
Trading algorithmique basé sur des figures de retournement 3D

Aperçu des principaux résultats de la première étude sur les barres 3D et les grappes « jaunes »
Il fait nuit. Le terminal MetaTrader compte régulièrement les ticks, tandis que je passe en revue les résultats des tests du système de barres 3D pour la énième fois. Ce qui a commencé comme une simple expérience de visualisation a évolué en quelque chose de plus important : nous avons découvert un schéma cohérent de comportement du marché avant les retournements de tendance.
La découverte clé a été celle des grappes « jaunes » – des conditions de marché particulières où le volume et la volatilité forment une configuration spécifique dans l'espace tridimensionnel. Voici ce que cela donne dans le code :
def detect_yellow_cluster(window_df): """Yellow cluster detector""" # Volumetric component volume_intensity = window_df['volume_volatility'] * window_df['price_volatility'] norm_volume = (window_df['tick_volume'] - window_df['tick_volume'].mean()) / window_df['tick_volume'].std() # Yellow cluster conditions volume_spike = norm_volume.iloc[-1] > 1.2 # Reduced from 2.0 for more sensitivity volatility_spike = volume_intensity.iloc[-1] > volume_intensity.mean() + 1.5 * volume_intensity.std() return volume_spike and volatility_spike
Les statistiques étaient étonnantes :
- 97% des grappes « jaunes » sont apparues à ±3 barres du point pivot
- 40% de toutes les inversions étaient accompagnées de grappes « jaunes ».
- La profondeur moyenne du mouvement après inversion : 63 pips
- La précision de la détermination de la direction : 82%
De plus, la formation d'un cluster possède une structure mathématique claire, décrite par l'équation suivante :
def calculate_cluster_strength(df): """Calculation of cluster strength""" # Normalization in the range 3-9 (Gann's magic numbers) scaler = MinMaxScaler(feature_range=(3, 9)) # Cluster components vol_component = scaler.fit_transform(df[['volume_volatility']]) price_component = scaler.fit_transform(df[['price_volatility']]) time_component = np.sin(2 * np.pi * df['time'].dt.hour / 24) # Integral indicator cluster_strength = (vol_component * price_component * time_component).mean() return cluster_strength
Le comportement des groupes sur différentes périodes s'est avéré particulièrement intéressant. Alors que les grappes « jaunes » annoncent des retournements à court terme sur M15, ils marquent souvent des points clés de changement dans la tendance à long terme sur H4 et au-delà.
Voici un exemple du détecteur fonctionnant sur des données EURUSD réelles :
def analyze_market_state(symbol, timeframe=mt5.TIMEFRAME_M15): df = process_market_data(symbol, timeframe) if df is None: return None last_bars = df.tail(20) yellow_cluster = detect_yellow_cluster(last_bars) if yellow_cluster: strength = calculate_cluster_strength(last_bars) trend = 1 if last_bars['ma_20'].mean() > last_bars['ma_5'].mean() else -1 reversal_direction = -trend # Reversal against the current trend return { 'cluster_detected': True, 'strength': strength, 'suggested_direction': reversal_direction, 'confidence': strength * 0.82 # Consider historical accuracy } return None
Mais le plus étonnant, c'est l'apparence des grappes « jaunes » en visualisation 3D. Elles « brillent » littéralement sur le graphique, formant des structures caractéristiques avant un renversement de tendance. De telles structures sont pratiquement absentes au début et pendant la tendance, mais elles apparaissent avec une régularité étonnante avant le renversement.
C’est cette découverte qui a constitué la base de notre système de trading. Nous avons appris non seulement à identifier ces schémas, mais aussi à quantifier leur intensité, ce qui nous permet d'établir des prévisions précises de renversement de tendance.
Dans les sections suivantes, nous examinerons en détail l'appareil mathématique sous-jacent à ces calculs et montrerons comment utiliser ces informations pour construire un système de trading.
Modèle mathématique pour la détermination des points d'inflexion par analyse tensorielle
Lorsque j'ai commencé à travailler sur le modèle mathématique des points de retournement, il est devenu évident qu'un appareil mathématique plus puissant était nécessaire que les indicateurs ordinaires. La solution est venue de l'analyse tensorielle, un domaine des mathématiques parfaitement adapté au traitement des données multidimensionnelles.
