Что такое обучение? - страница 23
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Идея:
Вот такой вот простой способ можно реализовать из 3-х нейронов:
Такое вряд ли можно реализовать в классическом обучении, но для тестера МТ5 - само то перебирать.
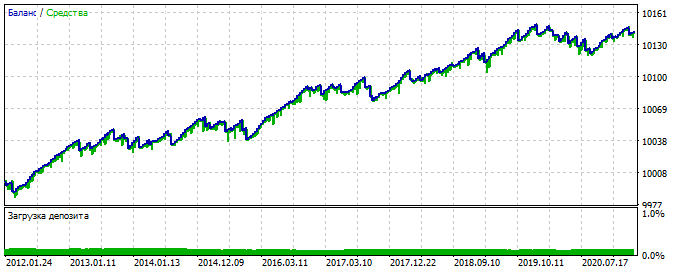
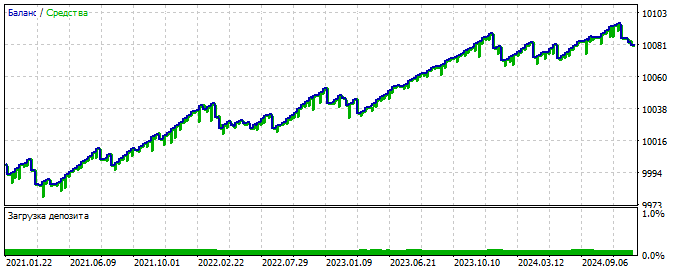
В качестве примера:
на вход 20 значений нормированных цен закрытия
коэффициент ТП 0.003 (выходное число прибавляется к цене Bid при бай и отнимается при сел)
коэффициент СЛ 0.01 (выходное число отнимается от цены Ask при бай и прибавляется при сел)
риск-ревард ТП:СЛ равен 1:3
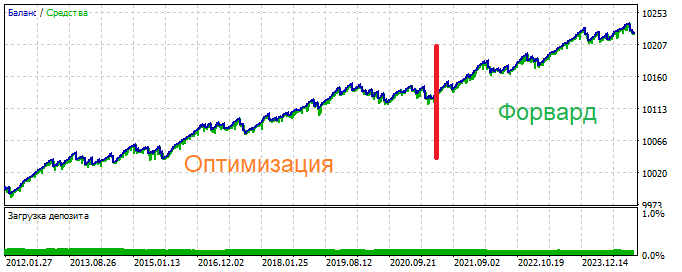
Оптимизация
Форвард
Общая
Идея:
Очень интересно.
Форум по трейдингу, автоматическим торговым системам и тестированию торговых стратегий
Обсуждение статьи "Советник на базе универсального аппроксиматора MLP"
Eric Ruvalcaba, 2025.08.05 20:49
Большое спасибо за статью и понимание. Отличная идея. Я реализовал некоторые независимые операции с позициями и заставил их работать на хеджирующем счете (мой брокер).
Вы лучшие.
Очень интересно.
Жаль, что не раскрывает, куда копать
И, главное, чтобы такие же результаты были на других участках.
Жаль, что не раскрывает, куда копать
И, главное, чтобы такие же результаты были на других участках.
У меня первый раз не получилось. Толи долго грузил, толи результатов не было.
Надо будет повторить.
И попробовать свои входы
Выявление паттернов:
1) Разделение графика цены (и не только) на участки и дальнейшее их изучение.
2) На примере выше - выявление похожих паттернов (мечта для ручных трейдеров-новичков, которые сталкиваются со сложностью поиска общеизвестных ДЦ-паттернов или паттернов, где наставники не могут объяснить, как они их отмечают).
В голову сразу налетели мысли, как куда кого прикрутить, как повертеть это всё. В общем, крайне интересное поле для исследований и ковыряний во всем этом.
UPD
На примере выше самоорганизующиеся карты Кохонена. Но видов кластеризации куда больше.
Позитивный эффект недообучения.
Как известно, переобучение в нейросетях - это переход от обобщения примеров к их поголовному запоминанию.Но если наоборот - недообучить нейросеть, то на форварде она иногда может давать обратный эффект: сглаживает баланс.
Причём, чем злостнее ошибка потерь, тем эффективней. Предполагаю, что такое будет действовать только там, где нет никаких закономерностей, а просто действует эффект накопления нерабочих паттернов, которые стремятся на дистанции "отработать" свои 50 на 50: то есть, на обучаемом участке мы намеренно "кошмарим" нейросеть, чтобы на форварде она статистически "выровнялась". Нейросеть как будто становится "слепой" к шуму. Этакая экстремальная версия регуляризации: сеть не успевает "запомнить" даже шум, оставаясь в зоне максимальной неопределённости, что в условиях хаоса работает как стабилизатор.
Использовал обычную MLP на питоне, количесво эпох от 1 до 3, или до 10-ти. То есть совсем немного.
Данная нейросеть выступала в качестве фильтра для уже имеющейся простой, но грубой торговой стратегии:
Вот так её форвард выглядит в оригинале (без фильтра НС):
А вот так с фильтром, если обучить на 1-3 эпохах с самой "лёгкой" архитектурой и большой ошибкой обучения:
Об эталонном срезе
Ни одна модель машинного обучения (в том виде, в каком она обычно применяется к финансовым рынкам) не демонстрирует устойчивой, надёжной, прибыльной работы в реальном времени на форексе или других ликвидных рынках. Давайте оговорюсь: ни одна модель в публичном доступе.