
Gaz neuronal en croissance : Implémentation en MQL5
Introduction
Dans les années 90, les chercheurs de artificial neuronal network sont arrivés à la conclusion qu'il était nécessaire d’élaborer une nouvelle classe de ces mécanismes informatiques, dont la caractéristique serait l'absence d'une topologie fixe des couches de réseau. Cela indique que le nombre et la disposition des neurones artificiels dans l'espace des caractéristiques ne sont pas pré-indiqués, mais sont calculés dans le processus d'apprentissage de ces modèles en fonction des caractéristiques des données d'entrée, en s'adaptant indépendamment à celles-ci.
La raison de l'émergence de telles idées était un certain nombre de problèmes pratiques concernant la compression entravée et la quantification vectorielle des paramètres d'entrée, tels que la reconnaissance de la parole et des images, la classification et la reconnaissance de motifs abstraits.
Depuis cette époque self-organizing maps et le Hebbian Learning étaient déjà connus (en particulier, les algorithmes qui produisent la topologisation du réseau, c'est-à-dire créent un ensemble de connexions entre les neurones, formant une couche "framework"), et les approches de un apprentissage compétitif « doux » avait été élaboré (dans de telles procédures, l'adaptation du poids non seulement du neurone « gagnant », mais aussi de ses « voisins » se produit), l'étape logique était de combiner ces méthodes, ce qui a été fait en 1995 par un scientifique allemand Bernd Fritzke qui a créé l'algorithme désormais populaire Growing gaz neuronal (GNG).
La méthode s'est avérée assez réussie, de sorte qu'une série de ses modifications est apparue ; l'un d'eux était l'adaptation pour l'apprentissage supervisé (Supervised-GNG). Comme l'a noté l'auteur, S-GNG a affiché une efficacité considérablement plus grande dans la classification des données que, disons, un réseau de fonctions de base radiales, en raison de la capacité d'optimiser la topologie dans les zones d'espace d'entrée qui sont difficiles à classer. Sans aucun doute, GNG est supérieur au groupement "K-means".
Il est à noter qu'en 2001 Fritzke a mis fin à sa carrière de scientifique à l'université de la Ruhr (Bochum, Allemagne) après avoir reçu une offre d'emploi à la bourse allemande (Deutsche Bӧrse). Eh bien, ce fait était une autre raison de choisir son algorithme comme base pour écrire cet article.
1. La croissance du Gaz Neuronal
Ainsi, GNG est un algorithme qui permet de mettre en œuvre un groupement adaptatif des données d'entrée, c'est-à-dire non seulement diviser l'espace en groupes, mais aussi de déterminer leur nombre requis en fonction des caractéristiques des données.
En commençant avec seulement deux neurones, l'algorithme en modifie systématiquement (augmente principalement) le nombre, tout en créant un ensemble de connexions entre les neurones qui correspond le mieux à la distribution des vecteurs d'entrée, en utilisant l'approche de l'apprentissage Hebbian compétitif. Chaque neurone dispose d’ une variable interne qui accumule ce qu'on appelle "l'erreur locale". Les connexions entre les nœuds sont caractérisées par une variable appelée « âge ».
Le pseudo-code GNG ressemble à ceci :
- Initialisation Créez deux nœuds avec les vecteurs de poids, permis par la distribution des vecteurs d'entrée, et les valeurs nulles des erreurs locales ; connectez des nœuds en définissant son âge sur 0.
- Entrez un vecteur dans un réseau de neural.
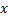
- Trouvez deux neurones
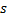 et
et 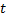 les plus proches de
les plus proches de 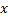 , c'est-à-dire des nœuds avec un vecteur de poids
, c'est-à-dire des nœuds avec un vecteur de poids 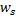 et
et 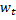 de sorte que
de sorte que 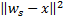 soit minimal, et
soit minimal, et 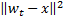 soit la deuxième valeur minimale de distance parmi tous les nœuds.
soit la deuxième valeur minimale de distance parmi tous les nœuds. -
Mettre à jour l'erreur locale du neurone gagnant
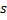 en y ajoutant le carré de la distance entre les vecteurs
en y ajoutant le carré de la distance entre les vecteurs 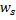 et
et 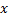 :
:
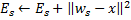
-
Déplacez le neurone gagnant
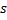 et tous ses voisins topologiques (c'est-à-dire tous les neurones qui ont une connexion avec le gagnant) dans la direction du vecteur
et tous ses voisins topologiques (c'est-à-dire tous les neurones qui ont une connexion avec le gagnant) dans la direction du vecteur 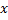 d'entrée par des distances égales aux titres
d'entrée par des distances égales aux titres 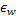 et
et 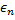 à partir d'un plein.
à partir d'un plein.
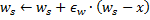
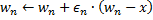
- Augmentez l'âge de toutes les connexions sortantes du gagnant
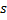 par 1.
par 1. - Si les deux meilleurs neurones
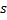 et
et 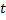 sont connectés, définissez l'âge de leur connexion à zéro. Sinon, créez une connexion entre eux.
sont connectés, définissez l'âge de leur connexion à zéro. Sinon, créez une connexion entre eux. - Supprimez les connexions dont l'âge est supérieur à
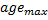 .. S'il en résulte que les neurones n'ont plus de bords d'émanation, supprimez également ces neurones.
.. S'il en résulte que les neurones n'ont plus de bords d'émanation, supprimez également ces neurones. -
Si le nombre de l'itération en cours est un multiple de
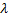 , et que la taille limite du réseau n'a pas atteint, insérez un nouveau neurone
, et que la taille limite du réseau n'a pas atteint, insérez un nouveau neurone 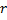 comme suit :
comme suit :- Déterminez un neurone
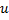 avec la plus grande erreur locale.
avec la plus grande erreur locale. - Déterminez parmi les voisins
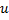 du neurone
du neurone 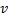 avec une erreur maximale.
avec une erreur maximale. - Créez un nœud
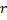 "au milieu" entre
"au milieu" entre 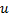 et
et 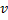 :
:
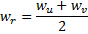
- Remplacez le bord entre
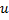 et
et 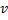 par le bord entre
par le bord entre 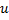 et
et 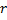 ,
, 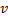 et
et 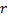 .
. - Diminuez les erreurs de neurones
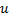 et
et 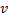 , réglez la valeur de l'erreur de neurone .
, réglez la valeur de l'erreur de neurone . 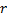 .
.
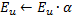
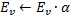
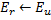
- Déterminez un neurone
-
Diminuez les erreurs de tous les neurones
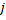 par la fraction
par la fraction 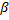 ..
..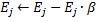
- Si un critère d'arrêt n'est pas encore rempli, passez à l'étape 2.
Examinons comment le gaz neuronal en croissance s'adapte aux caractéristiques de l'espace d'entrée.
Tout d'abord, faites attention à l'augmentation de la variable d'erreur du gagnant à l'étape 4. Cette procédure conduit au fait que les nœuds qui gagnent le plus souvent, c'est-à-dire ceux au voisinage desquels apparaissent le plus grand nombre de signaux d'entrée, ont la plus grande erreur, et donc ces zones sont de premiers candidats au « compactage » en ajoutant de nouveaux nœuds.
Le décalage des nœuds dans la direction du vecteur d'entrée à l'étape 5 indique que le gagnant essaie de "moyenner" sa position parmi les signaux d'entrée situés dans son voisinage. Dans ce cas, le meilleur neurone peu "attire" ses voisins dans la direction du signal ( ![]() est choisi en règle générale).
est choisi en règle générale).
