
Utilisation des règles d'association dans l'analyse des données Forex

Introduction au concept des règles d'association
Le trading algorithmique moderne exige de nouvelles approches d'analyse. Le marché est en constante évolution, et les méthodes classiques d'analyse technique ne permettent plus d'identifier les relations complexes qui s'y rattachent.
Je travaille avec des données depuis longtemps et j'ai constaté que de nombreuses idées fructueuses proviennent de domaines connexes. Aujourd'hui, je souhaite partager mon expérience de l'utilisation des règles d'association dans le trading. Cette méthode a fait ses preuves dans l'analyse des données de vente au détail, nous permettant de trouver des liens entre les achats, les transactions, les variations de prix et l'offre et la demande futures. Et si on l'appliquait au marché des changes ?
L'idée de base est simple : nous recherchons des schémas stables de comportement des prix, des indicateurs et leurs combinaisons. Par exemple, à quelle fréquence une hausse de l'EURUSD fait-elle suite à une baisse de l'USDJPY ? Quelles sont les conditions qui précèdent le plus souvent les mouvements importants ?
Dans cet article, je vais vous présenter le processus complet de création d'un système de trading basé sur cette idée. Nous allons :
- Collecter les données historiques en MQL5
- Les analyser en Python
- Identifier les tendances significatives
- Les transformer en signaux de trading
Pourquoi cette liste en particulier ? MQL5 est idéal pour travailler avec les données boursières et automatiser les transactions. Python fournit à son tour de puissants outils d'analyse. D'après mon expérience, je peux affirmer que cette combinaison est très efficace pour développer des systèmes de trading.
Le code contiendra de nombreuses choses intéressantes, notamment en ce qui concerne l'application des règles d'association au Forex.
Collecte et préparation des données historiques du Forex
Il est extrêmement important pour nous de collecter et de préparer toutes les données dont nous avons besoin. Prenons comme base les données H1 des principales paires de devises des deux dernières années (depuis 2022).
Nous allons maintenant créer un script MQL5 qui collectera et exportera les données nécessaires au format CSV :
//+------------------------------------------------------------------+ //| Dataset.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string pairs[] = {"EURUSD", "GBPUSD", "USDJPY", "USDCHF"}; datetime startTime = D'2022.01.01 00:00'; datetime endTime = D'2024.01.01 00:00'; for(int i=0; i<ArraySize(pairs); i++) { string filename = pairs[i] + "_H1.csv"; int fileHandle = FileOpen(filename, FILE_WRITE|FILE_CSV); if(fileHandle != INVALID_HANDLE) { // Set headers FileWrite(fileHandle, "DateTime", "Open", "High", "Low", "Close", "Volume"); MqlRates rates[]; ArraySetAsSeries(rates, true); int copied = CopyRates(pairs[i], PERIOD_H1, startTime, endTime, rates); for(int j=copied-1; j>=0; j--) { FileWrite(fileHandle, TimeToString(rates[j].time), DoubleToString(rates[j].open, 5), DoubleToString(rates[j].high, 5), DoubleToString(rates[j].low, 5), DoubleToString(rates[j].close, 5), IntegerToString(rates[j].tick_volume) ); } FileClose(fileHandle); } } } //+------------------------------------------------------------------+
Traitement des données en Python
Après avoir constitué un ensemble de données, il est important de les traiter correctement.
Pour cela, j'ai créé la classe spéciale ForexDataProcessor, qui se charge de tout le travail ingrat. Examinons ses principaux composants.
Nous allons commencer par charger les données. Notre fonction utilise des données horaires pour les principales paires de devises : EURUSD, GBPUSD, USDJPY et USDCHF. Les données doivent être au format CSV et comporter les principales caractéristiques de prix.
import pandas as pd
import numpy as np
from datetime import datetime
import os
import warnings
warnings.filterwarnings('ignore')
class ForexDataProcessor:
def __init__(self):
self.pairs = ["EURUSD", "GBPUSD", "USDJPY", "USDCHF"]
self.data = {}
self.processed_data = {}
def load_data(self):
"""Load data for all currency pairs"""
success = True
for pair in self.pairs:
filename = f"{pair}_H1.csv"
try:
df = pd.read_csv(filename,
encoding='utf-16',
sep='\t',
names=['DateTime', 'Open', 'High', 'Low', 'Close', 'Volume'])
# Remove lines with duplicate headers
df = df[df['DateTime'] != 'DateTime']
# Convert data types
df['DateTime'] = pd.to_datetime(df['DateTime'], format='%Y.%m.%d %H:%M')
for col in ['Open', 'High', 'Low', 'Close']:
df[col] = pd.to_numeric(df[col], errors='coerce')
df['Volume'] = pd.to_numeric(df['Volume'], errors='coerce')
# Remove NaN strings
df = df.dropna()
df.set_index('DateTime', inplace=True)
self.data[pair] = df
print(f"Loaded {pair} data successfully. Shape: {df.shape}")
except Exception as e:
print(f"Error loading {pair} data: {str(e)}")
success = False
return success
def safe_qcut(self, series, q, labels):
"""Safe quantization with error handling"""
try:
if series.nunique() <= q:
# If there are fewer unique values than quantiles, use regular categorization
return pd.qcut(series, q=q, labels=labels, duplicates='drop')
return pd.qcut(series, q=q, labels=labels)
except Exception as e:
print(f"Warning: Error in qcut - {str(e)}. Using manual categorization.")
