Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 1929
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
im Rahmen eines persönlichen Gesprächs
Ihre Wahl
einfache Version
wie Sie sehen können, sind die Werte recht unterschiedlich, Sie können das selbst überprüfen
In meinem Modell.
daher nur eine Spalte, aber das ist nicht wirklich wichtig.
===================UPD
Mann, sie sind jedes Mal anders, wenn Sie umap_tranform ausführen, das sollte nicht sein
Ich habe nicht aufgepasst. Es ist schon lange her...
im Rahmen eines persönlichen Gesprächs
Ihre Option
einfache Version
wie Sie sehen können, sind die Werte recht unterschiedlich, Sie können das selbst überprüfen
In meinem Modell.
daher nur eine Spalte, aber das ist nicht wirklich wichtig.
===================UPD
Mann, die sind jedes Mal anders, wenn Sie umap_tranform ausführen, das sollte nicht so sein
Normalerweise stellt man für die Wiederholbarkeit den Seed (des eingebauten HSS) auf einen bestimmten Wert ein. Wenn nicht, wird der Zufall verwendet. Vielleicht hat dieses Paket auch Seed - prüfen Sie es.
Ich denke schon, aber der Punkt ist, dass es ohne RMS immer dasselbe sein sollte, im "umap"-Analogpaket ist das Ergebnis immer dasselbe
für Sie, mit nur einer Hoffnung, dass Sie das r-ku lernen)
Es gibt zwei Funktionen
get.indи
get.targetder erste erzeugt einen Datensatz von Indikatoren, der zweite das Ziel des Zickzackkurses
Sie brauchen nur die Daten mit einem Schlusskurs von 10k zu laden und in die Variable clos zu schreiben
und erhalten Sie Ihre umap mit dem Ziel
https://github.com/jlmelville/uwotfür Sie, mit der einzigen Hoffnung, dass Sie das p lernen)
Es gibt zwei Funktionen
и
die erste erstellt einen Datensatz von Indikatoren, die zweite erstellt ein Ziel von Zickzack
Sie brauchen nur die Daten mit einem Schlusskurs von 10k zu laden und in die Variable clos zu schreiben
und erhalten Sie Ihre umap mit dem Ziel
https://github.com/jlmelville/uwotSehr schön, Sie kennenzulernen, danke!
Ich wünsche mir mehr Kommentare :)
Hier stellt sich die Frage, wie die Prädiktoren aus der Datei mit dem resultierenden Ziel synchronisiert werden können.
Es hat mich sehr gefreut, Sie kennenzulernen, vielen Dank!
Ich wünsche mir mehr Kommentare :)
Die Frage ist hier, wie man die Prädiktoren aus der Datei mit dem Ziel synchronisiert.
Nun, da das Ziel mit Hilfe des Preises erstellt wird, ist es bereits synchron, und wenn die Prädiktoren mit Hilfe derselben Szene erstellt werden, bedeutet dies, dass sie es auch sind.)
Oder ich verstehe die Frage nicht.
Ich habe versucht, die Variablen so zu benennen, dass sie ohne Kommentare verständlich sind
Eine Frage von einem Nerd.
Es gibt drei Variablen A, B, C. Eine Art Bedingung wird von ihnen handschriftlich vermerkt. Zum Beispiel.
Ich möchte diesen Zustand automatisch reproduzieren. Ich brauche sie nicht zu finden, denn ich weiß sie bereits. Aber ich muss z.B. Dutzende von Gewichtskoeffizienten haben, deren Kombination diese Bedingung mit hoher Wahrscheinlichkeit erfüllen kann, wenn ich A, B, C dort einsetze (Polynom oder HC - ich weiß es nicht, weil ich Null weiß) und die ursprüngliche Bedingung erhalte.
Mich interessiert, welche Art und wie viele Eingangsgewichte die geforderte Funktion hat, damit solche Ausgangsbedingungen über Gewichte reproduziert werden können?
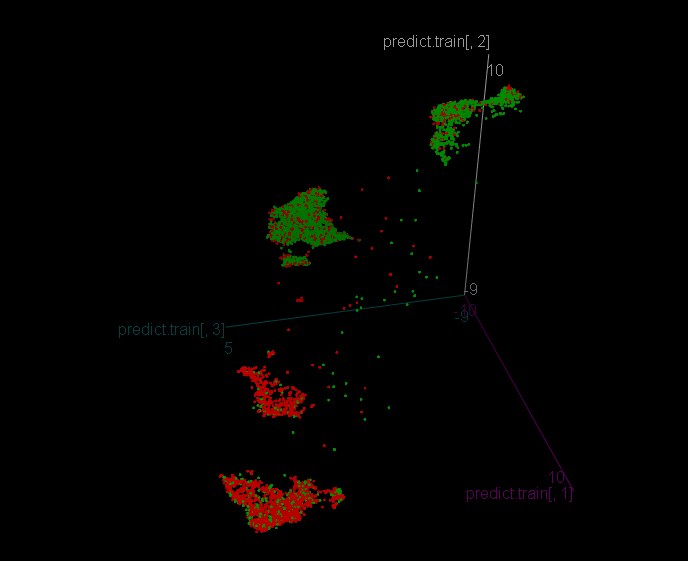
Ich erzähle und zeige Ihnen, wie die Bäume auf den Clustern ausgebildet wurden.
