Discussion de l'article "Gaz neuronal en croissance : Implémentation en MQL5"
Ça a l'air cool :)
Mais ce que c'est, et comment l'utiliser, je ne l'ai pas encore compris :)
Ça a l'air cool :)
Mais ce que c'est, et comment l'utiliser, nous avons besoin d'en savoir plus :)
peut être utilisé comme première couche cachée - pour la réduction de la dimensionnalité ou le regroupement lui-même, peut être utilisé dans les réseaux probabilistes, et beaucoup d'autres options.
Merci pour ce matériel !
Je vais essayer de l'apprendre à mon rythme :)
Merci pour ce nouvel article sur une méthode de mise en réseau intéressante. Si vous parcourez la littérature, il en existe des dizaines, voire des centaines. Mais le problème des traders ne réside pas dans le manque d'outils, mais dans leur utilisation correcte. L'article serait encore plus intéressant s'il contenait un exemple d'utilisation de cette méthode dans un Expert Advisor.

Merci pour ce nouvel article sur une méthode de mise en réseau intéressante. Si vous parcourez la littérature, il en existe des dizaines, voire des centaines. Mais le problème des traders ne réside pas dans le manque d'outils, mais dans leur utilisation correcte. L'article serait encore plus intéressant s'il contenait un exemple d'utilisation de cette méthode dans un Expert Advisor.
1. L'article est bon. Il est présenté de manière accessible, le code n'est pas compliqué.
2. Les inconvénients de l'article comprennent le fait que rien n'est dit sur les données d'entrée du réseau. Vous auriez pu écrire quelques mots sur les données d'entrée - vecteur de cotations pour la période/les données de l'indicateur, vecteur d'écarts de prix, cotations normalisées ou autre. Pour l'utilisation pratique de l'algorithme, la question des données d'entrée et de leur préparation est essentielle. Je recommande d'utiliser un vecteur de variations de prix relatives pour ces algorithmes : x[i]=prix[i+1]-prix[i].
En outre, le vecteur d'entrée peut être préalablement normalisé (x_normal[i]=x[i]/M), pour lequel l'écart maximal du prix pour la période considérée peut être utilisé comme M (ici et ci-dessous, par souci de concision, je n'écris pas de déclarations de variables) :
M=x[ArrayMaximum(x)]-x[ArrayMinimum(x)];
Dans ce cas, tous les vecteurs d'entrée se trouveront dans un hypercube unitaire de côté [-0,5,0,5], ce qui augmentera considérablement la qualité du regroupement. Vous pouvez également utiliser l'écart normal standard ou toute autre variable de calcul de moyenne sur les écarts relatifs des cotations au cours de la période considérée comme M.
3. Le document suggère d'utiliser le carré de la norme de la différence comme distance entre le vecteur des poids des neurones et le vecteur d'entrée:
for(i=0, sum=0; i<m; i++, sum+=Pow(x[i]-w[i],2));
À mon avis, cette fonction de distance n'est pas efficace pour cette tâche de regroupement. La fonction calculant le produit scalaire ou le produit scalaire normalisé, c'est-à-dire le cosinus de l'angle entre le vecteur de poids et le vecteur d'entrée, est plus efficace :
for(i=0, norma_x=0, norma_w=0; i<m; i++, norma_x+=x[i]*x[i], norma_w+=w[i]*w[i]); norma_x=sqrt(norma_x); norma_w=sqrt(norma_w); for(i=0, sum=0; i<m; i++, sum+=x[i]*w[i]); if(norma_x*norma_w!=0) sum=sum/(norma_x*norma_w);
Dans chaque grappe, les vecteurs similaires seront regroupés en fonction de la direction des oscillations, mais pas en fonction de l'ampleur de ces oscillations, ce qui réduira considérablement la dimensionnalité du problème à résoudre et augmentera les caractéristiques des distributions de poids du réseau neuronal entraîné.
4.Il a été observé à juste titre qu'il est nécessaire de définir un critère d'arrêt pour la formation du réseau. Le critère d'arrêt doit déterminer le nombre requis de grappes du réseau formé. Ce nombre dépend à son tour du problème général à résoudre. Si la tâche consiste à prévoir une série temporelle pour 1 à 2 échantillons à l'avance et qu'à cette fin, par exemple, un perseptron multicouche est utilisé, le nombre de grappes ne doit pas être très différent du nombre de neurones de la couche d'entrée du perseptron.

