고 판단했으나 실제론 아닌 경우에 해당됩니다.
3. 통계적 가설 검정 예시
예시 용으로 사용된 원본 데이터는 Data.xls 파일에서 확인하실 수 있습니다.
3.1. 의존 샘플 시험
다음의 상황을 가정하십시오. 다양한 거래를 생성하는 트레이딩 시스템이 있다고 칩시다. 100 유닛만큼 되는 수익 거래 예시가 있습니다. 원본 데이터는 "Profits" 시트에서 찾아볼 수 있습니다.
Profits 샘플에서 아웃라이어들을 제거한 후의 해설적 통계를 1번 테이블에서 확인하실 수 있습니다.

1번 테이블. Profits 샘플 통계
이 샘플의 히스토그램은 다음과 같습니다 (2번 그림).

2번 그림. Profits 히스토그램 샘플
평균값은 83.4 포인트이며 중간값은 83 포인트입니다.
만약 마켓 진입 포인트를 몇 포인트만큼 수정하면 어떻게 될까요? 예를 들어, 진입 가격을 개선하는 지정가 주문은 거래 신호가 나타난 후에 배치할 수 있습니다.
결과엔 어떠한 영향을 줄까요? 이 질문에는 통계 가설로 대답할 수 있습니다.
Statistica 패키지를 이용할 때 한 그룹에서 샘플들을 꺼냈는지 확인합니다.
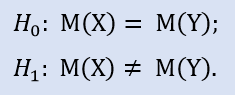
만약 진입 가격을 15 포인트만큼 수정하면 NewProfits 샘플을 받게 될 것입니다. 이상적으로 흘러가면 결과는 다음과 같이 시각화가능합니다 (3번 그림).

3번 그림. Profits와 NewProfits 샘플 차트
대립 가설이 받아들여질 가능성은 샘플간의 중간값이 다를 수록 높아집니다.
이 그림에서는 더 나은 가격들이 없기때문에 그렇게 되기 어려운 면이 있습니다. 제 경우에 2번째 샘플은 가격이 변동한 후 84개의 매매를 성립시켰습니다. 나머지 15개의 매매는 그냥 이루어지질 않았습니다. 이 수정 샘플은 NewProfitsReal라고 명명됩니다.
"box-and-whisker"유형의 플롯에서 두 샘플 사이에는 큰 차이가 없습니다.

4번 그림. Profits와 NewProfitsReal 샘플 그림
연결된 샘플들을 대상으로 비모수 윌콕슨 부호순위 검정(Wilcoxon signed-rank test)을 수행해봅시다.
결과는 2번 테이블에 정리되어 있습니다.

