Einsatz künstlicher Intelligenz bei MTS
- DIE IDEENBÖRSE
- [Archiv!] Jede Anfängerfrage, um das Forum nicht zu überladen. Fachleute, gehen Sie nicht daran vorbei. Könnte nirgendwo ohne dich hingehen - 2.
- Berater für einen Artikel. Tests für alle Teilnehmer.
Äquivalent zur Glättung von AC unter Verwendung eines Cypher-Filters mit einigen Eigenschaften. Die Glättungskoeffizienten sind nicht ausgeglichen, was einem Stein auf der Kauftaste gleichkommt. Der Ziegelstein (+ z.B. Stochastik) funktioniert sehr gut von selbst, wenn man nur weiß, wann man ihn kaufen und wann man verkaufen muss. Unter Berücksichtigung der Tatsache, dass der Wechselstrom während 21 Takten 2 Mal abfallen kann, und des Vorhandenseins von 4 optimierbaren Parametern......))))
Aber für mich wirft es ein Licht darauf, wie neuronale Netze funktionieren und warum sie nicht so effizient sind, wie wir sie gerne hätten.
Am Anfang der kreativen Periode hatte ich ein Hobby - EAs für die Arbeit auf m1 zu schreiben, basierend auf den Ergebnissen der letzten Woche (7200 Bars, im Gegensatz zu 66000) - so viel wie 300 Prozent pro Woche wurden im Tester angezeigt.....
Ich frage mich, wie viele Oberschwingungen der Preis in eine Fourier-Reihe zerlegt werden muss, um nach der Optimierung einen Gral zu erhalten?
Äquivalent zur Glättung von AC unter Verwendung eines Cypher-Filters mit einigen Eigenschaften. Die Glättungskoeffizienten sind nicht ausgeglichen, was einem Stein auf der Kauftaste gleichkommt. Der Ziegelstein (+ z.B. Stochastik) funktioniert sehr gut von selbst, wenn man nur weiß, wann man ihn kaufen und wann man verkaufen muss. Unter Berücksichtigung der Tatsache, dass der Wechselstrom innerhalb von 21 Takten 2 Mal abfallen kann, und des Vorhandenseins von 4 optimierbaren Parametern......))))
Aber für mich wirft es ein Licht darauf, wie neuronale Netze funktionieren und warum sie nicht so effizient sind, wie wir sie gerne hätten.
Am Anfang der kreativen Periode hatte ich ein Hobby - EAs für die Arbeit auf m1 zu schreiben, basierend auf den Ergebnissen der letzten Woche (7200 Bars, im Gegensatz zu 66000) - so viel wie 300 Prozente pro Woche wurden im Tester angezeigt.....
Ich frage mich, wie viele Oberschwingungen der Preis in eine Fourier-Reihe zerlegt werden muss, um nach der Optimierung einen Gral zu erhalten?
Was den AC-Oszillator betrifft, so betrachtet der Expert Advisor nicht nur seinen letzten Wert (Entscheidungen, die auf den letzten Werten basieren, werden in der technischen Analyse am häufigsten verwendet), sondern er untersucht auch die Historie, d.h. welche 3 anderen Werte der Indikator in der Vergangenheit hatte. Er interessiert sich für das Verhalten von Oszillatoren zur Entscheidungsfindung. Genau dieses Verhalten wird in das neuronale Netz eingegeben. Und am Ausgang erhalten wir Kaufen oder Verkaufen.
Eine weitere Neuerung ist nicht das Standardtraining für neuronale Netze, sondern die Auswahl der Gewichte anhand historischer Daten mit Hilfe eines genetischen Algorithmus. Ich habe beide Varianten ausprobiert. Genetics liefert etwas schlechtere Ergebnisse und ist langsamer in der Zeit. Aber es gibt keinen eingebauten neuronalen Algorithmus und das Lernen in MT4. Aber es gibt eine Optimierung auf der Grundlage der Genetik. Und einige Forscher in diesem Bereich haben erkannt, dass dynamisches Lernen nicht sehr geeignet ist, wenn sich die Situation drastisch ändert. Wenn die Bullen auf dem Markt die Oberhand gewinnen, wird sich das System auf den Bullen-Trend einstellen und den Bären-Trend vergessen - und umgekehrt. Samuel A. L. 1959, "Some studies in machine learning using the game of checkers" (IBM J. Research and Devepopmend 3: 210 - 229), stieß erstmals auf diese Ungeheuerlichkeit und beschrieb sie. Er stellte fest, dass sein Programm, wenn es einen professionellen Gegner hatte, allmählich zu einem Spiel auf professionellem Niveau überging. Aber wenn der Gegner ein Anfänger war, dann "vergaß" das Programm die vorherige Stufe und begann, zum primitiven Spiel überzugehen. Daher ist es wahrscheinlich nicht sinnvoll, das Neuron dynamisch auf seine eigenen Fehler und Verluste zu trainieren. Es ist einfacher, die Geschichte zu durchlaufen, um eine dem Markt angemessene Handelsstrategie zu entwickeln.
