Existe um padrão para o caos? Vamos tentar encontrá-lo! Aprendizado de máquina com o exemplo de uma amostra específica. - página 25
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Em TP=SL, será cerca de 50%. Com TP = 2*SL, será 33%, etc.
O lucro médio de uma negociação é sempre muito pequeno. Cerca de 0,00005. Mas ele será gasto com spread, slippage, swap, que não são levados em conta na margem de lucro do professor (o spread é levado em conta, mas o mínimo por barra, o real será maior).
E isso usando TP=SL=0,00400. Ou seja, com um risco de 400, obtemos um lucro de 5 pontos, ou seja, a vantagem de 1%.
Eu gostaria de tirar pelo menos 10 pontos do movimento de 50 pontos, mas todas as opções são de ameixa.
Mas isso é tudo com minhas fichas e metas. Talvez haja opções melhores.
Essa estratégia proporciona 43% de negociações lucrativas no EURUSD de 2008 a 2023, com relação TP/SL de 61,8, e 39% das negociações lucrativas são suficientes para o ponto de equilíbrio. Ainda não verifiquei os números, posso estar errado em algum ponto, e é claro que essas são condições ideais. No entanto, há uma perspectiva de aprendizado aqui, o que significa que você pode obter uma porcentagem maior às custas da MO.
Com relação aos preditores, você pegou os preditores do meu artigo? Eles são encontrados com frequência nos modelos que tenho, entre outros.
Acrescentado: Sim, não levei em conta o fato de que há negociações lucrativas, mas não fechadas pelo TP, e haverá menos lucro, é claro.Essa estratégia proporciona 43% de negociações lucrativas no EURUSD de 2008 a 2023, com relação TP/SL de 61,8 em condições ideais, e 39% das negociações lucrativas são suficientes para o ponto de equilíbrio. Ainda não verifiquei os números, posso estar errado em algum ponto, e é claro que essas são condições ideais. No entanto, há uma perspectiva de aprendizado aqui, o que significa que você pode obter uma porcentagem maior às custas da MO.
Com relação aos preditores, você pegou meus preditores do meu artigo? Eles são encontrados com frequência nos modelos que tenho, entre outros.
Não tenho certeza de qual é sua estratégia. Parece que você recebe um sinal para entrar uma vez por dia. Acho que é muito pouco falar sobre a significância estatística dos resultados.
Treinei seus mais de 5.000 preditores em seu conjunto de dados. Eles não dão mais do que os mesmos 5 pontos, portanto, acho que não são melhores do que meus deltas de preço simples e ziguezagues, que também dão 5 pontos.
Vou verificar outras ideias por enquanto. Se elas não derem nada, tentarei seus preditores para gerar meu próprio modelo.
Não entendo muito bem qual é sua estratégia. Parece um sinal para entrar uma vez por dia.
A estratégia é a seguinte:
Na abertura do dia, calculamos a faixa limite esperada do movimento de preços. Para isso, podemos usar o ATR(3) no final do último dia, mas eu uso uma fórmula um pouco diferente. Adiamos essa faixa desde o início da abertura do dia atual (barra) - consideramos que ela é 100%.
Quando atingimos um nível significativo acima/abaixo da abertura (parei em 23,6, pois, de acordo com minhas observações, muitas vezes isso acontece em diferentes instrumentos), abrimos uma posição com TP no próximo nível significativo (uso 61,8) e colocamos SL no preço de abertura do dia.
Se tivermos fechado no take profit, entramos novamente quando aparecer um sinal.
É melhor fechar no final do dia (23h45) se as retiradas não funcionarem, mas, na verdade, estou esperando pelo TP/SL.
Agora, a marcação inicial funciona assim: se fecharmos com lucro, colocamos 1, se fecharmos com prejuízo, -1.
Ao dividir a amostra, fiz com que o alvo fosse deslocado em 300 pips, portanto, se o lucro for inferior a 300 pips, ele será zero.