2번 테이블 Profits와 NewProfitsReal 샘플에 대한 윌콕슨 검정 결과
유의 수준이 상당히 높으므로 귀무 가설 쪽이 유리합니다.
이로서 진입 가격을 변화시켜도 시스템의 결과엔 영향이 없다고 말할 수 있습니다. 상대적으로 말이지요. 엄밀하게 말하자면 몇몇 진입 포인트를 포기했기 때문에 시스템의 수익성은 오히려 감소했습니다.
윌콕슨 검정은 MQL5에서 프로그램으로 수행될 수 있습니다. 분포 중앙값을 지정된 m 값과 비교하지만 이 차이는 중요하지 않습니다.
체크해볼 것입니다.
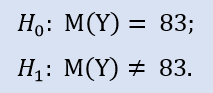
ALGLIB 라이브러리에는 CAlglib::WilcoxonSignedRankTest()라는 과정이 있습니다. 이 과정에서 3개의 검정 타입: 양면, 좌측, 우측 각각에 대한 결과를 내놓습니다.
test_profits.mq5 스크립트에서 이런 계산 예제를 보실 수 있습니다. "Experts" 저널에서 NewProfitsReal 샘플에 대한 결과를 확인할 수 있습니다.
OO 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the two-sided test: 0.7472 HD 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the left-sided test: 0.6285 CM 0 12:04:08.814 test_profits (EURUSD.e,H1) p-value for the right-sided test: 0.3736-->
좌측 검정은 다음 형태를 갖추고 있습니다.
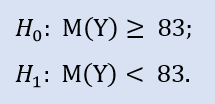
여기에서 NewProfitsReal 샘플의 중간값이 83과 같거나 그보다 클 수 있기 때문에 대안을 확인해볼 수 있습니다. H0를 기각하는 에러 확률은 0.63입니다. 그러므로 H0은 받아들여집니다.
우측 검정은 다음 형태를 갖추고 있습니다.:
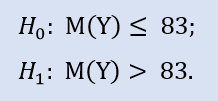
여기에서 NewProfitsReal 샘플의 중간값이 83과 같거나 그보다 작을 수 있기 때문에 대안을 확인해볼 수 있습니다. H0를 기각하는 에러 확률은 0.37입니다. 그러므로 H0은 받아들여집니다.
3.2. 독립 샘플 검정
브로커마다 매매주문을 얼마나 빨리 처리하는지, 그리고 매매주문의 실행시간과 관련하여 브로커마다 차이가 있는지 확인해야 한다고 가정해봅시다.
그러니까 분석용 소스 데이터가 2 샘플 있다는 것이죠. 각 샘플은 시작 시점에는 50개의 관측값을 지녔습니다. 아웃라이어를 제거한 후 첫 샘플 (브로커 A)에는 48개의 관측값이, 두번째 샘플 (브로커 B)에는 49개의 관측값이 남습니다. 이 데이터는 "ExecutionTime" 시트에서 찾아볼 수 있습니다.
체크해볼 것입니다.
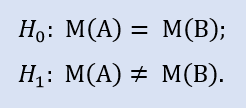
샘플 인덱스를 그림에 표현해봅시다 (5번 그림). 그림에서 보이듯 중간값들의 값이 딱히 크게 차이나진 않습니다.

5번 그림. 브로커 A와 B의 데이터 샘플 그림
각 샘플이 어떤 분포에 속하는지 모르기 때문에 비교를 위해 비모수 검정을 참조합니다.
예를 들어 맨- 휘트니 U 검정(Mann — Whitney U-test)을 할 수 있게 해줍니다 (3번 그림). 이 검정은 가장 쓸모있다고 여겨집니다.

3번 테이블. 브로커 A, B 데이터 샘플의 맨-휘트니 U 검정 결과
결론: 테스트 결과가 다르므로 표본 동등성에 대한 귀무 가설은 기각되고 대립 가설이 받아들여집니다.
맨-휘트니 U 검정은 MQL5로 프로그램화할 수 있습니다. ALGLIB 라이브러리에는 CAlglib:: MannWhitneyUTest() 과정이 있습니다. 이 과정에서 3개의 검정 타입: 양면, 좌측, 우측 각각에 대한 결과를 내놓습니다.
test_time_execution.mq5 스크립트를 통해 계산 예제를 확인할 수 있습니다. "Expert" 저널에 샘플 비교에 사용할 수있는 결과가 담겨있습니다.
MR 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the two sided test: 0.0001 QF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the left-sided test: 1.0000 PF 0 12:55:08.577 test_time_execution (EURUSD.e,H1) p-value for the right-sided test: 0.0001-->
좌측 검정은 다음 형태를 갖추고 있습니다.
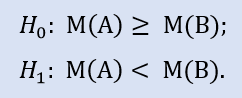
귀무 가설은 브로커 A 데이터 샘플의 중앙값이 브로커 B 데이터 샘플의 중앙값보다 크거나 같을 수 있다는 것입니다. 대립가설은 그걸 부정합니다. H0를 기각할 에러 확률은 1.0입니다. 그러므로 H0은 받아들여집니다.
우측 검정은 다음 형태를 갖추고 있습니다.:
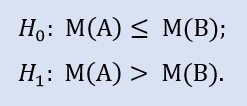
귀무 가설은 브로커 A 데이터 샘플의 중앙값이 브로커 B 데이터 샘플의 중앙값보다 작거나 같을 수 있다는 것입니다. 대립가설은 그걸 부정합니다.
H0를 기각할 에러 확률은 0.0입니다. 따라서 H0은 기각되고 H1이 받아들여집니다.
3.3. 상관 검정
전략 포트폴리오가 하나 있다 생각해보십시오. 우리의 목표는 그 포트폴리오 내의 전략 수를 줄이는 것입니다.
선택 기준은 다음과 같습니다. 손절매 시리즈를 비교할 때 두 전략이 동일한 경우 포트폴리오에서 두 전략 중 하나가 제거됩니다. 각기 다른 두개의 시스템의 손절매 데이터 샘플을 봅시다. 가정: 시스템은 시장 진입 시 동일한 방식으로 반응하고 시장 퇴출 시에는 다르게 반응합니다.
스피어만의 순위상관분석 테스트(Spearman's Rank-Order Correlation test)를 사용할 것입니다. 데이터 파일의 "Correlation" 시트에 예제 3개가 있습니다.
상관 계수가 0인지 확인하십시오.
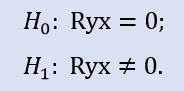
Stops1-Stops2 샘플 쌍을 비교하면 다음의 결과를 얻을 수 있습니다 (4번 그림).