# Manual categorization as a backup option
percentiles = np.percentile(series, [20, 40, 60, 80])
return pd.cut(series,
bins=[-np.inf] + list(percentiles) + [np.inf],
labels=labels)
def calculate_indicators(self, df):
"""Calculate technical indicators for a single dataframe"""
result = df.copy()
# Basic calculations
result['Returns'] = result['Close'].pct_change()
result['Log_Returns'] = np.log(result['Close']/result['Close'].shift(1))
result['Range'] = result['High'] - result['Low']
result['Range_Pct'] = result['Range'] / result['Open'] * 100
# SMA calculations
for period in [5, 10, 20, 50, 200]:
result[f'SMA_{period}'] = result['Close'].rolling(window=period).mean()
# EMA calculations
for period in [5, 10, 20, 50]:
result[f'EMA_{period}'] = result['Close'].ewm(span=period, adjust=False).mean()
# Volatility
result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20)
# RSI
delta = result['Close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window=14).mean()
loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean()
rs = gain / loss
result['RSI'] = 100 - (100 / (1 + rs))
# MACD
exp1 = result['Close'].ewm(span=12, adjust=False).mean()
exp2 = result['Close'].ewm(span=26, adjust=False).mean()
result['MACD'] = exp1 - exp2
result['MACD_Signal'] = result['MACD'].ewm(span=9, adjust=False).mean()
result['MACD_Hist'] = result['MACD'] - result['MACD_Signal']
# Bollinger Bands
result['BB_Middle'] = result['Close'].rolling(window=20).mean()
result['BB_Upper'] = result['BB_Middle'] + (result['Close'].rolling(window=20).std() * 2)
result['BB_Lower'] = result['BB_Middle'] - (result['Close'].rolling(window=20).std() * 2)
result['BB_Width'] = (result['BB_Upper'] - result['BB_Lower']) / result['BB_Middle']
# Discretization for association rules
# SMA-based trend
result['Trend'] = 'Sideways'
result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend'
result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
# RSI zones
result['RSI_Zone'] = pd.cut(result['RSI'].fillna(50),
bins=[-np.inf, 30, 45, 55, 70, np.inf],
labels=['Oversold', 'Weak', 'Neutral', 'Strong', 'Overbought'])
# Secure quantization for other parameters
labels = ['Very_Low', 'Low', 'Medium', 'High', 'Very_High']
result['Volatility_Zone'] = self.safe_qcut(
result['Volatility'].fillna(result['Volatility'].mean()),
5, labels)
result['Price_Zone'] = self.safe_qcut(
result['Close'],
5, labels)
result['Volume_Zone'] = self.safe_qcut(
result['Volume'],
5, labels)
# Candle patterns
result['Body'] = result['Close'] - result['Open']
result['Upper_Shadow'] = result['High'] - result[['Open', 'Close']].max(axis=1)
result['Lower_Shadow'] = result[['Open', 'Close']].min(axis=1) - result['Low']
result['Body_Pct'] = result['Body'] / result['Open'] * 100
body_mean = abs(result['Body_Pct']).mean()
result['Candle_Pattern'] = 'Normal'
result.loc[abs(result['Body_Pct']) < body_mean * 0.1, 'Candle_Pattern'] = 'Doji'
result.loc[result['Body_Pct'] > body_mean * 2, 'Candle_Pattern'] = 'Long_Bullish'
result.loc[result['Body_Pct'] < -body_mean * 2, 'Candle_Pattern'] = 'Long_Bearish'
return result
def process_all_pairs(self):
"""Process all currency pairs and create combined dataset"""
if not self.load_data():
return None
# Handling each pair
for pair in self.pairs:
if not self.data[pair].empty:
print(f"Processing {pair}...")
