Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 2181
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Некрасиво он рисует. Лучше просто кусочно-линейными
Некрасиво он рисует. Лучше просто кусочно-линейными
Чем-то напоминает Ишимоку.
Я уже отвечал - некий Демко формировал равнотиковые бары (100 тиков на бар по данным Альпари) и работал с ценами OPEN таких баров.
Немного пособирал тики с интервалом 100 тиков (на демке), конечно данных мало, но вроде как на те картинки что ты выкладывал не похоже.
Скорее всего этот интервал нужно подбирать под конкретный счёт.
Если кто-то хочет накопить больше данных выложу сборщик тиков для mql4
Остановился на 3 видах тренда (флет это тренд с нулевой скоростью), сужение и расширение канала, и забор, когда ширина баров выше средней ширины хайлоу и края канала не коррелируют между собой и не постоянны. В зависимости от предыдущего состояния и текущего алгоритм определения появления сигнальных точек. Они уже могут быть, а могут и не быть.
зы сигнальные точки, точки смены состояний.Для визуального анализа - хороший подход. Если пытаться делать методами стандартного матстата, то тяжело будет считать распределения величин типа размаха (high-low) для СБ при неизвестной дисперсии (когда она тоже оценивается по выборке).
Немного пособирал тики с интервалом 100 тиков (на демке), конечно данных мало, но вроде как на те картинки что ты выкладывал не похоже.
Скорее всего этот интервал нужно подбирать под конкретный счёт.
Если кто-то хочет накопить больше данных выложу сборщик тиков для mql4
С 300 тиками по 100 - получится что вместо 1 минутного бара будет 3 сто-тиковых.
А в целом мне кажется не универсальной идея. На одном ДЦ по одному, на другом по другому,... на пятнадцатом ...
Для визуального анализа - хороший подход. Если пытаться делать методами стандартного матстата, то тяжело будет считать распределения величин типа размаха (high-low) для СБ при неизвестной дисперсии (когда она тоже оценивается по выборке).
Остановился на возвратной логике, Если значение вне коридора, то набираем среднее от него, если среднее изменилось, значит изменения значимые, если возврат к предыдущим значениям, то отсев выброса. На скоростях, при смене тренда на ура (более менее видно и точно). на более сложных рисунках... работаем над этим. Дисперсию оцениваю как отношение средних разниц минмумов максимумов к средним хай лоу или опен клоз на отрезке.
Без возврата пока путей не вижу, как точку изменения определить.
Немного пособирал тики с интервалом 100 тиков (на демке), конечно данных мало, но вроде как на те картинки что ты выкладывал не похоже.
Скорее всего этот интервал нужно подбирать под конкретный счёт.
Если кто-то хочет накопить больше данных выложу сборщик тиков для mql4
Ну, не знаю...
Вот, конкретно:
Формат данных: Time; Open; High; Low; Close; Real VolumeДанные преобразовывались из реальных тиков Дукаскопи за два года, с начала 2016 по конец 2017
Нарезка баров по 100 тиков на бар. Тайминги бара брались от тайминга первого тика, к сожалению без микросекунд тк формат хранения времени в МТ не позволяет на чарте отображать микросекунды.
Если проверить - все верно, получилась стационарность и двумодальность.
Возможно, что-то не договорил. Ну, и ладно.
Альпари реал выдает по 300 тиков в минуту примерно - он с 3-х поставщиков котировок/ликвидности их объединяет. Демо у них же в разы меньше. Другие ДЦ тоже другое количество будут давать.
С 300 тиками по 100 - получится что вместо 1 минутного бара будет 3 сто-тиковых.
А в целом мне кажется не универсальной идея. На одном ДЦ по одному, на другом по другому,... на пятнадцатом ...
Поддерживаю, фильтрацию(преобразование) ликвидности БД/ДЦ может изменить в любой момент! Если даже сравнивать M1 данные раньше была огромная разница между БД/ДЦ, даже разница между M1 одного ДЦ на терминалах MT4 и MT5!
просто прибавил или отнял ото всех признаков в датасете число, в зависимости от метки. Модель стала еще более глубокий тест на истории проходить
с этим нужно переспать. Какие-то примитивные вещи, казалось бы. Здесь как бы 10 пятизначных пунктов, разнес просто классы подальше друг от друга, получается. Не знаю как лучше, ведь признаки имеют разный разброс значений. Наверное, для каждого столбца имеет смысл свое число. А может и нет.
Визуализирую потом.
А, ну да
было
стало
главное не перебарщивать
получилась вот такая картина: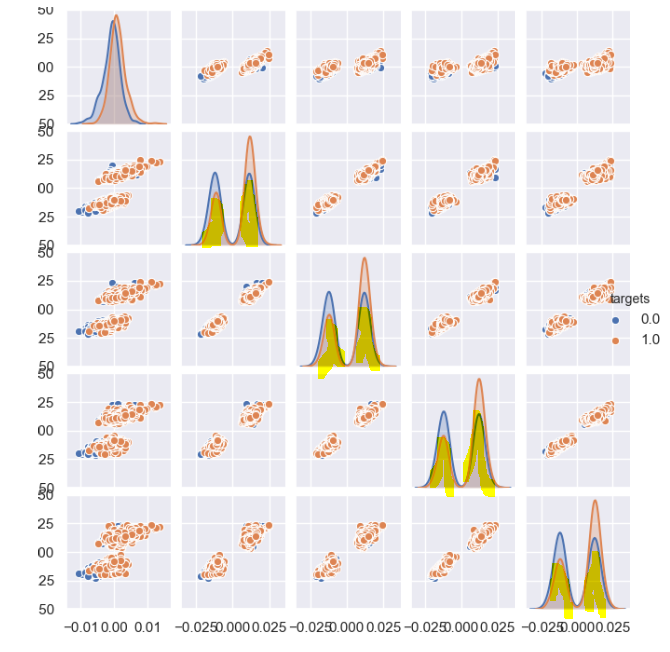
потом я дропнул в исходном датафрейме те распределения что не на своих местах (желтым на рисунке выше)
получилось вот что
загнал все в случайный лес и прогнал в тестере
трейн с 06.20 по 08.20. не густо, но уже не минус.
Интересная идея! Вашим методом я попробовал с помощью знака приращения МА растащить распределения фич
получилась вот такая картина:
потом я дропнул в исходном датафрейме те распределения что не на своих местах (желтым на рисунке выше)
получилось вот что
загнал все в случайный лес и прогнал в тестере
трейн с 06.20 по 08.20. не густо, но уже не минус.
вчера же максимка готовый грааль выкладывал по этим картинкам и бота на сигнал повесил. чо не берешь?