
Я тут читаю: Флах П. - Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных - 2015
там есть несколько страниц посвященных этой теме. Вот итоговая:

- Отмеченный пункт 1 говорит, что балансировка полезна.
- Но имеется и пункт 2. Из которого можно сделать вывод, что при большой выборке, когда примеров малого класса будет достаточно много, то выборка по нему станет репрезентативной. И тогда балансировка не нужна.
Хотя мы и добавки будем вносить тысячами, и тогда модель тоже может измениться.
А может оно и правильно. Рынок как говорят - меняется, пусть и модель меняется. - Но еще есть п. 3. Но сложно узнать есть ли такая поправка в конкретной реализации дерева в выбранной для использования программе.
Примечание:
При не репрезентативных выборках, как меру нечистоты можно использовать корень индекса Джини (Флах П стр 147, 160 и 169) он же метод DKM (индекс и коэф Джини разные вещи - не путать)
https://www.kaggle.com/nigelcarpenter/r-xgboost-with-gini-eval-and-stopping тут коэф
https://www.kaggle.com/oxofff/gini-scorer-cv-gridsearch и тут коэф
Примеров кода с индексами Джини нетДругой вариант — выравнивать по кол-ву примеров по классам.
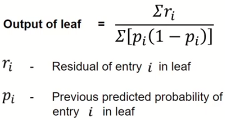





")

