Discussão do artigo "Estimativa da densidade de Kernel da função de densidade de probabilidade desconhecida"
Para o autor. Resultados ainda melhores são obtidos se estimarmos não a densidade da distribuição, mas a função de distribuição, ou seja, a integral da densidade: em primeiro lugar, é mais fácil construí-la com base nos dados e, como ela é sempre não decrescente e limitada entre 0 e 1, a sensibilidade à escolha do algoritmo de suavização, seja ele kernel, spline, regressão ou qualquer outro, é muito menor. Os requisitos sobre a quantidade de dados disponíveis também são reduzidos, e em uma ordem de magnitude.
Bem, a densidade pode ser facilmente obtida por diferenciação numérica, se necessário.
Bem, a densidade pode ser facilmente obtida por diferenciação numérica, se necessário.
Talvez. Não posso dizer nada sobre isso. Nem mesmo tentei avaliar o pdf por meio do cdf . Provavelmente, o preconceito de que o uso da diferenciação exigiria um aumento significativo na precisão da estimativa do cdf funcionou. Além disso, não encontrei nenhuma publicação que avaliasse o método cdf->pdf ou que o comparasse com outros métodos. Se você puder compartilhar links, ficarei grato.
A ideia original era não usar nenhuma ferramenta externa, ou seja, supunha-se que tudo deveria ser implementado apenas por ferramentas MQL5.
Essa é a ideia de todos os inventores de bicicletas, sem exceção.
Veja o que os pacotes correspondentes têm a esse respeito e compare com o que você forneceu - uma quantidade infinitesimal do que é necessário ao aplicar a estatística e a econometria na negociação.
Talvez. Não posso dizer nada sobre isso. Nem mesmo tentei estimar o pdf por meio do cdf . Muito provavelmente, o preconceito de que o uso da diferenciação exigiria um aumento significativo na precisão da estimativa do cdf funcionou. Além disso, não encontrei nenhuma publicação que avaliasse o método cdf->pdf ou que o comparasse com outros métodos. Se você compartilhar links, ficarei grato.
Não posso fornecer referências porque não as tenho. Em vez disso, farei estas considerações.
Ao avaliar um pdf diretamente, temos que dividir o domínio da definição em intervalos com antecedência, e há dois problemas: primeiro, não sabemos em quantos intervalos é melhor dividir o domínio e, segundo, não sabemos que tipo de grade(uniforme, ... ?) seria melhor. E se a segunda pergunta as pessoas ainda tentaram resolver de alguma forma, por exemplo, usando o particionamento de quantis, então, para a primeira, na minha opinião, não há nenhum método universal: todos os que conheço têm limitações que os tornam de pouca utilidade em tarefas de automação, quando não podemos nos dar ao luxo de usar o método de "poke".
A estimativa de cdf não tem essas desvantagens. Nesse caso, as etapas da função estão localizadas exatamente onde os dados de entrada caem e, portanto, o problema de escolher uma grade para o interpolante desaparece por si só. Depois que a grade é criada, não é difícil escolher o número de intervalos: já sabemos o número máximo de intervalos (e sua localização!!!), portanto, ao afinar, podemos definir qualquer precisão necessária, e cada vez em uma grade natural que melhor corresponda à estrutura dos dados de entrada.
Na prática, usei essa técnica para pesquisar modos locais de distribuições empíricas quando o número de amostras de dados não excede 100, e obtive resultados muito suaves, e visualmente a precisão da pesquisa é definida como bastante qualitativa, pelo menos 2 a 4 modos principais são encontrados praticamente sem desvios. Mas eu uso um algoritmo de suavização diferente, pois não gosto dos algoritmos de kernel por vários motivos.
Tudo perfeitamente justo. Mas, ao que me parece, exceto por um ponto, ao qual você aparentemente não prestou atenção.
Uma expressão bem conhecida para Kernel smoother é "Kernel smooth".
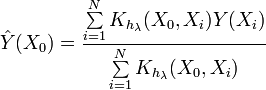
Um método baseado em tal suavização para estimar a pdf pode ter a seguinte aparência (simplificada):
- Particionamos a sequência de entrada em intervalos (agrupamento, Binning)
- Suavizamos o histograma resultante.
Se você não gostar da suavização de kernel, poderá usar, por exemplo, p-spline. (Provavelmente é melhor escolher o p-spline imediatamente).
Com essa abordagem para a estimativa do pdf , tudo o que você disse acaba sendo absolutamente justo. Mas, mesmo nesse caso, esse método de estimativa para sequências de grande comprimento (>1000000) oferece excelentes resultados. À medida que o comprimento da sequência de entrada diminui, todos os encantos que você mencionou começam a aparecer cada vez mais.