J'explique l'opération avec des bords entre les neurones aux étapes 6-8. La signification du vieillissement et de la suppression des anciennes connexions est que la topologie du réseau doit être au maximum proche de la triangulation Delaunay, c'est-à-dire une triangulation (subdivision en triangles) de neurones dans lequel, entre autres, l'angle minimal de tous les angles des triangles dans la triangulation est maximisé (en évitant les triangles "fins").
En termes simples, la triangulation de Delaunay correspond à la plus "belle", au sens d'entropie maximale, de topologie de la couche. Il convient de noter que la structure topologique n'est pas requise en tant qu'unité distincte, mais lorsqu'elle est utilisée pour déterminer l'emplacement de nouveaux nœuds lorsqu'ils sont insérés à l'étape 8 - ils sont toujours situés au milieu d'un bord.
L'étape p est une correction des variables d'erreur de tous les neurones de la couche. Il s'agit de s'assurer que le réseau "oublie" les anciens vecteurs d'entrée et répond mieux aux nouveaux. Ainsi, nous obtenons la possibilité d'utiliser le gaz neuronal en croissance pour l'adaptation des réseaux neuronaux en fonction du temps, à savoir, des distributions lentement dérivantes des signaux d'entrée. Ceci, cependant, ne lui offre pas la capacité de suivre les changements rapides dans les caractéristiques des entrées (voir plus de détails ci-dessous dans la section où les inconvénients de l'algorithme sont soulevés).
Peut-être devrions-nous examiner le critère d’arrêt séparément. L'algorithme laisse place à la fantaisie des développeurs de systèmes d'analyse. Les options possibles sont : vérifier l'efficacité du réseau sur l'ensemble de test, analyser la dynamique de l'erreur moyenne des neurones, restreindre la complexité du réseau, etc.
À titre informatif, nous travaillerons avec l'option la plus simple - car le but de cet article est de démontrer non seulement l'algorithme lui-même, mais les possibilités de son implémentation au moyen de MQL5; nous continuerons l'apprentissage de la couche jusqu'à épuisement des entrées (naturellement leur nombre est prédéfini).
2. Sélection de la Méthode d'Organisation des Données
Lors de la programmation de l'algorithme, nous devrons évidemment faire face à la nécessité de stocker ce que l'on appelle des "ensembles". Nous aurons deux ensembles – un ensemble de neurones et un ensemble de bords entre eux. Bien que les deux structures évoluent au cours du programme (et nous prévoyons à la fois d'ajouter et de supprimer des éléments), nous devrions également fournir des mécanismes pour cela.
Bien sûr, nous pourrions essayer d'utiliser des tableaux d'objets dynamiques, mais nous devrions effectuer de nombreuses opérations de copie-déplacement de données, ce qui ralentirait essentiellement le programme. Une option plus appropriée pour travailler avec des abstractions avec les propriétés indiquées est les graphes de programme et leur version la plus simple - une liste chaînée.
Je rappellerai à nos lecteurs le principe de fonctionnement de la linked list (Fig. 1). Les objets de la classe de base contiennent un pointeur vers le même objet que l'un des membres, ce qui permet de les combiner dans des structures linéaires, sans tenir compte de l'ordre physique des objets en mémoire. De plus, il existe la classe "carriage", qui encapsule la procédure de déplacement à travers la liste, l'ajout, l'insertion et la suppression de nœuds, la recherche, la comparaison et le tri, et, si nécessaire, d'autres procédures.
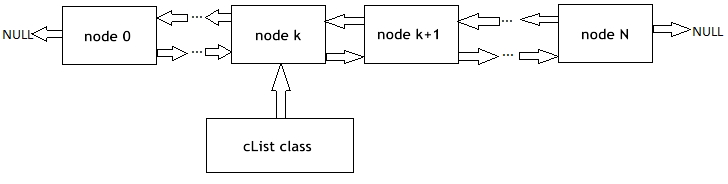
Figure 1. Représentation schématique de l'organisation des listes enchaînées linéaires
Les spécialistes de MetaQuotes Software Corp. ont déjà implémenté des listes chaînées des objets de la classe CObject dans une bibliothèque standard. Le code de programme correspondant se trouve dans le fichier d'en-tête List.mqh, qui se trouve dans MQL5\Include\Arrays du pack de livraison standard de MetaTrader 5.
Nous ne réinventerons pas la roue et ferons confiance à la qualification des programmeurs respectés de MetaQuotes, prenant les classes CObject et CList comme base de nos structures de données. Ici, nous utiliserons l'un des piliers de l'approche orientée objet – le mécanisme d'héritage.
3. Programmation du modèle
Définissons d'abord la forme logicielle du concept de artificial neuron".
L'une des règles d'étiquette lors de l’élaboration d'applications POO est de toujours commencer à programmer avec les structures de données les plus courantes. Même lorsque vous écrivez uniquement pour vous-même, mais surtout si l'on suppose que les codes seront disponibles pour d'autres programmeurs, vous devez garder à l'esprit le fait qu'à l'avenir les développeurs peuvent avoir des idées différentes pour l’élaboration la modification du programme logique; et vous ne pouvez pas savoir à l'avance à quel endroit les modifications seront apportées.
Le principe de la POO implique que les autres développeurs ne devront pas examiner vos classes, au contraire qu'ils devraient pouvoir hériter des structures de données à partir des données disponibles au bon endroit de la hiérarchie. Ainsi, la première classe écrite doit être aussi abstraite que possible, et les caractéristiques doivent être ajoutées aux niveaux inférieurs, lorsqu'on est plus proche « de la terre pécheresse ».
Appliqué à notre problème, cela indique que nous commençons à écrire un programme avec la définition de la classe CCustomNeuron ("une sorte de neurone"), qui, comme tous les neurones artificiels, aura un certain nombre de synapses (poids d'entrée) et la valeur de sortie Il pourra s'initialiser (attribuer des valeurs aux poids), calculer la valeur du signal à sa sortie, et même adapter ses poids d'une valeur déterminée.
Nous pouvons à peine atteindre plus d'abstraction (compte tenu du fait que nous héritons notre classe d'un CObject généralisé au maximum) - tous les neurones doivent être en mesure d'effectuer les actions déterminées.
Pour décrire les données, créez un fichier d'en-tête Neurons.mqh, en le plaçant dans le dossier Include\GNG.
