Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 2475
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
м-да, чтобы апроксимировать независящие др от др параметры в попытках свести их в 1 output - действительно, нужно взвесить статистически данные глубоко исторические вплоть до текущего момента - т.е. иметь репрезентабельную выборку (чем больше - тем больше вероятность попадания в цель)... чтобы обработать их (взвесить) в чёрном ящике... но это всё статистика, и она может быть далека даже от текущей экономической фазы... -просто получим среднюю с большой дисперсией (и коэфициентом вариации в придачу)
мы вроде лет за 30 и прошли полный экономический цикл - признаки для обучения на текущий момент лучше брать из подобной фазы экономического развития (так полагаю)-- чтобы уменьшить выборку нач. данных ()... но лично я не имею этих данных (нужных мне, чтобы я поверила в валидность полноценного анализа за столь длительный период)....
это не хитрость, а попытка оторваться от реальности... имхо
(можно и меньшими затратами - логичными - получить нормальный форвард - не анализируя шелуху и беспредметность для текущего момента - хоть и всё познаётся только в сравнении, и в чёрном ящике тоже, но всё равно сначала бы включала мозг, а потом даже уже не столь глубокое обучение машины, а лишь касающейся части текущего момента по важным в текущей рыночной ситуации признакам) - и то всех нужных данных из истории нет...
всё-таки понимание Экосистемы и база знаний об обмене вещества и энергии в ней в совокупности со своевременной информированностью о движущих новостях/событиях -- это способ прикинуть Эволюцию без загрузки таких мощностей ПК лишь ради средней и дисперсии... имхо
но спасибо за ваши наблюдения... но для меня спорна необходимость такого глубокого обучения (хотя, наверно, для чёрного ящика она бесспорна))
Дисперсия и прочие отклонения - это закономерный итог анализа системы основанной на вероятностях но не на дифференциальных уравнениях, все что вы можете получить это систему дифференциальных уравнений, переменными в которых являются внимание "вероятности определенных событий", тех событий которые кажутся вам важными, и все что можно предсказать это вероятность но не точное значение. Поняв это все проще становится и вы не будете бояться не дисперсии ни других вещей. Вы всегда будете получать отклонения, ваша задача лишь их минимизировать. Нельзя предсказать поведение системы на долгосрок со 100 процентной точностью, но можно достигнуть определенных показателей которых будет достаточно для прибыльной торговли. Я это к тому что не надо делать за машину ее работу, дайте ей свободу и вы увидите что она гораздо лучше вас знает какие данные ей нужны. Кстати насчет черного ящика, чем чернее ящик тем он умнее. ИИ строится как раз по этому принципу.
. Я это к тому что не надо делать за машину ее работу, дайте ей свободу и вы увидите что она гораздо лучше вас знает какие данные ей нужны. Кстати насчет черного ящика, чем чернее ящик тем он умнее. ИИ строится как раз по этому принципу.
- ну понятно, чем больше данных на входе (и признаков для отбора), тем точнее аппроксимирующая оценка и даже прогноз на её основе (хоть и всё равно с вероятностью ошибки)...
после ваших постов немного проясняется зона ответственности разработчика,
Дисперсия и прочие отклонения - это закономерный итог анализа системы основанной на вероятностях но не на дифференциальных уравнениях, все что вы можете получить это систему дифференциальных уравнений, переменными в которых являются внимание "вероятности определенных событий", тех событий которые кажутся вам важными, и все что можно предсказать это вероятность но не точное значение.
Algorithm To Find Derivatives Using Newtons Forward Difference Formula
. Вы всегда будете получать отклонения, ваша задача лишь их минимизировать.
да, там где-то на линке, что оставляла чуть ранее, была картинка ~ сходимость прогноза и ошибки на самое дно параболы (это чтобы сильно не переучить и вовремя остановиться) - Эволюция идёт по спирали в эту точку (так полагаю, с уменьшением ускорения, пока не остановится совсем - пока не утихнут колебания разности от большего к меньшему, как упасть в воронку)
p.s.