Agora vamos dar uma olhada na expressão da estimativa de densidade de Kernel (KDE)
![]()
Essa expressão é diferente da apresentada anteriormente. Como podemos ver, essa expressão determina diretamente o valor da função de densidade de probabilidade em um determinado ponto. E o que é importante nesse caso é que não há partição em intervalos. Os valores da sequência de entrada são usados diretamente.
Pelo menos, é assim que vejo a situação com o KDE. O algoritmo de estimativa de pdf apresentado no artigo, à primeira vista, lida muito bem com sequências de 20 a 30 elementos. Às vezes, você pode querer reduzir o grau de suavização. Você pode fazer isso facilmente substituindo no código
h=0.9*a/MathPow(N,0.2); // Regra de ouro de Silvermanpor
h=0.7*a/MathPow(N,0.2); // Regra de ouro de Silverman
A ideia original era não usar nenhuma ferramenta externa, ou seja, supunha-se que tudo deveria ser implementado apenas por ferramentas MQL5.
Essa é a ideia de todos os inventores de bicicletas, sem exceção.
Veja o que os pacotes correspondentes têm a esse respeito e compare com o que você forneceu - uma quantidade infinitesimal do que é necessário ao aplicar a estatística e a econometria na negociação.
Prezado Alex,
É fácil para você raciocinar do alto de seu voo. Mas pense por um segundo no seguinte:
Esse recurso chama-se"www.mql5.com - Automated Trading and Testing of Trading Strategies" (www.mql5.com - Negociação automatizada e teste de estratégias de negociação). Como você pode ver, o site se chama mql5, não EViews ou mesmo MQ ou MT5. Portanto, é fácil presumir que esse site tem como foco principal a popularização, a depuração e o desenvolvimento da linguagem de programação MQL5. Isso é confirmado pela presença do servicedesk e pela colocação de informações de referência sobre MQL5 no site.
Se esse site fosse chamado, por exemplo, de "uma coleção de estratégias de negociação" e não pertencesse à MQ. Nesse caso, seria de se esperar que publicações descrevendo soluções em Exel, R, EVievs, Gauss, Stata e assim por diante aparecessem em tal site.
Se eu tivesse publicado este artigo no site do EViews, poderia ter tentado entender a essência de sua reprovação. Mas você e eu não estamos no EViews neste momento.
Este site é visitado por pessoas com históricos muito diferentes. São pessoas de diferentes idades, com diferentes formações educacionais e diferentes especialidades. Acho que a maioria delas tem pouca ou nenhuma experiência com pacotes econométricos. Você acha que todas essas pessoas deveriam ser banidas deste site, ou seja, deixá-las aprender o EViews primeiro?
Como você publicou por conta própria, deve estar familiarizado com o procedimento de publicação de artigos neste site. É impossível publicar qualquer artigo por conta própria. Você só pode enviar um artigo para análise. A própria administração do site seleciona os artigos adequados ao seu conceito geral. E, em alguns casos, a própria administração solicita artigos sobre tópicos de seu interesse. Como eu já disse, a administração tem um conceito geral e estatísticas sobre o número de solicitações para esta ou aquela publicação. Nessa situação, acho que não é muito correto dirigir-se a mim com reclamações sobre o tópico do artigo. Talvez você deva discutir essas questões com os representantes da MQ?
Há artigos publicados neste site que não são interessantes para mim. Enfatizo que não são artigos ruins, mas apenas não são interessantes para mim. Normalmente não os leio nem escrevo comentários sobre eles. Talvez você deva escolher uma linha de comportamento semelhante para si mesmo? Embora eu não ouse dar conselhos, faça como se sentir mais confortável.
Prezado Alex,
É fácil para você raciocinar a partir da altura de seu voo. Mas pense no seguinte por um segundo:
Esse recurso chama-se"www.mql5.com - Automated Trading and Testing of Trading Strategies" (www.mql5.com - Negociação automatizada e teste de estratégias de negociação). Como você pode ver, o site se chama mql5, não EViews ou mesmo MQ ou MT5. Portanto, é fácil presumir que esse site tem como foco principal a popularização, a depuração e o desenvolvimento da linguagem de programação MQL5. Isso é confirmado pela presença do servicedesk e pela colocação de informações de referência sobre MQL5 no site.
Se esse site fosse chamado, por exemplo, de "uma coleção de estratégias de negociação" e não pertencesse à MQ. Nesse caso, seria de se esperar que publicações descrevendo soluções em Exel, R, EVievs, Gauss, Stata e assim por diante aparecessem em tal site.