//+------------------------------------------------------------------+ //| a base class to introduce object-neurons | //+------------------------------------------------------------------+ class CCustomNeuron:public CObject { protected: int m_synapses; double m_weights[]; public: double NET; CCustomNeuron(); ~CCustomNeuron(){}; void ZeroInit(int synapses); int Synapses(); void Init(double &weights[]); void Weights(double &weights[]); void AdaptWeights(double &delta[]); virtual void ProcessVector(double &in[]) {return;} virtual int Type() const { return(TYPE_CUSTOM_NEURON);} }; //+------------------------------------------------------------------+ //| constructor | //+------------------------------------------------------------------+ void CCustomNeuron::CCustomNeuron() { m_synapses=0; NET=0; } //+------------------------------------------------------------------+ //| returns the dimension of the input vector of a neuron | //| INPUT: no | //| OUTPUT: number of "synapses" of the neuron | //+------------------------------------------------------------------+ int CCustomNeuron::Synapses() { return m_synapses; } //+------------------------------------------------------------------+ //| initializing neuron with a zero vector of weights. | //| INPUT: synapses - number of synapses (input weights) | //| OUTPUT: no | //+------------------------------------------------------------------+ void CCustomNeuron::ZeroInit(int synapses) { if(synapses<1) return; m_synapses=synapses; ArrayResize(m_weights,m_synapses); ArrayInitialize(m_weights,0); NET=0; } //+------------------------------------------------------------------+ //| initializing neuron weights with a set vector. | //| INPUT: weights - data vector | //| OUTPUT: no | //+------------------------------------------------------------------+ void CCustomNeuron::Init(double &weights[]) { if(ArraySize(weights)<1) return; m_synapses=ArraySize(weights); ArrayResize(m_weights,m_synapses); ArrayCopy(m_weights,weights); NET=0; } //+------------------------------------------------------------------+ //| obtaining vector of neuron weights. | //| INPUT: no | //| OUTPUT: weights - result | //+------------------------------------------------------------------+ void CCustomNeuron::Weights(double &weights[]) { ArrayResize(weights,m_synapses); ArrayCopy(weights,m_weights); } //+------------------------------------------------------------------+ //| change weights of the neuron by a specified value | //| INPUT: delta - correcting vector | //| OUTPUT: no | //+------------------------------------------------------------------+ void CCustomNeuron::AdaptWeights(double &delta[]) { if(ArraySize(delta)!=m_synapses) return; for(int i=0;i<m_synapses;i++) m_weights[i]+=delta[i]; NET=0; }
Les fonctions définies dans la classe sont très simples, il n'est donc pas nécessaire d'inclure leurs descriptions détaillées ici. Notez que nous avons défini la fonction de traitement des données d'entrée ProcessVector(double &in[]) (la valeur de sortie est ici calculée comme celle d'un perceptron ordinaire) avec le modificateur virtual.
Cela indique que dans le cas où la méthode est redéfinie par des classes dérivées, la procédure appropriée sera choisie en fonction de la classe d'objets réelle de manière dynamique au moment de l'exécution, ce qui augmente sa flexibilité, y compris celle dans le sens de l'interaction avec l'utilisateur, et réduit les coûts de main-d'œuvre pour la programmation.
Malgré le fait qu'apparemment nous n'avons rien fait pour organiser les neurones dans une liste chaînée, en fait cela s'est déjà produit au moment où nous avons souligné que la nouvelle classe hérite de CObject. Ainsi, les membres privés de notre classe sont maintenant m_first_node, m_curr_node et m_last_node, qui sont du type "pointer at CObject" et pointent, respectivement, sur le premier, l’actuel et le dernier élément de la liste. Nous avons également toutes les fonctions nécessaires pour naviguer dans la liste.
Il est maintenant temps de souligner les différences d'un neurone de la couche GNG par rapport à ses autres homologues en définissant la classe CGNGNeuron :
//+------------------------------------------------------------------+ //| a separate neuron of the GNG network | //+------------------------------------------------------------------+ class CGNGNeuron:public CCustomNeuron { public: int uid; double E; double U; double error; CGNGNeuron(); virtual void ProcessVector(double &in[]); }; //+------------------------------------------------------------------+ //| constructor | //+------------------------------------------------------------------+ CGNGNeuron::CGNGNeuron() { E=0; U=0; error=0; } //+------------------------------------------------------------------+ //| calculating "distance" from the neuron to the input vector | //| INPUT: in - data vector | //| OUTPUT: no | //| REMARK: the current "distance" is placed in the error variable, | //| "local error" is contained in another variable, | //| which is called E | //+------------------------------------------------------------------+ void CGNGNeuron::ProcessVector(double &in[]) { if(ArraySize(in)!=m_synapses) return; error=0; NET=0; for(int i=0;i<m_synapses;i++) { error+=(in[i]-m_weights[i])*(in[i]-m_weights[i]); } }
Donc, comme vous pouvez le constater, ces différences sont en présence de champs :
- erreur - le carré actuel de la distance entre le vecteur d'entrée et le vecteur de poids des neurones,
- E – une variable qui accumule l'erreur locale et un identifiant unique,
- uid - il est nécessaire pour nous permettre de joindre davantage les neurones par des connexions paires (la simple indexation existant dans la classe CList n'est pas suffisante, car nous devrons ajouter et supprimer des neurones, ce qui entraînera une confusion dans la numérotation).
La fonction ProcessVector(...) a changé - maintenant elle calcule la valeur du champ d'erreur.
Ne faites pas attention au champ U pour l'instant, sa signification sera expliquée plus loin dans la section "Modification de l'algorithme".
L'étape suivante consiste à écrire une classe qui représente une connexion entre deux neurones.
//+------------------------------------------------------------------+ //| class defining connection (edge) between two neurons | //+------------------------------------------------------------------+ class CGNGConnection:public CObject { public: int uid1; int uid2; int age; CGNGConnection(); virtual int Type() const { return(TYPE_GNG_CONNECTION);} }; //+------------------------------------------------------------------+ //| constructor | //+------------------------------------------------------------------+ CGNGConnection::CGNGConnection() { age=0; }
Il n'y a rien de difficile ici – un bord a deux extrémités (neurones spécifiés par les identifiants uid1 et uid2) et un âge initialement égal à zéro.
Nous allons maintenant travailler avec des classes "carriages" de listes chaînées, qui comportent des possibilités nécessaires à l'implémentation de l'algorithme GNG.
Tout d'abord, héritez d'une classe de liste de neurones de CList :
//+------------------------------------------------------------------+ //| linked list of neurons | //+------------------------------------------------------------------+ class CGNGNeuronList:public CList { public: //--- constructor CGNGNeuronList() {MathSrand(TimeLocal());} CGNGNeuron *Append(); void Init(double &v1[],double &v2[]); CGNGNeuron *Find(int uid); void FindWinners(CGNGNeuron *&Winner,CGNGNeuron *&SecondWinner); }; //+------------------------------------------------------------------+ //| adds an "empty" neuron at the end of the list | //| INPUT: no | //| OUTPUT: pointer at a new neuron | //+------------------------------------------------------------------+ CGNGNeuron *CGNGNeuronList::Append() { if(m_first_node==NULL) { m_first_node= new CGNGNeuron; m_last_node = m_first_node; } else { GetLastNode(); m_last_node=new CGNGNeuron; m_curr_node.Next(m_last_node); m_last_node.Prev(m_curr_node); } m_curr_node=m_last_node; m_curr_idx=m_data_total++; while(true) { int rnd=MathRand(); if(!CheckPointer(Find(rnd))) { ((CGNGNeuron *)m_curr_node).uid=rnd; break; } } //--- return(m_curr_node); } //+------------------------------------------------------------------+ //| initializing list by way of creating two neurons set | //| by vectors of weights | //| INPUT: v1,v2 - vectors of weights | //| OUTPUT: no | //+------------------------------------------------------------------+ void CGNGNeuronList::Init(double &v1[],double &v2[]) { Clear(); Append(); ((CGNGNeuron *)m_curr_node).Init(v1); Append(); ((CGNGNeuron *)m_curr_node).Init(v2); } //+------------------------------------------------------------------+ //| search for a neuron by uid | //| INPUT: uid - a unique ID of the neuron | //| OUTPUT: pointer at the neuron if successful, otherwise NULL | //+------------------------------------------------------------------+ CGNGNeuron *CGNGNeuronList::Find(int uid) { if(!GetFirstNode()) return(NULL); do { if(((CGNGNeuron *)m_curr_node).uid==uid) return(m_curr_node); } while(CheckPointer(GetNextNode())); return(NULL); } //+------------------------------------------------------------------+ //| search for two "best" neurons in terms of minimal current error | //| INPUT: no | //| OUTPUT: Winner - neuron "closest" to the input vector | //| SecondWinner - second "closest" neuron | //+------------------------------------------------------------------+ void CGNGNeuronList::FindWinners(CGNGNeuron *&Winner,CGNGNeuron *&SecondWinner) { double err_min=0; Winner=NULL; if(!CheckPointer(GetFirstNode())) return; do { if(!CheckPointer(Winner) || ((CGNGNeuron *)m_curr_node).error<err_min) { err_min= ((CGNGNeuron *)m_curr_node).error; Winner = m_curr_node; } } while(CheckPointer(GetNextNode())); err_min=0; SecondWinner=NULL; GetFirstNode(); do { if(m_curr_node!=Winner) if(!CheckPointer(SecondWinner) || ((CGNGNeuron *)m_curr_node).error<err_min) { err_min=((CGNGNeuron *)m_curr_node).error; SecondWinner=m_curr_node; } } while(CheckPointer(GetNextNode())); m_curr_node=Winner; }
Dans le constructor de classe un générateur de nombres pseudo-aléatoires est initialisé : il sera utilisé pour attribuer des identifiants uniques aux éléments de la liste.
