
La trasformazione di Box-Cox

Introduzione
Mentre le capacità dei PC aumentano, i trader e gli analisti Forex hanno maggiori possibilità di utilizzare algoritmi matematici altamente sviluppati e complessi che richiedono notevoli risorse di calcolo. Ma l'adeguatezza delle risorse informatiche non può risolvere da sola i problemi dei trader. Sono inoltre necessari algoritmi efficienti per l'analisi delle quotazioni di mercato.
Attualmente, aree come la statistica matematica, l'economia e l'econometria forniscono un gran numero di metodi, modelli e algoritmi efficienti e ben funzionanti utilizzati attivamente dai trader per l'analisi di mercato. Molto spesso si tratta di metodi parametrici standard creati con un'ipotesi della stabilità delle sequenze ricercate e della normalità della loro legge di distribuzione.
Ma non è un segreto che le quotazioni Forex sono sequenze che non possono essere classificate come stabili e che hanno una normale legge di distribuzione. Pertanto, non possiamo utilizzare metodi parametrici "standard" di statistica matematica, econometria ecc. quando analizziamo le quotazioni.
Nell'articolo "Box-Cox Transformation and the Illusion of Macroeconomic Series "Normality" [1] A.N. Porunov scrive come segue:
"Gli analisti economici hanno spesso a che fare con dati statistici che non superano il test di normalità per un motivo o per l'altro. In questa situazione ci sono due scelte: o rivolgersi a metodi non parametrici che richiedono una discreta quantità di formazione matematica, oppure utilizzare tecniche speciali che consentano di convertire le "statistiche anomale" originali in quella "normale", il che è anche un compito piuttosto complesso".
Nonostante il fatto che la quotazione di A.N.Porunov si riferisca agli analisti economici, può essere pienamente attribuita ai tentativi di analizzare le quotazioni Forex "anormali" utilizzando metodi parametrici di statistica matematica ed econometria. La stragrande maggioranza di questi metodi è stata sviluppata per analizzare sequenze aventi la normale legge di distribuzione. Ma, nella maggior parte dei casi, il fatto della "anomalia" dei dati iniziali viene semplicemente ignorato. Inoltre, i metodi menzionati spesso richiedono non solo una distribuzione normale, ma anche sequenze iniziali di stazionarietà.
Regressione, dispersione (ANOVA) e alcuni altri tipi di analisi possono essere chiamati metodi "standard" che richiedendo la normalità iniziale dei dati. Non è possibile elencare tutti i metodi parametrici che hanno limitazioni riguardanti la normalità della legge di distribuzione in quanto occupano l'intera area, ad esempio, dell'econometria, ad eccezione dei suoi metodi non parametrici.
Per essere onesti, va aggiunto che i metodi parametrici "standard" hanno una sensibilità diversa alla deviazione della legge iniziale di distribuzione dei dati dal valore normale. Pertanto, la deviazione dalla "normalità" durante l'uso di tali metodi non porta necessariamente a conseguenze disastrose ma, naturalmente, non aumenta l'accuratezza e l'affidabilità dei risultati ottenuti.
Tutto ciò solleva la questione sulla necessità di passare a metodi non parametrici di analisi e previsione delle quotazioni. Tuttavia, i metodi parametrici rimangono molto interessanti. Ciò può essere spiegato dalla loro prevalenza e dalla quantità sufficiente di dati, algoritmi già pronti ed esempi della loro applicazione. Per utilizzare correttamente questi metodi, è necessario far fronte almeno a due problemi legati alle sequenze iniziali: instabilità e "anormalità".
Sebbene non possiamo influenzare la stabilità delle sequenze iniziali, possiamo cercare di avvicinare la loro legge di distribuzione a quella normale. Per risolvere questo problema, esistono varie trasformazioni. I più noti sono brevemente descritti nell'articolo "The Use of Box-Cox Transformation Technique in Economic and Statistical Analyses" [2]. In questo articolo ne considereremo solo uno: la trasformazione di Box-Cox [1], [2], [3].
Dobbiamo sottolineare qui che l'uso della trasformazione di Box-Cox, come qualsiasi altro tipo di trasformazione, può solo portare la legge di distribuzione della sequenza iniziale più o meno più vicina a quella normale. Significa che l'utilizzo di questa trasformazione non garantisce che la sequenza risultante avrà la normale legge di distribuzione.
1. La trasformazione di Box-Cox
Per la sequenza originale X di N lunghezza
![]()
La trasformazione di Box-Cox a un parametro si trova come segue:
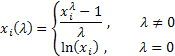
dove![]() .
.
Come puoi vedere, questa trasformazione ha un solo parametro: lambda. Se il valore lambda è uguale a zero, viene eseguita la trasformazione logaritmica della sequenza iniziale. Nel caso in cui il valore lambda differisca da zero, la trasformazione è legge di potenza. Se il parametro lambda è uguale a uno, la legge di distribuzione della sequenza iniziale rimane invariata, anche se la sequenza si sposta poiché l'unità viene sottratta da ciascuno dei suoi valori.
A seconda del valore lambda, la trasformazione di Box-Cox include i seguenti casi speciali:
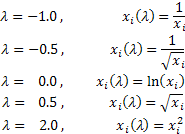
L'utilizzo della trasformazione di Box-Cox richiede che tutti i valori della sequenza di input siano positivi e diversi da zero. Se la sequenza di input non soddisfa questi requisiti, può essere spostata in area positiva dal volume che garantisce la "positività" di tutti i suoi valori.
Esaminiamo solo la trasformazione di Box-Cox a un parametro per ora, preparando i dati di input per essa in modo appropriato. Al fine di evitare valori negativi o zero nei dati di input, troveremo sempre il valore più basso della sequenza di input e lo dedurremo da ciascun elemento della sequenza eseguendo inoltre un piccolo spostamento pari a 1e-5. Tale spostamento aggiuntivo è necessario per fornire uno spostamento di sequenza garantito nell'area positiva, nel caso in cui il suo valore più basso sia uguale a zero.
In effetti, non è necessario applicare questo spostamento a sequenze "positive". Ma useremo lo stesso algoritmo, tuttavia, per ridurre la probabilità di ottenere valori estremamente grandi quando si aumenta a una potenza durante la trasformazione. Pertanto, qualsiasi sequenza di input si troverà nell'area positiva dopo lo spostamento e avrà il valore più basso vicino allo zero.
La fig.1 mostra le curve di trasformazione di Box-Cox con valori diversi del parametro lambda. La fig.1 è stata preso dall'articolo "Box-Cox Transformations" [3]. La griglia orizzontale sul grafico è data su una scala logaritmica.

Fig.1. La trasformazione di Box-Cox in caso di vari valori del parametro lambda
Come possiamo vedere, le "code" della distribuzione iniziale possono essere "allungate" o "inseguite". Curva superiore in Fig.1 corrisponde a lambda=3, mentre quello inferiore - con lambda=-2.
Affinché la legge di distribuzione della sequenza risultante sia il più vicino possibile alla legge normale, è necessario selezionare il valore ottimale del parametro lambda.
Un modo per determinare il valore ottimale di questo parametro consiste nel massimizzare la funzione di verosimiglianza logaritmo:
![]()
dove
![]()
Significa che dobbiamo selezionare il parametro lambda, al quale questa funzione raggiunge il suo valore massimo.
