

In this blog i'm exloring how the local memory operates with regard to a work group (of work items).
We create a simple kernel that will export IDs , global id, local id, group id of a work item .
Additionally we will instantiate a local integer using prefix __local within the kernel function
and we will increase it (++) .
Local memory is shared within a work group so we will see what happens with execution as we capture the value of that
variable and pass it to the global slot of the work item that is running .
Ow yeah we will also have an output array along with the IDs and throw the value it saw in there .
So while we'll have one local variable we will get its state across multiple work items.
this is the code :
#property version "1.00" int OnInit() { //--- EventSetMillisecondTimer(33); //--- return(INIT_SUCCEEDED); } void OnDeinit(const int reason) { //--- } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global int* output){\r\n" "//initialized once in local memory for each compute unit\r\n" "__local int f;" "f++;" "output[get_global_id(0)]=f;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=8; int global_ids[];ArrayResize(global_ids,items,0); ArrayFill(global_ids,0,items,0); int local_ids[];ArrayResize(local_ids,items,0); ArrayFill(local_ids,0,items,0); int group_ids[];ArrayResize(group_ids,items,0); int output[];ArrayResize(output,items,0); int global_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); CLSetKernelArgMem(ker,3,output_handle); uint offsets[]={0}; uint works[]={items}; CLExecute(ker,1,offsets,works); //CLExecute(ker); while(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel finished"); CLBufferRead(global_id_handle,global_ids,0,0,items); CLBufferRead(local_id_handle,local_ids,0,0,items); CLBufferRead(group_id_handle,group_ids,0,0,items); CLBufferRead(output_handle,output,0,0,items); int f=FileOpen("OCL\\localmemtestlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+" : OUTPUT["+IntegerToString(i)+"]="+IntegerToString(output[i])+"\n"); } FileClose(f); //get number of groups int groups_created=group_ids[0]; for(int i=0;i<ArraySize(group_ids);i++){ if(group_ids[i]>groups_created){groups_created=group_ids[i];} } int compute_units=CLGetInfoInteger(ker,CL_DEVICE_MAX_COMPUTE_UNITS); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); Print("Device max work group size("+device_max_work_group_size+")"); Print("Device max compute units("+compute_units+")"); Print("Device Local Mem Size ("+CLGetInfoInteger(ctx,CL_DEVICE_LOCAL_MEM_SIZE)+")"); Print("------------------"); Print("Groups created : "+IntegerToString(groups_created+1)); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); CLBufferFree(output_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } }
We output the contents of the id arrays and output array to a file and inspect them . Let's run it for 8 items , we must surpass 256 items in this device for it to start spliting automatically to groups as reported by Kernel work group size. ,we have 8 items and so there will only be 1 group.
Here is the file output :
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : OUTPUT[0]=1 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : OUTPUT[1]=1 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : OUTPUT[2]=1 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : OUTPUT[3]=1 GLOBAL.ID[4]=4 : LOCAL.ID[4]=4 : GROUP.ID[4]=0 : OUTPUT[4]=1 GLOBAL.ID[5]=5 : LOCAL.ID[5]=5 : GROUP.ID[5]=0 : OUTPUT[5]=1 GLOBAL.ID[6]=6 : LOCAL.ID[6]=6 : GROUP.ID[6]=0 : OUTPUT[6]=1 GLOBAL.ID[7]=7 : LOCAL.ID[7]=7 : GROUP.ID[7]=0 : OUTPUT[7]=1
We can see all the ids printed and the output , all the values are 1 .
You probably expected that as all these items executed at the same time , so , the initial value they saw before the ++'ed it was 0.
The specs state that we instantiate the local integer f for the compute unit but a work group runs in one compute unit , so the next question is do we instantiate it per work group as well ?
Let's find out , let's add a local[] uint to send the execute function , as seen in the previous blogs , to split the work in 2 work groups with 4 work items each .