Expliquons la signification des méthodes de classe :
- La méthode Append() est un ajout aux fonctionnalités de la classe CList. Lors de l'appel, un nœud est ajouté à la fin de la liste, ou le premier nœud est créé si la luxure est vide.
- La fonction Init(double &v1[],double &v2[]) doit son apparition à l'algorithme GNG. Rappelez-vous que la croissance du réseau commence avec deux neurones, donc cette signature nous conviendrait le mieux. Dans le corps de la fonction, lors de l'utilisation des ID m_curr_node, m_first_node, m_last_node, il est nécessaire de convertir explicitement puis taper CGNGNeuron*, si nous souhaitons utiliser la fonctionnalité de cette classe (les variables déterminées ont été héritées de CList, donc en principe elles pointent vers CObject ).
- La fonction Find(int uid), comme son nom l’indique, recherche un neurone par son ID et renvoie un pointeur sur l'élément trouvé ou NULL s'il ne le trouve pas.
- FindWinners(CGNGNeuron *&Winner, CGNGNeuron *&SecondWinner) – fait également partie de l'algorithme. Nous devrons rechercher un gagnant dans la liste des neurones, et celui à côté en termes de proximité avec le vecteur d'entrée, c'est pour cela que nous utilisons cette fonction. Notez que les paramètres sont passés à cette fonction par référence afin que nous puissions y écrire les valeurs renvoyées (*& indique "référence à un pointeur" - c'est une syntaxe correcte, l'inverse &* indique "pointeur sur une référence" qui est interdit : le compilateur générera une erreur dans ce cas).
La classe suivante est une liste de connexions entre les neurones.
//+------------------------------------------------------------------+ //| a linked list of connections between neurons | //+------------------------------------------------------------------+ class CGNGConnectionList:public CList { public: CGNGConnection *Append(); void Init(int uid1,int uid2); CGNGConnection *Find(int uid1,int uid2); CGNGConnection *FindFirstConnection(int uid); CGNGConnection *FindNextConnection(int uid); }; //+------------------------------------------------------------------+ //| adds an "empty" connection at the end of the list | //| INPUT: no | //| OUTPUT: pointer at a new binding | //+------------------------------------------------------------------+ CGNGConnection *CGNGConnectionList::Append() { if(m_first_node==NULL) { m_first_node= new CGNGConnection; m_last_node = m_first_node; } else { GetLastNode(); m_last_node=new CGNGConnection; m_curr_node.Next(m_last_node); m_last_node.Prev(m_curr_node); } m_curr_node=m_last_node; m_curr_idx=m_data_total++; //--- return(m_curr_node); } //+------------------------------------------------------------------+ //| initialize the list by creating one connection | //| INPUT: uid1,uid2 - IDs of neurons for the connection | //| OUTPUT: no | //+------------------------------------------------------------------+ void CGNGConnectionList::Init(int uid1,int uid2) { Append(); ((CGNGConnection *)m_first_node).uid1 = uid1; ((CGNGConnection *)m_first_node).uid2 = uid2; m_last_node = m_first_node; m_curr_node = m_first_node; m_curr_idx=0; } //+------------------------------------------------------------------+ //| check if there is connection between the set neurons | //| INPUT: uid1,uid2 - IDs of the neurons | //| OUTPUT: pointer at the connection if there is one, or NULL | //+------------------------------------------------------------------+ CGNGConnection *CGNGConnectionList::Find(int uid1,int uid2) { if(!CheckPointer(GetFirstNode())) return(NULL); do { if((((CGNGConnection *)m_curr_node).uid1==uid1 && ((CGNGConnection *)m_curr_node).uid2==uid2) ||(((CGNGConnection *)m_curr_node).uid1==uid2 && ((CGNGConnection *)m_curr_node).uid2==uid1)) return(m_curr_node); } while(CheckPointer(GetNextNode())); return(NULL); } //+------------------------------------------------------------------+ //| search for the first topological neighbor of the set neuron | //| starting with the first element of the list | //| INPUT: uid - ID of the neuron | //| OUTPUT: pointer at the connection if there is one, or NULL | //+------------------------------------------------------------------+ CGNGConnection *CGNGConnectionList::FindFirstConnection(int uid) { if(!CheckPointer(GetFirstNode())) return(NULL); while(true) { if(((CGNGConnection *)m_curr_node).uid1==uid || ((CGNGConnection *)m_curr_node).uid2==uid) break; if(!CheckPointer(GetNextNode())) return(NULL); } return(m_curr_node); } //+------------------------------------------------------------------+ //| search for the first topological neighbor of the set neuron | //| starting with the list element next to the current one | //| INPUT: uid - ID of the neuron | //| OUTPUT: pointer at the connection if there is one, or NULL | //+------------------------------------------------------------------+ CGNGConnection *CGNGConnectionList::FindNextConnection(int uid) { if(!CheckPointer(GetCurrentNode())) return(NULL); while(true) { if(!CheckPointer(GetNextNode())) return(NULL); if(((CGNGConnection *)m_curr_node).uid1==uid || ((CGNGConnection *)m_curr_node).uid2==uid) break; } return(m_curr_node); }
Méthodes définies de la classe :
- Append(). L'implémentation de cette méthode est similaire à celle décrite dans la classe précédente, à l'exception du type de retour (malheureusement, il n'y a pas de modèles de classe dans MQL5, nous devons donc écrire ces choses à chaque fois).
- Init(int uid1,int uid2) - l'algorithme GNG nécessite l'initialisation d'une connexion à son début, qui est effectuée dans cette fonction.
- La fonction Find(int uid1,int uid2) est claire.
- La différence entre les méthodes FindFirstConnection(int uid) et FindNextConnection(int uid) est que la première recherche une connexion avec un voisin à partir du début de la liste, tandis que la seconde commence par le nœud à côté de l'actuel (m_curr_node ).
Ici, la description des structures de données est terminée. Il est temps d’entamer la programmation de notre propre algorithme.