self.processed_data[pair] = self.calculate_indicators(self.data[pair])
# Add a pair prefix to the column names
self.processed_data[pair].columns = [f"{pair}_{col}" for col in self.processed_data[pair].columns]
else:
print(f"Skipping {pair} - no data")
# Find the common time range for non-empty data
common_dates = None
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
if common_dates is None:
common_dates = set(self.processed_data[pair].index)
else:
common_dates &= set(self.processed_data[pair].index)
if not common_dates:
print("No common dates found")
return None
# Align all pairs by common dates
aligned_data = {}
for pair in self.pairs:
if pair in self.processed_data and not self.processed_data[pair].empty:
aligned_data[pair] = self.processed_data[pair].loc[sorted(common_dates)]
# Combine all pairs
combined_df = pd.concat([aligned_data[pair] for pair in aligned_data], axis=1)
return combined_df
def save_data(self, data, suffix='combined'):
"""Save processed data to CSV"""
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"forex_data_{suffix}_{timestamp}.csv"
try:
data.to_csv(filename, sep='\t', encoding='utf-16')
print(f"Saved processed data to: {filename}")
return True
except Exception as e:
print(f"Error saving data: {str(e)}")
return False
if __name__ == "__main__":
processor = ForexDataProcessor()
# Handling all pairs
combined_data = processor.process_all_pairs()
if combined_data is not None:
# Save the combined dataset
processor.save_data(combined_data)
# Display dataset info
print("\nCombined dataset shape:", combined_data.shape)
print("\nFeatures for association rules analysis:")
for col in combined_data.columns:
if any(x in col for x in ['_Zone', '_Pattern', 'Trend']):
print(f"- {col}")
# Save individual pairs
for pair in processor.pairs:
if pair in processor.processed_data and not processor.processed_data[pair].empty:
processor.save_data(processor.processed_data[pair], pair)
Une fois le chargement réussi, la partie la plus intéressante commence : le calcul des indicateurs techniques. Je m'appuie ici sur tout un arsenal d'outils éprouvés par le temps. Les moyennes mobiles permettent d'identifier les tendances de durée variable. Une SMA(50) agit souvent comme support ou résistance dynamique. L'oscillateur RSI avec une période classique de 14 est performant pour déterminer les zones de sur-achat et de sur-vente du marché. Le MACD est indispensable pour identifier les points de momentum et de retournement. Les Bandes de Bollinger donnent une image claire de la volatilité actuelle du marché.
# Volatility and RSI calculation example result['Volatility'] = result['Returns'].rolling(window=20).std() * np.sqrt(20) delta = result['Close'].diff() gain = (delta.where(delta > 0, 0)).rolling(window=14).mean() loss = (-delta.where(delta < 0, 0)).rolling(window=14).mean() rs = gain / loss result['RSI'] = 100 - (100 / (1 + rs))
La discrétisation des données mérite une attention particulière. Toutes les valeurs continues doivent être réparties en catégories claires. En la matière, il est important de trouver un juste milieu : une division trop abrupte compliquera la recherche de tendances, et une division trop faible entraînera la perte de nuances importantes du marché. Par exemple, pour déterminer la tendance, une division plus simple est plus efficace : celle qui repose sur la position du prix par rapport à la moyenne :
# Defining a trend result['Trend'] = 'Sideways' result.loc[result['Close'] > result['SMA_50'], 'Trend'] = 'Uptrend' result.loc[result['Close'] < result['SMA_50'], 'Trend'] = 'Downtrend'
Les figures de chandeliers nécessitent également une approche particulière. Sur la base d'une analyse statistique, je distingue les Doji pour les tailles de corps de bougie minimales, les Long_Bullish et les Long_Bearish pour les mouvements de prix extrêmes. Cette classification nous permet d'identifier clairement les moments d'indécision du marché et les fortes impulsions.
À la fin du traitement, toutes les paires de devises sont combinées en un seul tableau de données avec une échelle de temps commune. Cette étape est d'une importance fondamentale : elle ouvre la possibilité de rechercher des relations complexes entre différents instruments. Nous pouvons désormais observer comment la tendance d'une paire influence la volatilité d'une autre, ou comment les configurations de chandeliers japonais sont liées aux volumes d'échanges sur l'ensemble du marché.
Implémentation de l'algorithme Apriori en Python
Après avoir préparé les données, nous passons à l'étape clé : la mise en œuvre de l'algorithme Apriori pour trouver des règles d'association dans nos données financières. Nous adaptons l'algorithme Apriori, initialement développé pour l'analyse des paniers de biens et services, afin qu'il fonctionne avec des séries temporelles de paires de devises.
Dans le contexte du marché des changes, une « transaction » désigne un ensemble d'états de divers indicateurs et paires de devises à un moment donné. Par exemple :- Tendance EUR/USD = Haussière
- Zone RSI GBPUSD = Sur-achat
- Zone de volatilité USD/JPY = Élevée
L'algorithme recherche les combinaisons fréquentes de ces états, sur la base desquelles des règles de trading sont ensuite établies.