L'articolo "Box-Cox Transformations" [3] tratta brevemente un altro modo per determinare il valore ottimale di questo parametro basato sulla ricerca del valore più alto del coefficiente di correlazione tra i quantili della funzione di distribuzione normale e la sequenza trasformata ordinata. Molto probabilmente, è possibile trovare altri metodi di ottimizzazione dei parametri lambda, ma prima discutiamo la ricerca della funzione di probabilità logaritmo massimo menzionata in precedenza.
Ci sono diversi modi per trovarlo. Ad esempio, possiamo fare una semplice ricerca. Per fare ciò, dobbiamo calcolare il valore della funzione di verosimiglianza all'interno di un intervallo selezionato, modificando il valore del parametro lambda in un passo basso. Inoltre, dobbiamo selezionare il parametro lambda ottimale in cui la funzione di probabilità ha il valore più alto.
La distanza di passo determinerà l'accuratezza del calcolo del valore ottimale del parametro lambda. Più basso è il pitch, maggiore è la precisione, anche se la quantità richiesta di calcoli viene aumentata proporzionalmente in quel caso. Vari algoritmi di ricerca per la funzione massima / minima, algoritmi genetici e alcuni altri metodi possono essere utilizzati per aumentare l'efficienza dei calcoli.
2. Trasformazione nella legge di distribuzione normale
Uno dei compiti più importanti della trasformazione di Box-Cox è la riduzione della legge di distribuzione della sequenza di input a forma "normale". Proviamo a scoprire in che misura un tale problema può essere risolto con l'aiuto di questa trasformazione.
Per evitare qualsiasi distrazione e ripetizione inutile, useremo l'algoritmo di ricerca della funzione minima con il metodo di Powell. Questo algoritmo è stato descritto negli articoli "Time Series Forecasting Using Exponential Smoothing" e "Time Series Forecasting Using Exponential Smoothing (continued)".
È necessario creare una classe CBoxCox per la ricerca del valore ottimale del parametro di trasformazione. In questa classe la funzione di verosimiglianza sopra menzionata sarà realizzata come oggettiva. La classe PowellsMethod [4], [5] viene utilizzata come classe di base realizzando direttamente l'algoritmo di ricerca.
//+------------------------------------------------------------------+ //| CBoxCox.mqh | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" //+------------------------------------------------------------------+ //| CBoxCox class | //+------------------------------------------------------------------+ class CBoxCox:public PowellsMethod { protected: double Dat[]; // Input data double BCDat[]; // Box-Cox data int Dlen; // Data size double Par[1]; // Parameters double LnX; // ln(x) sum public: void CBoxCox(void) { } void CalcPar(double &dat[]); double GetPar(int n) { return(Par[n]); } private: virtual double func(const double &p[]); }; //+------------------------------------------------------------------+ //| CalcPar | //+------------------------------------------------------------------+ void CBoxCox::CalcPar(double &dat[]) { int i; double a; //--- Lambda initial value Par[0]=1.0; Dlen=ArraySize(dat); ArrayResize(Dat,Dlen); ArrayResize(BCDat,Dlen); LnX=0; for(i=0;i<Dlen;i++) { //--- input data a=dat[i]; Dat[i]=a; //--- ln(x) sum LnX+=MathLog(a); } //--- Powell optimization Optimize(Par); } //+------------------------------------------------------------------+ //| func | //+------------------------------------------------------------------+ double CBoxCox::func(const double &p[]) { int i; double a,lamb,var,mean,k,ret; lamb=p[0]; var=0; mean=0; k=0; if(lamb>5.0){k=(lamb-5.0)*400; lamb=5.0;} // Lambda > 5.0 else if(lamb<-5.0){k=-(lamb+5.0)*400; lamb=-5.0;} // Lambda < -5.0 //--- Lambda != 0.0 if(lamb!=0) { for(i=0;i<Dlen;i++) { //--- Box-Cox transformation BCDat[i]=(MathPow(Dat[i],lamb)-1.0)/lamb; //--- average value calculation mean+=BCDat[i]/Dlen; } } //--- Lambda == 0.0 else { for(i=0;i<Dlen;i++) { //--- Box-Cox transformation BCDat[i]=MathLog(Dat[i]); //--- average value calculation mean+=BCDat[i]/Dlen; } } for(i=0;i<Dlen;i++) { a=BCDat[i]-mean; //--- variance var+=a*a/Dlen; } //--- log-likelihood ret=Dlen*MathLog(var)/2.0-(lamb-1)*LnX; return(k+ret); } //------------------------------------------------------------------------------------
Adesso tutto ciò che dobbiamo fare per trovare il valore ottimale del parametro lambda è fare riferimento al metodo CalcPar della classe menzionata fornendogli il collegamento all'array contenente i dati di input. Possiamo ottenere il valore ottimale del parametro ottenuto facendo riferimento al metodo GetPar. Come è stato detto prima, i dati di input devono essere positivi.
La classe PowellsMethod implementa l'algoritmo di ricerca del minimo della funzione di molte variabili, ma nel nostro caso viene ottimizzato un solo parametro. Ciò porta al fatto che la dimensione dell'array Par[] è uguale a una. Significa che la matrice contiene un solo valore. Teoricamente possiamo usare una variabile standard invece dell'array di parametri in questo caso, ma ciò richiederebbe l'implementazione di modifiche nel codice della classe di base PowellsMethod. Presumibilmente, non ci saranno problemi se compiliamo il codice MQL5 sorgente usando gli array contenenti un solo elemento.
Dobbiamo tenere presente il fatto che la funzione CBoxCox::func() contiene una limitazione dell'intervallo dei valori consentiti del parametro lambda. Nel nostro caso, questo intervallo è limitato a valori da -5 a 5. Questo viene fatto per evitare di ottenere valori estremamente grandi o troppo piccoli quando si aumentano i dati di input al grado lambda.
Inoltre, se otteniamo valori lambda estremamente grandi o troppo piccoli durante l'ottimizzazione, ciò potrebbe indicare che la sequenza è di scarsa utilità per il tipo di trasformazione selezionato. Pertanto, sarebbe saggio in ogni caso non superare un intervallo ragionevole quando si calcola il valore lambda.
3. Sequenze casuali
Scriviamo uno script di test che eseguirà la trasformazione di Box-Cox della sequenza pseudocasuale formata da noi usando la classe CBoxCox.
Di seguito è riportato il codice sorgente di tale script.
//+------------------------------------------------------------------+ //| BoxCoxTest1.mq5 | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "CBoxCox.mqh" #include "RNDXor128.mqh" CBoxCox Bc; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int i,n; double dat[],bcdat[],lambda,min; //--- data size n=1600; //--- input array preparation ArrayResize(dat,n); //--- transformed data array ArrayResize(bcdat,n); Rnd.Reset(); //--- random sequence generation for(i=0;i<n;i++)dat[i]=Rnd.Rand_Exp(); //--- input data shift min=dat[ArrayMinimum(dat)]-1e-5; for(i=0;i<n;i++)dat[i]=dat[i]-min; //--- optimization by lambda Bc.CalcPar(dat); lambda=Bc.GetPar(0); PrintFormat("Iterations= %i, lambda= %.4f",Bc.GetIter(),lambda); if(lambda!=0){for(i=0;i<n;i++)bcdat[i]=(MathPow(dat[i],lambda)-1.0)/lambda;} else {for(i=0;i<n;i++)bcdat[i]=MathLog(dat[i]);} // Lambda == 0.0 //--- dat[] <-- input data //--- bcdat[] <-- transformed data } //-----------------------------------------------------------------------------------
Una sequenza pseudocasuale con la legge esponenziale della distribuzione viene utilizzata come dati trasformati di input nello script mostrato. La lunghezza della sequenza è impostata in n variabile ed è uguale a 1600 valori in questo caso.
