Maschinelles Lernen im Handel: Theorie, Modelle, Praxis und Algo-Trading - Seite 1180
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ivan Negreshniy, ich verstehe nicht, ich habe das Modell in CatBoost erstellt, aber wie soll es verbunden werden, ist es die Brücke/Kanal von EA zu Python, wo Prädiktorwerte übergeben werden, und in die entgegengesetzte Richtung wird das Ergebnis der Berechnungen erhalten - eine konkrete Klasse?
Soweit ich verstehe, erlaubt CatBoost, einen Code des Modells zu entladen, die ich nicht verstehe, aber ich werde es für die Schätzung der professionellen beifügen, es sei denn, es kann in MQL irgendwie integriert werden und nicht Python dann zu verwenden? Und, CatBoost haben Bibliotheken in C++, sie können nicht machen sie in MQL arbeiten und verwenden Sie nicht Python und Konsole Befehle?
Was nicht klar ist, ist die Brücke für die End-to-End-Automatisierung der Arbeit mit Daten und Modelle direkt von Expert Advisor, einschließlich der Erstellung, Einrichtung, Ausbildung, etc. benötigt. Und was CatBoost Dumps in Dateien ist Serialisierung eines bestimmten Modells, das nur für Berechnungen verwendet werden kann.
Natürlich können Sie einen EA auf der Grundlage dieser Dateien im Editor erstellen, aber er wird sich nicht wesentlich von einem gewöhnlichen EA mit starrer Logik unterscheiden, und wenn dies das Ziel ist, ist es IMHO viel einfacher, es durch Training mit Vorlagen zu erreichen, was ich vorgeschlagen habe. https://www.mql5.com/ru/forum/270216
Da dort alles automatisch trainiert und generiert wird und der Code jedes Baumes in eine separate, logische Funktion umgewandelt wird, die leichter zu analysieren und schneller auszuführen ist, wenn Sie sie ausfüllen, können wir später vergleichen.
Für mich ist das in erster Linie arbeitsintensiv.
Die meisten Prädiktoren bündeln Indikatoren und fügen sie in die tägliche ATR ein. Der Rest der Zeitreihenarbeit besteht in der Charakterisierung der Prädiktoren.
Ich habe zwei Fragen
1) Erläutern Sie bitte, was das bedeutet - eine Reihe vonIndikatoren und deren Einpassung in das ATR-Tagebuch.
2) Warum catbust? Sind Sie sicher, dass er besser ist als andere Boosts?
Was hier nicht klar ist: Die Brücke wird für die durchgehende Automatisierung der Arbeit mit Daten und Modellen direkt aus dem EA benötigt, einschließlich Erstellung, Konfiguration, Schulung usw,
Ich verstehe, d.h. es geht in erster Linie um die Möglichkeit, eine eigene Schnittstelle für die Arbeit mit der MoD-Bibliothek zu erstellen, richtig? Dies ist gleichbedeutend mit der Tatsache, dass ich nun plane, die gleiche Schnittstelle zu verwenden, aber durch die Aktivierung einer Exe-Datei und die Eingabe von Befehlen in diese. Im Allgemeinen ist es ja interessant, es mit Python zu machen, aber ich habe leider keine solchen Kenntnisse.
und was CatBoost in Dateien ausgibt, ist die Serialisierung eines bestimmten Modells, das nur für Berechnungen verwendet werden kann.
Natürlich können wir einen EA auf der Grundlage dieser Dateien im Editor erstellen, aber er wird sich nicht wesentlich von einem gewöhnlichen EA mit starrer Logik unterscheiden, und wenn dies das Ziel ist, dann ist es IMHO viel einfacher, es durch Training mit Hilfe von Vorlagen zu erreichen, die ich vorgeschlagen habe. https://www. mql5.com/ru/forum/270216
Wenn Sie diesen Code verstehen, können Sie mir vielleicht sagen, wie ich ihn in eine lesbare Form übersetzen kann, z. B. indem ich jeder Regel eine fertige Beschreibung gebe, wie ich es für Blätter nach der Verarbeitung von Modellen aus R mache
Ich kann den Verschlüsselungsalgorithmus in diesem Code einfach nicht verstehen - können Sie dessen Beschreibung/Dolmetscher erstellen (vielleicht gegen eine Gebühr)?