import pandas as pd import numpy as np from collections import defaultdict from itertools import combinations import time import logging # Setting up logging logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('apriori_forex_advanced.log'), logging.StreamHandler() ] ) class AdvancedForexApriori: def __init__(self, min_support=0.01, min_confidence=0.7, max_length=3): self.min_support = min_support self.min_confidence = min_confidence self.max_length = max_length def find_patterns(self, df): start_time = time.time() logging.info("Starting advanced pattern search...") # Group columns by type for more meaningful analysis column_groups = { 'trend': [col for col in df.columns if 'Trend' in col], 'rsi': [col for col in df.columns if 'RSI_Zone' in col], 'volume': [col for col in df.columns if 'Volume_Zone' in col], 'price': [col for col in df.columns if 'Price_Zone' in col], 'pattern': [col for col in df.columns if 'Pattern' in col] } # Create a list of all columns for analysis pattern_cols = [] for cols in column_groups.values(): pattern_cols.extend(cols) logging.info(f"Found {len(pattern_cols)} pattern columns in {len(column_groups)} groups") # Prepare data pattern_df = df[pattern_cols] n_rows = len(pattern_df) # Find single patterns logging.info("Finding single patterns...") single_patterns = {} for col in pattern_cols: value_counts = pattern_df[col].value_counts() value_counts = value_counts[value_counts/n_rows >= self.min_support] for value, count in value_counts.items(): pattern = f"{col}={value}" single_patterns[pattern] = count/n_rows # Find pair and triple patterns logging.info("Finding complex patterns...") complex_rules = [] # Generate column combinations for analysis column_combinations = [] for i in range(2, self.max_length + 1): column_combinations.extend(combinations(pattern_cols, i)) total_combinations = len(column_combinations) for idx, cols in enumerate(column_combinations, 1): if idx % 10 == 0: logging.info(f"Processing combination {idx}/{total_combinations}") # Create a cross-table for the selected columns grouped = pattern_df.groupby([*cols]).size().reset_index(name='count') grouped['support'] = grouped['count'] / n_rows # Sort by minimum support grouped = grouped[grouped['support'] >= self.min_support] for _, row in grouped.iterrows(): # Form all possible combinations of antecedents and consequents items = [f"{col}={row[col]}" for col in cols] for i in range(1, len(items)): for antecedent in combinations(items, i): consequent = tuple(set(items) - set(antecedent)) # Calculate the support of the antecedent ant_support = self._calculate_support(pattern_df, antecedent) if ant_support > 0: # Avoid division by zero confidence = row['support'] / ant_support if confidence >= self.min_confidence: # Count the lift cons_support = self._calculate_support(pattern_df, consequent) lift = confidence / cons_support if cons_support > 0 else 0 # Adding additional metrics to evaluate rules leverage = row['support'] - (ant_support * cons_support) conviction = (1 - cons_support) / (1 - confidence) if confidence < 1 else float('inf') rule = { 'antecedent': antecedent, 'consequent': consequent, 'support': row['support'], 'confidence': confidence, 'lift': lift, 'leverage': leverage, 'conviction': conviction } # Sort the rules by additional criteria if self._is_meaningful_rule(rule): complex_rules.append(rule) # Sort the rules by complex metric complex_rules.sort(key=self._rule_score, reverse=True) end_time = time.time() logging.info(f"Pattern search completed in {end_time - start_time:.2f} seconds") logging.info(f"Found {len(complex_rules)} meaningful rules") return complex_rules def _calculate_support(self, df, items): """Calculate support for a set of elements""" mask = pd.Series(True, index=df.index) for item in items: col, val = item.split('=') mask &= (df[col] == val) return mask.mean() def _is_meaningful_rule(self, rule): """Check the rule for its relevance to trading""" # The rule should have the high lift and 'leverage' if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False # At least one element should be related to a trend or RSI has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True def _rule_score(self, rule): """Calculate the rule complex evaluation""" return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1) # Load data logging.info("Loading data...") data = pd.read_csv('forex_data_combined_20241116_074242.csv', sep='\t', encoding='utf-16', index_col='DateTime') logging.info(f"Data loaded, shape: {data.shape}") # Apply the algorithm apriori = AdvancedForexApriori(min_support=0.01, min_confidence=0.7, max_length=3) rules = apriori.find_patterns(data) # Display results logging.info("\nTop 10 trading rules:") for i, rule in enumerate(rules[:10], 1): logging.info(f"\nRule {i}:") logging.info(f"IF {' AND '.join(rule['antecedent'])}") logging.info(f"THEN {' AND '.join(rule['consequent'])}") logging.info(f"Support: {rule['support']:.3f}") logging.info(f"Confidence: {rule['confidence']:.3f}") logging.info(f"Lift: {rule['lift']:.3f}") logging.info(f"Leverage: {rule['leverage']:.3f}") logging.info(f"Conviction: {rule['conviction']:.3f}") # Save results results_df = pd.DataFrame(rules) results_df.to_csv('forex_rules_advanced.csv', index=False, sep='\t', encoding='utf-16') logging.info("Results saved to forex_rules_advanced.csv")
Adaptation des règles d'association pour l'analyse des paires de devises
Dans le cadre de mon travail d'adaptation de l'algorithme Apriori au marché des changes, j'ai rencontré des défis intéressants. Bien que cette méthode ait été initialement créée pour analyser les achats en magasin, son potentiel pour le Forex me semblait prometteur.
La principale difficulté résidait dans le fait que le marché des changes est radicalement différent des achats classiques en magasin. Au fil des années passées à travailler sur les marchés financiers, je me suis habitué à gérer des prix et des indicateurs en constante évolution. Mais comment appliquer un algorithme qui, d'habitude, se contente de rechercher des liens entre les bananes et le lait sur les tickets de caisse des supermarchés ?
Mes expériences ont abouti à un système de 5 indicateurs. Je les ai tous testés minutieusement.
Le « support » s'est avéré être un indicateur très délicat. J'ai failli inclure une fois une règle aux performances excellentes dans un système de trading, mais le support n'était que de 0,02. Heureusement, je l'ai remarqué à temps – en pratique, une telle règle ne s'appliquerait qu'une fois tous les 100 ans !
La « confiance » s'est avérée plus simple. Quand on travaille sur les marchés, on apprend vite qu'une probabilité de 70% est déjà un excellent indicateur. L'essentiel est de gérer judicieusement les risques avec les 30% restants. Nous devons toujours garder la gestion des risques à l'esprit. Sans cela, vous subirez un revers, voire une perte, même si vous tenez le Graal entre vos mains.