La classe RNDXor128 (George Marsaglia, Xorshift RNG) viene utilizzata per la generazione di una sequenza pseudocasuale. Questa classe è stata descritta nell'articolo "Analysis of the Main Characteristics of Time Series" [6]. Tutti i file necessari per la compilazione degli script BoxCoxTest1.mq5 si trovano nell'archivio Box-Cox-Tranformation_MQL5.zip. Questi file devono trovarsi in una directory per una corretta compilazione.
Quando viene eseguito lo script mostrato, viene formata la sequenza di input spostata nell'area dei valori positivi e viene eseguita la ricerca del valore ottimale del parametro lambda. Quindi viene visualizzato il messaggio contenente il valore lambda ottenuto e il numero di passaggi dell'algoritmo di ricerca. Di conseguenza, la sequenza trasformata verrà creata nella matrice di output bcdat[].
Questo script nella sua forma attuale consente solo di preparare la sequenza trasformata per il suo ulteriore utilizzo e non implementa alcuna modifica. Durante la stesura di questo articolo, il tipo di analisi descritto nell'articolo "Analysis of the Main Characteristics of Time Series" [6] è stato selezionato per la valutazione dei risultati della trasformazione. Gli script utilizzati non sono mostrati in questo articolo per ridurre il volume dei codici pubblicati. Di seguito vengono presentati solo i risultati grafici dell'analisi già pronti.
La fig. 2 mostra l'istogramma e il grafico forniti dalla scala di distribuzione normale per la sequenza pseudocasuale con la legge di distribuzione esponenziale utilizzata nello script BoxCoxTest1.mq5. Risultato del test di Jarque-Bera JB=3241.73, p= 0.000. Come possiamo vedere, la sequenza di input non è affatto "normale" e, come previsto, la sua distribuzione è simile a quella esponenziale.

Fig.2. Sequenza pseudocasuale con la legge di distribuzione esponenziale. Test di Jarque-Bera JB=3241.73, р=0.000.

Fig.3. Sequenza trasformata. Lambda parameter=0.2779, test di Jarque-Bera JB=4.73, р=0.094
La fig. 3 mostra il risultato dell'analisi della sequenza trasformata (BoxCoxTest1.mq5 script, bcdat[] array). La legge di distribuzione della sequenza trasformata è molto più vicina a quella normale, il che è anche confermato dai risultati del test di Jarque-Bera JB= 4,73, p = 0,094. Valore del parametro lambda ottenuto=0,2779.
La trasformazione di Box-Cox si è dimostrata abbastanza adatta in questo esempio. Sembra che la sequenza risultante sia diventata molto più vicina a quella "normale" e il risultato del test di Jarque-Bera sia diminuito da JB = 3241,73 a JB = 4,73. Non è sorprendente dal momento che la sequenza scelta, evidentemente, si adatta abbastanza bene a questo tipo di trasformazione.
Esaminiamo un altro esempio della trasformazione di Box-Cox della sequenza pseudocasuale. Dobbiamo creare una sequenza di input "adatta" per la trasformazione di Box-Cox considerando la sua natura di legge di potenza. Per raggiungere questo obiettivo, dobbiamo generare una sequenza pseudocasuale (che ha già la legge di distribuzione vicina a quella normale) e poi distorcerla alzando tutti i suoi valori alla potenza di 0,35. Possiamo aspettarci che la trasformazione di Box-Cox restituisca la distribuzione normale originale alla sequenza di input con grande precisione.
Di seguito è riportato il codice sorgente dello script di testo BoxCoxTest2.mq5.
Questo script differisce dal precedente solo per il fatto che in esso viene generata un'altra sequenza di input.
//+------------------------------------------------------------------+ //| BoxCoxTest2.mq5 | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "CBoxCox.mqh" #include "RNDXor128.mqh" CBoxCox Bc; RNDXor128 Rnd; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int i,n; double dat[],bcdat[],lambda,min; //--- data size n=1600; //--- input data array ArrayResize(dat,n); //--- transformed data array ArrayResize(bcdat,n); Rnd.Reset(); //--- random sequence generation for(i=0;i<n;i++)dat[i]=Rnd.Rand_Norm(); //--- input data shift min=dat[ArrayMinimum(dat)]-1e-5; for(i=0;i<n;i++)dat[i]=dat[i]-min; for(i=0;i<n;i++)dat[i]=MathPow(dat[i],0.35); //--- optimization by lambda Bc.CalcPar(dat); lambda=Bc.GetPar(0); PrintFormat("Iterations= %i, lambda= %.4f",Bc.GetIter(),lambda); if(lambda!=0) { for(i=0;i<n;i++)bcdat[i]=(MathPow(dat[i],lambda)-1.0)/lambda; } else { for(i=0;i<n;i++)bcdat[i]=MathLog(dat[i]); } // Lambda == 0.0 //-- dat[] <-- input data //-- bcdat[] <-- transformed data } //-----------------------------------------------------------------------------------
La sequenza pseudocasuale di input con la legge di distribuzione normale viene generata nello script mostrato. Viene spostato nell'area dei valori positivi e quindi tutti gli elementi di questa sequenza vengono elevati alla potenza di 0,35. Dopo il completamento dell'operazione di script dat[] array contiene la sequenza di input, mentre bcdat[] array contiene quella trasformata.
La fig.4 mostra le caratteristiche della sequenza di ingresso, la quale ha perso la sua distribuzione normale originale a causa dell'aumento alla potenza di 0,35. In tal caso il test di Jarque-Bera mostra JB=3609.29, p= 0.000.

Fig.4. Sequenza pseudocasuale di input. Test di Jarque-Bera JB=3609.29, p=0.000.

Fig.5. Sequenza trasformata. Parametro Lambda=2.9067, test Jarque-Bera JB=0.30, p=0.859
Come mostrato nella fig.5, la sequenza trasformata ha la legge di distribuzione abbastanza vicina a quella normale, la quale è confermata anche dal valore del test di Jarque-Bera JB=0,30, p=0,859.
Questi esempi dell'uso della trasformazione di Box-Cox hanno dimostrato ottimi risultati. Ma non dobbiamo dimenticare che in entrambi i casi abbiamo affrontato le sequenze che erano più convenienti per questa trasformazione. Pertanto, questi risultati possono essere visti semplicemente come una conferma delle prestazioni dell'algoritmo che abbiamo creato.
4. Quotazioni
Dopo aver confermato le normali prestazioni dell'algoritmo che implementa la trasformazione di Box-Cox, dobbiamo provare ad applicarlo alle quotazioni Forex reali, poiché vogliamo ridurle alla normale legge di distribuzione.
Useremo le sequenze descritte nell'articolo "Time Series Forecasting Using Exponential Smoothing (continued)" [5] come quotazioni di prova. Vengono inseriti nella directory \Dataset2 dell’archivio Box-Cox-Tranformation_MQL5.zip e forniscono quotazioni reali, 1200 valori dei quali sono stati salvati nei file appropriati. Estratto La cartella \Dataset2 deve essere inserita nella directory \MQL5\Files del terminale per fornire l'accesso a questi file.