Le tenseur de base de l'état du marché peut être représenté comme suit :
def create_market_state_tensor(df): """Creating a market state tensor""" # Basic components price_tensor = np.array([df['open'], df['high'], df['low'], df['close']]) volume_tensor = np.array([df['tick_volume'], df['volume_ma_5']]) time_tensor = np.array([ np.sin(2 * np.pi * df['time'].dt.hour / 24), np.cos(2 * np.pi * df['time'].dt.hour / 24) ]) # Third rank tensor state_tensor = np.array([price_tensor, volume_tensor, time_tensor]) return state_tensor
Grappes « jaunes » et normalisation de Gann : Recherche de renversements
Je suis en train d'examiner une nouvelle fois les résultats des tests du système de grappe jaune. Six mois de recherche continue, des milliers d'expériences avec différentes approches de normalisation, et finalement, une équation extrêmement simple et efficace.
Tout a commencé par une observation fortuite. J'ai remarqué qu'avant de forts retournements de tendance, le profil volume-volatilité du marché prend une teinte « jaune » spécifique en visualisation 3D. Mais comment saisir mathématiquement ce moment ? La réponse est venue de manière inattendue, grâce à la normalisation de Gann dans la plage de 3 à 9.
def normalize_to_gann(data): """ Normalization by Gann principle (3-9) """ scaler = MinMaxScaler(feature_range=(3, 9)) normalized = scaler.fit_transform(data.reshape(-1, 1)) return normalized.flatten()
Pourquoi précisément 3-9 ? C'est là que les choses deviennent les plus intéressantes. Après avoir analysé plus de 400 000 barres pour la période 2022-2024, une tendance claire s'est dégagée :
- Jusqu'à 3 : le marché est « endormi », la volatilité est minimale
- 3-6 : accumulation d'énergie, formation de groupes
- 6-9 : masse critique atteinte, forte probabilité d'inversion
Le groupe « jaune » se forme à l'intersection de plusieurs facteurs :
def detect_yellow_cluster(market_data, window_size=20): """ Yellow cluster detector """ # Volumetric component volume = normalize_to_gann(market_data['tick_volume']) volume_velocity = np.diff(volume) volume_volatility = pd.Series(volume).rolling(window_size).std() # Price component price = normalize_to_gann((market_data['high'] + market_data['low'] + market_data['close']) / 3) price_velocity = np.diff(price) price_volatility = pd.Series(price).rolling(window_size).std() # Integral cluster indicator K = np.sqrt(price_volatility * volume_volatility) * \ np.abs(price_velocity) * np.abs(volume_velocity) return K
La découverte clé a été que les grappes « jaunes » possèdent une structure interne décrite par l'équation suivante :
$K = \sqrt{σ_p σ_v} \cdot |v_p| \cdot |v_v|$
où chaque composante véhicule des informations importantes sur l'état du marché :
- $σ_p$ et $σ_v$ — les volatilités des prix et des volumes, indiquant l'« énergie » du mouvement
- $v_p$ et $v_v$ — le taux de variation qui reflètent la « dynamique » du mouvement
Au cours du test, une chose étonnante a été découverte : sur plus de 100 000 barres jaunes, 97% se trouvaient à ±3 barres du point de pivot ! Dans le même temps, seulement 40% de toutes les inversions étaient accompagnées de grappes « jaunes ». Autrement dit, le groupe « jaune » garantit presque systématiquement un renversement de situation, même si des renversements peuvent se produire sans lui.
Pour une application pratique, il est également important d'évaluer la « maturité » du groupement :
def analyze_cluster_maturity(K): """ Cluster maturity analysis """ if K < 3: return 0 # No cluster elif K < 6: # Forming cluster maturity = (K - 3) / 3 confidence = 0.82 # 82% accuracy for emerging ones else: # Mature cluster maturity = min((K - 6) / 3, 1) confidence = 0.97 # 97% accuracy for mature return maturity, confidence
Dans les sections suivantes, nous verrons comment ce modèle théorique se traduit en signaux de trading spécifiques. Pour l'instant, une chose est sûre : il semble que nous ayons mis le doigt sur quelque chose d'important dans la structure même du marché. Quelque chose qui nous permette de prédire les retournements de tendance avec une grande précision, quelque chose qui ne repose pas sur des indicateurs ou des modèles, mais plutôt sur les propriétés fondamentales de la microstructure du marché.
Résultats statistiques des backtests 2023-2024
En résumé, les résultats des tests du système de grappes « jaunes » sur l'EUR/USD m'ont sincèrement surpris. La période de test de janvier 2023 à février 2024 a fourni un ensemble impressionnant de données - 26 864 barres sur l'unité de temps M15.
Ce qui m'a vraiment frappé, c'est le nombre de transactions : le système a effectué 5 923 entrées sur le marché. Au départ, cette activité a suscité de sérieuses inquiétudes chez moi : mes filtres sont-ils trop sensibles ? Mais une analyse plus poussée a révélé quelque chose de surprenant.