Acho que isso é muito pouco para falar sobre a significância estatística dos resultados.
Peguei os dados de 2008. Sim, não há muitos dados, mas isso depende de como você olha para eles, porque se você considerar que o nível de 23,6 não é aleatório e que seu cruzamento é significativo para o mercado, então será como eventos semelhantes que podem ser comparados entre si, ao contrário da situação ao gerar entradas em cada barra - há muitos eventos semelhantes, o que só complica o aprendizado.
Portanto, acho que faz sentido treinar dessa forma, mas os eventos que influenciam a decisão dos participantes do mercado devem ser diferentes em estratégias diferentes. E, além disso, negociar conjuntos de modelos.
Treinei seus mais de 5.000 preditores em seu conjunto de dados. Eles não dão mais do que os mesmos 5 pontos, portanto, acho que não são melhores do que meus deltas de preço simples e ziguezagues, que também dão 5 pontos.
Vou verificar outras ideias por enquanto. Se elas não derem nada, tentarei seus preditores para gerar meu próprio modelo.
Você está falando da primeira amostra ou da segunda amostra? Se for a primeira, então eu tinha uma matriz de expectativa de cerca de 30 pontos para boas variantes.
Posso tentar treinar sua amostra no CatBoost, se você a carregar, é claro.
Aqui está a estratégia:
Na abertura do dia, calculamos a faixa limite esperada do movimento de preços. Para isso, podemos usar o ATR(3) no final do último dia, eu uso uma fórmula ligeiramente diferente. Adiamos esse intervalo desde o início da abertura do dia atual (barra) - consideramos que ele é 100%.
Quando atingimos um nível significativo acima/abaixo da abertura (eu parei em 23,6, pois, de acordo com minhas observações, isso costuma acontecer em diferentes instrumentos), abrimos uma posição com TP no próximo nível significativo (eu uso 61,8) e colocamos SL no preço de abertura do dia.
Se fecharmos com o take profit, entramos novamente quando um sinal aparecer.
É melhor fechar no final do dia (23h45) se as retiradas não funcionarem, mas, na verdade, estou esperando pelo TP/SL agora.
Agora, a marcação inicial funciona assim: se fechamos com lucro, colocamos 1, se fechamos com prejuízo, -1.
Ao dividir a amostra, fiz com que a meta fosse deslocada em 300 pips, portanto, se o lucro for menor que 300 pips, será zero.
Peguei dados de 2008. Sim, não há muitos dados, mas isso depende de como você olha para eles, porque se considerarmos que o nível de 23,6 não é acidental e que seu cruzamento é significativo para o mercado, então esses são eventos semelhantes que podem ser comparados entre si.
Agora o alvo está mais ou menos claro.
Você tem uma estimativa do resultado em pips ou apenas em ganhos/perdas? Parece que é a última opção. É melhor estimar em pts.
Assim, o modelo que dá 75% não funciona, na verdade, como 50/50.
ao contrário da situação em que as entradas são geradas em cada barra - há muitos desses eventos, o que só complica o aprendizado.
Eu gostaria de acrescentar o desbaste - barras semelhantes, se o preço não tiver subido 100...1000 pts, então pule.
Você está falando da primeira amostra ou da segunda amostra? Se estiver falando da primeira, então eu tinha uma matriz de expectativa de cerca de 30 pips para boas variantes.
Bem, a primeira não foi melhor (mas eu pesquisei menos, não selecionei recursos, por exemplo).
Posso tentar treinar sua amostra no CatBoost, se você fizer o upload, é claro.
Tenho centenas delas. E não gosto de colocar nenhuma delas em uma operação. Eu mudo o TP ou o SL ou qualquer outra coisa - essa é uma nova variante. Portanto, não vale a pena.
Agora a meta está mais ou menos clara.
Você tem uma estimativa do resultado em pontos ou apenas vitória/derrota? Parece que é a última opção. É melhor estimar em pontos.
