Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 1489
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
значит нужно больше точек для ск. окна, как минимум
писал же, что даже несколько тысяч точек брал
а если рандомный ряд подается, то о каком предсказании кроме 50\50 может идти речь?
какая разница кокой ряд, данные одни и те же , модель одна и та же
прогнозирую новые данные через функцию в пакете целиком (так как в всех примерах в инете итп...) результаты супер
прогнозирую те же данные той же моделью но в скользящем окне и результат другой, неприемлемый.
В это и собственно сам вопрос - в Чем проблема то?писал же, что даже несколько тысяч точек брал
какая разница кокой ряд, данные одни и те же , модель одна и та же
прогнозирую новые данные через функцию в пакете целиком (так как в всех примерах в инете итп...) результаты супер
прогнозирую те же данные той же моделью но в скользящем окне и результат другой, неприемлемый.
В это и собственно сам вопрос - в Чем проблема то?не понятно что за модель и откуда ты берешь состояния. Без всяких пакетов, концептуально в чем смыл
может гсч там такой, что нифига не рэндом выдает, поэтому получается его предсказать в 1-м случае. Попробуй поменять seed для трэйна и теста что бы увидеть, что и в первом случае предсказать ничего невозможно, в остальном хз чем помочь идея не ясна
По вероятности классификации и делаются сплиты. Точнее не по вероятности, а по ошибке классифиции. Т.к. на обучающем уч-ке все известно, и мы имеем не вероятность, а точную оценку.
Хотя там есть разные ф-ии разделения, т.е. меры нечистоты (выборки слева или справа).
Я имел ввиду распределение точности классификации по выборке, а не итогово, как это делается сейчас.
не понятно что за модель и откуда ты берешь состояния. Без всяких пакетов, концептуально в чем смыл
может гсч там такой, что нифига не рэндом выдает, поэтому получается его предсказать в 1-м случае. Попробуй поменять seed для трэйна и теста что бы увидеть, что и в первом случае предсказать ничего невозможно, в остальном хз чем помочь идея не ясна
Вот файл, там цены и две колонки с предикторами "data1" и "data2"
Берешь и обучаешь HMM всего двум состояниям (на трейн данных без учителя )на этих двух колонках ( "data1" и "data2")у себя в питоне или где там тебе нравиться , цену вообще не трогаешь, только потом лишь для визуализации
Потом берешь алгоритм Витерби и приходишься по (тест данных)
получим два состояния , должно выглядеть примерно так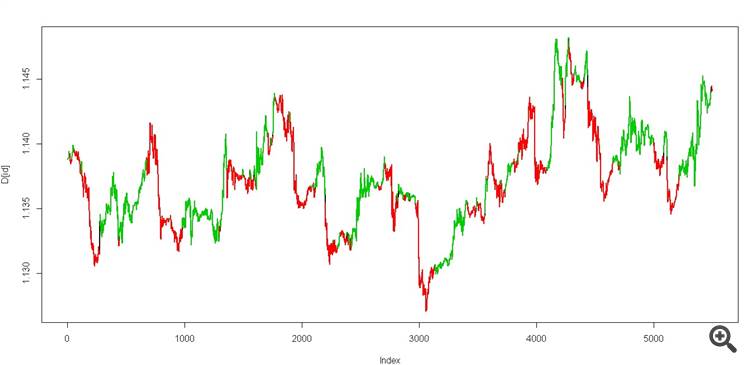
кароч грааль настоящий))
А потом попробуй тот же Витерби посчитать в скользящем окне на тех же данных
Вот файл, там цены и две колонки с предикторами "data1" и "data2"
Берешь и обучаешь HMM всего двум состояниям (на трейн данных )на этих двух колонках ( "data1" и "data2")у себя в питоне или где там тебе нравиться , цену вообще не трогаешь, только потом лишь для визуализации
Потом берешь алгоритм Витерби и приходишься по (тест данных)
получим два состояния , должно выглядеть примерно так
кароч грааль настоящий))
А потом попробуй тот же Витерби посчитать в скользящем окне на тех же данных
сенк, позырю че да как позже, отпишу, т.к. сам с марковскими работаю
сенк, позырю че да как позже, отпишу, т.к. сам с марковскими работаю
ну как успехи?
ну как успехи?
еще не смотрел, выходной ) как будет время, отпишу, позже в смысле на неделе
пакеты пока глянул. Думаю, подойдет https://hmmlearn.readthedocs.io/en/latest/tutorial.html
еще не смотрел, выходной ) как будет время, отпишу, позже в смысле на неделе
пакеты пока глянул. Думаю, подойдет https://hmmlearn.readthedocs.io/en/latest/tutorial.html
должно
Потом берешь алгоритм Витерби и приходишься по (тест данных)
получим два состояния , должно выглядеть примерно так
кароч грааль настоящий))
Может я чето путаю но не эти ли картинки не так давно демонстрировал некто Инокентий? А потом оказалось что оно с подглядыванием было, шэйм млять, фэйспалм