Supponiamo che queste quotazioni non siano sequenze stazionarie. Pertanto, non estenderemo i risultati dell'analisi alla cosiddetta popolazione generale, ma li considereremo solo come caratteristiche di questa particolare sequenza di lunghezza finita.
Inoltre, va detto ancora una volta che, se non c'è stazionarietà, diversi frammenti di quotazioni della stessa coppia di valute seguono leggi di distribuzione molto diverse.
Creiamo uno script che consenta di leggere i valori della sequenza da un file ed eseguire la sua trasformazione di Box-Cox. Dagli script di test mostrati sopra differirà solo nel modo in cui si forma la sequenza di input. Di seguito è riportato il codice sorgente di tale script, mentre lo script BoxCoxTest3.mq5 viene inserito nell'archivio allegato.
//+------------------------------------------------------------------+ //| BoxCoxTest3.mq5 | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "CBoxCox.mqh" CBoxCox Bc; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int i,n; double dat[],bcdat[],lambda,min; string fname; //--- input data file fname="Dataset2\\EURUSD_M1_1200.txt"; //--- data reading if(readCSV(fname,dat)<0){Print("Error."); return;} //--- data size n=ArraySize(dat); //--- transformed data array ArrayResize(bcdat,n); //--- input data array min=dat[ArrayMinimum(dat)]-1e-5; for(i=0;i<n;i++)dat[i]=dat[i]-min; //--- lambda parameter optimization Bc.CalcPar(dat); lambda=Bc.GetPar(0); PrintFormat("Iterations= %i, lambda= %.4f",Bc.GetIter(),lambda); if(lambda!=0){for(i=0;i<n;i++)bcdat[i]=(MathPow(dat[i],lambda)-1.0)/lambda;} else {for(i=0;i<n;i++)bcdat[i]=MathLog(dat[i]);} // Lambda == 0.0 //--- dat[] <-- input data //--- bcdat[] <-- transformed data } //+------------------------------------------------------------------+ //| readCSV | //+------------------------------------------------------------------+ int readCSV(string fnam,double &dat[]) { int n,asize,fhand; fhand=FileOpen(fnam,FILE_READ|FILE_CSV|FILE_ANSI); if(fhand==INVALID_HANDLE) { Print("FileOpen Error!"); return(-1); } asize=512; ArrayResize(dat,asize); n=0; while(FileIsEnding(fhand)!=true) { dat[n++]=FileReadNumber(fhand); if(n+128>asize) { asize+=128; ArrayResize(dat,asize); } } FileClose(fhand); ArrayResize(dat,n-1); return(0); } //-----------------------------------------------------------------------------------
Tutti i valori (ce ne sono 1200 nel nostro caso) vengono importati nella matrice dat[] in questo script dal file delle virgolette, il cui nome è impostato nella variabile fname. Più avanti vengono eseguiti lo spostamento della sequenza iniziale, la ricerca del valore ottimale del parametro e la trasformazione di Box-Cox, nel modo descritto sopra. Dopo l'esecuzione dello script, il risultato della trasformazione si trova nella matrice bcdat[].
Come si può vedere dal codice sorgente mostrato, la sequenza di quotazioni EURUSD M1 è stata selezionata nello script per la trasformazione. Il risultato dell'analisi della sequenza originale e trasformata è mostrato in Fig.6 e 7.

Fig.6. Sequenza di ingresso EURUSD M1. Test di Jarque-Bera JB=100.94, p=0.000.

Fig.7. Sequenza trasformata. Parametro Lambda=0.4146, test di Jarque-Bera JB=39.30, p=0.000
Secondo le caratteristiche mostrate nella fig.7, il risultato della trasformazione delle quotazioni EURUSD M1 non è così impressionante come i risultati della trasformazione delle sequenze pseudocasuali mostrati in precedenza. La trasformazione di Box-Cox non è in grado di far fronte a tutti i tipi di sequenze di input, sebbene sia considerata abbastanza universale. Ad esempio, è impraticabile aspettarsi dalla trasformazione della legge di potenza di trasformare la distribuzione a due cime in quella normale.
Sebbene la legge di distribuzione mostrata nella fig.7 difficilmente possa essere considerata normale, possiamo ancora vedere una notevole diminuzione dei valori del test di Jarque-Bera come negli esempi precedenti. Mentre JB=100.94 per la sequenza originale, esso mostra JB=39.30 dopo la trasformazione. Significa che la legge sulla distribuzione è riuscita ad avvicinarsi ai valori normali in una certa misura dopo la trasformazione.
Sono stati ottenuti approssimativamente gli stessi risultati quando si trasformano diversi frammenti di altre quotazioni. Ogni volta la trasformazione di Box-Cox ha avvicinato la legge di distribuzione a quella normale in misura maggiore o minore. Tuttavia, non è mai diventato normale.
Una serie di esperimenti con la trasformazione di varie quotazioni consente di trarre la conclusione abbastanza attesa: la trasformazione di Box-Cox consente di avvicinare la legge di distribuzione delle quotazioni Forex a quella normale, ma non può garantire il raggiungimento della vera normalità della legge di distribuzione dei dati trasformati.
È ragionevole effettuare la trasformazione che ancora non porta la sequenza originale a quella normale? Non esiste una risposta definitiva a questa domanda. In ogni caso specifico dobbiamo prendere una decisione individuale sulla necessità della trasformazione di Box-Cox. In questo caso, molto dipenderà dal tipo di metodi parametrici che vengono utilizzati nell'analisi delle quotazioni e dalla sensibilità di questi metodi alla deviazione dei dati iniziali dalla normale legge di distribuzione.
5. Rimozione delle tendenze
La parte superiore della fig.6 mostra il grafico della sequenza originale EURUSD M1 utilizzata nello script BCTransform.mq5. Si può facilmente vedere che i suoi valori stanno aumentando quasi uniformemente lungo tutta la sequenza. In una prima approssimazione, possiamo concludere che la sequenza contiene la tendenza lineare. La presenza di tale "tendenza" suggerisce che dobbiamo cercare di escludere la tendenza prima di effettuare varie trasformazioni e analizzare la sequenza ricevuta.
La rimozione di una tendenza dalle sequenze di input analizzate probabilmente non deve essere considerata come un metodo adatto a tutti i casi. Ma supponiamo che analizzeremo la sequenza mostrata nella fig.6 per trovare componenti periodici (o ciclici) in essa. In questo caso possiamo sicuramente sottrarre la tendenza lineare dalla sequenza di input dopo aver definito i parametri di tendenza.
La rimozione di una tendenza lineare non influirà sul rilevamento di componenti periodici. Può anche essere utile e rendere i risultati di tale analisi più accurati o affidabili in una certa misura a seconda del metodo di analisi selezionato.
Se decidessimo che una rimozione della tendenza può essere utile in alcuni casi, allora probabilmente ha senso esaminare come la trasformazione di Box-Cox affronta una sequenza dopo che una tendenza è stata esclusa da essa.
In ogni situazione, quando rimuoviamo una tendenza dovremo decidere quale curva deve essere utilizzata per l'approssimazione della tendenza. Questa può essere una linea retta, curve di ordine superiore, medie mobili ecc. In questo caso, scegliamo, se posso dirlo, la versione estrema per non essere distratti dal problema di selezione della curva ottimale. Useremo gli incrementi della sequenza originale, cioè le differenze tra i suoi valori attuali e precedenti invece della sequenza originale stessa.