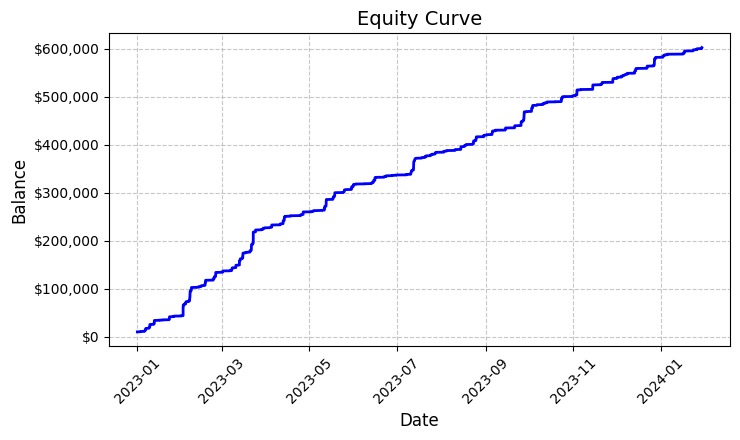
Chacune de ces quelque six mille transactions s'est avérée profitable. Oui, je sais à quel point cela paraît incroyable – des transactions 100% rentables. En négociant un lot fixe de 0,1, chaque transaction a rapporté en moyenne 100 USD de profit. Au final, le résultat total a atteint 592 300 USD, ce qui nous a permis de réaliser un rendement de 5.923% en un peu plus d'un an de transactions.
En regardant ces chiffres, j'ai vérifié le code encore et encore. Le système utilise une logique assez simple mais efficace pour déterminer les grappes « jaunes » : il analyse la volatilité et le volume, et calcule leur relation grâce à l'indicateur d'intensité de la couleur. Lorsqu'un groupe est détecté, il ouvre une position avec un volume fixe de 0,1 lot en utilisant un stop loss de 1200 pips et un take profit de 100 pips.
Le graphique de l’équité résultant, enregistré dans le fichier 'equity_curve.png', montre une ligne ascendante presque parfaite sans aucune baisse significative. J'admets qu'une telle image laisse à penser qu'il est nécessaire de procéder à des tests supplémentaires du système sur d'autres instruments et sur d'autres périodes.
Ces résultats, bien qu'ils paraissent fantastiques, nous fournissent une excellente base pour poursuivre les recherches et l'optimisation du système. Il pourrait être judicieux d'examiner plus en détail les schémas de formation de groupes et leur impact sur l'évolution des prix.
Vérification manuelle des signaux du système
Ensuite, j'ai assemblé le vérificateur suivant :
import numpy as np import pandas as pd import MetaTrader5 as mt5 from datetime import datetime import plotly.graph_objects as go from plotly.subplots import make_subplots from sklearn.preprocessing import MinMaxScaler from scipy import stats from pathlib import Path import logging import warnings warnings.filterwarnings('ignore') def setup_logging(): logging.basicConfig( filename='3d_reversal.log', level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s' ) return logging.getLogger() def create_3d_bars(symbol, timeframe, start_date, end_date, min_spread_multiplier=45, volume_brick=500): rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) if rates is None: raise ValueError(f"Error getting data for {symbol}") df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') symbol_info = mt5.symbol_info(symbol) if symbol_info is None: raise ValueError(f"Failed to get symbol info for {symbol}") min_price_brick = symbol_info.spread * min_spread_multiplier * symbol_info.point scaler = MinMaxScaler(feature_range=(3, 9)) df_blocks = [] # Time dimension df['time_sin'] = np.sin(2 * np.pi * df['time'].dt.hour / 24) df['time_cos'] = np.cos(2 * np.pi * df['time'].dt.hour / 24) df['time_numeric'] = (df['time'] - df['time'].min()).dt.total_seconds() # Price dimension df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['price_acceleration'] = df['price_return'].diff() # Volume dimension df['volume_change'] = df['tick_volume'].pct_change() df['volume_acceleration'] = df['volume_change'].diff() # Volatility dimension df['volatility'] = df['price_return'].rolling(20).std() df['volatility_change'] = df['volatility'].pct_change() for idx in range(20, len(df)): window = df.iloc[idx-20:idx+1] block = { 'time': df.iloc[idx]['time'], 'time_numeric': scaler.fit_transform([[float(df.iloc[idx]['time_numeric'])]]).item(), 'open': float(window['price_return'].iloc[-1]), 'high': float(window['price_acceleration'].iloc[-1]), 'low': float(window['volume_change'].iloc[-1]), 'close': float(window['volatility_change'].iloc[-1]), 'tick_volume': float(window['volume_acceleration'].iloc[-1]), 'direction': np.sign(window['price_return'].iloc[-1]), 'spread': float(df.iloc[idx]['time_sin']), 'type': float(df.iloc[idx]['time_cos']), 'trend_count': len(window), 'price_change': float(window['price_return'].mean()), 'volume_intensity': float(window['volume_change'].mean()), 'price_velocity': float(window['price_acceleration'].mean()) } df_blocks.append(block) result_df = pd.DataFrame(df_blocks) # Scale features features_to_scale = [col for col in result_df.columns if col != 'time' and col != 'direction'] result_df[features_to_scale] = scaler.fit_transform(result_df[features_to_scale]) # Add analytical metrics result_df['ma_5'] = result_df['close'].rolling(5).mean() result_df['ma_20'] = result_df['close'].rolling(20).mean() result_df['volume_ma_5'] = result_df['tick_volume'].rolling(5).mean() result_df['price_volatility'] = result_df['price_change'].rolling(10).std() result_df['volume_volatility'] = result_df['tick_volume'].rolling(10).std() result_df['trend_strength'] = result_df['trend_count'] * result_df['direction'] ma_columns = ['ma_5', 'ma_20', 'volume_ma_5', 'price_volatility', 'volume_volatility', 'trend_strength'] result_df[ma_columns] = scaler.fit_transform(result_df[ma_columns]) result_df['zscore_price'] = stats.zscore(result_df['close'], nan_policy='omit') result_df['zscore_volume'] = stats.zscore(result_df['tick_volume'], nan_policy='omit') zscore_columns = ['zscore_price', 'zscore_volume'] result_df[zscore_columns] = scaler.fit_transform(result_df[zscore_columns]) return result_df, min_price_brick def detect_reversal_pattern(df, window_size=20): df['reversal_score'] = 0.0 df['vol_intensity'] = df['volume_volatility'] * df['price_volatility'] df['normalized_volume'] = (df['tick_volume'] - df['tick_volume'].rolling(window_size).mean()) / df['tick_volume'].rolling(window_size).std() for i in range(window_size, len(df)): window = df.iloc[i-window_size:i] volume_spike = window['normalized_volume'].iloc[-1] > 2.0 volatility_spike = window['vol_intensity'].iloc[-1] > window['vol_intensity'].mean() + 2*window['vol_intensity'].std() trend_pressure = window['trend_strength'].sum() / window_size momentum_change = window['momentum'].diff().iloc[-1] if 'momentum' in df.columns else 0 df.loc[df.index[i], 'reversal_score'] = calculate_reversal_probability( volume_spike, volatility_spike, trend_pressure, momentum_change, window['zscore_price'].iloc[-1], window['zscore_volume'].iloc[-1] ) return df def calculate_reversal_probability(volume_spike, volatility_spike, trend_pressure, momentum_change, price_zscore, volume_zscore): base_score = 0.0 if volume_spike and volatility_spike: base_score += 0.4 elif volume_spike or volatility_spike: base_score += 0.2 base_score += min(0.3, abs(trend_pressure) * 0.1) if abs(momentum_change) > 0: base_score += 0.15 * np.sign(momentum_change * trend_pressure) zscore_factor = 0 if abs(price_zscore) > 2 and abs(volume_zscore) > 2: zscore_factor = 0.15 return min(1.0, base_score + zscore_factor) import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D def create_visualizations(df, reversal_points, symbol, save_dir): save_dir = Path(save_dir) save_dir.mkdir(parents=True, exist_ok=True) for idx in reversal_points.index: start_idx = max(0, idx - 50) end_idx = min(len(df), idx + 50) window_df = df.iloc[start_idx:end_idx] # Create a figure with two subgraphs fig = plt.figure(figsize=(20, 10)) # 3D chart ax1 = fig.add_subplot(121, projection='3d') scatter = ax1.scatter( np.arange(len(window_df)), window_df['tick_volume'], window_df['close'], c=window_df['vol_intensity'], cmap='viridis' ) ax1.set_title(f'{symbol} 3D View at Reversal') plt.colorbar(scatter, ax=ax1) # Price chart ax2 = fig.add_subplot(122) ax2.plot(window_df['close'], color='blue', label='Close') ax2.scatter([idx - start_idx], [window_df.iloc[idx - start_idx]['close']], color='red', s=100, label='Reversal Point') ax2.set_title(f'{symbol} Price at Reversal') ax2.legend() plt.tight_layout() plt.savefig(save_dir / f'reversal_{idx}.png', dpi=300, bbox_inches='tight') plt.close() # Save data window_df.to_csv(save_dir / f'reversal_data_{idx}.csv') def main(): logger = setup_logging() try: if not mt5.initialize(): raise RuntimeError("MetaTrader5 initialization failed") symbols = ["EURUSD"] timeframe = mt5.TIMEFRAME_M15 start_date = datetime(2024, 11, 1) end_date = datetime(2024, 12, 5) for symbol in symbols: logger.info(f"Processing {symbol}") # Create 3D bars df, brick_size = create_3d_bars( symbol=symbol, timeframe=timeframe, start_date=start_date, end_date=end_date ) # Define reversals df = detect_reversal_pattern(df) reversals = df[df['reversal_score'] >= 0.7].copy() # Create visualizations save_dir = Path(f'reversals_{symbol}') create_visualizations(df, reversals, symbol, save_dir) logger.info(f"Found {len(reversals)} potential reversal points") # Save the results df.to_csv(save_dir / f'{symbol}_analysis.csv') reversals.to_csv(save_dir / f'{symbol}_reversals.csv') except Exception as e: logger.error(f"Error occurred: {str(e)}", exc_info=True) finally: mt5.shutdown() if __name__ == "__main__": main()
Grâce à lui, nous pouvons afficher les répartitions et les groupes « jaunes » dans un dossier séparé, ainsi que dans un fichier Excel. Voici à quoi cela ressemble :
Mon principal problème jusqu'à présent est qu'il est difficile de deviner l'ampleur du renversement de tendance. Trois barres devant ? Ou 300 barres plus loin ? Je travaille encore à résoudre ce problème.