4. La Classe de l'Algorithme
Créez un nouveau fichier d'en-tête GNG.mqh, placez-le dans le dossier Include\GNG.
//+------------------------------------------------------------------+ //| GNG.mqh | //| Copyright 2010, alsu | //| alsufx@gmail.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2010, alsu" #property link "alsufx@gmail.com" #include "Neurons.mqh" //+------------------------------------------------------------------+ //| the main class representing the GNG algorithm | //+------------------------------------------------------------------+ class CGNGAlgorithm { public: //--- linked lists of object-neurons and connection between them CGNGNeuronList *Neurons; CGNGConnectionList *Connections; //--- parameters of the algorithm int input_dimension; int iteration_number; int lambda; int age_max; double alpha; double beta; double eps_w; double eps_n; int max_nodes; CGNGAlgorithm(); ~CGNGAlgorithm(); virtual void Init(int __input_dimension, double &v1[], double &v2[], int __lambda, int __age_max, double __alpha, double __beta, double __eps_w, double __eps_n, int __max_nodes); virtual bool ProcessVector(double &in[],bool train=true); virtual bool StoppingCriterion(); }; //+------------------------------------------------------------------+ //| constructor | //+------------------------------------------------------------------+ CGNGAlgorithm::CGNGAlgorithm(void) { Neurons=new CGNGNeuronList(); Connections=new CGNGConnectionList(); Neurons.FreeMode(true); Connections.FreeMode(true); } //+------------------------------------------------------------------+ //| destructor | //+------------------------------------------------------------------+ CGNGAlgorithm::~CGNGAlgorithm(void) { delete Neurons; delete Connections; } //+------------------------------------------------------------------+ //| initializes the algorithm using two vectors of input data | //| INPUT: v1,v2 - input vectors | //| __lambda - number of iterations after which a new | //| neuron is inserted | //| __age_max - maximum age of connection | //| __alpha, __beta - used for adapting errors | //| __eps_w, __eps_n - used for adapting weights | //| __max_nodes - limit on the network size | //| OUTPUT: no | //+------------------------------------------------------------------+ void CGNGAlgorithm::Init(int __input_dimension, double &v1[], double &v2[], int __lambda, int __age_max, double __alpha, double __beta, double __eps_w, double __eps_n, int __max_nodes) { iteration_number=0; input_dimension=__input_dimension; lambda=__lambda; age_max=__age_max; alpha= __alpha; beta = __beta; eps_w = __eps_w; eps_n = __eps_n; max_nodes=__max_nodes; Neurons.Init(v1,v2); CGNGNeuron *tmp; tmp=Neurons.GetFirstNode(); int uid1=tmp.uid; tmp=Neurons.GetLastNode(); int uid2=tmp.uid; Connections.Init(uid1,uid2); } //+------------------------------------------------------------------+ //| the main function of the algorithm | //| INPUT: in - vector of input data | //| train - if true, start learning, otherwise | //| only calculate the input values of neurons | //| OUTPUT: true, if stop condition is fulfilled, otherwise false | //+------------------------------------------------------------------+ bool CGNGAlgorithm::ProcessVector(double &in[],bool train=true) { if(ArraySize(in)!=input_dimension) return(StoppingCriterion()); int i; CGNGNeuron *tmp=Neurons.GetFirstNode(); while(CheckPointer(tmp)) { tmp.ProcessVector(in); tmp=Neurons.GetNextNode(); } if(!train) return(false); iteration_number++; //--- Find two neurons closest to in[], i.e. the nodes with weight vectors //--- Ws and Wt, so that ||Ws-in||^2 is minimal and ||Wt-in||^2 - //--- is second minimal value of distance of all the nodes. //--- Under ||*|| we mean Euclidean norm CGNGNeuron *Winner,*SecondWinner; Neurons.FindWinners(Winner,SecondWinner); //--- Update the local error of the winner Winner.E+=Winner.error; //--- Shift the winner and all its topological neighbors (i.e. //--- all neurons connected with the winner) in the direction of the input //--- vector by distances equal to fractions eps_w and eps_n of the full. double delta[],weights[]; Winner.Weights(weights); ArrayResize(delta,input_dimension); for(i=0;i<input_dimension;i++) delta[i]=eps_w*(in[i]-weights[i]); Winner.AdaptWeights(delta); //--- Increment the age of all connections emanating from the winner by 1. CGNGConnection *tmpc=Connections.FindFirstConnection(Winner.uid); while(CheckPointer(tmpc)) { if(tmpc.uid1==Winner.uid) tmp = Neurons.Find(tmpc.uid2); if(tmpc.uid2==Winner.uid) tmp = Neurons.Find(tmpc.uid1); tmp.Weights(weights); for(i=0;i<input_dimension;i++) delta[i]=eps_n*(in[i]-weights[i]); tmp.AdaptWeights(delta); tmpc.age++; tmpc=Connections.FindNextConnection(Winner.uid); } //--- If two best neurons are connected, reset the age of the connection. //--- Otherwise create a connection between them. tmpc=Connections.Find(Winner.uid,SecondWinner.uid); if(tmpc) tmpc.age=0; else { Connections.Append(); tmpc=Connections.GetLastNode(); tmpc.uid1 = Winner.uid; tmpc.uid2 = SecondWinner.uid; tmpc.age=0; } //--- Delete all the connections with an age larger than age_max. //--- If this results in neurons having no connections with other //--- nodes, remove those neurons. tmpc=Connections.GetFirstNode(); while(CheckPointer(tmpc)) { if(tmpc.age>age_max) { Connections.DeleteCurrent(); tmpc=Connections.GetCurrentNode(); } else tmpc=Connections.GetNextNode(); } tmp=Neurons.GetFirstNode(); while(CheckPointer(tmp)) { if(!Connections.FindFirstConnection(tmp.uid)) { Neurons.DeleteCurrent(); tmp=Neurons.GetCurrentNode(); } else tmp=Neurons.GetNextNode(); } //--- If the number of the current iteration is multiple of lambda, and the network //--- hasn't been reached yet, create a new neuron r according to the following rules CGNGNeuron *u,*v; if(iteration_number%lambda==0 && Neurons.Total()<max_nodes) { //--- 1.Find neuron u with the maximum local error. tmp=Neurons.GetFirstNode(); u=tmp; while(CheckPointer(tmp=Neurons.GetNextNode())) { if(tmp.E>u.E) u=tmp; } //--- 2.determin among the neighbors of u the node u with the maximum local error. tmpc=Connections.FindFirstConnection(u.uid); if(tmpc.uid1==u.uid) v=Neurons.Find(tmpc.uid2); else v=Neurons.Find(tmpc.uid1); while(CheckPointer(tmpc=Connections.FindNextConnection(u.uid))) { if(tmpc.uid1==u.uid) tmp=Neurons.Find(tmpc.uid2); else tmp=Neurons.Find(tmpc.uid1); if(tmp.E>v.E) v=tmp; } //--- 3.Create a node r "in the middle" between u and v. double wr[],wu[],wv[]; u.Weights(wu); v.Weights(wv); ArrayResize(wr,input_dimension); for(i=0;i<input_dimension;i++) wr[i]=(wu[i]+wv[i])/2; CGNGNeuron *r=Neurons.Append(); r.Init(wr); //--- 4.Replace the connection between u and v by a connection between u and r, v and r tmpc=Connections.Append(); tmpc.uid1=u.uid; tmpc.uid2=r.uid; tmpc=Connections.Append(); tmpc.uid1=v.uid; tmpc.uid2=r.uid; Connections.Find(u.uid,v.uid); Connections.DeleteCurrent(); //--- 5.Decrease the errors of neurons u and v, set the value of the error of //--- neuron r the same as of u. u.E*=alpha; v.E*=alpha; r.E = u.E; } //--- Decrease the errors of all neurons by the fraction beta tmp=Neurons.GetFirstNode(); while(CheckPointer(tmp)) { tmp.E*=(1-beta); tmp=Neurons.GetNextNode(); } //--- Check the stopping criterion return(StoppingCriterion()); } //+------------------------------------------------------------------+ //| Stopping criterion. In this version of file makes no | //| actions, always returns false. | //| INPUT: no | //| OUTPUT: true, if the criterion is fulfilled, otherwise false | //+------------------------------------------------------------------+ bool CGNGAlgorithm::StoppingCriterion() { return(false); }
La classe CGNGAlgorithm dispose deux champs importants - les pointeurs sur les listes chaînées de neurones Neurones et les connexions entre eux. Connexions. Ils seront le support physique de la structure de notre réseau de neurones. Les champs restants sont les paramètres de l'algorithme définis de l'extérieur.
