Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 1258
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
eine Vielzahl von Formeln ((
Nun ) gibt es einen Link zum R-Paket. Ich selbst verwende R nicht, aber ich verstehe die Formeln.
wenn Sie R verwenden, probieren Sie es aus)
Nun ) gibt es einen Link zum R-Paket. Ich selbst verwende R nicht, aber ich verstehe die Formeln.
Wenn Sie R verwenden, probieren Sie es aus)
Der Artikel von heute Morgen ist noch offen: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
Die enttäuschendste Tatsache ist, dass ich keine Python-Implementierung dieses Algorithmus finden konnte. Die Autoren erstellten ein R-Paket(BayesTrees), das einige offensichtliche Probleme aufwies - vor allem das Fehlen einer "Vorhersage"-Funktion - und es wurde eine andere, weiter verbreitete Implementierung namens bartMachine erstellt.
Wenn Sie Erfahrung mit der Implementierung dieser Technik haben oder eine Python-Bibliothek kennen, hinterlassen Sie bitte einen Link in den Kommentaren!
Das erste Paket ist also nutzlos, weil es keine Vorhersagen treffen kann.
Der zweite Link enthält wieder Formeln.
Hier ist ein gewöhnlicher Baum, der leicht zu verstehen ist. Alles ist einfach und logisch. Und das ohne Formeln.
Vielleicht bin ich noch nicht bei den Libs angelangt. Bäume sind nur ein Spezialfall eines großen Bayes'schen Themas, z.B. gibt es hier viele Beispiele von Büchern und Videos
Ich habe die Bayes'sche Optimierung der NS-Hyperparameter gemäß Vladimirs Artikel verwendet. Das funktioniert gut.Wie welche Bäume... Es gibt Bayes'sche neuronale Netze
Unerwartet!
NS arbeitet mit den mathematischen Operationen + und * und kann beliebige Indikatoren in sich selbst konstruieren, von MA bis zu digitalen Filtern.
Bäume werden jedoch durch einfache if(x<v){linker Zweig}else{rechter Zweig} in einen rechten und einen linken Teil unterteilt.
Oder ist es auch if(x<v){linker Zweig}else{rechter Zweig}?
Aber wenn es viele Variablen zu optimieren gibt, ist es sehr lang.
Unerwartet!
NS arbeiten mit den mathematischen Operationen + und * und können darin beliebige Indikatoren konstruieren - von MA bis zu digitalen Filtern.
Bäume werden durch einfache if(x<v){linker Zweig}else{rechter Zweig} in einen rechten und einen linken Teil unterteilt.
Oder ist baisian NS auch if(x<v){linker Zweig}else{rechter Zweig}?
es ist, ja, langsam, so ziehen von dort nützliches Wissen so weit, gibt ein Verständnis für einige Dinge
Nein, im Bayes'schen NS werden die Gewichte einfach durch Stichproben aus den Verteilungen optimiert, und die Ausgabe ist ebenfalls eine Verteilung, die eine Reihe von Auswahlmöglichkeiten enthält, aber einen Mittelwert, eine Varianz usw. hat. Mit anderen Worten, es werden viele Varianten erfasst, die eigentlich nicht im Trainingsdatensatz enthalten sind, die aber a priori angenommen werden. Je mehr Stichproben in ein solches NS eingespeist werden, desto eher konvergiert es zu einem regulären NS, d.h. Bayes'sche Ansätze sind zunächst für nicht sehr große Datensätze geeignet. Das ist das, was ich bis jetzt weiß.
D.h. solche NS benötigen keine sehr großen Datensätze, die Ergebnisse werden zu den konventionellen konvergieren. Die Ausgabe nach dem Training ist jedoch keine Punktschätzung, sondern eine Wahrscheinlichkeitsverteilung für jede Stichprobe.
es ist langsam, deshalb ziehe ich bisher einige nützliche Erkenntnisse daraus, es vermittelt ein Verständnis für einige Dinge
Nein, im Bayes'schen NS werden die Gewichte einfach durch Stichproben aus den Verteilungen optimiert, und die Ausgabe ist ebenfalls eine Verteilung, die eine Reihe von Auswahlmöglichkeiten enthält, aber einen Mittelwert, eine Varianz usw. hat. Mit anderen Worten, es werden viele Varianten erfasst, die eigentlich nicht im Trainingsdatensatz enthalten sind, die aber a priori angenommen werden. Je mehr Stichproben in ein solches NS eingespeist werden, desto mehr nähert es sich einem regulären NS an, d. h. Bayes'sche Ansätze eignen sich zunächst für nicht sehr große Datensätze. Das ist das, was ich bis jetzt weiß.
D.h. solche NS benötigen keine sehr großen Datensätze, die Ergebnisse konvergieren zu den herkömmlichen. Die Ausgabe nach dem Training wird jedoch keine Punktschätzung sein, sondern eine Wahrscheinlichkeitsverteilung für jede Stichprobe.
Du rennst herum wie auf Speed, eine Sache nach der anderen, eine Sache nach der anderen... und es ist sinnlos.