Le « Lift » est devenu mon indicateur préféré. Après des centaines d'heures de tests, j'ai remarqué une tendance : les règles avec un lift supérieur à 1,5 fonctionnent effectivement sur le marché réel. Cette découverte a eu un impact profond sur mon approche du tri des signaux.
L'utilisation de l'effet de levier s'est avérée amusante. Au départ, je voulais l'exclure complètement du système, le considérant comme inutile. Mais lors d'une période particulièrement volatile du marché, cela a permis d'éliminer la plupart des faux signaux.
La « conviction » a été ajoutée en dernier, après consultation des forums. Cela m'a permis de comprendre l'importance de cet indicateur pour évaluer la signification réelle des tendances observées.
Ce qui m'a le plus surpris, c'est la façon dont l'algorithme trouve des liens inattendus entre différentes paires de devises. Qui aurait cru, par exemple, que certains schémas de l'EURUSD pouvaient prédire les mouvements de l'USDJPY avec une telle précision ? En 9 ans d'expérience sur le marché, je n'avais pas remarqué beaucoup des relations que l'algorithme a découvertes. Bien que le trading de paires, le trading de paniers et l'arbitrage aient été mon domaine, je me souviens encore de l'époque où cmillion commençait tout juste à développer ses robots basés sur les mouvements mutuels des paires.
Je poursuis maintenant mes recherches, en testant de nouvelles combinaisons d'indicateurs et de périodes. Le marché est en constante évolution et chaque jour apporte son lot de nouvelles découvertes. La semaine prochaine, je prévois de publier les résultats des tests du système sur des données annuelles, ainsi que les premiers résultats en direct de l'algorithme sur un compte de démonstration réel. On y a découvert plusieurs résultats très intéressants.
Honnêtement, je ne m'attendais même pas à ce que ce projet aille aussi loin. Tout a commencé par une simple expérience d'exploration de données et de tentatives de classification rigoureuse de tous les mouvements du marché pour répondre aux besoins des algorithmes de classification, pour finalement se transformer en un système de trading à part entière. Je crois que je commence tout juste à comprendre le véritable potentiel de cette approche.
Caractéristiques de mise en œuvre pour le Forex
Revenons un peu au code lui-même. Notre code comporte plusieurs adaptations importantes de l'algorithme de traitement des données financières :
column_groups = {
'trend': [col for col in df.columns if 'Trend' in col],
'rsi': [col for col in df.columns if 'RSI_Zone' in col],
'volume': [col for col in df.columns if 'Volume_Zone' in col],
'price': [col for col in df.columns if 'Price_Zone' in col],
'pattern': [col for col in df.columns if 'Pattern' in col]
}
Ce regroupement permet de trouver des combinaisons d'indicateurs plus pertinentes et réduit la complexité des calculs.
def _is_meaningful_rule(self, rule): if rule['lift'] < 1.5 or rule['leverage'] < 0.01: return False has_trend_or_rsi = any('Trend' in item or 'RSI' in item for item in rule['antecedent'] + rule['consequent']) if not has_trend_or_rsi: return False return True
Nous ne sélectionnons que les règles présentant une forte signification statistique (lift > 1,5) et l'inclusion obligatoire d'indicateurs de tendance ou de RSI.
def _rule_score(self, rule): return (rule['lift'] * 0.4 + rule['confidence'] * 0.3 + rule['support'] * 0.2 + rule['leverage'] * 0.1)
Le score pondéré permet de classer les règles en fonction de leur utilité potentielle pour le trading.
Visualisation des associations trouvées
Après avoir identifié les règles d'association, nous devons les visualiser et les analyser correctement. À cette fin, j'ai développé la classe spéciale ForexRulesVisualizer, qui offre plusieurs méthodes d'analyse visuelle des modèles trouvés.
Distribution des métriques de règles
La première étape de l'analyse consiste à comprendre la distribution des principales métriques des règles trouvées. Le graphique de distribution du « support », de la « confiance », du « lift » et du « levier » permet d'évaluer la qualité des règles trouvées et, si nécessaire, d'ajuster les paramètres de l'algorithme.
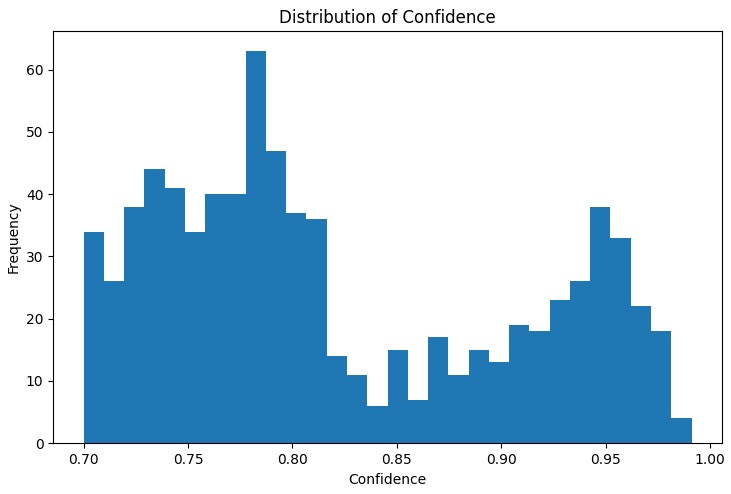
L'outil le plus utile était le graphique de réseau interactif, qui montre clairement les liens entre les différentes conditions de marché. Dans ce graphique, les nœuds représentent les états indicateurs (par exemple, "EURUSD_Trend=Uptrend" ou "USDJPY_RSI_Zone=Overbought"), et les bords représentent les règles trouvées, où l'épaisseur du bord est proportionnelle à la valeur 'lift'.