Parmi les méthodes de classe auxiliaire, je distinguerais Init(...) qui passe les paramètres externes à une instance de l'algorithme et initialise les structures de données et le critère d'arrêt StoppingCriterion() qui, comme nous l'avons convenu précédemment, ne fait rien en retournant toujours faux.
La fonction ProcessVector(…) qui est la fonction principale de l'algorithme qui traite le vecteur de données indiqué, ne contient aucune subtilité : nous avons organisé les données et les méthodes de travail avec celles-ci de manière à ce qu'en ce qui concerne l'algorithme, nous devons seulement passer mécaniquement par toutes ses étapes. Leur emplacement dans le code est indiqué par les commentaires appropriés.
5. Utilisation au travail
Montrons le travail de l'algorithme sur des données réelles du terminal /MetaTrader 5.
Ici, nous ne visons pas la création d’ un Expert Advisor fonctionnel basé sur GNG (c'est un peu trop pour un article), nous souhaitons seulement voir comment fonctionne le gaz neuronal croissant , ce qu'on appelle une présentation "en direct".
Afin de rendre magnifiquement les données, créez une fenêtre vide échelonnée le long de l'axe des prix dans la fourchette de 0 à 100. Pour cela, nous utilisons un indicateur "vide" Dummy.mq5 (il n'a pas d'autres fonctions) :
//+------------------------------------------------------------------+ //| Dummy.mq5 | //| Copyright 2010, alsu | //| alsufx@gmail.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2010, alsu" #property link "alsufx@gmail.com" #property version "1.00" #property indicator_separate_window #property indicator_minimum 0 #property indicator_maximum 100 #property indicator_buffers 1 #property indicator_plots 1 //--- plot Label1 #property indicator_type1 DRAW_LINE #property indicator_style1 STYLE_SOLID #property indicator_width1 1 //--- indicator buffers double DummyBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- indicator buffers mapping SetIndexBuffer(0,DummyBuffer,INDICATOR_DATA); IndicatorSetString(INDICATOR_SHORTNAME,"GNG_dummy"); //--- return(0); } //+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime& time[], const double& open[], const double& high[], const double& low[], const double& close[], const long& tick_volume[], const long& volume[], const int& spread[]) { //--- an empty buffer ArrayInitialize(DummyBuffer,EMPTY_VALUE); //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
Dans le MetaEditor, créez un script appelé GNG.mq5 - il affichera le réseau dans la fenêtre de l'indicateur fictif.
Paramètres externes - le nombre de vecteurs de données pour l'apprentissage et les paramètres de l'algorithme :
//--- the number of input vectors used for learning input int samples=1000; //--- parameters of the algorithm input int lambda=20; input int age_max=15; input double alpha=0.5; input double beta=0.0005; input double eps_w=0.05; input double eps_n=0.0006; input int max_nodes=100;
Déclarez des variables globales :
//---global variables CGNGAlgorithm *GNGAlgorithm; int window; int rsi_handle; int input_dimension; int _samples; double RSI_buffer[]; datetime time[];
Commencez à écrire la fonction OnStart(). Tout d'abord, trouvons la fenêtre nécessaire :
void OnStart() { int i,j; int window=ChartWindowFind(0,"GNG_dummy");
Pour les données d'entrée, nous utilisons les valeurs de l'indicateur RSI - c'est pratique car ses valeurs sont normalisées dans la fourchette de 0 à 100, nous n'aurons donc pas besoin de procéder à un prétraitement.
Pour un vecteur d'entrée du réseau de neurones, nous supposons la paire (input_dimension=2) qui se compose de deux valeurs RSI - sur la barre actuelle et précédente (dont le nom scientifique est "immersion d'une série temporelle dans un espace de caractéristiques bidimensionnel") . Il est plus facile d'afficher des vecteurs à deux dimensions sur un organigramme.
Donc, préparez d'abord les données à initialiser et créez une instance de l'objet algorithme :
//--- to have CopyBuffer() work correctly, the number of the vectors //--- must be within the number of bars with a reserve left for the vector length _samples=samples+input_dimension+10; if(_samples>Bars(_Symbol,_Period)) _samples=Bars(_Symbol,_Period); //--- receive input data for the algorithm rsi_handle=iRSI(NULL,0,8,PRICE_CLOSE); CopyBuffer(rsi_handle,0,1,_samples,RSI_buffer); //--- return the user-defined value _samples=_samples-input_dimension-10; //--- remember open time of the first 100 bars CopyTime(_Symbol,_Period,0,100,time); //--- create an instance of the algorithm and set the size of input data GNGAlgorithm=new CGNGAlgorithm; input_dimension=2; //--- data vectors double v[],v1[],v2[]; ArrayResize(v,input_dimension); ArrayResize(v1,input_dimension); ArrayResize(v2,input_dimension); for(i=0;i<input_dimension;i++) { v1[i] = RSI_buffer[i]; v2[i] = RSI_buffer[i+3]; }
Initialisez maintenant l'algorithme :
//--- initialization
GNGAlgorithm.Init(input_dimension,v1,v2,lambda,age_max,alpha,beta,eps_w,eps_n,max_nodes); Dessinez une boîte rectangulaire et des étiquettes d'information (pour voir visuellement combien d'itérations de l'algorithme ont été traitées et combien de neurones ont « poussé » dans le réseau) :