Non appena discutiamo l'analisi degli incrementi, è impossibile non commentare alcuni punti correlati.
In vari articoli e forum la necessità di passare all'analisi degli incrementi è giustificata in modo tale da poter lasciare l'impressione sbagliata sulle proprietà di tale transizione. L'analisi della transizione agli incrementi è spesso descritta come una sorta di trasformazione che è in grado di trasformare una sequenza originale in una stazionaria o normalizzare la sua legge di distribuzione. Ma è vero? Proviamo a rispondere a questa domanda.
Dobbiamo iniziare dal fatto che l'essenza della transizione all'analisi degli incrementi è composta da un'idea molto semplice di dividere una sequenza originale in due componenti. Possiamo dimostrarlo come segue.
Supponiamo di avere la sequenza di input
![]()
E abbiamo deciso di dividerlo, per qualsiasi motivo, in una tendenza e alcuni elementi rimanenti, che sono apparsi dopo la sottrazione dei valori di tendenza, dagli elementi della sequenza originale. Supponiamo di aver deciso di utilizzare una media mobile semplice con un periodo di smoothing pari a due elementi di sequenza per un'approssimazione di tendenza.
Tale media mobile può essere calcolata come la somma di due elementi di sequenza adiacenti divisi per due. In tal caso, il residuo dalla sottrazione della media dalla sequenza originale sarà uguale alla differenza tra gli stessi elementi adiacenti divisi per due.
Denotiamo il valore medio sopra menzionato come S, mentre il residuo sarà D. Nel caso in cui spostiamo il fattore permanente 2 nella parte sinistra dell'equazione per maggiore chiarezza, otterremo quanto segue:
![]()
Dopo aver completato le nostre trasformazioni abbastanza semplici, abbiamo diviso la nostra sequenza originale in due componenti, uno dei quali è la somma dei valori delle sequenze adiacenti e l'altro è costituito dalle differenze. Queste sono esattamente le sequenze che chiamiamo incrementi, mentre le somme formano la tendenza.
A questo proposito, sarebbe più ragionevole considerare gli incrementi come una parte della sequenza originale. Pertanto, non dobbiamo dimenticare che, se passiamo all'analisi degli incrementi, l'altra parte della sequenza definita dalle somme viene spesso semplicemente ignorata, a meno che non la analizziamo separatamente, ovviamente.
Il modo più semplice per avere un'idea di che tipo di benefici possiamo ricevere con questa divisione della sequenza è applicare il metodo spettrale.
Direttamente dalle espressioni sopra riportate, possiamo ricavare che la componente S è il risultato della filtrazione di sequenza originale con l'uso del filtro a bassa frequenza avente le caratteristiche di impulso h=1.1. Di conseguenza, il componente D è il risultato della filtrazione con l'uso del filtro ad alta frequenza con le caratteristiche di impulso h = -1,1. La fig.8 visualizza nominalmente le caratteristiche di frequenza di tali filtri.

Fig.8. Caratteristiche ampiezza-frequenza
Supponiamo di essere passati dall'analisi diretta della sequenza stessa all'analisi delle sue differenze. Cosa possiamo aspettarci qui? Ci sono varie opzioni in quel caso. Daremo una breve occhiata solo ad alcuni di essi.
- Nel caso in cui l'energia di base del processo analizzato sia concentrata nella regione a bassa frequenza della sequenza originale, la transizione all'analisi delle differenze sopprimerà semplicemente quell'energia, rendendola più complessa o addirittura impossibile continuare l'analisi;
- Nel caso in cui l'energia di base del processo analizzato sia concentrata nella regione ad alta frequenza della sequenza originale, la transizione all'analisi delle differenze può portare a effetti positivi a causa della filtrazione dei componenti interferenti a bassa frequenza. Ma questo è possibile solo nel caso in cui tale filtrazione non influenzi in modo significativo le proprietà del processo analizzato;
- Possiamo anche menzionare il caso in cui l'energia del processo analizzato è uniformemente distribuita su tutta la gamma di frequenze della sequenza. In tal caso. distorceremo irreversibilmente il processo dopo il passaggio all'analisi delle sue differenze, sopprimendo la sua parte a bassa frequenza.
Allo stesso modo possiamo trarre conclusioni sui risultati della transizione all'analisi delle differenze per qualsiasi altra combinazione di tendenza, tendenza a breve termine, rumore interferente e così via. Ma, in ogni caso, la transizione all'analisi delle differenze non porterà a una forma stazionaria del processo analizzato e non normalizzerà il processo di distribuzione.
Sulla base di quanto sopra detto, possiamo concludere che una sequenza non "migliora" automaticamente dopo il passaggio all'analisi delle differenze. Possiamo supporre che, in alcuni casi, sia meglio analizzare sia la sequenza di input che le differenze insieme alle somme dei suoi valori adiacenti per ricevere una conoscenza più chiara della sequenza di input, mentre le conclusioni finali sulle proprietà di questa sequenza devono essere fatte sulla base della revisione congiunta di tutti i risultati ottenuti.
Torniamo all'argomento del nostro articolo e vediamo come si comporta la trasformazione di Box-Cox in caso di transizione all'analisi degli incrementi della sequenza EURUSD M1 mostrata nella fig.6. Per fare ciò, useremo lo script BoxCoxTest3.mq5 mostrato in precedenza, in cui sostituiremo i valori della sequenza con differenze (incrementi) dopo aver calcolo questi valori di sequenza dal file. Poiché non vengono implementate altre modifiche al codice sorgente dello script, non ha senso pubblicarlo. Mostreremo invece solo i risultati della sua analisi del funzionamento.

Fig.9. Incrementi EURUSD M1. Test di Jarque-Bera JB=32494.8, p=0.000

Fig.10. Sequenza trasformata. Lambda parameter=0.6662, test di Jarque-Bera JB=10302.5, p=0.000
La fig.9 mostra le caratteristiche della sequenza costituita da incrementi EURUSD M1 (differenze), mentre la fig.10 mostra le sue caratteristiche ottenute dopo la trasformazione di Box-Cox. Nonostante il fatto che il valore del test di Jarque-Bera sia diminuito di oltre tre volte da JB = 32494.8 a JB = 10302.5 dopo la trasformazione, la legge di distribuzione della sequenza trasformata è ancora lontana dalla normalità.
Tuttavia, non dobbiamo saltare a conclusioni affrettate pensando che la trasformazione di Box-Cox non possa far fronte correttamente alla trasformazione degli incrementi. Abbiamo considerato solo un caso speciale. Avendo a che fare con altre sequenze di input, potremmo ottenere risultati completamente diversi.
6. Esempi citati
Tutti gli esempi precedentemente citati della trasformazione di Box-Cox si riferiscono al caso in cui la legge di distribuzione della sequenza originale deve essere ridotta a quella normale o, forse, alla legge che è il più vicino possibile a quella normale. Come è stato accennato all'inizio, tale trasformazione può essere necessaria quando si utilizzano i metodi di analisi parametrica, i quali possono essere abbastanza sensibili alla deviazione di una legge di distribuzione della sequenza esaminata da quella normale.
Gli esempi mostrati hanno dimostrato che in tutti i casi dopo la trasformazione, secondo i risultati del test di Jarque-Bera, abbiamo effettivamente ricevuto le sequenze con la legge di distribuzione più vicina a quella normale rispetto alle sequenze originali. Questo fatto mostra chiaramente la versatilità e l'efficienza della trasformazione di Box-Cox.