Und wenn das das Ziel ist, ist es IMHO viel einfacher, es durch das Lernen von Mustern zu erreichen, was ich vorgeschlagen habe. https://www.mql5.com/ru/forum/270216
Da dort alles automatisch trainiert und generiert wird, und der Code jedes Baumes in eine separate, logische Funktion umgewandelt wird, ist das vielleicht einfacher für die Analyse und schneller zur Laufzeit, wenn Sie fertig sind, können wir später vergleichen.
Es geht nicht nur darum, ein Modell zu erhalten, sondern Blätter zu sammeln, sie zu bewerten und dann auf der Grundlage dieser Blätter neue Modelle zu erstellen.
Ich las dieses Thema und ich verstehe nicht ganz, der Prozess der automatischen Netze Gebäude wurde auf der Grundlage von nackten Indikatoren und Markup erstellt, die Informationen werden an die Vorlage übertragen, während ich Post-Processing von Indikatoren, plus ich einige meiner Indikatoren, die ich nicht öffentlich machen wollen, so stellt sich heraus, dass die Methode nicht verfügbar ist, und wieder - Sie können nicht Blätter aus ihm heraus...
Ich habe zwei Fragen
1) Erläutern Sie bitte, was es bedeutet,Indikatoren zu bündeln und sie in die ATR daily einzupassen
2) Warum catbust? Sind Sie sicher, dass es besser ist als andere Boosts? oder Gerüste
1. Dies ist meine Sicht des Marktes, d.h. der Preis hat einen Plan für die Bewegung, die durch ATR zu Beginn des Tages definiert ist, dann je nach den Hindernissen (Ebenen des Widerstands (Ebenen der Herstellung/Änderung von Handelsentscheidungen durch die Marktteilnehmer), die sind, einschließlich der Indikatoren), wird dieser Plan umgesetzt oder nicht. Prädiktoren beschreiben diese Hindernisse im Hinblick auf den Bewegungsplan. So sieht es grafisch aus - ein Raster entlang des ATR-Bereichs mit verschiedenen Indikatoren darin
Screenshots von der MetaTrader-Plattform
Si-9.18, M1, 2018.08.30
JSC ''Otkritie Broker'', MetaTrader 5, Real
Für Speicher
2. CatBoost - ich hatte gerade etwas Hilfe bei der Einrichtung des Systems. Außerdem funktioniert es offensichtlich schneller als mein früherer Ansatz, Modelle in R zu erstellen, und gleichzeitig war es effizienter, es gibt Dokumentation und Befehle über DOS :) Im Vergleich zu anderen Tools, z.B. Deductor Studio, ist es stabiler und die Modelle kommen besser heraus, außerdem ist das letzte kostenpflichtig, hier ist alles kostenlos.
Das könnte Sie interessieren, ich bin auf Folgendes gestoßen
Ich möchte ein System zur Baumoptimierung aufbauen, genauer gesagt, indem ich Bäume mit dem Optimierer baue... es ist ein interessantes Thema, aber ich weiß nicht, wo ich anfangen soll :))
https://explained.ai/
Vielen Dank für Ihr Interesse!
Die Sprachbarriere macht das Lesen mühsam, und die Übersetzer machen den Text entweder dumm oder lustig... leider.
übersetzen Sie ein Wort nach dem anderen mit dem Google Übersetzer Plugin für Chrome.
Ich benutze dasImTranslator-Plugin in Chrome, es funktioniert gut, wenn Sie einen Absatz auf einmal übersetzen, wenn Sie Wörter auswählen und mit der rechten Maustaste auf das Kontextmenü
kein Google-Klick nötig
Um welche Art von Plugin handelt es sich? Früher funktionierte es in Chrome, dann nicht mehr, und ich weiß nicht, wie ich es einrichten soll.
Verstehe, d.h. es ist vor allem eine Möglichkeit, eine eigene Schnittstelle für die Arbeit mit der MoD-Bibliothek zu schaffen, richtig? Dies ist gleichbedeutend mit der Tatsache, dass ich jetzt plane, die gleiche Schnittstelle zu schaffen, aber durch die Aktivierung einer Exe-Datei und die Eingabe von Befehlen in sie. Im Allgemeinen ist es ja interessant, es mit Python zu machen, aber ich habe leider keine solchen Kenntnisse.
