Was soll in den Eingang des neuronalen Netzes eingespeist werden? Ihre Ideen... - Seite 30
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ein normales Netzwerk sortiert die notwendigen und unnötigen Daten von selbst.
Die Hauptsache ist, was man lehrt!
Das Lernen mit einem Lehrer ist hier nicht geeignet. Netze mit rückwärtiger Fehlerfortpflanzung sind einfach unbrauchbar.
Gibt es eine Vorstellung davon, wie der Mechanismus trainiert werden sollte? Im Grunde genommen gehen wir also über die Gewichte, passen sie an einen Graphen an. Aber gleichzeitig gibt es einen anderen Satz von Gewichten, einen Satz, der nicht nur an diesen Graphen angepasst ist, sondern an den nächsten, und den nächsten, und den nächsten, und so weiter.
Hier wird Lernen als das Finden des Unterschieds zwischen einer Reihe von Sätzen, die nicht funktionieren, und denen, die funktionieren, dargestellt.
Und außerdem braucht das trainierte Netz keine "Feinabstimmung" mehr, es ändert die Anzahl der Gewichte bereits von selbst. Welche anderen Vorstellungen gibt es darüber, wie maschinelles Lernen aussieht, wie es dargestellt wird?
Ein normales Netzwerk sortiert die notwendigen und unnötigen Daten von selbst.
Die Hauptsache ist, was man lehrt!
Das Lernen mit einem Lehrer ist hier nicht geeignet. Netze mit rückwärtiger Fehlerfortpflanzung sind einfach unbrauchbar.
Das Netz sortiert nichts - es wählt die Variablen aus, die am besten zur Trainingsstichprobe passen.
Eine große Anzahl von Variablen ist ein großes Übel
Das Netz sortiert nichts - es wählt die Variablen aus, die am besten zur Trainingsstichprobe passen.
Einegroße Anzahl von Variablen ist das Hauptübel
Für das Auswendiglernen des Pfades - das Beste Für das Lernen (nach dem derzeitigen Verständnis) - das größte Übel.
trainieren Sie zwei Raster - eines nur für den Kauf, eines für den Verkauf.
beide einschalten :-)
Fügen Sie dann ein Netz zur Kollisionsauflösung hinzu (oder einfach nur alg.), damit sie nicht gleichzeitig in verschiedene Richtungen handeln.
Ich habe mir überlegt, dass man das Markup skripten könnte. Schreiben Sie alle Daten auf, an denen der Einstieg und der Ausstieg erfolgt. Wenn der Optimierer Gewichte setzt, die ein Signal außerhalb dieser Daten geben, öffnen wir mit dem maximalen Lot, das wir verlieren können. Oder wir eröffnen überhaupt nicht.
Es stellt sich heraus, dass es eine Methode mit einem Lehrer, sondern durch MT5 Kräfte sein wird
Ein neuronales Netz kann sogar mit 1 Wert eines Merkmals arbeiten, wenn man die Parameter auswählt
aber wir brauchen Gralsbedingungen (dts) mit fast keiner Streuung. Ich denke, dass jeder TS unter solchen Bedingungen funktionieren wird :)
Gibt es eine Möglichkeit zu beschreiben, wie man die Maschine zwingt, eine Position zu öffnen, wenn sie es für richtig hält? Wie würden wir es erklären: Wir zwingen das neuronale Netz, selbst Positionen zu öffnen.... "wenn, dann". Wir geben an, wann geöffnet werden soll: "Wenn der Output des neuronalen Netzes größer als 0,6 ist", "wenn von den beiden Output-Neuronen das obere den höheren Wert hat".
"Wenn - dann, wenn - dann." Und so weiter. Und hier, damit es keine Öffnungsgrenzen, Bedingungen gibt. Es gibt Eingaben, es gibt Gewichte. Im Inneren des neuronalen Netzes braut sich eine Art Brei zusammen.
Ist es möglich, der Maschine auf der Grundlage ihrer Arbeit mit Eingaben und Gewichten (die im Optimierer zu suchen sind) irgendwie zu beschreiben, dass sie Positionen öffnen soll, wenn sie sich dafür entscheidet? Wie kann diese Bedingung vorgeschrieben werden? Damit sie entscheidet, wann sie Positionen öffnet.
UPD Fügen Sie ein zweites neuronales Netz hinzu.
Wie kann man es dann verknüpfen... Oder mehrere neuronale Netze.
Oder gibt es eine andere Möglichkeit, eine solche Aufgabe zu beschreiben?
UPD Füge einen Erfahrungsblock hinzu.
Dann stellt sich heraus, dass es sich um eine Art q-Tabelle handelt. Und wir müssen alles innerhalb des neuronalen Netzes haben.
... Wie kann ich diese Bedingung einstellen? Damit er wählen kann, wann er.... öffnen soll.