Assim, um modelo de 75% não funciona realmente em 50/50.
Eu tenho uma avaliação em dinheiro :) Mais o alvo, como costumava ser. A meta pode ser movida posteriormente, se você quiser mais pontos.
Na estratégia específica, agora tudo é take profit. Fiz um lote calculado, na verdade, o spread piorou significativamente a proporção, mas está tudo bem, mas haverá estabilidade sem emissões de entradas super lucrativas - o risco é quase o mesmo em todos os lugares. Se você usar as pausas, será possível melhorar o resultado.
Gostaria de acrescentar o desbaste - barras semelhantes, se o preço não tiver subido 100...1000 pts, então pule.
E depois avaliar em cada barra, qual modelo aplicar?
O segundo em H1. Bem, o primeiro não foi melhor (mas eu pesquisei menos, não selecionei fichas, por exemplo).
Tenho centenas deles. E nenhuma delas eu gosto de colocar na negociação. Eu mudo o TP ou o SL ou qualquer outra coisa - essa é uma nova variante. Portanto, não faz sentido.
O que quero dizer é que, se houver o mesmo algoritmo para criar uma amostra, será possível comparar os preditores.
E então, para estimar em cada barra, qual o modelo a ser aplicado?
Sim, se pelo menos XX pips tiverem passado, como no treinamento. Mas haverá distorções - apenas as primeiras barras de 100 a 120 (200-220, etc.), se para cima e 999-979 (899-979) funcionarão com mais frequência.
O que quero dizer é que, se houver o mesmo algoritmo para criar uma amostra, será possível comparar os preditores.
Na verdade, não quero mais de 5.000, pois levará muito tempo para contar. Mas como uma pesquisa de preditores significativos, pode ser necessário verificá-los.
Boa tarde!
Tenho uma abordagem que pode resolver esse problema, mas, de preferência, os arquivos de amostra devem estar sem preditores. Ou seja, não são necessários mais de 5000 preditores, apenas o gráfico de movimento em si. O fato de ele consistir em OHLC ou ter uma variável não é importante. No entanto, tentei o método existente em uma variável da amostra, ou seja, na coluna 5584, que converti em um gráfico usando a fórmula D(i)=D(i-1)+ Target_100_Buy . Para todos os três arquivos, obtive estes gráficos:
1) treinamento: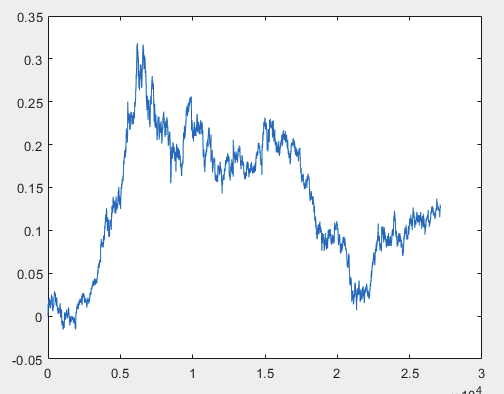
2)teste: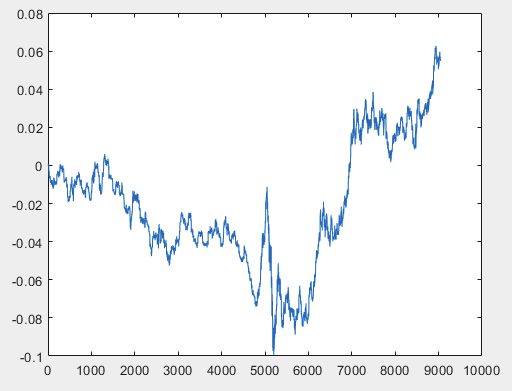
3) exame: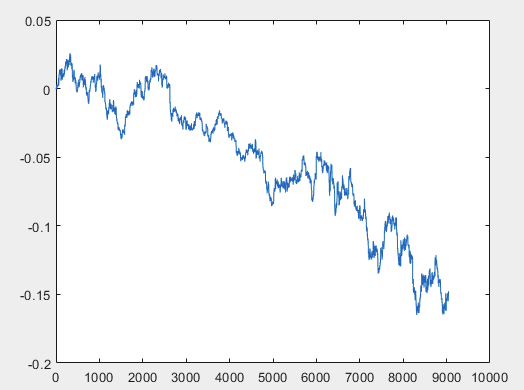
Não sei se fiz isso corretamente ou não, mas se o topikstarter criar novas amostras sem preditores, testarei o método em novos dados e falarei sobre a abordagem.