Carte thermique des interactions entre paires de devises 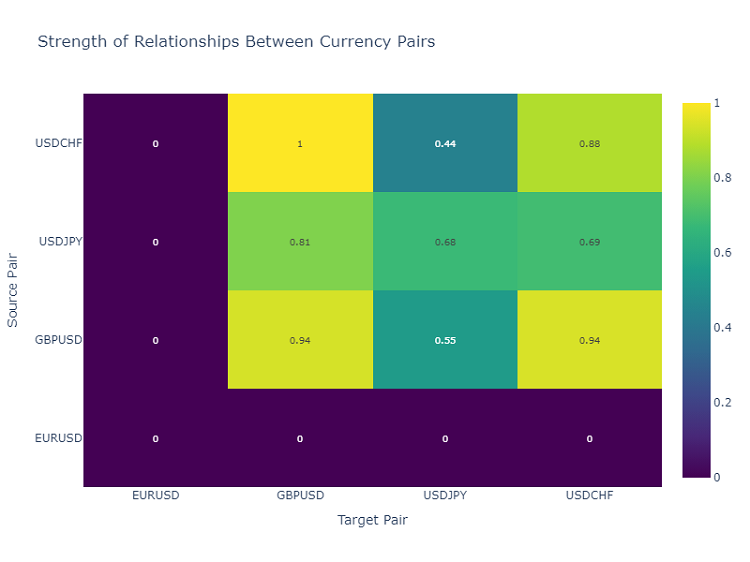
Pour analyser les relations entre les paires de devises, j'utilise une carte thermique, qui montre la force des relations entre les différents instruments. Cela permet d'identifier les paires qui s'influencent le plus souvent, ce qui est essentiel pour constituer un portefeuille de trading diversifié.
Création de signaux de trading
Une fois les règles d'association identifiées et visualisées, l'étape suivante importante consiste à les transformer en signaux de trading. À cette fin, j'ai développé la classe ForexSignalGenerator, qui analyse l'état actuel du marché et génère des signaux de trading en fonction des règles identifiées.
import pandas as pd import numpy as np from datetime import datetime import logging class ForexSignalGenerator: def __init__(self, rules_df, min_rule_strength=0.5): """ Signal generator initialization Parameters: rules_df: DataFrame with association rules min_rule_strength: minimum rule strength to generate a signal """ self.rules_df = rules_df self.min_rule_strength = min_rule_strength self.active_signals = {} def calculate_rule_strength(self, rule): """ Comprehensive assessment of the rule strength Takes into account all metrics with different weights """ strength = ( rule['lift'] * 0.4 + # Main weight on 'lift' rule['confidence'] * 0.3 + # Rule confidence rule['support'] * 0.2 + # Occurrence frequency rule['leverage'] * 0.1 # Improvement over randomness ) # Additional bonus for having trend indicators if any('Trend' in item for item in rule['antecedent']): strength *= 1.2 return strength def analyze_market_state(self, current_data): """ Current market state analysis Parameters: current_data: DataFrame with current indicator values """ signals = [] state = self._create_market_state(current_data) # Find all the matching rules matching_rules = self._find_matching_rules(state) # Grouping rules by currency pairs for pair in ['EURUSD', 'GBPUSD', 'USDJPY', 'USDCHF']: pair_rules = [r for r in matching_rules if any(pair in c for c in r['consequent'])] if pair_rules: signal = self._generate_pair_signal(pair, pair_rules) signals.append(signal) return signals def _create_market_state(self, data): """Forming the current market state""" state = [] for col in data.columns: if any(x in col for x in ['_Zone', '_Pattern', 'Trend']): state.append(f"{col}={data[col].iloc[-1]}") return set(state) def _find_matching_rules(self, state): """Searching for rules that match the current state""" matching_rules = [] for _, rule in self.rules_df.iterrows(): # Check if all the rule conditions are met if all(cond in state for cond in rule['antecedent']): strength = self.calculate_rule_strength(rule) if strength >= self.min_rule_strength: rule['calculated_strength'] = strength matching_rules.append(rule) return matching_rules def _generate_pair_signal(self, pair, rules): """Generating a signal for a specific currency pair""" # Divide the rules by signal type trend_signals = defaultdict(float) for rule in rules: # Looking for trend-related consequents trend_cons = [c for c in rule['consequent'] if pair in c and 'Trend' in c] if trend_cons: for cons in trend_cons: trend = cons.split('=')[1] trend_signals[trend] += rule['calculated_strength'] # Determine the final signal if trend_signals: strongest_trend = max(trend_signals.items(), key=lambda x: x[1]) return { 'pair': pair, 'signal': strongest_trend[0], 'strength': strongest_trend[1], 'timestamp': datetime.now() } return None # Usage example def run_trading_system(data, rules_df): """ Trading system launch Parameters: data: DataFrame with historical data rules_df: DataFrame with association rules """ signal_generator = ForexSignalGenerator(rules_df) # Simulate a pass along historical data signals_history = [] for i in range(len(data) - 1): current_slice = data.iloc[i:i+1] signals = signal_generator.analyze_market_state(current_slice) for signal in signals: if signal: signals_history.append({ 'datetime': current_slice.index[0], 'pair': signal['pair'], 'signal': signal['signal'], 'strength': signal['strength'] }) return pd.DataFrame(signals_history) # Loading historical data and rules data = pd.read_csv('forex_data_combined_20241116_090857.csv', sep='\t', encoding='utf-16', index_col='DateTime', parse_dates=True) rules_df = pd.read_csv('forex_rules_advanced.csv', sep='\t', encoding='utf-16') rules_df['antecedent'] = rules_df['antecedent'].apply(eval) rules_df['consequent'] = rules_df['consequent'].apply(eval) # Launch the test signals_df = run_trading_system(data, rules_df) # Analyze the results print("Generated signals statistics:") print(signals_df.groupby('pair')['signal'].value_counts())