En général, le nombre de barres dans l'histoire ne dépasse pas 5 300 000 sur le graphique minute le plus détaillé (10 ans*365 jours*24 heures*60 minutes). Sur le graphique horaire, il est de 87 000 barres. En d'autres termes, la création d'un classificateur avec un nombre de clusters supérieur à 10000-20000 n'est pas justifiée en raison de l'effet de "surentraînement", lorsque chaque vecteur de cotations a son propre cluster séparé.
Je m'excuse pour les erreurs éventuelles.
1. Merci, j'ai fait de mon mieux pour vous :)
2. Oui, je suis d'accord. Mais il y a toujours les intrants - c'est un autre grand problème, sur lequel on peut écrire des douzaines d'articles.
3) Et là, je ne suis pas du tout d'accord. Dans le cas d'entrées normalisées, la comparaison de produits scalaires est équivalente à la comparaison de normes euclidiennes - développez les formules.
4. Puisque le nombre maximum de clusters est déjà l'un des paramètres de l'algorithme.
max_nodes
Je procéderais, par exemple, de la manière suivante : mesurer l'erreur du gagnant aux N derniers pas et évaluer sa dynamique d'une manière ou d'une autre (par exemple, mesurer la pente de la droite de régression). Si l'erreur continue de diminuer et que les données d'entraînement sont déjà épuisées, il convient d'envisager leur lissage pour supprimer le bruit ou éliminer d' une manière ou d'une autre le déficit d'exemples.
3. je ne comprends pas où est l'équivalence des formules. La formule du cosinus de l'angle entre les vecteurs(x,w)/ (|x|||w|) n'est "pas très" similaire à |x-w|^2. La normalisation des entrées ne change pas les différences fondamentales entre ces mesures :
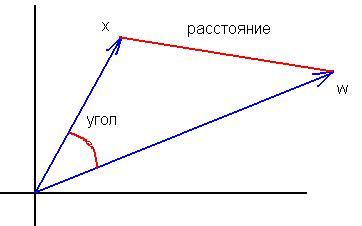
L'équivalence est que le maximum de la distance correspond toujours au minimum du produit scalaire et vice versa. La relation dans le cas des vecteurs normalisés est mutuellement non ambiguë et monotone, de sorte qu'il importe peu de calculer le carré de la distance ou l'angle.
Bonjour Alex,
Merci pour cette explication claire sur le sujet.
Serait-il possible de partager un code pratique pour la reconstruction des prix futurs, par exemple à partir de signaux optimaux.
L'idée est la suivante
1. Entrée (Source) : plusieurs devises (18)
2. Destination : Signal optimal de la devise que nous aimerions prédire (pic : 2. Optimal_Signals)
3. Trouver une neuro-connexion entre la Source et la Destination et l'exploiter dans le trading.

Une autre question à propos de la reconstruction du NN :
Est-il possible d'utiliser nos échantillons à la place des échantillons aléatoires, comme sur l'image 2 :
Notre cerveau peut reconstruire l'image en moins d'une seconde, voyons combien de temps il faut au NN pour faire la même chose, c'est juste une blague, ce n'est pas un défi.

Les échantillons générés aléatoirement ne sont pas très intéressants à voir car il n'y a pas de signification derrière ou d'utilisation, cependant si nous pouvons dessiner des points nous-mêmes avec une certaine signification derrière, ce serait beaucoup plus amusant :-0).

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Un nouvel article Gaz neuronal en croissance : Implémentation en MQL5 a été publié :
L'article étale un exemple de comment élaborer un programme MQL5 mettant en implémentant l'algorithme adaptatif de groupement appelé Growing neural gas (GNG). L'article est destiné aux utilisateurs qui ont étudié la documentation du langage et qui ont certaines compétences en programmation et des connaissances de base dans le domaine de la neuro-informatique.
Lors de la programmation de l'algorithme, nous devrons évidemment faire face à la nécessité de stocker ce que l'on appelle des "ensembles". Nous aurons deux ensembles – un ensemble de neurones et un ensemble de bords entre eux. Bien que les deux structures évoluent au cours du programme (et nous prévoyons à la fois d'ajouter et de supprimer des éléments), nous devrions également fournir des mécanismes pour cela.
Bien sûr, nous pourrions essayer d'utiliser des tableaux d'objets dynamiques, mais nous devrions effectuer de nombreuses opérations de copie-déplacement de données, ce qui ralentirait essentiellement le programme. Une option plus appropriée pour travailler avec des abstractions avec les propriétés indiquées est les graphes de programme et leur version la plus simple - une liste chaînée.
Je rappellerai à nos lecteurs le principe de fonctionnement de la linked list (Fig. 1). Les objets de la classe de base contiennent un pointeur vers le même objet que l'un des membres, ce qui permet de les combiner dans des structures linéaires, sans tenir compte de l'ordre physique des objets en mémoire. De plus, il existe la classe "carriage", qui encapsule la procédure de déplacement à travers la liste, l'ajout, l'insertion et la suppression de nœuds, la recherche, la comparaison et le tri, et, si nécessaire, d'autres procédures.
Auteur : Alexey Subbotin