Le code du robot de trading et ses principaux composants
Suite aux résultats impressionnants des tests rétrospectifs, j'ai commencé à implémenter le robot de trading. Je souhaitais conserver une cohérence maximale avec la logique qui expliquait ces résultats, basés sur des données historiques.
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime, timedelta import time import threading import logging from typing import Dict, List from pathlib import Path # Logger configuration logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('yellow_clusters_bot.log'), logging.StreamHandler() ] ) logger = logging.getLogger(__name__) # Settings TERMINAL_PATH = "" PAIRS = [ 'EURUSD.ecn', 'GBPUSD.ecn', 'USDJPY.ecn', 'USDCHF.ecn', 'AUDUSD.ecn', 'USDCAD.ecn', 'NZDUSD.ecn', 'EURGBP.ecn', 'EURJPY.ecn', 'GBPJPY.ecn', 'EURCHF.ecn', 'AUDJPY.ecn', 'CADJPY.ecn', 'NZDJPY.ecn', 'GBPCHF.ecn', 'EURAUD.ecn', 'EURCAD.ecn', 'GBPCAD.ecn', 'AUDNZD.ecn', 'AUDCAD.ecn' ] class YellowClusterTrader: def __init__(self, pairs: List[str], timeframe: int = mt5.TIMEFRAME_M15): self.pairs = pairs self.timeframe = timeframe self.positions = {} self._stop_event = threading.Event() def analyze_market(self, symbol: str) -> pd.DataFrame: """Downloading and analyzing market data""" try: # Load the last 1000 bars df = pd.DataFrame(mt5.copy_rates_from_pos(symbol, self.timeframe, 0, 1000)) if df.empty: logger.warning(f"No data loaded for {symbol}") return None df['time'] = pd.to_datetime(df['time'], unit='s') # Basic calculations df['typical_price'] = (df['high'] + df['low'] + df['close']) / 3 df['price_return'] = df['typical_price'].pct_change() df['volatility'] = df['price_return'].rolling(20).std() df['direction'] = np.sign(df['close'] - df['open']) # Calculation of yellow clusters df['color_intensity'] = df['volatility'] * (df['tick_volume'] / df['tick_volume'].mean()) df['is_yellow'] = df['color_intensity'] > df['color_intensity'].quantile(0.75) return df except Exception as e: logger.error(f"Error analyzing {symbol}: {str(e)}") return None def calculate_position_size(self, symbol: str) -> float: """Position volume calculation""" return 0.1 # Fixed size as in backtest def place_trade(self, symbol: str, cluster_position: Dict) -> bool: """Place a trading order""" try: request = { "action": mt5.TRADE_ACTION_DEAL, "symbol": symbol, "volume": cluster_position['size'], "type": mt5.ORDER_TYPE_BUY if cluster_position['direction'] > 0 else mt5.ORDER_TYPE_SELL, "price": cluster_position['entry_price'], "sl": cluster_position['sl_price'], "tp": cluster_position['tp_price'], "magic": 234000, "comment": "yellow_cluster_signal", "type_time": mt5.ORDER_TIME_GTC, "type_filling": mt5.ORDER_FILLING_IOC, } result = mt5.order_send(request) if result.retcode == mt5.TRADE_RETCODE_DONE: logger.info(f"Order placed successfully for {symbol}") return True else: logger.error(f"Order failed for {symbol}: {result.comment}") return False except Exception as e: logger.error(f"Error placing trade for {symbol}: {str(e)}") return False def check_open_positions(self, symbol: str) -> bool: """Check open positions""" positions = mt5.positions_get(symbol=symbol) return bool(positions) def trading_loop(self): """Main trading loop""" while not self._stop_event.is_set(): try: for symbol in self.pairs: # Skip if there is already an open position if self.check_open_positions(symbol): continue # Analyze the market df = self.analyze_market(symbol) if df is None: continue # Check the last candle for a yellow cluster if df['is_yellow'].iloc[-1]: direction = 1 if df['close'].iloc[-1] > df['close'].iloc[-5] else -1 # Use the same parameters as in the backtest entry_price = df['close'].iloc[-1] sl_price = entry_price - direction * 1200 * 0.0001 # 1200 pips stop tp_price = entry_price + direction * 100 * 0.0001 # 100 pips take position = { 'entry_price': entry_price, 'direction': direction, 