я кодила как-то по примеру Calculate Implied Volatility with VBA - Implied Volatility with Newton-Raphson Iteration - не нашла сигналов... да и понятно (т.к. Black-Sholes вообще не работает на валюте, т.к. не так уж всё биномиально распределено там, как хотелось бы мечтать)
... я, честно говоря, с Ньютоном вообще не знакома -то ли он так много всего разного(?) изобрёл, то ли это (ваш форвард и моя Implied Volatility) - это из одной оперы и в одной перспективе и суть один и тот же расчёт... ?.. не хочется тратить время на то, во что не верю, - в Black-Sholes'a не верю -- в фин. моделировании
но всё равно остаётся вопрос выбора целевой функции... - тоже зона ответственности самого разработчика... - что посоветуете?
(хотя да, вы же использовали forward difference)
p.s.
по степеням свободы - полистаю ещё раз
верю в Спрос -Предложение... в паутинообразную модель (ориентироваться на эластичность и на Вальраса) - в баланс-дисбаланс - для определения направления... (для вероятности выхода из флета в тренд) - только OI и time-management (включая то, что на Вальраса не всегда можно ориентироваться)...
для факта - стакан (разбор уровней или упс - выплывающий айсберг) -- хотя, конечно, лучше не разбирать, а пройти спокойно, когда уже кто-то разобрал уровень и NO-opposite exist (лучше с тестированием после пробоя - тоже видно в стакане, да и по ленте)
на Вальраса
Очень понравилось про сырную деревню и центр винотерапии.
Могу только по ньютону сказать. Я так понял там прогнозирование форварда на основе имеющейся кривой в прошлом, я такое делал давно еще, оно не работает с ценой вообще, от слова совсем, если вы об этом. Но это работает, если пытаться прогнозировать график бектеста на форвард, но там есть нюансы типа вот такого:
Это чисто мой опыт. Любой метод прогнозирования чего-то основан на интерполяции функции каким-либо полиномом с последующим построением продолжения, я не знаю как делает Ньютон, но скорее всего вычисляются производные сколь глубокого порядка и потом принимается что они константы для этой функции, хотя конечно со временем все это меняется (на рынке такие прогнозы вообще не работают, проверено). Если прогнозировать форвард бектеста то надо чтобы график был как можно более прямой и как можно больше в нем было точек,( данных или трейдов в данном случае, тогда можно немного вперед заглянуть). Иначе говоря если мы нашли выборку с достаточно узкими диапазонами колебания как можно большего количества первых производных то такие методы экстраполяции будут частично работать, главное не жадничать и вовремя останавливаться, вот первые два рисунка это два случая, второй нам подходит а первый даст рандом. Ниже я просто показываю как с помощью лотности бороться с неопределенностью (если мы точно не знаем где прогноз потеряет силу). Тут сами методы уже на второй план уходят, можно и фурье проинтерполировать и в будущее нарисовать продолжение, но с произвольными функциями это не будет работать. А насчет воронки обучения, ну можно по разному контролировать переобучение, я вот никогда не брал чужие формулы, просто потому что сам могу свои склепать в два счета если будет необходимость, и они будут скорее всего проще и полезнее, просто в виду того что все понимаю, так всегда было, никогда трудностей не испытывал в этом.
Могу только по ньютону сказать. Я так понял там прогнозирование форварда на основе имеющейся кривой в прошлом, я такое делал давно еще, оно не работает с ценой вообще, от слова совсем, если вы об этом.
Это чисто мой опыт. Любой метод прогнозирования чего-то основан на интерполяции функции каким-либо полиномом с последующим построением продолжения, я не знаю как делает Ньютон, но ... (на рынке такие прогнозы вообще не работают, проверено).
вот этот ваш вывод мне был интересен - спасибо! -
А насчет воронки обучения, ну можно по разному контролировать переобучение, я вот никогда не брал чужие формулы, просто потому что сам могу свои склепать в два счета если будет необходимость, и они будут скорее всего проще и полезнее, просто в виду того что все понимаю, так всегда было, никогда трудностей не испытывал в этом.