Évaluer la force des règles
Après de longues expériences de visualisation des règles, il est temps de passer à la partie la plus difficile : la création de véritables signaux de trading. Je l'avoue, cette tâche m'a beaucoup fait transpirer. Trouver de belles configurations sur les graphiques est une chose, les transformer en un système de trading fonctionnel en est une autre.
J'ai décidé de créer un module séparé, ForexSignalGenerator. Au départ, je voulais simplement générer des signaux selon les règles les plus strictes, mais je me suis vite rendu compte que tout était beaucoup plus compliqué. Le marché est en constante évolution, et une règle qui fonctionnait bien hier peut ne plus fonctionner aujourd'hui.
J'ai dû adopter une approche sérieuse pour évaluer la solidité des règles. Après plusieurs expériences infructueuses, j'ai mis au point un système d'échelle. Ce qui m'a le plus posé problème, c'est le choix des proportions – j'ai probablement essayé des dizaines de combinaisons. Au final, j'ai opté pour « lift » qui représente 40% de l'évaluation finale (il s'agit d'un indicateur vraiment clé), « confiance » - 30%, « support » - 20% et « levier » - 10%.
Il est intéressant de noter que les signaux les plus forts étaient souvent obtenus lorsque la règle comportait une composante de tendance. J'ai même ajouté un bonus spécial de 20% à la force de ces règles, et la pratique a montré que cela était justifié.
J'ai également dû travailler dur pour gérer l'analyse de la situation actuelle du marché. Dans un premier temps, j'ai simplement comparé les valeurs actuelles des indicateurs aux conditions des règles. Mais je me suis alors rendu compte que je devais prendre en compte le contexte plus large. Par exemple, j'ai ajouté la vérification de la tendance générale sur les dernières périodes, l'état de la volatilité, voire l'heure de la journée.
Actuellement, le système analyse environ 20 paramètres différents pour chaque paire de devises. Certains des motifs que j'ai découverts m'ont vraiment surpris.
Bien sûr, le système est encore loin d'être parfait. Parfois, je me surprends à penser que je dois ajouter des facteurs fondamentaux. Mais je garde cela pour plus tard. Je souhaite tout d'abord terminer la version actuelle.
Tri et agrégation des signaux
Lors du développement du système, j'ai rapidement réalisé que la simple définition des règles ne suffisait pas ; nous avions besoin d'un contrôle strict de la qualité des signaux. Après quelques transactions infructueuses, il est devenu évident que le tri est peut-être encore plus important que la recherche de modèles eux-mêmes.
J'ai commencé par un seuil simple correspondant à la force minimale des règles. Au début, je l'avais réglé à 0,5, mais j'obtenais sans cesse des faux positifs. Après deux semaines de tests, je l'ai augmenté à 0,7, et la situation s'est nettement améliorée. Le nombre de signaux a diminué d'environ un tiers, mais leur qualité a considérablement augmenté.
Le second niveau de tri est apparu après un incident particulièrement choquant. Il existait une règle qui fonctionnait parfaitement, j'ai ouvert une position en conséquence, mais le marché a évolué strictement dans la direction opposée. Lorsque j'ai commencé à me pencher sur la question, il s'est avéré que d'autres règles en vigueur à ce moment-là envoyaient des signaux contraires. Depuis, je vérifie la cohérence en n'ouvrant la position que si plusieurs règles pointent dans la même direction.
Gérer la volatilité s'est avéré intéressant. J'ai remarqué que pendant les périodes calmes, le système fonctionne comme sur des roulettes. Mais dès que le marché s'anime, les problèmes commencent. J'ai donc ajouté un filtre dynamique sur l’ATR. Si la volatilité dépasse le 75e percentile au cours des 20 derniers jours, nous augmentons de 20% les exigences relatives à la robustesse des règles.