Bem, e o lucro real de cada uma das amostras após o treinamento do comitê de redes neurais (há 10 delas no total). O lucro é expresso em número de pontos, com spread=0 e comissão=0:
1) treinar: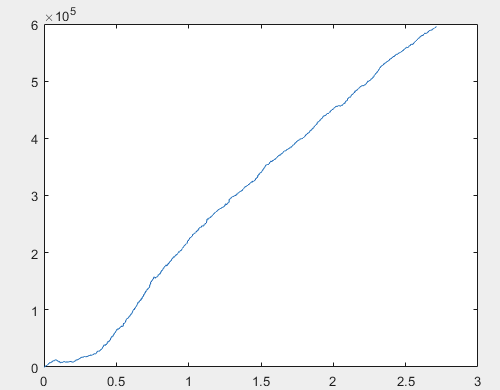
2) teste: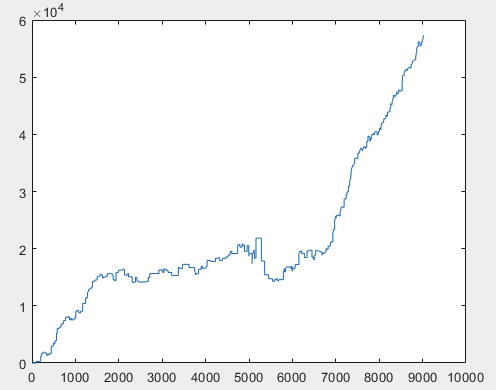
3) exame: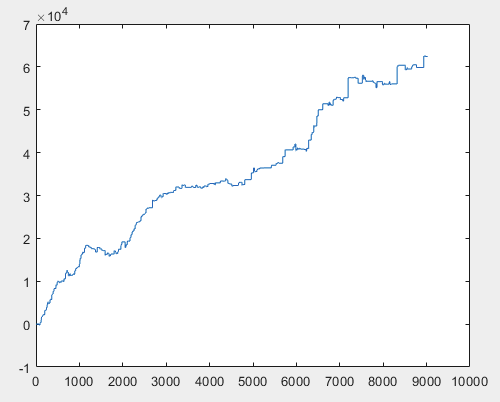
Acho que o resultado de mais de 60000 pips é bastante aceitável.
Sugiro que o topikstarter faça novas amostras, apenas do sinal mais "caótico".
O método será aplicado ao novo sinal e os resultados serão mostrados, assim como a abordagem será descrita até certo ponto.
Saudações, RomFil!
P.S. O futuro não é conhecido, mas um método para controlá-lo sempre pode ser encontrado... :)
Boa tarde!
Tenho uma abordagem que pode resolver esse problema, mas, de preferência, os arquivos de amostra devem estar sem preditores. Ou seja, não são necessários mais de 5000 preditores, apenas o gráfico de movimento em si. O fato de ele consistir em OHLC ou ter uma variável não é importante. No entanto, experimentei o método existente em uma variável da amostra, ou seja, na coluna 5584, que converti em um gráfico usando a fórmula D(i)=D(i-1)+ Target_100_Buy . Para todos os três arquivos, os gráficos são os seguintes:
Não entendo o que você fez e por que uma nova amostra é necessária se sua abordagem funciona com preços puros.