+1, но я не физ-мат... хоть мне и ближе своя логика, чем использование чужих моделей
Если прогнозировать форвард бектеста то надо чтобы график был как можно более прямой и как можно больше в нем было точек,( данных или трейдов в данном случае, тогда можно немного вперед заглянуть). Иначе говоря если мы нашли выборку с достаточно узкими диапазонами колебания как можно большего количества первых производных то такие методы экстраполяции будут частично работать,
в общем, имея нормальную параболу, от которой 1я производная будет линейной... в итоге получаем просто коэфициент её наклона (типа тренд, очищенный от шума) - при всех сопутствующих, что вы описали (узкий диапазон большого количества 1х производных)... просто взвешивать надо до посинения? (несколько слоёв пока на выходе не получим параболу)?.. точнее уже прямую 1х производных от неё
Тут сами методы уже на второй план уходят, можно и фурье проинтерполировать и в будущее нарисовать продолжение, но с произвольными функциями это не будет работать.
это меня и интригует в нейросетях, чтобы не выводить распределение и не сравнивать с табличными/эмпирическими, и не искать подтверждений каждого чиха статистически (вплоть до "а правильно ли я определила среднюю"), сравнивая нулевую гипотезу с табличным показателем... - это вообще какой-то прошлый век стат. обработки... в общем, чтобы не доказывать достоверность и модели и прогноза и ошибок и всё это с табличками в руках из прошлого века (простите за выражение)
или, как альтернатива, просто многослойное взвешивание (я так понимаю нейросеть)... как уже сказала: до посинения? (несколько слоёв пока на выходе не получим параболу)?.. точнее уже прямую 1х производных от неё
??? или вообще забыть про любые виды функций (включая параболу) и просто искать вес*сигнал(событие) -> следующий уровень... а на каждом уровне функцию выбирать примерно банально, как в Excel Поиске Решения (или для линейной зависимости, или для нелинейной зависимости, или для независимых данных) [хоть я и не знаю, что там в Excel под капотом по этим названиям, но это детали, акцент на логику]
а в точке схождения сигналов на следующем уровне (с учётом предыдущих весов) просчитать все разности полученных сигналов...
? правильно ли я понимаю нейросеть и дифференцирование машинными силами хаоса без какой-либо необходимости придерживаться какой-либо кривой/прямой - которая, как по мне, так может быть только итогом структурирования хаоса, но никак не отправной точкой... это я всё о той же ответственности разработчика - не верю и не вижу никаких оснований закладывать в фин. анализ какие бы то не было фин модели из книжек/блогов/статей ( и стат обработанные распределения) при аппроксимации/интерполяции хаоса... для дальнейшей экстраполяции output'a
p.s.
в глубине души понимаю, что есть лишь скорость (коэф при x) и ускорение (коэф при x^2) и смещение свободного члена -в параболе, ну и понятное дело 1я производная от неё линейная... меня вообще формулы пугают, особенно чужих моделей
Тут есть доля правды, но свою модель я проверял, там главное знать на какой форвард рассчитываем. Проблема в переобучении, чтобы не переобучалось нужно стремиться к максимальному отношению количества анализируемых данных к итоговому набору критериев, иначе говоря тут происходит сжатие данных, например можно проанализировать данные графика параболы и взять несколько тысяч точек а свести все к трем коэффициентам A*X^2 + B*X + C. Вот там где качество сжатия данных выше там и есть форвард. Переобучение можно контолировать введя правильные скалярные показатели ее качества которые учитывают это сжатие данных. В моем случае это делается проще - берется фиксированное количество коэффициентов а размер выборки берется как можно больше, это менее эффективно но работает.