Hier kann ich Ihnen helfen: Geben Sie gleichzeitig Kauf- und Verkaufssignale, und das Neuron wird entscheiden, wohin es gehen soll. Danken Sie mir nicht...
Zum ersten Mal gelang es mir, einen Satz in der Spitze von einem Arbeiter zu bekommen. Außerdem, ein Arbeiter für so viel wie 3 Jahre vorwärts.
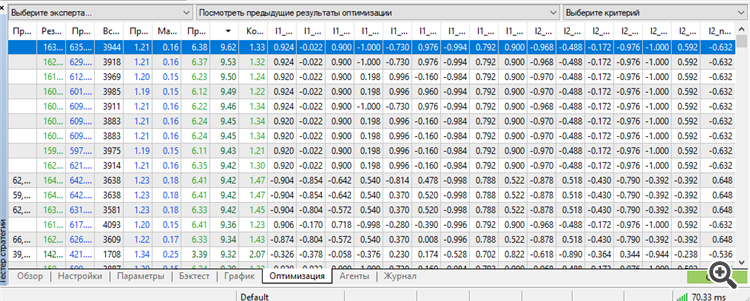
Ausbildung für 9 Jahre von 2012 bis 2021
Vorwärts 2021
Vorwärts 2022
Vorwärts 2023
Alle 3 Jahre im Voraus 2021-2023.12.13.
Es stimmt, wir mussten das volle Potenzial von MT5 ausschöpfen: die maximale Anzahl optimierbarer Parameter-Gewichte.
Mehr - MT5 schwört. Wenn es möglich wäre, mehr Parameter zu optimieren, wäre es interessanter, die Ergebnisse zu kennen. Ich bin verblüfft über diese Aufschrift "64 Bits zu lang" oder so ähnlich. Wenn der genetische Algorithmus es erlaubt, noch mehr zu optimieren, wäre es interessant zu wissen, wie man diese Einschränkung umgehen kann.
wenn mehr Parameter optimiert werden könnten
Umstieg von Toyota auf einen alten Sportwagen Da MT5 in der Anzahl der optimierbaren Parameter begrenzt ist, bin ich auf NeuroPro 1999 umgestiegen, aus dem Artikel hier -Neural Networks for Free and Easy - Connecting NeuroPro and MetaTrader 5.
Ich habe die Architektur in der Quantität erhöht: in MT5 war es 5-5-5-5, und hier ist es 10-10-10, und das Training ist bereits real (um genauer zu sein - Standard, durch die Methode der Fehlerrückvermehrung und andere interne Funktionen innerhalb des Programms.
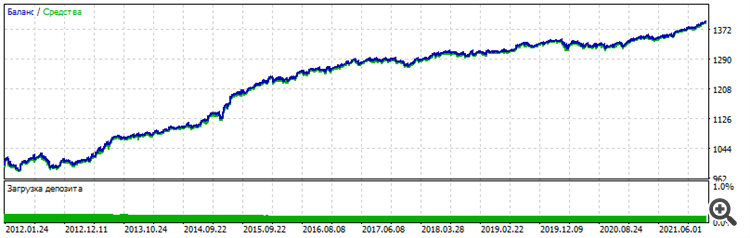


Der Autor des Programms hat darauf gespuckt und wird nicht einmal die Seltenheit aktualisieren - basierend auf seinen Antworten auf meine Fragen, hat er kein Interesse daran, NeoroPro weiterzuentwickeln, Multithreading, moderne Methoden einzuführen usw.). Überraschenderweise kann das Programm ähnliche Ergebnisse wie MT5 produzieren. Aber es ist leicht, die Vorwärtsbewegung zu unterbrechen - fügen Sie ein weiteres Neuron hinzu/fügen Sie eine weitere Schicht hinzu/verringern Sie die Datenmenge um einen Monat und alles wird zufällig.
Das heißt, wir müssen eine goldene Mitte zwischen Übertraining und Untertraining finden. Außerdem funktioniert das Modell nach dem Training immer noch nicht. Wir brauchen eine Nachoptimierung der MT5-Parameter - Eröffnungsschwellen für BUY und SELL. Etwas Ähnliches wurde seinerzeit von NeuroMachine, den Machern von MeGatrader, gemacht.
Das heißt, eine Art von Post-Processing. Ohne sie, die Balance-Chart bewegt sich kaum nach oben auf die gelehrt Zeitraum und Abflüsse auf den Forward. Bedingungen haben sich geändert: 6 Einträge bereits, EURUSD H1, zu Eröffnungspreisen, 10 Jahre Lehre von 2012 bis 2022.