Ma non dobbiamo sopravvalutare le possibilità della trasformazione di Box-Cox e presumere che qualsiasi sequenza di input sarà trasformata in una strettamente normale. Come si può vedere dagli esempi precedenti, questo è tutt'altro che vero. Né la sequenza originale, né quella trasformata possono essere considerate normali per le quotazioni effettive.
La trasformazione di Box-Cox è stata considerata solo nella sua forma più visiva e a un parametro, finora. Questo è stato fatto per semplificare il primo incontro con essa. Questo approccio è giustificato per dimostrare le capacità di questa trasformazione, ma per scopi pratici sarebbe probabilmente meglio usare una forma più generale della sua presentazione.
7. La forma generale della trasformazione di Box-Cox
Va ricordato che la trasformazione di Box-Cox è applicabile solo alle sequenze con valori positivi e diversi da zero. In pratica, questo requisito è facilmente soddisfatto da un semplice spostamento di una sequenza nell'area positiva, ma l'entità dello spostamento all'interno dell'area positiva può avere un impatto diretto sul risultato della trasformazione.
Pertanto, il valore di spostamento può essere considerato come un parametro di trasformazione aggiuntivo e ottimizzarlo insieme al parametro lambda, non consentendo ai valori della sequenza di entrare nell'area negativa.
Per la sequenza originale X di N lunghezza:
![]()
le espressioni che determinano la forma più generale della trasformazione di Box-Cox a due parametri sono le seguenti:
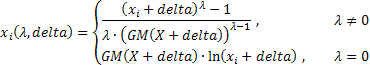
dove:
![]() ;
;
GM() - media geometrica.
La media geometrica della sequenza può essere calcolata nel modo seguente:
![]()
Come possiamo vedere, due parametri sono già utilizzati nelle espressioni mostrate: lambda e delta. Ora, dobbiamo ottimizzare entrambi questi parametri contemporaneamente durante la trasformazione. Nonostante la leggera complicazione dell'algoritmo, l'introduzione di un parametro aggiuntivo può certamente aumentare l'efficienza di trasformazione. Inoltre, i fattori di normalizzazione aggiuntivi sono apparsi nelle espressioni rispetto alla trasformazione utilizzata in precedenza. Con questi fattori il risultato della trasformazione manterrà la sua dimensione durante l'alterazione del parametro lambda.
Ulteriori informazioni sulla trasformazione di Box-Cox sono disponibili su[7], [8]. Alcune altre trasformazioni dello stesso tipo sono brevemente descritte in [8].
Ecco le caratteristiche principali della forma di trasformazione attuale e più generale:
- la trasformazione stessa richiede dalla sequenza di input di contenere solo valori positivi; l'inclusione del parametro delta aggiuntivo consente di eseguire automaticamente lo spostamento richiesto della sequenza quando si soddisfano alcune condizioni definite;
- quando si seleziona il valore ottimale del parametro delta, la sua grandezza deve garantire la "positività" di tutti i valori di sequenza;
- la trasformazione è continua in caso di alterazione del parametro lambda, comprese le variazioni prossime al suo valore zero;
- il risultato della trasformazione mantiene la sua dimensione in caso di alterazione del valore del parametro lambda.
Il criterio logaritmo della funzione di verosimiglianza è stato utilizzato in tutti gli esempi precedentemente citati durante la ricerca del valore ottimale del parametro lambda. Naturalmente, questo non è l'unico modo per stimare il valore ottimale dei parametri di trasformazione.
Ad esempio, possiamo menzionare il metodo dell'ottimizzazione dei parametri, in cui viene cercato il valore massimo del coefficiente di correlazione tra una sequenza trasformata ordinata in modo ascendente e una sequenza dei quantili della funzione di distribuzione normale. Questa variante è stata precedentemente menzionata nell'articolo. I valori dei quantili della funzione di distribuzione normale possono essere calcolati secondo le espressioni suggerite da James J. Filliben [9].
Le espressioni che determinano la forma generale della trasformazione a due parametri sono certamente più ingombranti di quelle precedentemente considerate. Forse, questa è la ragione del fatto che questo tipo di trasformazione è usato abbastanza raramente in pacchetti matematici e statistici. Le espressioni citate sono state realizzate in MQL5 per avere la possibilità di utilizzare la trasformazione di Box-Cox in forma più generale, se necessario.
Il file CFullBoxCox.mqh contiene il codice sorgente della classe CFullBoxCox, la quale esegue la ricerca del valore ottimale dei parametri di trasformazione. Come è già stato accennato, il processo di ottimizzazione si basa sul calcolo del coefficiente di correlazione.
//+------------------------------------------------------------------+ //| CFullBoxCox.mqh | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "PowellsMethod.mqh" //+------------------------------------------------------------------+ //| CFullBoxCox class | //+------------------------------------------------------------------+ class CFullBoxCox:public PowellsMethod { protected: int Dlen; // data size double Dat[]; // input data array double Shift[]; // input data array with the shift double BCDat[]; // transformed data (Box-Cox) double Mean; // transformed data average value double Cdf[]; // Quantile of the distribution cumulative function double Scdf; // Square root of summ of Quantile^2 double R; // correlation coefficient double DeltaMin; // Delta minimum value double DeltaMax; // Delta maximum value double Par[2]; // parameters array public: void CFullBoxCox(void) { } void CalcPar(double &dat[]); double GetPar(int n) { return(Par[n]); } private: double ndtri(double y0); // the function opposite to the normal distribution function virtual double func(const double &p[]); }; //+------------------------------------------------------------------+ //| CalcPar | //+------------------------------------------------------------------+ void CFullBoxCox::CalcPar(double &dat[]) { int i; double a,max,min; Dlen=ArraySize(dat); ArrayResize(Dat,Dlen); ArrayResize(Shift,Dlen); ArrayResize(BCDat,Dlen); ArrayResize(Cdf,Dlen); //--- copy the input data array ArrayCopy(Dat,dat); Scdf=0; a=MathPow(0.5,1.0/Dlen); Cdf[Dlen-1]=ndtri(a); Scdf+=Cdf[Dlen-1]*Cdf[Dlen-1]; Cdf[0]=ndtri(1.0-a); Scdf+=Cdf[0]*Cdf[0]; a=Dlen+0.365; for(i=1;i<(Dlen-1);i++) { //--- calculation of the distribution cumulative function Quantile Cdf[i]=ndtri((i+0.6825)/a); //--- calculation of the sum of Quantile^2 Scdf+=Cdf[i]*Cdf[i]; } //--- square root of the sum of Quantile^2 Scdf=MathSqrt(Scdf); min=dat[0]; max=min; for(i=0;i<Dlen;i++) { //--- copy the input data a=dat[i]; Dat[i]=a; if(min>a)min=a; if(max<a)max=a; } //--- Delta minimum value DeltaMin=1e-5-min; //--- Delta maximum value DeltaMax=(max-min)*200-min; //--- Lambda initial value Par[0]=1.0; //--- Delta initial value Par[1]=(max-min)/2-min; //--- optimization using Powell method Optimize(Par); } //+------------------------------------------------------------------+ //| func | //+------------------------------------------------------------------+ double CFullBoxCox::func(const double &p[]) { int i; double a,b,c,lam,del,k1,k2,gm,gmpow,mean,ret; lam=p[0]; del=p[1]; k1=0; k2=0; if (lam>5.0){k1=(lam-5.0)*400; lam=5.0;} // Lambda > 5.0 else if(lam<-5.0){k1=-(lam+5.0)*400; lam=-5.0;} // Lambda < -5.0 if (del>DeltaMax){k2=(del-DeltaMax)*400; del=DeltaMax;} // Delta > DeltaMax else if(del<DeltaMin){k2=(DeltaMin-del)*400; del=DeltaMin; // Delta < DeltaMin gm=0; for(i=0;i<Dlen;i++) { Shift[i]=Dat[i]+del; gm+=MathLog(Shift[i]); } //--- geometric mean gm=MathExp(gm/Dlen); gmpow=lam*MathPow(gm,lam-1); mean=0; //--- Lambda != 0.0 if(lam!