нашла ваш ответ ранее... наверно, поторопилась с предыдущим постом... наверно, действительно, стоит оттолкнуться хотя бы от параболы, как функции описывающей движение со скоростью и ускорением... (даже когда-то где-то видела research по этому виду графиков и грекам (дельта и гамма) опционов - пока не вспомню и не найду - да и не надо - ведь нужен временной анализ - горизонтальный, а не вертикальный)
это я всё о той же ответственности разработчика - не верю и не вижу никаких оснований закладывать в фин. анализ какие бы то не было фин модели из книжек/блогов/статей ( и стат обработанные распределения) при аппроксимации/интерполяции хаоса... для дальнейшей экстраполяции output'a
Да это основа, понимаете в чем дело, люди создавали эти формулы и модели без привязки к задаче, они старались сделать что-то универсальное, при этом наивно думая что оно применимо ко всему. Почему-то все любят кидаться словами Лаплас, Фурье, Тейлор, Нормальное распределение, и думают что если они зашьют все это в систему то непременно все это должно работать почему-то. Я был силен в этом, было дело я выводил формулу циолковского на коленке и никто не мог понять как это я сделал... У меня был такой опыт, я пытался в советнике предсказывать следующую свечу используя системы линейных уравнений, при этом составлялись огромные матрицы и считались определители и прочая лабуда, и как мне тогда казалось это же так круто этого ни у кого нет, но при тестировании оказалось что это все полная херь, хотя по моим предвосхищениям я в следующий миг должен был стать гуру рынка, это было лет 5 назад наверное, тогда я как раз университет заканчивал ( к слову я очень хорошо знал матан и физику ), я это к тому что зная крутые формулы и теоремы это не на много делает нас сильнее обычного трейдера а если говорить о практической плоскости то даже слабее в итоге... Самый верный путь идти от обратного. нужно задать себе вопрос сначала на что мы рассчитываем, ответить сначала простым человеческим языком а потом превращать все это в какие-то математические критерии. Сейчас я знаю что для этого не нужно задумываться о первоначальной модели и как ее построить а нужно идти от конца к началу, если модель выдает нужные показатели то уже после этого можно пытаться ее понять, но все в итге сводится к ИИ, и чем более умной будет система тем больше это будет раздражать математика, я этот барьер преодолел и в своей работе стараюсь как можно больше делегировать машине.
нашла ваш ответ ранее... наверно, поторопилась с предыдущим постом... наверно, действительно, стоит оттолкнуться хотя бы от параболы, как функции описывающей движение со скоростью и ускорением... (даже когда-то где-то видела research по этому виду графиков и грекам (дельта и гамма) опционов - пока не вспомню и не найду - да и не надо - ведь нужен временной анализ - горизонтальный, а не вертикальный)
Параболу я просто привел как пример как можно бесконечное число данных сжать в конечное, точек там бесконечное число на графике а свести можно к формуле где 3 коэффициента всего. А если именно о вашей мысли говорить я понимаю о чем вы думаете, можно брать любую функцию типа:
A[1]*X^0+A[2]*X^1 + ... + A[N]*X^N , это в общем случае ряд Тейлора(функциональный ряд), за тем исключением что A[i] > 0 для всех i = 1...N это дает в общем случае постоянный прирост именно первой производной, если наглядно то так:
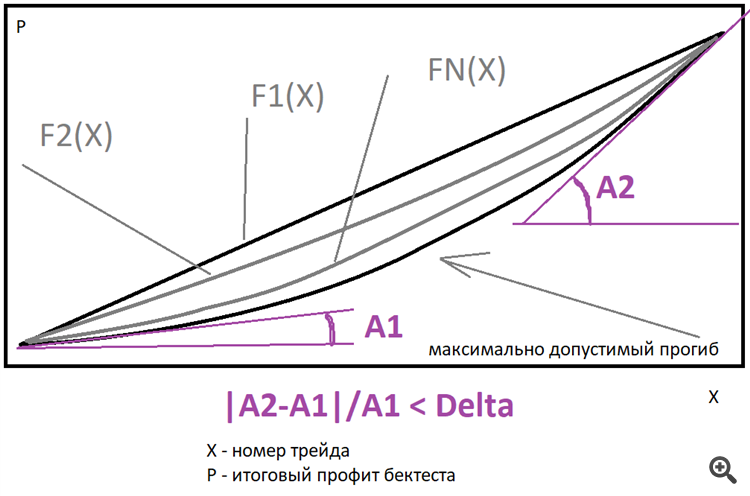
В идеале прямая лучший вариант, но можно для оценки отклонений использовать семейство степенных функций как раз такого вида как я описал выше. Нужно только задать во сколько раз конечная производная может быть больше стартовой. Можно апроксимировать итоговый график около такого семейства, находить лучшую функцию и отклонение реального графика уже искать относительно этой функции, я же использую только прямую, хотя возможно потом расширю функционал, это даст прирост эффективности на порядок и как следствие может снизить потребность в вычислительных мощностях при грамотном подходе.