4번 테이블. Stops1, Stops2 샘플에 대한 스피어만 순위상관분석 테스트
이 경우 표본 요소 간의 연결 부재에 대한 귀무 가설을 기각할 수 없습니다. 다시 말해, 받아들여집니다.
6번 그림에서 볼 수 있듯이 이 데이터는 유의미한 설정을 만들지 않습니다. 평면 상에 그냥 흩어져있을 뿐입니다.

6번 그림. Stops1, Stops2 샘플에 대한 스캐터 플롯
Stops1-Stops3 샘플 간의 관계 체크 결과는 5번 테이블에서 확인하실 수 있습니다.

5번 테이블. Stops1, Stops3 샘플에 대한 스피어만 순위상관분석 테스트 결과
이 경우, 에러 확률이 상당히 낮기 때문에 귀무 가설을 기각할 수 있습니다.
따라서 기존 관계에 대한 대립 가설을 받아들일 수 있습니다. 관계는 7번 그림처럼 나타내어집니다.

7번 그림. Stops1, Stops3 샘플에 대한 스캐터 플롯
결과와 MQL5 코드를 비교해보십시오. test_correlation.mq5에 계산 예시가 들어있습니다.
ALGLIB 라이브러리에서 스피어만 순위상관관계 계수의 유의 수준 시험을 구현시키는 CAlglib::SpearmanRankCorrelationSignificance() 과정을 찾아볼 수 있습니다.
해당 저널에는 다음이 담겨있습니다.
OO 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops2===--- GO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.9840 KK 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.4920 JJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.5080 DM 0 12:57:43.545 test_correlation (EURUSD.e,H1) HJ 0 12:57:43.545 test_correlation (EURUSD.e,H1) ---===Samples Stops1 and Stops3===--- NS 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the two-sided test: 0.0002 RO 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the left-sided test: 0.9999 FG 0 12:57:43.545 test_correlation (EURUSD.e,H1) p-value for the right-sided test: 0.0001-->
좌측 검정은 다음 형태를 갖추고 있습니다.
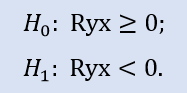
이 테스트에서는 변수 간에 음이 아닌 상관 관계가 있다는 귀무 가설(즉, 상관 관계가 0 또는 음수임)이 확인됩니다.
Stops1-Stops2 샘플을 대상으로 한 좌측 검정에서 귀무 가설이 받아들여집니다. 이 좌측 검정에서 Stops1-Stops3를 대상으로한 귀무 가설이 받아들여질 것이라는 것 또한 확인됩니다. 여기서 나올만한 합리적인 의문 중 하나를 들자면 "Stops1-Stops2에는 연결 관계가 없고 Stops1-Stops3 사이에는 연결 관계가 있는 것인가?" 인데요, 그 이유는 체크 조건문이 "0과 같거나 더 클 것" 이기 때문입니다. 전자에서는 "0과 같을 것"이 H0 조건이었고, 후자에서는 "0보다 클 것"입니다.
우측 검정은 다음 형태를 갖추고 있습니다.:
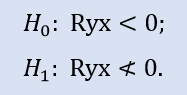
이 과정에서 음수 상관관계의 귀무 가설이 확인됩니다.
Stops1-Stops2 샘플에서 우측 검증을 통해 귀무 가설이 받아들여집니다. Stops1-Stops3 샘플에서는 우측 검증을 통해 귀무 가설이 기각되는 것을 보여줍니다.
마지막으로 한 마디 하겠습니다. 우측 검정를 통해 Stops1-Stops3 샘플간의 양수 확률적 연결이 있는 것을 확인하였습니다. 이 관계의 강도는 일반 수준 입니다. 따라서 1번 전략을 버릴지 3번 전략을 버릴지 결정하는 것은 트레이더 몫입니다.
마치며
지금까지 이 문서를 통해 수리통계학을 통해 변수들을 처리하는 예시에 대해 보여드리려고 했습니다. 초보 개발자분들이 미래에 자신만의 트레이딩 시스템을 개발하실 때에 도움이 되었으면 합니다. 또한 수학적 통계 방법을 사용하는 방법에 대한 문서가 앞으로도 더 나왔으면 하며 마칩니다.
ALGLIB 라이브러리 파일들은 별도로 다운받아야합니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/1240
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