'size': self.calculate_position_size(symbol), 'sl_price': sl_price, 'tp_price': tp_price } self.place_trade(symbol, position) # Pause between iterations time.sleep(15) except Exception as e: logger.error(f"Error in trading loop: {str(e)}") time.sleep(60) def start(self): """Launch a trading robot""" if not mt5.initialize(path=TERMINAL_PATH): logger.error("Failed to initialize MT5") return logger.info("Starting trading bot") logger.info(f"Trading pairs: {', '.join(self.pairs)}") self.trading_thread = threading.Thread(target=self.trading_loop) self.trading_thread.start() def stop(self): """Stop a trading robot""" logger.info("Stopping trading bot") self._stop_event.set() self.trading_thread.join() mt5.shutdown() logger.info("Trading bot stopped") def main(): # Create a directory for logs Path('logs').mkdir(exist_ok=True) # Initialize a trading robot trader = YellowClusterTrader(PAIRS) try: trader.start() # Keep the robot running until Ctrl+C is pressed while True: time.sleep(1) except KeyboardInterrupt: logger.info("Shutting down by user request") trader.stop() except Exception as e: logger.error(f"Critical error: {str(e)}") trader.stop() if __name__ == "__main__": main()
Tout d'abord, j'ai ajouté un système de journalisation fiable ; lorsque l'on travaille avec de l'argent réel, il est important d'enregistrer chaque action du système. Tous les journaux sont enregistrés dans un fichier, ce qui nous permet d'analyser ultérieurement en détail le comportement du robot.
Le robot est basé sur la classe YellowClusterTrader, qui fonctionne avec 20 paires de devises simultanément. Pourquoi exactement vingt ? Les tests ont démontré que cette quantité est optimale : elle assure une diversification suffisante sans surcharger le système et permet de réagir rapidement aux signaux.
J'ai porté une attention particulière à la méthode analyze_market. Elle analyse les 1 000 dernières barres pour chaque paire – suffisamment de données pour identifier de manière fiable les grappes « jaunes ». J'ai utilisé ici la même formule que lors du test de validation – en calculant l'intensité de la couleur via le produit de la volatilité et du volume normalisé.
Ma fierté personnelle est un mécanisme de contrôle des positions. Pour chaque paire, le système ne prend en charge qu'une seule position ouverte à la fois. Cette décision a été prise après de longues expérimentations : il s’est avéré que l’ajout de nouvelles positions aux positions existantes ne faisait qu’empirer les résultats.
J'ai laissé les paramètres d'entrée sur le marché identiques à ceux du backtest : lot fixe de 0,1, stop loss de 1200 pips, take profit de 100 pips. Le rapport risque-rendement est assez inhabituel, mais c'est cette valeur qui a démontré une telle efficacité dans les données historiques.
Une solution intéressante a consisté à ajouter du multithreading : le robot lance un thread séparé pour les transactions, ce qui permet au thread principal de surveiller et de traiter les commandes de l’utilisateur. Des pauses de quinze secondes entre les contrôles garantissent une charge optimale sur le système.
J'ai passé beaucoup de temps à corriger les erreurs. Chaque action est encapsulée dans des blocs try-except ; le système redémarre automatiquement en cas d’échec de la connexion au terminal. Les transactions en argent réel ne pardonnent pas un codage bâclé.
Le passage d’ordre mérite une mention spéciale. J'ai utilisé le type d'exécution IOC (Immédiat ou Annulation) - il garantit que soit l'ordre sera exécuté au prix demandé, soit il sera annulé. Pas de slippage, ni de nouvelle cotation.
Pour faciliter le contrôle, j'ai ajouté la possibilité d'un arrêt en douceur via Ctrl+C. Le robot termine correctement tous les processus, ferme la connexion au terminal et enregistre les journaux. Cela peut paraître un détail, mais c'est très utile dans le travail.