We'll see the same output probably and the only change will be in local ids and group ids
This is the line we add above the execute function and to use it we just add it as the last argument in the execution function.
(we are specifying 4 items per group in this dimension)
uint local[]={4}; CLExecute(ker,1,offsets,works,local);
As expected our code creates 2 groups :
2023.05.04 00:59:05.922 blog_simple_local_mem_operation (USDJPY,H1) Groups created : 2
And this is the output file :
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : OUTPUT[0]=1 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : OUTPUT[1]=1 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : OUTPUT[2]=1 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : OUTPUT[3]=1 GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : OUTPUT[4]=1 GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : OUTPUT[5]=1 GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : OUTPUT[6]=1 GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : OUTPUT[7]=1
as expected , the local memory integer f is instantiated (or allocated? what you call it) per work group .
Awesome.
But what if you want the value to increase (of f) within the work item in order to use it ?
There are commands to do that with the atomic_ prefix , in this case we are interested in the atomic_inc .
What they do is essentially "guard" the area around the variable f until the work item changes it , so i guess it has a small hit on speed .
(hope i'm not butchering the explanation here)
So let's write a version of the above which exports both the atomic and non atomic value , we'll name these accordingly
the code now looks like this :
void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global int* atomic_output," "__global int* non_atomic_output){\r\n" "//initialized once in local memory for each compute unit\r\n" "__local int with_atomic,without_atomic;" "with_atomic=0;" "without_atomic=0;" "atomic_inc(&with_atomic);" "without_atomic++;" "atomic_output[get_global_id(0)]=with_atomic;" "non_atomic_output[get_global_id(0)]=without_atomic;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int items=8; int global_ids[];ArrayResize(global_ids,items,0); ArrayFill(global_ids,0,items,0); int local_ids[];ArrayResize(local_ids,items,0); ArrayFill(local_ids,0,items,0); int group_ids[];ArrayResize(group_ids,items,0); int atomic_output[];ArrayResize(atomic_output,items,0); int non_atomic_output[];ArrayResize(non_atomic_output,items,0); int global_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int atomic_output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); int non_atomic_output_handle=CLBufferCreate(ctx,items*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); CLSetKernelArgMem(ker,3,atomic_output_handle); CLSetKernelArgMem(ker,4,non_atomic_output_handle); uint offsets[]={0}; uint works[]={items}; uint local[]={4}; CLExecute(ker,1,offsets,works,local); //CLExecute(ker); while(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel finished"); CLBufferRead(global_id_handle,global_ids,0,0,items); CLBufferRead(local_id_handle,local_ids,0,0,items); CLBufferRead(group_id_handle,group_ids,0,0,items); CLBufferRead(atomic_output_handle,atomic_output,0,0,items); CLBufferRead(non_atomic_output_handle,non_atomic_output,0,0,items); int f=FileOpen("OCL\\localmemtestlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<items;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+" : ATOMIC.OUTPUT["+IntegerToString(i)+"]="+IntegerToString(atomic_output[i])+" : NON-ATOMIC.OUTPUT["+IntegerToString(i)+"]="+IntegerToString(non_atomic_output[i])+"\n"); } FileClose(f); //get number of groups int groups_created=group_ids[0]; for(int i=0;i<ArraySize(group_ids);i++){ if(group_ids[i]>groups_created){groups_created=group_ids[i];} } int compute_units=CLGetInfoInteger(ker,CL_DEVICE_MAX_COMPUTE_UNITS); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE); Print("Kernel local mem ("+kernel_local_mem_size+")"); Print("Kernel private mem ("+kernel_private_mem_size+")"); Print("Kernel work group size ("+kernel_work_group_size+")"); Print("Device max work group size("+device_max_work_group_size+")"); Print("Device max compute units("+compute_units+")"); Print("Device Local Mem Size ("+CLGetInfoInteger(ctx,CL_DEVICE_LOCAL_MEM_SIZE)+")"); Print("------------------"); Print("Groups created : "+IntegerToString(groups_created+1)); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); CLBufferFree(atomic_output_handle); CLBufferFree(non_atomic_output_handle); }else{Print("Cannot create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Cannot create ctx"); } }
