OpenCL: testes internos de implementação em MQL5 - página 29
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
...
--
Faça 512 e veja o que obtém. Não tenha medo de esmagar o programa, ele só o tornará melhor. :) Quando o tiver feito, afixe-o aqui.
OK! Com 512 passes e 144000 barras:
Bem e se 60 é óptimo, então geralmente frio:
//---
Ou seja, no portátil mais fraco apresentado neste tópico, este é o resultado. Muito promissor.
//---
Infelizmente, não posso discutir o assunto livremente, uma vez que nem sequer entrei no artigo joo e nas redes neurais, enquanto nunca escavei por aí o OpenCL. Não posso usar este ou aquele código sem compreender cada linha de código. Quero saber tudo. ))) Ainda estou a trabalhar no motor do programa de negociação. Há tanto para fazer que a minha cabeça já está a rodopiar. )))
Aumentou a CountBars por um factor de 30 (para 4.320.000), decidiu testar a resistência da pedra à carga.
Não importa: funciona, aquece, mas não transpira muito. A temperatura está a subir lentamente, mas já atingiu a saturação.
A linha vermelha é a temperatura, a linha verde é a carga dos núcleos.
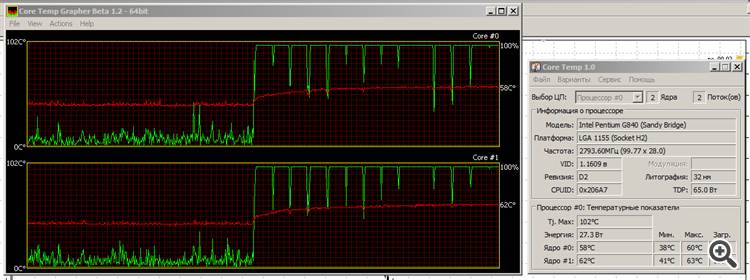
É por isso que adoro o espécime da Ponte Sandy da Intel: é "verde". Sim, os gráficos não são óptimos, mas vamos ver no que se torna Ivy Bridge......
É por isso que eu adoro o modelo Sandy Bridge da Intel: é "verde". Sim, os gráficos não são óptimos, mas veremos no que se torna Ivy Bridge...Oh. (risos) Isto é que é um verdadeiro teste de stress. :) A minha já estaria provavelmente morta por esta altura.
Depois que Haswell e depois Rockwell um pouco mais tarde... )))
Um exemplo de uma implementação de samambaia de Barnsley no OpenCL.
O cálculo é baseado no algoritmo Chaos Game(exemplo) e utiliza um gerador de números aleatórios com uma base de geração que depende do ID do fio e dos retornos get_global_id(0) para criar trajectórias únicas.
Ao escalar, o número de pontos necessários para manter a qualidade da imagem cresce quadraticamente, pelo que esta implementação pressupõe que cada instância do núcleo desenha um número fixo de pontos que se enquadram na área visível.
O número de fios estimado é especificado na linha 191:
o número de pontos está na linha 233:
UPD
IFS-fern.mq5 - Analógico CPU
Em escala=1000:
Fiz três camadas de neurónios 16x7x3. Na verdade, fiz anteontem, depurei hoje. Antes disso, os resultados não cabiam na verificação com o CPU - não vou descrever aqui as razões pelas quais, pelo menos não agora - estou demasiado sonolento. :)
Características temporais :
Amanhã farei o Optimizer para esta grelha. Depois carregarei dados reais e melhorarei o testador até cálculos realistas verificados com o MT5-tester. Depois tratarei do gerador MLP+cl-códigos de grelhas para a sua optimização.
Não afixo o código fonte por causa da ganância, mas o ex5 está incluído para aqueles que gostariam de o testar no seu hardware.
Estou tão estável como sob Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
A propósito, preste atenção: por CPU runtime a diferença entre o seu sistema e o meu (baseado no Pentium G840) não é assim tão grande.
A sua RAM é rápida? Tenho 1333 MHz.
Mais uma coisa: é interessante que ambos os núcleos sejam carregados na CPU durante os cálculos. A queda acentuada da carga no final é após o fim dos cálculos. O que é que isso significaria?
Estou tão estável como sob Putin:
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
A propósito, repare na diferença entre o seu sistema e o meu (baseado no Pentium G840) no tempo de execução da CPU.
2. a sua RAM é rápida? Tenho 1333 MHz.
1. tenho estado a restaurar o meu overclocking no meu tempo livre. uma vez tive um acidente muito grave (descobri mais tarde que o cabo de alimentação da unidade tinha saído da ranhura), por isso carreguei no botão "MemoryOK" na placa-mãe em busca de um milagre. Depois disso, ainda não funcionou, apenas as definições CMOS foram reiniciadas por defeito. Agora, voltei a colocar o processador em 3840 MHz, por isso agora está a funcionar de forma mais inteligente.
2. Ainda não se consegue perceber. :) Em particular, a referência, para a qual Renat mostrou a ligação, mostra 1600MHz. O Windows mostra até 1033MHz :)))), apesar de a memória em si ser de 2GHz, mas a minha mãe pode puxar até 1866 (figurativamente).
Mais uma coisa: é interessante que eu tenha ambos os núcleos carregados ao calcular no CPU. A queda acentuada da carga no final é após o fim dos cálculos. O que é que isso significaria?
Então talvez não esteja de todo na GPU? O condutor está em alta, mas... A minha única explicação é que o cálculo é feito em CPU-OpenCL, apenas, claro, em todos os núcleos disponíveis e usando instruções SSE vectoriais. :)
A segunda variante é que conta simultaneamente com CPU e CPU. Não sei como é que este apoio (CPU-LPU) é implementado pelo condutor, mas em princípio não excluo também uma tal variante de arranque de processamento opentzl.
Esta é a minha especulação, se alguma coisa. Ou como está na moda escrever agora - "IMHO". ;)
Duvido. Especialmente porque só tenho dois núcleos. De onde vem então o lucro de 25x?
Bem, se a pedra tem toda a Intel Math Kernel Library ou Intel Performance Primitives (eu não os descarreguei), ainda é possível... em alguns casos. Mas é improvável, uma vez que pesam centenas de megabytes.
Terei de ver o que o Google tem a dizer sobre o assunto.
Mathemat: Também, curiosamente, os meus cálculos de CPU têm ambos os núcleos carregados.
Não, referia-me à computação pura de CPU sem qualquer OpenCL. A carga está ligeiramente abaixo dos 100% onde cada núcleo tem valores de carga comparáveis. Mas ao executar o código OpenCL, ele vai até 100%, o que pode ser facilmente explicado pela operação da GPU.