 객체지향적 접근을 이용하여 EA 모드 프로그래밍하기
객체지향적 접근을 이용하여 EA 모드 프로그래밍하기
 MQL5 프로그래밍 기초: 터미널 글로벌 변수
MQL5 프로그래밍 기초: 터미널 글로벌 변수
 모스크바 거래소의 파생 상품 시장 사례를 통한 거래소 가격 책정 원칙
모스크바 거래소의 파생 상품 시장 사례를 통한 거래소 가격 책정 원칙
 리퀴드 차트
리퀴드 차트
이것은 흥미로운 역설입니다. 이에 대한 자세한 내용은 어디에서 확인할 수 있나요?
흥미로운 역설입니다. 이에 대한 자세한 내용은 어디에서 확인할 수 있나요?
인체공학적 환경이 무엇을 의미하는지 명확히 설명해 주세요.귀하의 기사는 저에게 이중적인 인상을줍니다.
게다가. 이 포럼에서는 결과에 대한 가상의 평가에 대해 질문하는 행위 자체가 매우 중요합니다. 포럼은 마쉬카를 그리고 그 간격에 마쉬카가 아니라 이것이 사실이라고 가정하는 사람들로 가득 차 있습니다.
마이너스.
Reshetov에 전적으로 동의합니다. 당신이 말한 모든 것-이것은 고정 시리즈 또는 그에 가까운 시리즈, 즉 시간에 따른 모와 편차의 변화가 거의없는 시리즈를 의미합니다. 그러나 금융 시장에는 그러한 시리즈가 없으며 금융 시장에 대한 통계의 전체 적용은 시계열의 고정성을 중심으로 이루어집니다. 가장 유명한 예는 ARIMA, ARCH 등입니다.
그림 2에 히스토그램이 표시된 무작위 계열은 이 계열이 고정 계열과 관계가 약하고 왜곡되어 있으며 꼬리가 상당히 다르다는 것을 보여줍니다. 특히 사용자가 그린 완벽한 정상 곡선과 비교하면 더욱 잘 드러납니다. 따라서 귀하의 추론은 이 예시에는 전혀 적용되지 않습니다. 이 예시는 레셰토프의 생각을 보여주는 예시일 뿐입니다.
추신. 통계에서 가장 위험하고 비열한 개념은 상관 관계입니다. 전혀 언급하지 않는 것이 좋습니다.
...당신이 말한 모든 것 - 이것은 고정 시리즈 또는 그에 가까운 시리즈, 즉 시간에 따른 모수와 분산 변화가 거의없는 시리즈를 의미합니다. 그리고 금융 시장에는 그러한 시리즈가 없으며 금융 시장에 대한 통계의 전체 적용은 시계열의 고정성을 중심으로 이루어집니다. 가장 유명한 예는 ARIMA, ARCH 등입니다.
그림 2에 히스토그램이 표시된 무작위 계열은 이 계열이 고정 계열과 관계가 약하고 왜곡되어 있으며 꼬리가 상당히 다르다는 것을 보여줍니다. 특히 사용자가 그린 완벽한 정상 곡선과 비교하면 더욱 잘 드러납니다. 따라서 귀하의 추론은 이 예시에는 전혀 적용되지 않습니다. 이 그림은 레셰토프의 생각을 보여주는 예시입니다.
의견 주셔서 감사합니다!
제 반론을 제시하겠습니다.
고정성은 시계열의 특징입니다. 그림 2는 변동 계열입니다. 이 기사에서는 시계열에 대해 이야기하지 않습니다! 시간이 유용한 특성이라는 데 동의하지만.....