So we initialize per group the variables with_atomic and without_atomic
and we will be exporting the their values too . Let's run it with the same items and local items
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : ATOMIC.OUTPUT[0]=4 : NON-ATOMIC.OUTPUT[0]=1
GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : ATOMIC.OUTPUT[1]=4 : NON-ATOMIC.OUTPUT[1]=1
GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : ATOMIC.OUTPUT[2]=4 : NON-ATOMIC.OUTPUT[2]=1
GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : ATOMIC.OUTPUT[3]=4 : NON-ATOMIC.OUTPUT[3]=1
GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : ATOMIC.OUTPUT[4]=4 : NON-ATOMIC.OUTPUT[4]=1
GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : ATOMIC.OUTPUT[5]=4 : NON-ATOMIC.OUTPUT[5]=1
GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : ATOMIC.OUTPUT[6]=4 : NON-ATOMIC.OUTPUT[6]=1
GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : ATOMIC.OUTPUT[7]=4 : NON-ATOMIC.OUTPUT[7]=1 Aaaand we get thiiis .... hmmm
The atomic gives us the last value it had why ?
well if we look at the code we are passing -to the global with_atomic_output array- the value of the local variable almost at the end of the work group's execution.
So imagine this :
- 4 work items (of the first group) enter the compute unit for execution
- Each one get's assigned to a Processing Element
- CU initializes the 2 integers with_atomic and without_atomic
- Each work item starts executing in parallel
- Generally a calculation is wayy faster than a transfer to the global memory
- And we can say that other than the atomic_inc(); function nothing else holds back
the work items until each one reaches the point it's supposed to send data back to the with_atomic array. - So at the time each item reaches the output stage the value of with_atomic is 4 already.
We might be able to see it if we place a private int to the atomic call and add 1 to it .
The khronos documentation states this for the atomic_inc()
So it is telling us that if we place an integer to the left of the atomic call we will receive the old value of the local variable .
That means the local variable will be locked and then the private integer will receive the value at that point , then the operation (++ because inc()) will happen on the local variable and then it will unlock. So we are getting the value this work item "used".
Then the variable we have will be private , we'' slap +1 on it and get the value at that instance !
Let's export that too in fact .
We add one more buffer , one more argument , we link the buffer to the kernel , we retrieve the value at the end , we print it in the file and we don't forget to free the buffer .
Now , the kernel looks like this to the part that gets the "old" from the atomic call :
int this_item_only; this_item_only=atomic_inc(&with_atomic)+1;
Creates a private int for each item called this_item_only , then it gets the old value of the local variable with_atomic and adds one to it
-excuse my variable names , its for the test , and from multiple tests i ran -
Here is the file output :
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : ATOMIC.OUTPUT[0]=4 : NON-ATOMIC.OUTPUT[0]=1 : INSTANCE.OUTPUT[0]=1
GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : ATOMIC.OUTPUT[1]=4 : NON-ATOMIC.OUTPUT[1]=1 : INSTANCE.OUTPUT[1]=2
GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : ATOMIC.OUTPUT[2]=4 : NON-ATOMIC.OUTPUT[2]=1 : INSTANCE.OUTPUT[2]=3
GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : ATOMIC.OUTPUT[3]=4 : NON-ATOMIC.OUTPUT[3]=1 : INSTANCE.OUTPUT[3]=4
GLOBAL.ID[4]=4 : LOCAL.ID[4]=0 : GROUP.ID[4]=1 : ATOMIC.OUTPUT[4]=4 : NON-ATOMIC.OUTPUT[4]=1 : INSTANCE.OUTPUT[4]=1
GLOBAL.ID[5]=5 : LOCAL.ID[5]=1 : GROUP.ID[5]=1 : ATOMIC.OUTPUT[5]=4 : NON-ATOMIC.OUTPUT[5]=1 : INSTANCE.OUTPUT[5]=2
GLOBAL.ID[6]=6 : LOCAL.ID[6]=2 : GROUP.ID[6]=1 : ATOMIC.OUTPUT[6]=4 : NON-ATOMIC.OUTPUT[6]=1 : INSTANCE.OUTPUT[6]=3
GLOBAL.ID[7]=7 : LOCAL.ID[7]=3 : GROUP.ID[7]=1 : ATOMIC.OUTPUT[7]=4 : NON-ATOMIC.OUTPUT[7]=1 : INSTANCE.OUTPUT[7]=4 Hell yeah .