=0) { for(i=0;i<Dlen;i++) { a=(MathPow(Shift[i],lam)-1.0)/gmpow; //--- transformed data (Box-Cox) BCDat[i]=a; //--- average value mean+=a; } } //--- Lambda == 0.0 else { for(i=0;i<Dlen;i++) { a=gm*MathLog(Shift[i]); //--- transformed data (Box-Cox) BCDat[i]=a; //--- average value mean+=a; } } mean=mean/Dlen; //--- sorting of the transformed data array ArraySort(BCDat); a=0; b=0; for(i=0;i<Dlen;i++) { c=(BCDat[i]-mean); a+=Cdf[i]*c; b+=c*c; } //--- correlation coefficient ret=a/(Scdf*MathSqrt(b)); return(k1+k2-ret); } //+------------------------------------------------------------------+ //| The function opposite to the normal distribution function | //| Prototype: | //| Cephes Math Library Release 2.8: June, 2000 | //| Copyright 1984, 1987, 1989, 2000 by Stephen L. Moshier | //+------------------------------------------------------------------+ double CFullBoxCox::ndtri(double y0) { static double s2pi =2.50662827463100050242E0; // sqrt(2pi) static double P0[5]={-5.99633501014107895267E1, 9.80010754185999661536E1, -5.66762857469070293439E1, 1.39312609387279679503E1, -1.23916583867381258016E0}; static double Q0[8]={ 1.95448858338141759834E0, 4.67627912898881538453E0, 8.63602421390890590575E1, -2.25462687854119370527E2, 2.00260212380060660359E2, -8.20372256168333339912E1, 1.59056225126211695515E1, -1.18331621121330003142E0}; static double P1[9]={ 4.05544892305962419923E0, 3.15251094599893866154E1, 5.71628192246421288162E1, 4.40805073893200834700E1, 1.46849561928858024014E1, 2.18663306850790267539E0, -1.40256079171354495875E-1,-3.50424626827848203418E-2, -8.57456785154685413611E-4}; static double Q1[8]={ 1.57799883256466749731E1, 4.53907635128879210584E1, 4.13172038254672030440E1, 1.50425385692907503408E1, 2.50464946208309415979E0, -1.42182922854787788574E-1, -3.80806407691578277194E-2,-9.33259480895457427372E-4}; static double P2[9]={ 3.23774891776946035970E0, 6.91522889068984211695E0, 3.93881025292474443415E0, 1.33303460815807542389E0, 2.01485389549179081538E-1, 1.23716634817820021358E-2, 3.01581553508235416007E-4, 2.65806974686737550832E-6, 6.23974539184983293730E-9}; static double Q2[8]={ 6.02427039364742014255E0, 3.67983563856160859403E0, 1.37702099489081330271E0, 2.16236993594496635890E-1, 1.34204006088543189037E-2, 3.28014464682127739104E-4, 2.89247864745380683936E-6, 6.79019408009981274425E-9}; double x,y,z,y2,x0,x1,a,b; int i,code; if(y0<=0.0){Print("Function ndtri() error!"); return(-DBL_MAX);} if(y0>=1.0){Print("Function ndtri() error!"); return(DBL_MAX);} code=1; y=y0; if(y>(1.0-0.13533528323661269189)){y=1.0-y; code=0;} // 0.135... = exp(-2) if(y>0.13533528323661269189) // 0.135... = exp(-2) { y=y-0.5; y2=y*y; a=P0[0]; for(i=1;i<5;i++)a=a*y2+P0[i]; b=y2+Q0[0]; for(i=1;i<8;i++)b=b*y2+Q0[i]; x=y+y*(y2*a/b); x=x*s2pi; return(x); } x=MathSqrt(-2.0*MathLog(y)); x0=x-MathLog(x)/x; z=1.0/x; //--- y > exp(-32) = 1.2664165549e-14 if(x<8.0) { a=P1[0]; for(i=1;i<9;i++)a=a*z+P1[i]; b=z+Q1[0]; for(i=1;i<8;i++)b=b*z+Q1[i]; x1=z*a/b; } else { a=P2[0]; for(i=1;i<9;i++)a=a*z+P2[i]; b=z+Q2[0]; for(i=1;i<8;i++)b=b*z+Q2[i]; x1=z*a/b; } x=x0-x1; if(code!=0)x=-x; return(x); } //------------------------------------------------------------------------------------
Alcune limitazioni vengono applicate all'intervallo di alterazione dei parametri di trasformazione durante l'ottimizzazione. Il valore del parametro lambda è limitato dai valori 5.0 e -5.0. Le limitazioni per i parametri delta sono specificate in relazione al valore minimo della sequenza di input. Questo parametro è limitato dai valori DeltaMin=(0.00001-min) e DeltaMax=(max-min)*200-min, dove min e max sono i valori minimo e massimo degli elementi della sequenza di input.
Lo script FullBoxCoxTest.mq5 illustra l'utilizzo della classe CFullBoxCox. Il codice sorgente di questo script è mostrato di seguito.
//+------------------------------------------------------------------+ //| FullBoxCoxTest.mq5 | //| 2012, victorg | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "2012, victorg" #property link "https://www.mql5.com" #include "CFullBoxCox.mqh" CFullBoxCox Bc; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { int i,n; double dat[],shift[],bcdat[],lambda,delta,gm,gmpow; string fname; //--- input file name fname="Dataset2\\EURUSD_M1_1200.txt"; //--- reading the data if(readCSV(fname,dat)<0){Print("Error."); return;} //--- data size n=ArraySize(dat); //--- shifted input data array ArrayResize(shift,n); //--- transformed data array ArrayResize(bcdat,n); //--- lambda and delta parameters optimization Bc.CalcPar(dat); lambda=Bc.GetPar(0); delta=Bc.GetPar(1); PrintFormat("Iterations= %i, lambda= %.4f, delta= %.4f", Bc.GetIter(),lambda,delta); gm=0; for(i=0;i<n;i++) { shift[i]=dat[i]+delta; gm+=MathLog(shift[i]); } //--- geometric mean gm=MathExp(gm/n); gmpow=lambda*MathPow(gm,lambda-1); if(lambda!=0){for(i=0;i<n;i++)bcdat[i]=(MathPow(shift[i],lambda)-1.0)/gmpow;} else {for(i=0;i<n;i++)bcdat[i]=gm*MathLog(shift[i]);} //--- dat[] <-- input data //--- shift[] <-- input data with the shift //--- bcdat[] <-- transformed data } //+------------------------------------------------------------------+ //| readCSV | //+------------------------------------------------------------------+ int readCSV(string fnam,double &dat[]) { int n,asize,fhand; fhand=FileOpen(fnam,FILE_READ|FILE_CSV|FILE_ANSI); if(fhand==INVALID_HANDLE) { Print("FileOpen Error!"); return(-1); } asize=512; ArrayResize(dat,asize); n=0; while(FileIsEnding(fhand)!=true) { dat[n++]=FileReadNumber(fhand); if(n+128>asize) { asize+=128; ArrayResize(dat,asize); } } FileClose(fhand); ArrayResize(dat,n-1); return(0); } //------------------------------------------------------------------------------------
La sequenza di input viene caricata nell'array dat[] dal file all'inizio dello script e quindi viene eseguita la ricerca dei valori ottimali dei parametri di trasformazione. Quindi la trasformazione stessa viene eseguita con l'uso dei parametri ottenuti. Di conseguenza, l'array dat[] contiene la sequenza originale, l'array shift[] contiene la sequenza originale spostata dal valore delta e l'array bcdat[] contiene il risultato della trasformazione di Box-Cox.