Was die Grals angeht, muss man nicht besonders schlau sein. Sie müssen nur eine Reihe von Bedingungen erfüllen:
1. Das System muss Positionen entweder ohne Stop-Losses oder mit Stop-Losses in einem sehr großen Abstand eröffnen, so dass die Wahrscheinlichkeit, dass sie funktionieren, nahe bei 0 liegt.
2. Ein leistungsstarker Filter, der auf mehreren Indikatoren basiert, deren Auslösebedingungen durch ein logisches UND (&&) getrennt sind. Und eine Menge von Eingabeparametern dieser sehr Indikatoren in die MTS externen Einstellungen zu ziehen, so dass nur ein paar Positionen wurden während mehrerer Jahre von historischen Daten auf Tests geöffnet.
3. Hinzu kommen Kapital- und Risikomanagement mit einem erhöhten Anteil
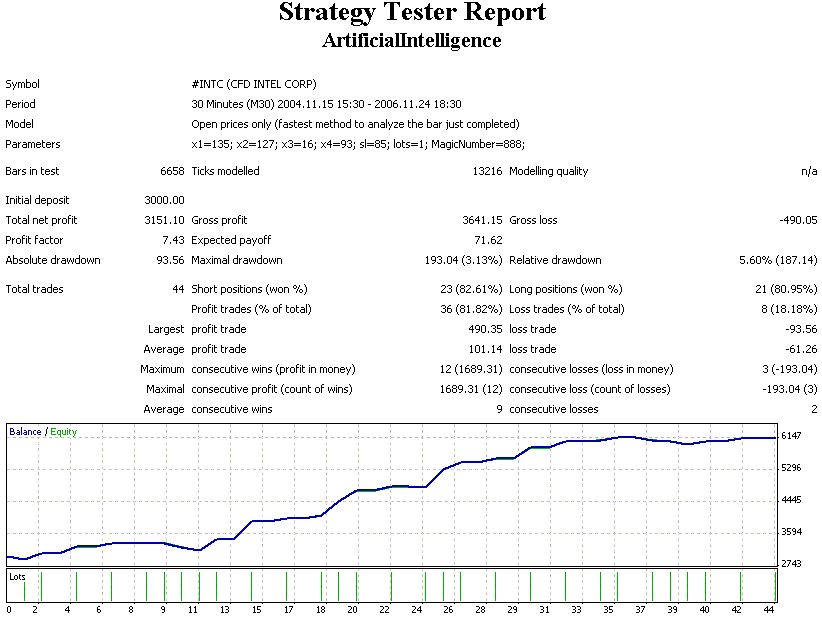
Ich verstehe nicht, wie man ernsthaft über eine Strategie diskutieren kann, die in 2 Jahren 44 Geschäfte einbringt... Zu wenig Statistiken!
Wir nehmen den Wert von 4 Punkten, multiplizieren jeden Wert mit einem Koeffizienten und summieren ihn - was ist das nicht, eine Glättung durch einen Filter?
wir nehmen den Wert von 4 Punkten, multiplizieren jeden Wert mit einem Koeffizienten, summieren - was ist das nicht, eine Glättung durch einen Filter?
Haben Sie schon von linear gewichteten gleitenden Durchschnitten gehört?
Was auch immer es ist, es hat ein Recht auf Leben. Die Idee mag nicht neu sein, aber sie ist sehr interessant und klug umgesetzt, und... in der Lage ist, einen Gewinn zu erzielen. Ich habe mehrere Vorwärtstests nach dem "Lernen" durchgeführt, und die Ergebnisse sind ermutigend. Vielen Dank an den Autor.
Was auch immer es ist, es hat ein Recht auf Leben. Die Idee mag nicht neu sein, aber sie ist sehr interessant und klug umgesetzt, und... in der Lage ist, einen Gewinn zu erzielen. Ich habe mehrere Vorwärtstests nach dem "Lernen" durchgeführt, und die Ergebnisse sind ermutigend. Vielen Dank an den Autor.
Und mit Gundosos darüber zu streiten, ob Neuronen wirksam sind oder nicht, ist reine Zeitverschwendung. Ich lege es nach dem Prinzip aus: Wenn du es willst, kannst du es haben, aber wenn du es nicht sehen willst, kannst du es haben. Aber mit der Hoffnung, dass sich jemand findet, der sich damit auskennt und den Code verbessern oder eine interessantere Idee zur Lösung des Problems vorschlagen kann.
wir nehmen den Wert von 4 Punkten, multiplizieren jeden Wert mit einem Koeffizienten, summieren - was ist das nicht, eine Glättung durch einen Filter?
Haben Sie schon von linear gewichteten gleitenden Durchschnitten gehört?
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.