Le plus difficile a été de vérifier les signaux contradictoires. Il arrive que certaines règles préconisent d'acheter, d'autres de vendre, et toutes les règles ont de bons paramètres. J'ai essayé différentes approches, mais j'ai finalement opté pour une solution simple : s'il existe des contradictions importantes dans les signaux, nous ignorons cette situation. Ce faisant, nous perdons certaines opportunités, mais nous réduisons considérablement les risques.
Le mois prochain, j'ajouterai le tri par heure. J'ai remarqué qu'à certaines heures, les règles fonctionnent nettement moins bien. Cela est particulièrement vrai en période de faible liquidité et lors de la publication d'informations importantes. Je pense que cela devrait encore augmenter le pourcentage de transactions réussies.
Résultats des tests
Après plusieurs mois de développement du système, je me suis trouvé confronté à une question cruciale : comment évaluer correctement la force de chaque règle trouvée ? Tout paraissait simple sur le papier, mais le marché réel a rapidement mis en évidence toutes les faiblesses de l'approche initiale.
À l'issue de longues expériences, j'ai mis au point un système de pondération pour différents facteurs. J'ai fait de « Lift » la composante principale (40% d'influence) - la pratique a montré qu'il s'agit d'un indicateur vraiment crucial. La « confiance » représente 30% – après tout, la fiabilité de la règle compte aussi beaucoup. Les « support » et « effet de levier » ont vu leur poids réduit ; ils agissent davantage comme des filtres.
Le tri des signaux s'est avéré être une toute autre histoire. Au début, j'ai essayé d'appliquer toutes les règles à la lettre, mais j'ai vite compris mon erreur. J'ai donc dû mettre en place un système de tri à plusieurs niveaux. Tout d'abord, nous éliminons les règles faibles en fonction du seuil de force minimal. Ensuite, nous vérifions si le signal est confirmé par plusieurs règles – les règles isolées sont généralement moins fiables.
La prise en compte de la volatilité s'est avérée particulièrement importante. Durant les périodes calmes, le système fonctionnait parfaitement, mais dès que la volatilité augmentait, le nombre de faux signaux grimpait en flèche. J'ai dû ajouter des filtres dynamiques qui deviennent plus stricts à mesure que la volatilité augmente.
Les tests du système ont duré près de 3 mois. Je l'ai exécuté sur un historique de 2 ans pour 4 paires majeures. Les résultats ont été tout à fait inattendus. Par exemple, la paire USDJPY a affiché les meilleures performances : 65% de transactions rentables avec un RR de 1,6. Mais la paire GBPUSD a été décevante - seulement 58% avec un RR de 1,4.
Il est intéressant de noter que les règles avec un « lift » supérieur à 2,0 et une « confiance » supérieure à 0,8 ont systématiquement donné les meilleurs résultats pour toutes les paires. Apparemment, ces niveaux constituent réellement des seuils de signification naturelle sur le marché des changes.
Améliorations supplémentaires
Actuellement, je vois plusieurs pistes d'amélioration du système. Premièrement, les paramètres des règles doivent être rendus plus dynamiques : le marché évolue et le système doit s'adapter. Deuxièmement, on constate un manque évident de prise en compte de la macroéconomie et du contexte de l'actualité. Oui, cela compliquera le système, mais les gains potentiels en valent la peine.
L'application de filtres adaptatifs semble particulièrement intéressante. Les différentes phases du marché nécessitent clairement des paramètres système différents. Elle est implémentée de manière rudimentaire pour le moment, mais je vois déjà plusieurs façons de l'améliorer.
La semaine prochaine, je prévois de commencer à tester une nouvelle version avec une optimisation dynamique des tailles de position. Les premiers résultats basés sur les données historiques sont prometteurs, mais le marché réel, comme toujours, procédera à ses propres ajustements.
Conclusion
L'utilisation de règles d'association dans le trading algorithmique ouvre des perspectives intéressantes pour la découverte de schémas de marché non évidents. La clé du succès réside ici dans une préparation adéquate des données, une sélection rigoureuse des règles et un système de génération de signaux bien conçu.
Il est important de rappeler que tout système de trading nécessite une surveillance constante et une adaptation aux conditions changeantes du marché. Les règles associatives sont un outil d'analyse puissant, mais elles doivent être utilisées conjointement avec d'autres méthodes d'analyse techniques et fondamentales.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/16061
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Apparemment, on suppose que le lecteur doit déjà avoir une certaine connaissance de cette méthode, et si ce n'est pas le cas ?
Je ne comprends pas les mesures mentionnées, en particulier :
Lift est devenu mon indicateur préféré. Après des centaines d'heures de tests, j'ai remarqué une tendance : les règles dont le lift est supérieur à 1,5 fonctionnent vraiment sur le marché réel. Cette découverte a sérieusement influencé mon approche du filtrage des signaux.
Si j'ai bien compris la méthode, des signaux corrélés sont recherchés dans les segments quantiques. Mais je ne comprenais pas l'étape suivante. Quel est le segment cible ? Je suppose que les règles résultantes sont comparées à la cible et évaluées par rapport aux mesures.
Si c'est le cas, cela fait écho à ma méthode, et il est intéressant d'évaluer les performances et l'efficacité.