//-- draw a rectangular box and information labels ObjectCreate(0,"GNG_rect",OBJ_RECTANGLE,window,time[0],0,time[99],100); ObjectSetInteger(0,"GNG_rect",OBJPROP_BACK,true); ObjectSetInteger(0,"GNG_rect",OBJPROP_COLOR,DarkGray); ObjectSetInteger(0,"GNG_rect",OBJPROP_BGCOLOR,DarkGray); ObjectCreate(0,"Label_samples",OBJ_LABEL,window,0,0); ObjectSetInteger(0,"Label_samples",OBJPROP_ANCHOR,ANCHOR_RIGHT_UPPER); ObjectSetInteger(0,"Label_samples",OBJPROP_CORNER,CORNER_RIGHT_UPPER); ObjectSetInteger(0,"Label_samples",OBJPROP_XDISTANCE,10); ObjectSetInteger(0,"Label_samples",OBJPROP_YDISTANCE,10); ObjectSetInteger(0,"Label_samples",OBJPROP_COLOR,Red); ObjectSetString(0,"Label_samples",OBJPROP_TEXT,"Total samples: 2"); ObjectCreate(0,"Label_neurons",OBJ_LABEL,window,0,0); ObjectSetInteger(0,"Label_neurons",OBJPROP_ANCHOR,ANCHOR_RIGHT_UPPER); ObjectSetInteger(0,"Label_neurons",OBJPROP_CORNER,CORNER_RIGHT_UPPER); ObjectSetInteger(0,"Label_neurons",OBJPROP_XDISTANCE,10); ObjectSetInteger(0,"Label_neurons",OBJPROP_YDISTANCE,25); ObjectSetInteger(0,"Label_neurons",OBJPROP_COLOR,Red); ObjectSetString(0,"Label_neurons",OBJPROP_TEXT,"Total neurons: 2");
Dans la boucle principale, préparez un vecteur pour l'entrée de l'algorithme, affichez-le sur le graphique sous la forme d'un point bleu :
//--- start the main loop of the algorithm with i=2 because 2 were used already for(i=2;i<_samples;i++) { //--- fill out the data vector (for clarity, get samples separated //--- by 3 bars - they are less correlated) for(j=0;j<input_dimension;j++) v[j]=RSI_buffer[i+j*3]; //--- show the vector on the chart ObjectCreate(0,"Sample_"+i,OBJ_ARROW,window,time[v[0]],v[1]); ObjectSetInteger(0,"Sample_"+i,OBJPROP_ARROWCODE,158); ObjectSetInteger(0,"Sample_"+i,OBJPROP_COLOR,Blue); ObjectSetInteger(0,"Sample_"+i,OBJPROP_BACK,true); //--- change the information label ObjectSetString(0,"Label_samples",OBJPROP_TEXT,"Total samples: "+string(i+1));
Passez le vecteur à l'algorithme (une seule fonction - c'est l'avantage de l'approche orientée-objet !) :
//--- pass the input vector to the algorithm for calculation
GNGAlgorithm.ProcessVector(v); Retirez les anciens neurones du tableau et dessinez-en de nouveaux (cercles rouges) et des connexions (lignes pointillées jaunes), mettez en surbrillance le gagnant et le deuxième meilleur neurone avec les couleurs Jaune/vert et Vert :
//--- we need to remove old neurons an connections from the chart to draw new ones then for(j=ObjectsTotal(0)-1;j>=0;j--) { string name=ObjectName(0,j); if(StringFind(name,"Neuron_")>=0) { ObjectDelete(0,name); } else if(StringFind(name,"Connection_")>=0) { ObjectDelete(0,name); } }
double weights[]; CGNGNeuron *tmp,*W1,*W2; CGNGConnection *tmpc; GNGAlgorithm.Neurons.FindWinners(W1,W2); //--- drawing the neurons tmp=GNGAlgorithm.Neurons.GetFirstNode(); while(CheckPointer(tmp)) { tmp.Weights(weights); ObjectCreate(0,"Neuron_"+tmp.uid,OBJ_ARROW,window,time[weights[0]],weights[1]); ObjectSetInteger(0,"Neuron_"+tmp.uid,OBJPROP_ARROWCODE,159); //--- the winner is colored Lime, second best - Green, others - Red if(tmp==W1) ObjectSetInteger(0,"Neuron_"+tmp.uid,OBJPROP_COLOR,Lime); else if(tmp==W2) ObjectSetInteger(0,"Neuron_"+tmp.uid,OBJPROP_COLOR,Green); else ObjectSetInteger(0,"Neuron_"+tmp.uid,OBJPROP_COLOR,Red); ObjectSetInteger(0,"Neuron_"+tmp.uid,OBJPROP_BACK,false); tmp=GNGAlgorithm.Neurons.GetNextNode(); } ObjectSetString(0,"Label_neurons",OBJPROP_TEXT,"Total neurons: "+string(GNGAlgorithm.Neurons.Total())); //--- drawing connections tmpc=GNGAlgorithm.Connections.GetFirstNode(); while(CheckPointer(tmpc)) { int x1,x2,y1,y2; tmp=GNGAlgorithm.Neurons.Find(tmpc.uid1); tmp.Weights(weights); x1=weights[0];y1=weights[1]; tmp=GNGAlgorithm.Neurons.Find(tmpc.uid2); tmp.Weights(weights); x2=weights[0];y2=weights[1]; ObjectCreate(0,"Connection_"+tmpc.uid1+"_"+tmpc.uid2,OBJ_TREND,window,time[x1],y1,time[x2],y2); ObjectSetInteger(0,"Connection_"+tmpc.uid1+"_"+tmpc.uid2,OBJPROP_WIDTH,1); ObjectSetInteger(0,"Connection_"+tmpc.uid1+"_"+tmpc.uid2,OBJPROP_STYLE,STYLE_DOT); ObjectSetInteger(0,"Connection_"+tmpc.uid1+"_"+tmpc.uid2,OBJPROP_COLOR,Yellow); ObjectSetInteger(0,"Connection_"+tmpc.uid1+"_"+tmpc.uid2,OBJPROP_BACK,false); tmpc=GNGAlgorithm.Connections.GetNextNode(); } ChartRedraw(); } //--- delete the instance of the algorithm from the memory delete GNGAlgorithm; //--- a pause before clearing the chart while(!IsStopped()); //--- remove all the drawings from the chart ObjectsDeleteAll(0,window); }
Compilez le code, démarrez l'indicateur fictif, puis exécutez le script GNG sur le même graphique. Une image comme celle-ci doit apparaître sur le graphique :
Vous voyez, l'algorithme fonctionne vraiment : la grille s'adapte progressivement aux nouvelles données entrantes en essayant de couvrir leur espace conformément à la densité de peuplement des points bleus.
La vidéo ne montre que le tout début du processus d'apprentissage (seulement 1000 itérations, alors que le nombre réel de vecteurs requis pour l'apprentissage de GNG peut aller jusqu'à des dizaines de milliers) ; Cependant, cela nous donne déjà une assez bonne compréhension du processus.
6. Problèmes connus
Comme indiqué précédemment, le problème principal de GNG est son incapacité à suivre des séries mobiles avec des caractéristiques en perpétuelle mutation. De telles distributions "sautantes" de signaux d'entrée peuvent conduire à ce qu'une grande partie des neurones de la couche GNG, ayant déjà pris une structure assez topologique, se retrouvent soudainement en faillite.
De plus, puisque les signaux d'entrée ne tombent pas dans la région de leur emplacement, l'âge des connexions entre ces neurones n'est pas augmenté, par conséquent, la partie "morte" du réseau, qui "se rappelle" des anciennes caractéristiques du signal, n’assure pas un travail utile, mais consomme seulement des ressources informatiques (voir. Fig 2).
Dans le cas des distributions lentement dérivantes, cet effet néfaste n'est pas observé : si la vitesse de dérive est comparable à la « vitesse de déplacement » des neurones dans l'adaptation des poids, GNG est en mesure de suivre ces changements.