Forward - die letzten zwei Jahre 2022-2023-12-16
Gesamtchart - Sie können sehen, dass ähnliche Stabilität, Charakter ist identisch, es sieht nicht wie Glück
Ich werde andere Paare versuchen und die Architektur erhöhen, um den Glücksfaktor vollständig auszuschließen und die Leistung der Methode zu bestätigen. Nun und vor allem - Post-Optimierung - die Arbeitsgruppe war in der Spitze in der Sortierung nach dem "Recovery-Faktor" Parameter. Wenn dies zu einem späteren Zeitpunkt nicht der Fall ist, gibt es keine Bestätigung. Wieder werde ich auf Zufall, Glück und Pech angewiesen sein.
Die Methode des kreativen Stocherns brachte mich auf eine Idee: Eine Schicht von Neuronen im klassischen Sinne ist ein Haufen Ungemach.
Vor allem die erste Schicht, die Eingangsdaten empfängt.
Die wichtigste Schicht. Der Input sind heterogene Daten. Oder homogen - das spielt keine Rolle. Jede Ziffer, jede Zahl ist eine Darstellung von Form, Inhalt, Abhängigkeit - im Original.
Es ist wie eine Quelle, wie ein Film, wie ein Foto. Und stellen Sie sich vor, ein gewöhnliches neuronales Netz nimmt jede Zahl, jedes Attribut - und summiert es dummerweise, zusätzlich multipliziert mit dem Gewicht, zu einem Haufen Müll, genannt Addierer. Das ist, als würde man ein Foto unscharf machen und versuchen, das Bild wiederherzustellen - nichts wird funktionieren. Das war's. Die Quelle ist verloren, ausgelöscht. Sie ist verschwunden. Jegliche Wiederherstellung reduziert sich auf eine Sache - zusätzliches Zeichnen. So arbeiten moderne neuronale Netze, um alte Fotos zu restaurieren oder sie zu verbessern, sie zu vergrößern - sie zeichnen sie einfach nach. Die kreative Arbeit des neuronalen Netzes hat keine Quelle, es nimmt das, was es einmal in seiner Bilddatenbank hatte, etwas Ähnliches, wenn auch nur zu 99 %, aber nicht die Quelle.
Und so füttern wir Preise, Preissteigerungen, umgewandelte Preise, Indikatordaten, Zahlen, in denen irgendeine Zahl, irgendein Zustand auf dem Diagramm kodiert ist - und es nimmt und löscht dummerweise die Einzigartigkeit jeder Zahl, wirft alle Zahlen in eine Grube und macht eine Schlussfolgerung (Output) auf der Grundlage dieses riesigen Mülls, in dem es unmöglich ist, zu erkennen, was was ist. Eine solche Zahl des Addierers wird von nun an identisch mit verschiedenen Zahlen sein, mit verschiedenen Zahlen. Das heißt, wir haben zwei Zahlen - sie werden in einer anderen Zahlenfolge angezeigt. Der Inhalt dieser Zahlen ist unterschiedlich, aber das Volumen kann das gleiche sein. Das Volumen ist numerisch. Und dann kann dieses Haufen-Mala im Addierer sowohl die eine als auch die andere Zahl bedeuten. Wir werden nie genau wissen, welche es ist - in diesem Stadium haben wir die eindeutige Information ausgelöscht.
Wir haben sie verschmiert, in einen Topf geworfen, jetzt ist es eine Suppe. Und wenn die Eingabe Müll ist? Dann wird der erste Addierer mit 1000-prozentiger Wahrscheinlichkeit diesen Müll in Müll zum Quadrat verwandeln. Und mit 1000%iger Wahrscheinlichkeit wird ein solches neuronales Netz niemals etwas aus diesem Müll herausfinden, niemals finden, niemals extrahieren. Denn in diesem Fall wühlt es sich nicht nur durch den Müll, sondern zerkleinert ihn auch in einem Fleischwolf namens "next layers".
Mein laienhafter Ansatz sagt mir, dass wir unsere Herangehensweise an Architekturen und die Art und Weise, wie wir Eingaben behandeln, ändern müssen. Als Beweis - meine obigen Diagramme. Ein Input, zwei Inputs, drei Inputs - ein Neuron, zwei Neuronen, drei Neuronen.
Das war's, als Nächstes kommt die Umschulung - das Auswendiglernen des Pfades, anstatt mit neuen Daten zu arbeiten. Die zweite Bestätigung ist die Umschulung selbst. Je mehr Neuronen, desto mehr Schichten - desto schlechter für neue Daten. Das heißt, mit jeder neuen Schicht, mit jedem neuen Neuron verwandeln wir die ursprünglichen Daten in Müll zum Quadrat, und alles, was dem neuronalen Netz bleibt, ist, sich den Weg einfach einzuprägen.
Und das kann es bei der Umschulung sehr gut. So eine kleine Verrücktheit.