내가 이해하는 한, 등방성은 연구중인 시스템의 특정 안정성을 의미합니다....
그래서 중요한 점에 주목하고 싶습니다. 금융 시계열에 대해 이야기하자면 시스템이 고정되어 있지 않더라도 계량 경제학을 사용하여 모델의 동작을 설명하는 안정적인 모델 (예 : GARCH)을 찾을 수 있습니다. 그리고 여기서 저는 시스템의 불변성-모델에 따른 동작을 볼 수 있습니다.... 하지만 시스템이 모델을 "깨뜨릴"확률이 있다는 조건이 있습니다...
의견을 보내주셔서 감사합니다!
제 반론은 다음과 같습니다.
고정성은 시계열의 특징입니다. 그림 2는 변동 시리즈입니다. 이 기사에서는 시계열에 대해 이야기하지 않습니다! 시간이 유용한 특성이라는 데 동의하지만.....
내가 이해하는 한, 등방성은 연구중인 시스템의 특정 안정성을 의미합니다....
그래서 중요한 점에 주목하고 싶습니다. 금융 시계열에 대해 이야기하자면 시스템이 고정되어 있지 않더라도 계량 경제학을 사용하여 모델의 동작을 설명하는 안정적인 모델 (예 : GARCH)을 찾을 수 있습니다. 그리고 여기서 저는 시스템의 불변성-모델에 따른 동작을 볼 수 있습니다.... 하지만 시스템이 모델을 "깨뜨릴" 확률이 있다는 조건이 있습니다.....
몇 년 전, 저는 대부분의 사람들이 완전히 받아 들일 수없는 한 가지 아이디어를 입증하는 기사를 사이트에 게시했습니다. 즉.
많은 지표가 있습니다. 모든 사람들은 지표가 그려지면 동일하다고 생각합니다. 결국 우리는 바로 이것을 봅니다. 동시에, 우리가 현실에서 보는 것이 존재하지 않을 수 있다는 것은 대부분의 사람들에게 발생하지 않습니다! 그 이유는 진부합니다. 지표에 해당하는 회귀를 취하면 일부 계수의 신뢰 구간이 너무 넓어서 그러한 계수의 값에 대해 전혀 말할 수 없으며 그러한 결함 계수를 버리면 지표 패턴이 완전히 달라진다는 것이 쉽게 드러날 수 있습니다. 그들이 말할 때 : 진실이 있고, 거짓이 있고, 통계가 있다는 것은이 슬프고 매우 익숙하지 않은 상황을 의미합니다. 신뢰 구간을 포함하여 아무것도 신뢰할 수 없습니다.
그래서 저는 파라메트릭 모델을 떠나 머신러닝 기반 모델에 참여하게 되었습니다. 거기에는 고정성에는 문제가 없지만 과잉 훈련의 문제가 완전히 영광입니다.
그리고 저는 그 기사가 마음에 들었습니다.
예, 비교 시스템 (또는 시스템)이 매개 변수를 변경하면 테스트 결과가 쓸모가 없습니다.
그러나 방법 적용의 데모는 매우 기쁩니다. Forex에서는 드문 일입니다!
나는 견적 가격에 대해 비슷한 방법을 정확하게 적용하는 사람으로서 다른 것을 말하고 싶습니다. 환경이 균질한지 (두 개의 독립된 대형 샘플에서) 미리 확인한 다음 가설 테스트 결과를 어느 정도 침착하게 신뢰할 수 있습니다. 이는 동일한 테스트를 통해서도 가능합니다.