Tutti i file necessari per la compilazione di script FullBoxCoxTest.mq5 si trovano nell'archivio Box-Cox-Tranformation_MQL5.zip.
La trasformazione delle sequenze di test che utilizziamo viene eseguita con l'aiuto dello script FullBoxCoxTest.mq5. Come ci si aspettava, durante l'analisi dei dati ottenuti possiamo concludere che questo tipo di trasformazione a due parametri mostra risultati leggermente migliori rispetto al tipo a un parametro. Ad esempio, per la sequenza EURUSD M1, i cui risultati dell'analisi sono mostrati nella fig.6, il valore del Test di Jarque-Bera comprendeva JB = 100,94. JB=39.30 dopo la trasformazione a un parametro (vedi fig.7), ma dopo la trasformazione a due parametri (script FullBoxCoxTest.mq5) questo valore è sceso a JB=37.49.
Conclusione
In questo articolo abbiamo esaminato i casi in cui i parametri di trasformazione di Box-Cox sono stati ottimizzati in modo che la legge di distribuzione della sequenza risultante fosse il più vicino possibile a quella normale. Ma, in pratica, i casi possono verificarsi quando la trasformazione di Box-Cox deve essere utilizzata in un modo leggermente diverso. Ad esempio, il seguente algoritmo può essere utilizzato quando si prevedono le sequenze temporali:
- vengono selezionati i valori preliminari dei parametri di trasformazione di Box-Cox e i modelli previsionali;
- viene eseguita la trasformazione di Box-Cox dei dati di input;
- la previsione viene effettuata in base ai parametri attuali;
- la trasformazione di Box-Cox inversa viene effettuata per i risultati previsionali;
- l'errore di previsione viene valutato dalla sequenza di input non tradotta;
- i valori dei parametri vengono modificati per ridurre al minimo l'errore di previsione e l'algoritmo ritorna al passaggio 2.
Nell'algoritmo sopra i parametri di trasformazione devono essere minimizzati dal criterio minimo dell'errore di previsione, così come quelli del modello previsionale. In questo caso, l'obiettivo della trasformazione di Box-Cox non è ancora la trasformazione della sequenza di input nella legge di distribuzione normale.
Ora, è necessario trasformare la sequenza di input per ricevere la legge di distribuzione fornendo l'errore minimo di previsione. A seconda del metodo di previsione selezionato, questa legge di distribuzione non deve necessariamente essere normale.
La trasformazione di Box-Cox è applicabile solo alle sequenze con valori positivi e diversi da zero. Lo spostamento della sequenza di input deve essere eseguito in tutti gli altri casi. Questa caratteristica della trasformazione può certamente essere definita uno dei suoi svantaggi. Ma nonostante questo, la trasformazione di Box-Cox è probabilmente lo strumento più versatile ed efficiente tra le altre trasformazioni dello stesso tipo.
Elenco delle referenze
- А.N. Porunov. Box-Сox Transformation and the Illusion of «Normality» of Macroeconomic Series. "Business Informatics" journal, №2(12)-2010, pp. 3-10.
- Mohammad Zakir Hossain, The Use of Box-Cox Transformation Technique in Economic and Statistical Analyses. Journal of Emerging Trends in Economics and Management Sciences (JETEMS) 2(1):32-39.
- Box-Cox Transformations.
- L'articolo "Time Series Forecasting Using Exponential Smoothing".
- L'articolo "Time Series Forecasting Using Exponential Smoothing (continued)".
- Analysis of the Main Characteristics of Time Series.
- Power transform.
- Draper N.R. and H. Smith, Applied Regression Analysis, 3rd ed., 1998, John Wiley & Sons, New York.
- Q-Q plot.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/363
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 Sbarazzarsi delle DLL auto-prodotte
Sbarazzarsi delle DLL auto-prodotte
 Alcuni suggerimenti per i clienti alle prime armi
Alcuni suggerimenti per i clienti alle prime armi
 Chi è chi nella MQL5.community?
Chi è chi nella MQL5.community?
 Analisi di regressione multipla. Generatore di strategie e tester tutto in uno
Analisi di regressione multipla. Generatore di strategie e tester tutto in uno
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Victor, pensi che in caso di scarsa approssimazione alla normalità dopo la trasformazione BC sia ragionevole riapplicare la stessa trasformazione?
Non lo so, ma credo che una nuova applicazione della trasformazione non avrà più lo stesso effetto della prima.
Mi sembra che questo tipo di trasformazioni non sia perfetto. L'applicazione di questa trasformazione, così come di qualsiasi altra, porta a modificare le caratteristiche iniziali della sequenza in ingresso (probabilmente). E qui la cosa principale è non esagerare, altrimenti la sequenza ottenuta dopo la trasformazione non avrà nulla in comune con quella originale. Probabilmente è per questo che non sono molto diffuse le trasformazioni che possono portare qualsiasi sequenza in ingresso a una sequenza normale. Ma vorrei sottolineare ancora una volta che non ho preso in seria considerazione queste questioni.
Capisco. Sì, è un argomento piuttosto profondo. Si può, come si dice, vedere e rivedere.....
L'articolo è molto istruttivo. C'è un collegamento logico con quello che hai scritto prima. Grazie per il materiale.
Capisco. Sì, è un argomento piuttosto profondo. Si può, come si dice, vedere e rivedere.....
L'articolo è molto istruttivo. C'è un collegamento logico con quello che hai scritto prima. Grazie per il materiale.
Grazie per la valutazione del mio lavoro.
Se parliamo di trading, è interessante la stabilità delle caratteristiche del quoziente quando ci si sposta lungo di esso. Lei ha fornito le caratteristiche del cambiamento dopo la trasformazione senza spostamento, ma cosa succede al parametro BC quando si sposta di una barra in avanti? Se confrontiamo le caratteristiche statiche dello spostamento sequenziale lungo la cotir non trasformata con le caratteristiche statiche della cotir trasformata, cosa vediamo? La fluttuazione della varianza diminuisce con lo spostamento? Se diminuisce, è proprio questo il grande vantaggio del BC.
Questo articolo è stato concepito come un articolo di base, pensato principalmente per far conoscere al lettore le caratteristiche dei metodi statistici classici e per fornire una sorta di cassetta degli attrezzi per la sperimentazione. Le vostre domande vanno ben oltre lo scopo di questo articolo. Non sarò in grado di rispondere per voi.