Wenn Sie diesen Code verstehen, können Sie mir sagen, wie ich ihn in eine lesbare Form übersetzen kann, z. B. indem ich jeder Regel eine fertige Beschreibung gebe, wie ich es für Blätter nach der Verarbeitung von Modellen aus R mache
Ich kann den Verschlüsselungsalgorithmus in diesem Code einfach nicht verstehen - können Sie dessen Beschreibung/Dolmetscher erstellen (vielleicht gegen eine Gebühr)?
Es geht nicht nur darum, ein Modell zu erhalten, sondern Blätter zu sammeln, sie zu bewerten und dann auf der Grundlage dieser Blätter neue Modelle zu erstellen.
Ich habe dieses Thema gelesen und verstehe nicht ganz, der Prozess der automatischen Netzbildung wurde von Ihnen auf der Grundlage von nackten Indikatoren und Markup erstellt, die Informationen werden per Vorlage übertragen, in meinem Fall gibt es eine Nachbearbeitung von Indikatoren, plus ich benutze einige Indikatoren, die ich nicht anzeigen möchte, so stellt sich heraus, dass diese Methode nicht verfügbar ist, und wieder - Sie können keine Blätter von ihm bekommen...
Ich verstehe nicht, warum kann die manuelle Bearbeitung Splits und Blätter entscheiden Bäume, ja ich habe alle die Verzweigung automatisch zu einem logischen Operator umgewandelt, aber ehrlich gesagt nicht daran erinnern, dass ich mich jemals korrigiert haben.
Und im Allgemeinen lohnt es sich, den CatBoost-Code zu graben, wie kann ich das sicher wissen.
Zum Beispiel habe ich oben Test auf Python mein neuronales Netz mit Training durch Multiplikationstabelle mit zwei, und nahm es jetzt für die Prüfung Bäume und Wälder (DecisionTree, RandomForest, CatBoost)
und hier ist das Ergebnis - offensichtlich ist es nicht zugunsten von CatBoost, denn zwei mal zwei ist null fünf...:)
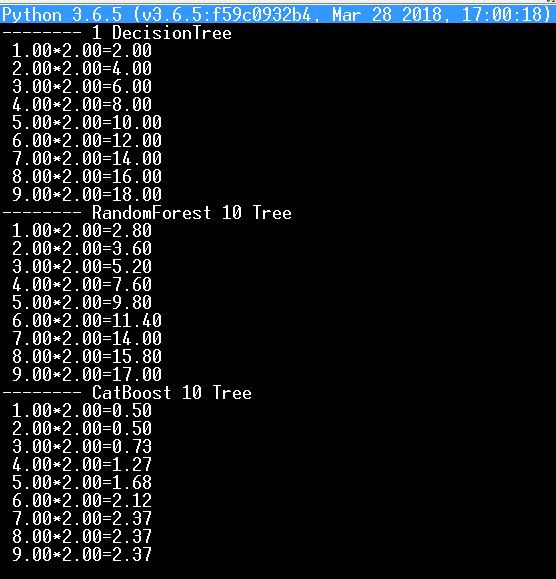
Es stimmt, dass sich die Ergebnisse verbessern, wenn man Tausende von Bäumen nimmt.Ich verstehe nicht, warum die manuelle Bearbeitung von Abspaltungen und Blättern von Entscheidungsbäumen notwendig ist. Ja, ich habe alle Zweige automatisch in logische Operatoren umgewandelt, aber ehrlich gesagt kann ich mich nicht erinnern, dass ich sie jemals selbst korrigiert habe.
Und im Allgemeinen lohnt es sich, den CatBoost-Code zu graben, wie kann ich das sicher wissen.
Zum Beispiel habe ich oben Test auf Python mein neuronales Netz mit Lernen durch Multiplikationstabelle mit zwei, und jetzt nahm es für die Prüfung Bäume und Wälder (DecisionTree, RandomForest, CatBoost)
und hier ist das Ergebnis - es fällt eindeutig nicht zugunsten von CatBoost aus, so wie zwei mal zwei null fünf ist...:)
Komm schon, es ist unmöglich, dass Forest oder Boosting nicht mit dem Einmaleins zurechtkommen
Auf keinen Fall kann ein Wald oder ein Boosting das Einmaleins nicht bewältigen.