Now the first time i did this i used 512 items (instead of 8) which allowed me to find another possible issue :
I was getting "ATOMIC.OUTPUT" values of 224 on the second group instead of 256 (group size was 256 per group , 2 groups)
That was done by the offset in execution for some of the work items , 32 items were starting later leading to them not having reached the
atomic_inc part yet and at that same time the other 224 work items had hit their export to global memory stages thus reporting 224 as the atomic output.
Here is a schematic :
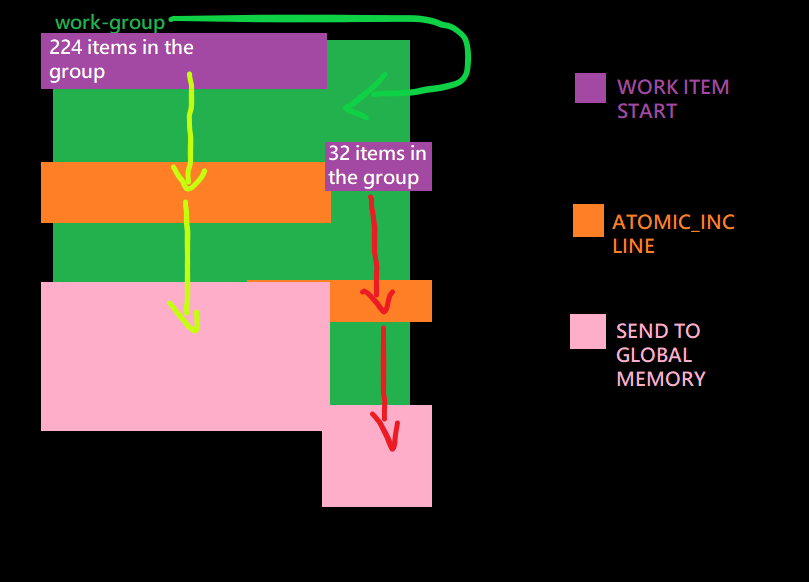
The 224 items reach the global memory part when the reset 32 items have not yet hit the atomic_inc part
You have seen the solution to the articles and its that of a barrier .
What the barrier is gonna do is stop all GROUP ITEMS at the line you place it at until ALL OTHER GROUP ITEMS reach that line too .
That solved the issue this is the line of code :
barrier(CLK_GLOBAL_MEM_FENCE);
If we specified CLK_LOCAL_MEM_FENCE , then the items IN THE GROUP would not be able to do anything to the local memory until ALL ITEMS of that group had hit that line .
Where do you think this line went ?
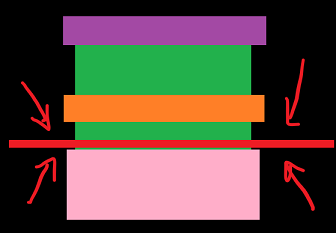
Correct , before the export to the global memory .
I'm attaching the final source code .
Cheers




")
![[XAUUSD]: Weekly Liquidity Activation Points (timings), June 22-26, 2026](https://c.mql5.com/6/1013/splash-preview-771790.png "[XAUUSD]: Weekly Liquidity Activation Points (timings), June 22-26, 2026")
")