Новая версия платформы MetaTrader 5 build 5120: улучшения и исправления - страница 35
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Forester #:
У вас тоже 3 блока оказались лучшими. Может 2-канальная память тоже. Или еще почему-то...
Да, по какой-то причине. Возможно, слабо фрагментирована память или что-то другое. В этом ничего не понимаю.
Не пробовали вторую переменную адреса задействовать, может получится более 4Гб сохранять/читать?
У меня мало ОЗУ, чтобы такие эксперименты проводить. Хотел бы уложить MqlTick в 12 быстрых (на распаковку) байтов (sizeof(MqlTick) = 60), тогда ограничение на 4 гига стали бы несущественными.
Эти два параметра определяют 64-битное число размера памяти из старших и младших 32-х бит. То есть, размер памяти может быть больше 4 Гб.
Эту функцию сам не использовал, но по логике так.
https://learn.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-createfilemappingw
4G — это ограничение 32-битных компьютеров. После 64-битных такого ограничения нет.
Параметры dwMaximumSizeHigh и dwMaximumSizeLow вместе образуют 64-битное значение размера «виртуальной» области памяти (high << 32 | low)
Форум по трейдингу, автоматическим торговым системам и тестированию торговых стратегий
Новая версия платформы MetaTrader 5 build 5120: улучшения и исправления
fxsaber, 2025.06.30 16:28
150 миллионов тиков в секунду.
Это ошибочный результат: число проходов меньше.
В кодобазу уже выложен "сжиматель" тиков на принципе использования float (правда не все инструменты "влезут" без потери точности - в частности, некоторая крипта). Но если уже хочется совсем убыстриться, то можно перейти на целочисленную математику с ulong (в "пунктах" денег, а-ля тип decimal, который присутствует во всех уважающих себя финансовых платформах и SQL-движках).
На самом деле распаковка должна быть такой.
У меня по прежнему тут сбой и ваш вариант показывает 4 агента вместо 36
Распечатка имен
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-301
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-300
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-300
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-302
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-303
tes\Tester\D0E820...1FF075\Agent-127.0.0.1-300
Экспериментально выяснилось, что при передаче фреймов строка не до 64, а до 63 символов обрезается.
Хорошо бы в справке написать.
Однако, почему фактически советник-пустышка в режиме по тикам проигрывает кратно эмуляции этого режима в мат. режиме
На самом деле, нас мало интересует скорость итерации по тикам. На фоне рассчета внутренней логики системы и индикаторов это будет довольно маленький процент.
Сначала хорошо бы закешировать тяжелые расчеты (считывать индикаторы из файла как и тики? опять же что быстрее: посчитать или запросить из памяти), и уже после этого заниматься микрооптимизациями.
Имхо
Режим реальных тиков тест за 3 месяца (если больше - то 4 блока в память не влезают):
Memory1 - Memory2 = 109 MB (see Line 245 in source)
Agents = 36
Passes = 1001
AmountTicks = 3936371 (225 MB)
Performance = 4.5 Ticks (millions)/sec.
TotalTime = 00:00:27.937
[TesterInputs]
inRamMode=1
inCompression=true
inBlockSize=8
inBlocks=1
inDataTotal=0
inRange=0||0||1||1000||Y
TotalTime = 00:00:03.964
TotalTime = 00:00:04.257
TotalTime = 00:00:03.919
TotalTime = 00:00:04.134
TotalTime = 00:00:04.440
TotalTime = 00:00:04.009
TotalTime = 00:00:05.181
TotalTime = 00:00:04.495
TotalTime = 00:00:01.603
TotalTime = 00:00:04.059
TotalTime = 00:00:04.273
TotalTime = 00:00:03.951
TotalTime = 00:00:02.176
TotalTime = 00:00:02.034
TotalTime = 00:00:02.207
TotalTime = 00:00:02.081
Компрессия конечно ускорила тестирование в 2-2.5 раза.
Ускорение Performance и замедление по общему времени оптимизации выгладит странно.
После нескольких запусков оптимизации по File Map начинает появляться ошибка:
Access violation at 0x00007FFB7D9730E0 write to 0x000001C12D06B5D8 in 'msvcrt.dll'
Перезагрузка компьютера помогла.
Может быть после использования памяти она не освобождается?
Это не помогло, ошибка продолжает появляться:
HandleMemory.ForceFree(); //HandleMemory.Close();На мой взгляд RAM Drive всё же лучше:
- код короче и понятнее
- общее время оптимизации примерно то же как и с File Map без компрессии и всего на 20-25% медленнее с компрессией.
- нет ошибок Access violation, которые могут появиться через несколько перезапусков
- нет ограничений в 4Гб
На самом деле, нас мало интересует скорость итерации по тикам. На фоне рассчета внутренней логики системы и индикаторов это будет довольно маленький процент.
Скорость в этой затее не главное, а дополнительный плюс.
Основное - то, что каждому агенту не будет храниться в памяти отдельная копия тиковых данных. Все агенты будут читать из 1-4 копий этих данных в памяти. 1 или 2 копии наверное самое лучшее. Хотя в предыдущих тестах и 3 блока были лучшими. Надо еще под большие размеры блока памяти сделать тест с несколькими годами тиков.
Решил все таки установить ImDisk, дал ему 36 Гб памяти и протестировал на 36 агентах с 1 до 36 блоков памяти, (при 36 агентах каждому агенту по 1 блоку).
Сделал оптимизацию старого варианта только с RAM диском, на inBlockSize (лучший размер блока чтения из файла) :
1 блок памяти
Performance = 5.1 Ticks(millions)/sec.
Time: 241193 ms
2 блока памяти
Performance = 31.7 Ticks(millions)/sec.
Time: 36820 ms - общее время оптимизации для всех inBlockSize
3 блока памяти
Performance = 19.5 Ticks(millions)/sec.
Time: 59421 ms
4 блока памяти
Performance = 22.7 Ticks(millions)/sec.
Time: 52251 ms
Картинка для лучшего варианта с 2 блоками памяти: по оси У время теста
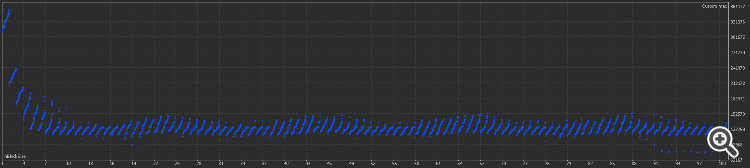
Самый быстрый вариант - если 14-16 тиков считывать за раз из файла, потом идет волнами примерно на одном уровне.
Т.е. по умолчанию можно принять 2 блока памяти и inBlockSize = 16 (сколько тиков считывать при каждом обращении к файлу)
При таких параметрах получается
Performance = 32.1 Ticks(millions)/sec.
Time: 3610 ms
Быстрее на 8%, чем с самый быстрый с File Map (3964ms)