Wir haben das folgende Modell für die Klassenerkennung
Der Verlauf hat eine ziemlich genaue Genauigkeit von 0,9196756 - d.h. die Logik des Clusters ist recht gut reproduzierbar.
Dann habe ich für jeden Cluster ein Modell trainiert
Cluster 1
Cluster 2
Cluster 3
Cluster 4
Alle Cluster haben eine Genauigkeit von 0,53 oder so.
Und so sieht das Modell ohne Aufteilung in Cluster aus
Die Genauigkeit von 0,5293815 ist in etwa die gleiche wie bei Clustern.
Wenn wir Modelle für Cluster und ein Baummodell mit der gesamten Stichprobe vergleichen, sehen wir, dass Cluster-Bäume mehr Blätter mit verallgemeinerten Stichprobeninformationen mit Ziel 1 und -1 haben, was theoretisch gut ist.
Schauen wir uns an, was die Tests zeigen - zunächst die Ausbildungszeit
Modell ohne Clusterpartitionierung:
Modell mit Partitionierung in Clustern:
Wir sehen, dass die Genauigkeit mit dem Modell ohne Clustering besser ist, aber mehr mit dem Modell mit Clustern gehandelt wird, was eine bessere finanzielle Leistung ermöglicht.
Schauen wir uns nun die Stichprobe außerhalb der Ausbildung an.
Und hier sind unsere Cluster:
Und das Modell ohne Cluster:
Die Situation scheint hier umgekehrt zu sein - viele Trades hatten einen negativen Effekt, als der Markt ab April zu krampfen begann.
Ich beschloss, die Blätter der Clustermodelle einzeln zu betrachten, wenn es keinen Cluster gegeben hätte, und zwar in einem absteigenden Histogramm:
Insgesamt 6 unrentable Blätter (Null-Ziel entfernt - es ist ein Eintrag Verbot), stellt sich heraus, dass wir nicht in der richtigen Cluster sind?
Da das Ziel auf dem Preis basiert, ist es bereits synchronisiert, und wenn die Prädiktoren auf der gleichen Szene basieren, sind sie es auch.)
Oder ich verstehe die Frage nicht.
Ich habe versucht, die Variablen so zu benennen, dass sie ohne Kommentare verständlich sind
Wie kann man einen Datensatz mit Prädiktoren und Schlusskursen nehmen und ihn mit der Angabe einer Spalte mit Schlusskursen laden, anstatt die Variante der Generierung von Indikatoren in R zu verwenden?
Wie ich es verstehe, da das Ziel ZZ Tops ist, dann sollte ein Teil der Stichprobe mit Prädiktoren herausgefiltert werden, hier, und so zu füttern die Prädiktoren sollte man auch herausfiltern, die Tabelle mit Prädiktoren, oder was?
Eine Frage von einem Nerd.
Es gibt drei Variablen A, B, C. Eine Art Bedingung wird von ihnen handschriftlich vermerkt. Zum Beispiel.
Ich möchte diesen Zustand automatisch reproduzieren. Ich brauche sie nicht zu finden, denn ich weiß sie bereits. Aber ich muss z.B. Dutzende von Gewichtskoeffizienten haben, deren Kombination diese Bedingung mit hoher Wahrscheinlichkeit erfüllen kann, wenn ich A, B, C dort einsetze (Polynom oder HC - ich weiß es nicht, weil ich Null weiß) und die ursprüngliche Bedingung erhalte.
Mich interessiert, welche Art und wie viele Eingangsgewichte die geforderte Funktion hat, damit solche Ausgangsbedingungen über Gewichte reproduziert werden können?
alternativ
Die Eingabe von NS sind die Werte A,B,C n-mal (sagen wir 1000), die Ausgabe ist die Antwort Ihrer Formel für diese Werte als 0;1. Versuchen Sie es. Und sehen Sie den Klassifizierungsfehler und wie gut das Modell die Bedingung wiedergibt.
Wenn man genau sehen und interpretieren will, was für eine Art das ist, kann man das durch Bäume tun.
Variante 2 (wenn die erste nicht gut funktioniert hat) - A, B, A-B, C, A+3*C, 2B - Variablen, alle die gleichen wie in der ersten Variante, die in den Baum zu setzen sind. Und Sie können seine Struktur wie auf den Bildern von Alexey oben sehen