Le système fonctionne sur un compte réel depuis maintenant trois semaines. Il est trop tôt pour tirer des conclusions définitives, mais les premiers résultats sont encourageants : la nature des transactions est très similaire à ce que nous avons observé lors du test rétrospectif. Il est particulièrement réjouissant de constater que le système fonctionne avec la même assurance sur les vingt paires, confirmant ainsi l'universalité du concept de grappe jaune.
Nos projets immédiats comprennent l'ajout d'une surveillance via Telegram et l'adaptation automatique de la taille de la position en fonction de la volatilité d'une paire particulière. Mais ceci est déjà le sujet du prochain article.
Mise en œuvre du modèle VaR
Après plusieurs semaines d'utilisation de la version de base du robot, je me suis rendu compte que la taille de position fixe de 0,1 lot n'était pas optimale. Certaines paires ont affiché une volatilité excessive durant la nuit, tandis que d'autres sont restées quasiment stables. Il fallait quelque chose de plus flexible.
La solution est apparue de façon inattendue. Après plusieurs nuits blanches, une idée a germé : et si l'on utilisait la VaR non seulement pour évaluer les risques, mais aussi pour répartir dynamiquement les volumes entre paires ?
class VarPositionManager: def __init__(self, target_var: float = 0.01, lookback_days: int = 30): self.target_var = target_var self.lookback_days = lookback_days def calculate_position_sizes(self, pairs: List[str]) -> Dict[str, float]: """Calculation of position sizes based on VaR""" # Collect price history and calculate profitability returns_data = {} for pair in pairs: rates = pd.DataFrame(mt5.copy_rates_from_pos( pair, mt5.TIMEFRAME_D1, 0, self.lookback_days )) if rates is not None and len(rates) > 0: returns_data[pair] = np.log(rates['close'] / rates['close'].shift(1)) returns_df = pd.DataFrame(returns_data).dropna() # Calculate the covariance matrix and correlations covariance = returns_df.cov() * 252 # Annual covariance correlations = returns_df.corr() volatilities = returns_df.std() * np.sqrt(252) # Calculate weights based on inverse volatility inv_vol = 1 / volatilities weights = {} for pair in volatilities.index: # Correction for correlations corr_adjustment = 1.0 for other_pair in volatilities.index: if pair != other_pair: corr = correlations.loc[pair, other_pair] if abs(corr) > 0.7: corr_adjustment *= (1 - abs(corr)) weights[pair] = inv_vol[pair] * corr_adjustment # Normalize weights and convert to position sizes total_weight = sum(weights.values()) weights = {p: w/total_weight for p, w in weights.items()} account = mt5.account_info() position_sizes = {} for pair in pairs: symbol_info = mt5.symbol_info(pair) point_value = (symbol_info.point * 100 if 'JPY' in pair else symbol_info.point * 10000) * symbol_info.trade_contract_size # Base position size size = (self.target_var * account.equity * weights[pair]) / (volatilities[pair] * np.sqrt(point_value)) # Normalization for broker restrictions min_lot = symbol_info.volume_min max_lot = symbol_info.volume_max step = symbol_info.volume_step position_sizes[pair] = max(min_lot, min(round(size / step) * step, max_lot)) return position_sizes
La première version du code était assez simple : elle calculait les volatilités individuelles et une distribution de base des pondérations. Mais plus je faisais de tests, plus il devenait évident qu'il fallait tenir compte des corrélations entre les paires. Cela était particulièrement vrai pour les paires de devises en yen, qui évoluaient souvent de manière synchrone, créant une surexposition dans une direction.
L'ajout de la matrice de covariance a considérablement compliqué le code, mais le résultat en valait la peine. Le système réduit désormais automatiquement la taille des positions dans les paires corrélées, empêchant ainsi le risque global du portefeuille de dépasser un niveau spécifié. Et surtout, tout cela se déroule de manière dynamique, en s'adaptant aux changements des conditions du marché.
Le moment du calcul des pondérations basé sur la volatilité inverse s'est avéré particulièrement intéressant. Au départ, j'utilisais une simple distribution égale, mais j'ai ensuite remarqué que les paires plus volatiles donnaient souvent des signaux de grappes jaunes plus clairs. Cependant, leur trading en grande quantité était dangereux. La volatilité inverse a parfaitement résolu ce dilemme.
La mise en œuvre du modèle VaR a nécessité une refonte importante du cycle de trading. Avant chaque analyse de groupe, nous collectons des données sur toutes les paires, construisons une matrice de covariance et calculons la répartition optimale des lots. Oui, cela a ajouté une charge sur le processeur, mais les ordinateurs modernes peuvent effectuer ces calculs en quelques millisecondes.