Se eu tivesse publicado este artigo no site do EViews, poderia ter tentado entender a essência de sua reprovação. Mas você e eu não estamos no EViews neste momento.
Este site é visitado por pessoas com históricos muito diferentes. São pessoas de diferentes idades, com diferentes formações educacionais e diferentes especialidades. Acho que a maioria delas tem pouca ou nenhuma experiência com pacotes econométricos. Você acha que todas essas pessoas deveriam ser banidas deste site, ou seja, deixá-las aprender o EViews primeiro?
Como você publicou por conta própria, deve estar familiarizado com o procedimento de publicação de artigos neste site. É impossível publicar qualquer artigo por conta própria. Você só pode enviar um artigo para análise. A própria administração do site seleciona os artigos adequados ao seu conceito geral. E, em alguns casos, a própria administração solicita artigos sobre tópicos de seu interesse. Como eu já disse, a administração tem um conceito geral e estatísticas sobre o número de solicitações para esta ou aquela publicação. Nessa situação, acho que não é muito correto dirigir-se a mim com reclamações sobre o assunto do artigo. Talvez você deva discutir essas questões com os representantes da MQ?
Há artigos publicados neste site que não são interessantes para mim. Enfatizo que não são artigos ruins, mas apenas não são interessantes para mim. Normalmente não os leio nem escrevo comentários sobre eles. Talvez você deva escolher uma linha de comportamento semelhante para si mesmo? Embora eu não ouse dar conselhos, faça como se sentir mais confortável.
Não posso aceitar sua resposta, pois ela não tem nada a ver com a essência da minha postagem. Tentarei explicar meu ponto de vista.
1. O Metaquotes não tem nada a ver com isso - eles forneceram uma ferramenta muito decente e estão fazendo isso.
2. Não tenho conhecimento de nenhuma restrição quanto aos tópicos dos artigos. É claro, dentro dos limites da negociação. Esse site tem uma seção "Estatísticas", ou seja, eles entendem o assunto do site de forma muito mais ampla do que você, em total conformidade com o conteúdo e os problemas de negociação. Não vamos nos referir ao Metaquotes e passar para a substância.
3. Minha postagem não é sobre O QUE desenvolver, mas COMO desenvolver. Para mim, isso é o que é fundamental em relação ao seu artigo. Eu não estava fazendo campanha para o EViews, do qual tenho uma opinião negativa - ele é bom para fins de demonstração e treinamento, mas não acho que se possa negociar com ele. Meu link é para pacotes que demonstram a amplitude do problema.
4. Estou programando há muito tempo. Há 40 anos, surgiram as primeiras bibliotecas de programas e, imediatamente, há 40 anos, os amadores foram criticados por reescreverem algum programa a partir de um pacote existente. Você não é o primeiro. Mas este site está cheio de amadores que gostam de construir uma bicicleta novamente - daí minha reação hipertrofiada.
5. A questão da avaliação nuclear é um assunto muito discutido e discutido. E se você pegasse a biblioteca de outra pessoa, teria a oportunidade de superar as dificuldades técnicas que resolveu em seu trabalho e talvez oferecer uma solução para as questões levantadas pelo praticante alsu, ou lembrar que a avaliação visual das distribuições desempenha um papel muito importante em sua avaliação formal, ou expandir funcionalmente, etc. - De qualquer forma, você estaria um passo à frente.
Não tive a intenção de expressar nada ofensivo em relação a você. Seu artigo e seu desenvolvimento são respeitados, mas não posso concordar com o foco metodológico da técnica de implementação de suas ideias.
Minha postagem sobre seu artigo é ditada pela esperança de que alguém complemente sistematicamente o terminal Metaquotes com meios de estatística e econometria. Eu o encaminho para essas pessoas.
Extremamente interessante. Muito interessante.
Vocês aceitam solicitações?
Não apenas código-fonte aberto, mas código orientado a estatísticas é desejável. Favor prestar atenção ao R.
Extremamente interessante. Muito interessante.
Vocês aceitam solicitações?
Não apenas código-fonte aberto, mas código orientado a estatísticas é desejável. Por favor, preste atenção ao R.
As solicitações são aceitas aqui: https://www.mql5.com/ru/forum/6505. Escreva o que você quiser. :)
- www.mql5.com
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Estimativa da densidade de Kernel da função de densidade de probabilidade desconhecida foi publicado:
O artigo trata da criação de um programa que permite estimar a densidade do kernel da função densidade de probabilidade desconhecida. Método de estimativa de densidade do kernel foi escolhido para executar a tarefa. O artigo contém códigos fonte da implementação de software de método, exemplos de seu uso e ilustrações.
Autor: Victor