As colunas da lista abaixo são o resultado do evento que aconteceu, ou seja, elas não devem participar do treinamento. No máximo 5582 - mas aí acho que é fácil prever, portanto, será recuperado pelo modelo como está.
5581 Auxiliar
5582 Auxiliar
5583 Rótulo
5584 Auxiliar
5585 Auxiliar
Não entendo o que você fez e por que é necessária uma nova amostra se sua abordagem funciona com preços puros.
As colunas da lista abaixo são o resultado de um evento que aconteceu, ou seja, elas não deveriam participar do treinamento. No máximo 5582 - mas acho que é fácil de prever, portanto, será recuperado pelo modelo.
5581 Auxiliar
5582 Auxiliar
5583 Rótulo
5584 Auxiliar
5585 Auxiliar
"O que eu fiz?":
O trem de amostra tem cerca de 1 GB de tamanho. Leva muito tempo para carregá-lo no espaço de trabalho. Tenho um i5-3570 com 24 GB de RAM e um SSD rápido e o Excel leva vários minutos para abrir esse arquivo. Por isso, decidi que ele deveria ser reduzido. Eu estava com muita preguiça de descobrir os sobrescritos para mais de 5.000 colunas. Peguei a coluna 5584 5586 e apliquei um sinal a todas as linhas, por exemplo, COMPRAR (sinceramente, não me lembro qual, talvez VENDER). Assim, essa coluna formou um gráfico de acordo com a fórmula acima. Ou seja, o primeiro passo foi zero, depois 0,00007, depois 0,00007-0,00002=0,00005, depois 0,00005+0,00007=0,00012, etc. Ou seja, a partir da coluna 5584 5586, formei um gráfico de movimento sem vinculação, por assim dizer, um gráfico de movimento relativo. Como se fosse um gráfico Close, ou seja, ao final de cada etapa do gráfico, o preço do ativo muda pelo valor correspondente.
P.S. Enganei-me quanto ao número da coluna... Peguei o 5586 mais recente (acabei de procurar no Excel) com o sinal de VENDA.
"... por que uma nova amostra":
Para mostrar e contar, em certa medida, sobre a abordagem em seu exemplo. Se você nomear os números das colunas em que pode pegar os preços do OHLC ou apenas da Cláusula, isso será suficiente.
Sobre o restante:
Os dados dos arquivos de amostra não são usados de forma alguma. Com base nas colunas 5584 5586 de cada arquivo, é feito um gráfico conforme descrito acima. E a abordagem já está sendo aplicada a esses gráficos obtidos.
Bem, como o topikstarter não quer fornecer novas amostras, sugiro que os interessados publiquem suas próprias amostras... :)
Saudações, RomFil!
Boa tarde!
Tenho uma abordagem que pode resolver esse problema, mas, de preferência, os arquivos de amostra devem estar sem preditores. Ou seja, não são necessários mais de 5000 preditores, apenas o gráfico de movimento em si. O fato de ele consistir em OHLC ou ter uma variável não é importante. No entanto, experimentei o método existente em uma variável da amostra, a saber, a coluna 5584, que converti em um gráfico usando a fórmula D(i)=D(i-1)+ Target_100_Buy . Para todos os três arquivos, os gráficos são os seguintes:
A repetibilidade da função de destino é treinada? Por exemplo, se ela foi bem-sucedida 20 vezes, será bem-sucedida 21 vezes?
Quantos valores você insere como preditores?
Aqui estão os alvos mais simples para compra e venda com TP/SL=50 pts
M5 por cerca de 5 anos.
A marcação está em cada barra M5, ou seja, muito provavelmente a negociação do último sinal (5 minutos atrás) ainda não foi concluída. Não tenho certeza se seria correto empilhá-las. O empilhamento seria aceitável para um alvo com apenas uma negociação em um momento - mesmo 100 ao mesmo tempo podem não ser concluídas durante a noite.
P.S. - Eu os tenho como não treináveis. Eles sempre falham em meu conjunto de preditores.