Sie scheinen viel Freizeit zu haben, wie mancher Gentleman müssen Sie arbeiten, hart arbeiten und sich um eine berufliche Weiterentwicklung bemühen, anstatt von neuronalen Netzen zu den Grundlagen zu eilen.
Glauben Sie mir, niemand bei einem normalen Maklerhaus wird Ihnen Geld für wissenschaftliches Geschwafel oder Artikel geben, sondern nur für Aktien, die von den besten Maklern der Welt bestätigt wurden.Ich habe es nicht eilig, aber ich lerne konsequent von einfach bis komplex
Wenn Sie keinen Job haben, kann ich Ihnen zum Beispiel anbieten, etwas in mql umzuschreiben.
Ich arbeite für den Vermieter wie jeder andere auch, es ist seltsam, dass du nicht arbeitest, du bist selbst ein Vermieter, ein Erbe, ein Goldjunge, ein normaler Mann, wenn er seinen Job in drei Monaten auf der Straße verliert, ist er in sechs Monaten tot.
Wenn es überhaupt nichts über MO im Handel gibt, dann gehen Sie spazieren, Sie werden denken, Sie sind die einzigen Bettler hier)
Ich zeigte ihnen alle in IR, ehrlich, keine kindischen Geheimnisse, kein Bullshit, der Fehler im Test ist 10-15%, aber der Markt ändert sich ständig, der Handel nicht geht, Chatter nahe Null
Kurzum, geh weg, Vasya, ich bin nicht am Jammern interessiert.
Alles, was Sie tun, ist Jammern, keine Ergebnisse, Sie graben Gabeln im Wasser und das war's, aber Sie haben nicht den Mut zuzugeben, dass Sie Ihre Zeit verschwenden
Du solltest zur Armee gehen oder zumindest auf einer Baustelle mit Männern arbeiten, das würde deinen Charakter verbessern.es ist langsam, deshalb ziehe ich bisher einige nützliche Erkenntnisse daraus, es vermittelt ein Verständnis für einige Dinge
Nein, im Bayes'schen NS werden die Gewichte einfach durch Stichproben aus den Verteilungen optimiert, und die Ausgabe ist ebenfalls eine Verteilung, die eine Reihe von Auswahlmöglichkeiten enthält, aber einen Mittelwert, eine Varianz usw. hat. Mit anderen Worten, es werden viele Varianten erfasst, die eigentlich nicht im Trainingsdatensatz enthalten sind, die aber a priori angenommen werden. Je mehr Stichproben in ein solches NS eingespeist werden, desto eher konvergiert es zu einem regulären NS, d.h. Bayes'sche Ansätze sind zunächst für nicht sehr große Datensätze geeignet. Das ist das, was ich bis jetzt weiß.
D.h. solche NS brauchen keine sehr großen Datensätze, die Ergebnisse werden zu den konventionellen konvergieren.
Hier ist von https://www.mql5.com/ru/forum/226219 Kommentare zu Vladimirs Artikel über Bayes'sche Optimierung, wie sie die Kurve über mehrere Punkte aufzeichnet. Aber dann brauchen sie auch keine NS/Wälder - man kann die Antwort einfach in dieser Kurve suchen.
Ein weiteres Problem: Wenn ein Optimierer nicht lernt, wird er NS unverständlichen Unsinn beibringen.
 Probe gelehrt
Probe gelehrt 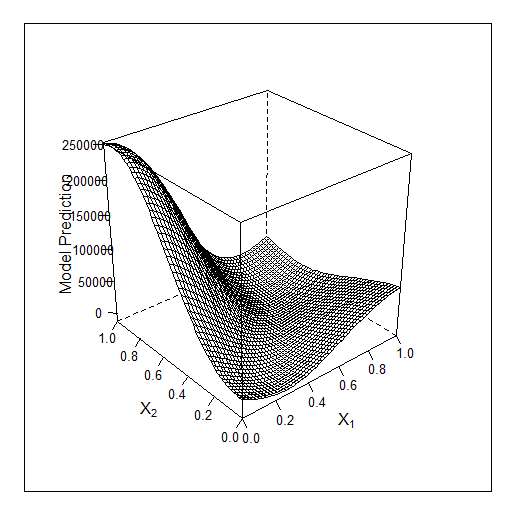
Hier für 3 Merkmale Bayes Arbeit
Es sind die Idioten in diesem Thread, die den Spaß daran verderben.
vor sich hin jammern.
Was gibt es da zu besprechen? Sie sammeln nur Links und verschiedene wissenschaftliche Zusammenfassungen, um die Neulinge zu beeindrucken, SanSanych hat alles in seinem Artikel geschrieben, es gibt nicht viel hinzuzufügen, jetzt gibt es verschiedene Verkäufer und Artikelschreiber, die alles mit ihren Mistgabeln in Scham und Abscheu beschmiert haben. Sie nennen sich "Mathematiker", sie nennen sich "Quanten" .....
Möchten Sie Mathematik versuchen, diesehttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf zu lesen?
Und Sie werden nicht verstehen, dass Sie kein Mathematiker sind, sondern ein Spinner.