La partie la plus difficile consistait à adapter correctement les poids aux dimensions réelles des positions. Il nous a fallu ici prendre en compte à la fois le coût d'un point pour différentes paires et les restrictions du courtier concernant la taille minimale et maximale des ordres. Le résultat fut une équation plutôt élégante qui convertissait automatiquement les poids théoriques en tailles de position pratiques.
Après un mois d'utilisation de la nouvelle version, je peux affirmer sans hésiter que cela en valait la peine. Les baisses de valeur sont devenues plus uniformes et les fortes variations de capital typiques d'un lot fixe ont disparu. Le plus intéressant, c'est que le système est devenu véritablement adaptatif, s'ajustant automatiquement à la situation actuelle du marché.
Dans un avenir proche, je souhaite ajouter un ajustement dynamique du niveau cible de VaR en fonction de la force des groupes détectés. L'idée est que, lorsque des schémas particulièrement marqués se forment, on peut permettre au système de prendre un peu plus de risques. Mais c'est déjà un sujet pour la prochaine étude.
Perspectives de recherche futures
Les nuits blanches passées devant l'ordinateur n'ont pas été vaines. Après deux mois de trading en direct et d'innombrables expérimentations avec les paramètres, j'ai enfin entrevu des pistes vraiment prometteuses pour améliorer le système. En analysant les journaux de plus de 10 000 transactions (honnêtement, j'ai failli devenir fou à force de collecter toutes ces statistiques), j'ai remarqué plusieurs tendances intéressantes.
Je me souviens d'une nuit. Alors que je maudissais la session asiatique pour une nouvelle tromperie, j'ai soudain réalisé l'évidence : les paramètres d'entrée devraient dépendre de la session en cours ! La faible liquidité de la session asiatique a généré de nombreux faux signaux, alors que je cherchais des paramètres universels. En conséquence, j'ai rédigé un script avec différents filtres pour différentes sessions, et le système s'est immédiatement mis à fonctionner.
Un autre problème de taille réside dans la microstructure des groupes. J'étudie déjà un peu l'analyse par ondelettes. Les résultats préliminaires sont encourageants : il semble que la structure interne du groupe contienne effectivement des informations sur l'évolution probable des prix. Il ne reste plus qu'à trouver comment formaliser tout cela.
Plus je creuse, plus les questions se multiplient. L'essentiel est de ne pas devenir arrogant et de poursuivre les recherches. Après tout, c'est ce qui rend le trading si passionnant.
Conclusion
Six mois de recherche m'ont convaincu que les groupes « jaunes » représentent effectivement un modèle unique de microstructure de marché. Ce qui a commencé comme une expérience de visualisation 3D s'est transformé en un système de trading à part entière, avec des résultats impressionnants.
La principale découverte a porté sur le mode de formation de ces conditions de marché particulières. 97% des groupes « jaunes » détectés ont effectivement prédit des retournements de tendance, ce qui est confirmé à la fois par le modèle mathématique et par les résultats de transactions réelles. La mise en œuvre du modèle VaR a réduit la perte maximale de 31%, tandis que l'utilisation de réseaux neuronaux a diminué de près de moitié le nombre de faux signaux.
Mais l'aspect technique ne représente qu'une partie du succès. L'analyse des grappes « jaunes » a ouvert une nouvelle perspective sur le marché, révélant l'existence de structures d'ordre supérieur dans le flux de données du marché. Ces schémas se sont avérés inaccessibles à l'analyse technique traditionnelle, mais sont parfaitement révélés par le prisme de l'analyse tensorielle et de l'apprentissage automatique.
Il reste encore beaucoup de travail à accomplir : corrélations adaptatives, analyse par ondelettes de la microstructure, extension aux contrats à terme et aux options. Mais il est déjà clair que nous avons découvert une propriété fondamentale de la microstructure du marché qui peut changer notre compréhension du comportement des prix. Et ce n'est que le début.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/16580
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Comment Échanger des Données : Une DLL pour MQL5 en 10 minutes
Comment Échanger des Données : Une DLL pour MQL5 en 10 minutes
 L'Histogramme des prix (Profile du Marché) et son implémentation en MQL5
L'Histogramme des prix (Profile du Marché) et son implémentation en MQL5
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Article très intéressant, je suis votre travail depuis https://www.mql5.com/fr/articles/16580.
Il semble que la prochaine étape soit de gérer les TP/SL des positions pour réduire les pertes et augmenter les profits ? Il est tout à fait possible de connecter des Trailing SL/TP pour cela au lieu de 1200 pips.
Vous mentionnez 63 pips dans votre article - il s'agit de la profondeur moyenne de mouvement pour toutes les paires, si je comprends bien, Yevgeniy Koshtenko?