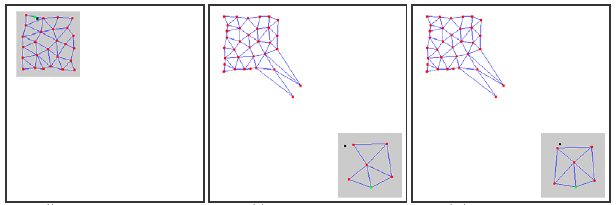
Figure 2. La réaction du gaz neuronal en croissance sur la distribution "sautante"
Des nœuds séparés inactifs (morts) peuvent également apparaître sur le réseau si une fréquence très élevée d'insertion de nouveaux neurones (le paramètre λ) est donnée à l'entrée de l'algorithme.
Sa valeur trop faible conduit au fait que le réseau commence à suivre des émissions statistiquement insignifiantes de distribution de signaux d'entrée, dont la probabilité de récurrence est très faible. Si un neurone GNG est inséré à cet endroit, il restera presque certainement inactif pendant longtemps.
De plus, comme le montrent les recherches empiriques, la faible valeur d'insertion, bien qu'elle contribue à la diminution rapide de l'erreur moyenne du réseau au début du processus d'apprentissage,découlant de la formation donne les pires valeurs de cet indicateur : un tel réseau regroupe les données de manière plus grossière.
7. Modification de l'Algorithme
Le problème de la distribution "sautante" peut être résolu en modifiant l'algorithme d'une certaine manière. La modification largement acceptée est celle qui introduit le facteur dit d'utilité des neurones (GNG avec facteur d'utilité ou GNG-U). Les modifications du pseudocode dans ce cas sont infimes et sont les suivantes :
- à chaque neurone
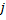 une variable appelée « facteur d'utilité »
une variable appelée « facteur d'utilité » 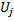 (cette variable U dans la liste des champs de la classe CGNGNeuron) est mise en conformité ;
(cette variable U dans la liste des champs de la classe CGNGNeuron) est mise en conformité ; -
à l'étape 4, après avoir adapté les poids du neurone gagnant, nous modifions son facteur d'utilité d'un montant égal à la différence entre une erreur du deuxième meilleur neurone et le gagnant :
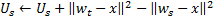
Physiquement, cet additif est la quantité par laquelle l'erreur totale du réseau aurait changé s'il n'y avait pas eu de gagnant (alors le deuxième meilleur gagnant deviendrait le gagnant), c'est-à-dire qu'il caractérise réellement l'utilité du neurone pour réduire l'erreur globale. -
les neurones sont supprimés à l'étape 8 selon un principe différent : seul un nœud avec une valeur d'utilité minimale est supprimé, et uniquement si la valeur d'erreur maximale dans la couche dépasse son facteur d'utilité de plusieurs
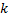 fois :
fois :
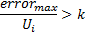
-
lors de l'ajout d'un nouveau nœud à l'étape 9, son facteur d'utilité est calculé comme la moyenne arithmétique entre les utilités des neurones voisins :
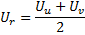
-
à l'étape 10 le facteur d'utilité de tous les neurones est diminué de la même manière et dans le même ordre que les variables d'erreurs :
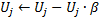
La constante ![]() ici est capitale à la capacité de suivre la mobilité : sa valeur trop grande conduit à la suppression non seulement de vraiment « peu d'utilité », mais aussi d'autres neurones tout à fait utilisables ; une valeur trop faible conduit à des suppressions rares et par conséquent, à un taux d'adaptation réduit.
ici est capitale à la capacité de suivre la mobilité : sa valeur trop grande conduit à la suppression non seulement de vraiment « peu d'utilité », mais aussi d'autres neurones tout à fait utilisables ; une valeur trop faible conduit à des suppressions rares et par conséquent, à un taux d'adaptation réduit.
Dans le fichier GNG.mqh, l'algorithme GNG-U est décrit comme une classe dérivée de CGNGAlgorithm. Les lecteurs peuvent suivre indépendamment les modifications et essayer d'utiliser l'algorithme.
Conclusion
En créant un réseau de neurones, nous avons passé en revue les principales caractéristiques de la programmation orientée-objet bâtie dans le langage MQL5. Il semble assez évident qu'en l'absence de telles opportunités (ce dont je remercie les développeurs), il serait beaucoup plus compliqué d'écrire des programmes complexes pour le trading automatisé.
Quant aux algorithmes analysés, il est vital de noter que, naturellement, ils peuvent être améliorés. En particulier, le premier candidat à la mise à niveau est le nombre de paramètres externes. Ils sont assez nombreux, et cela indique qu'il peut bien y avoir de telles modifications, dans lesquelles ces paramètres deviendraient des variables internes et seraient sélectionnés en fonction des caractéristiques des données d'entrée et de l'état de l'algorithme.
L'auteur de l'article souhaite bonne chance à tous dans l'étude de la neuro-informatique et son utilisation dans le trading !
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/163
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.
 Assistant MQL5 : Création d'Expert Advisors sans programmation
Assistant MQL5 : Création d'Expert Advisors sans programmation
 Le gestionnaire d'événements "New Bar"
Le gestionnaire d'événements "New Bar"
 L'exemple simple de création d'un indicateur à l'aide d'une logique floue
L'exemple simple de création d'un indicateur à l'aide d'une logique floue
 Simulink : un guide pour les développeurs d'Expert Advisors
Simulink : un guide pour les développeurs d'Expert Advisors
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Très intéressant,
J'ai hâte de le mettre en œuvre et de l'utiliser à la place d'un réseau neuronal fixe.
Article intéressant !
Mais il est assez ancien - le compilateur a été modifié et le code génère maintenant des erreurs et des avertissements !
Bonjour
Je demande si quelqu'un de la communauté a réussi à développer un EA en utilisant GNG ?
Je demande si le résultat est bon ?
Merci de votre compréhension.
Bonjour
Je demande si quelqu'un de la communauté a réussi à développer un EA en utilisant GNG ?
Je demande si le résultat est bon ?
merci
Eh bien... après quoi ? cinq mois o_O personne n'est disposé à le faire, alors peut-être que je peux faire un commentaire à ce sujet moi-même.
Dans l'implémentation que vous avez vue dans cet article, le NN est une variante auto-adaptative de ce que l'on appelle un réseau de fonctions à base radiale. Si vous comparez un EA basé sur l'algorithme GNG au même type d'EA basé sur un type de réseau neuronal de clusterisation non adaptatif, vous obtiendrez très probablement de meilleurs résultats avec GNG que sans GNG. Donc, pour répondre à votre dernière question, oui, le résultat est bon dans le sens que je viens d'expliquer.
Pour ce qui est de la première question, j'ai moi-même développé des EAs avec un GNG à l'intérieur, et cela a fonctionné modérément bien, yay. Cependant, pour un usage quotidien, je préfère d'autres algorithmes qui, en règle générale, ne sont pas neuronaux. Je peux étayer mon propos en rappelant que l'ANN se présente toujours comme une "boîte noire", ce qui signifie que vous ne comprenez pas vraiment ce qui se passe à l'intérieur lorsqu'il traite les données d'entrée. Cela implique que l'ANN ne serait un algorithme de choix que dans une situation où vous auriez un ensemble de données complètement non structurées avec des dépendances intrinsèques absolument inconnues que vous aimeriez que l'ANN extraie d'une manière ou d'une autre. Note : sans aucune promesse de résultat précis. Dans tous les autres cas, c'est-à-dire lorsque vous avez une idée de la manière dont les dépendances de votre ensemble de données peuvent être organisées, vous devriez d'abord essayer d'autres méthodes "boîte blanche" plus déterministes pour le structurer. Il en existe des milliers.