Índice Hearst - página 22
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Estou confuso com seu "Não há um único que funcione", depois das palavras "... e na literatura". Há muitas abordagens diferentes na literatura que dão resultados ligeiramente diferentes umas das outras, o que não é surpreendente, pois todas elas são estimativas. Entretanto, também é verdade que quanto maior a amostra, mais precisas devem ser essas estimativas e mais "iguais" umas às outras. Eu só concordaria que um algoritmo Hurst viável é difícil de encontrar nos fóruns.
Quanto ao que alimentar a entrada do algoritmo, o algoritmo não se importa. Alimente o preço e você receberá algo em torno de um. De fato, para a essência do algoritmo, o preço tem uma forte memória a longo prazo, pois permanece relativamente distante dos valores originais. Incrementos de preço de ração - você recebe algo como 0,5, o que novamente se justifica, pois suas mudanças relativas são grandes e quase aleatórias. Tendências de alimentação e/ou ciclos - obter persistência. O ruído geralmente reduz o índice. Vejo que a pergunta, "nosso preço é ruidoso ou um preço de mercado justo?" não é o tema do algoritmo da Hearst, isso é outro domínio.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Em geral, quanto mais tempo, melhor. De acordo com o algoritmo do livro de Peters, o comprimento que tem o maior número de divisores de números inteiros é melhor.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Dois modelos são diferenciados:
1. O processo tem um índice Hurst "estável". Ou seja, o índice é uma constante e não muda no tempo (durante toda a existência do processo). Neste caso, sua definição é tomada como um mínimo - um segmento estatisticamente significativo - ou seja, um segmento que permite fazer uma estimativa confiante da distribuição do processo. Ou sem incomodar - o maior segmento possível.
2. O indicador é alguma função, possivelmente muito complexa, possivelmente aleatória. Neste caso, não há critérios objetivos para selecionar o comprimento da BP. Estimar um índice para um caso geral é impossível tanto no domínio do tempo quanto no da freqüência, a menos que você seja um médium.
É importante ressaltar que a análise RS é um dos métodos mais grosseiros, sua estimativa é sempre tendenciosa e o tamanho da amostra não ajudará de forma alguma. Para obter um cálculo correto do índice Hurst, use a estimativa baseada em ondas (o algoritmo pode ser encontrado em mathlab, por exemplo).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
O coração pelo preço é ~1, mas aqui o quê?
A única coisa que posso ajudar neste caso é ressaltar que não há análise Hurst ou R/S no arquivo _hurst_classik. O objetivo do próprio nome "R/S" é rescindir a linha. Mas o texto _hurst_classik que tem a pretensão de _RS_Analiz não contém qualquer remapeamento, mas, por exemplo, toma trivialmente a diferença entre os preços máximo e mínimo.
Além disso, a análise R/S, para alcançar Hearst, calcula a inclinação da curva e para isso necessita de muitos pontos no log(R/S) do plano - log(n) em vez de um. Neste milagre _RS_Analiz não existe tal coisa.
O ponto principal do meu posto era "identificar o modelo BP", mas isso não chamou sua atenção.
Se estamos falando de modelos da classe ARFIMA ou algo parecido, não estou realmente interessado, porque estes modelos estão crescendo "naqui", cujo objetivo é levantar dinheiro para fundos de investimento. Tal "ciência" é chamada de ciência de gabinete porque é criada apenas para ajustar a base científica para um resultado desejado conhecido, geralmente uma previsão de preço.
Se estamos falando de modelos da classe ARFIMA ou algo parecido, não estou realmente interessado, porque estes modelos estão crescendo "naqui", cujo objetivo é levantar dinheiro para fundos de investimento. Tal "ciência" é chamada de ciência de gabinete porque é criada apenas para adequar uma estrutura científica a um resultado deliberadamente desejado, geralmente uma previsão de preço.
Não vamos fazer estimativas. Estamos falando agora de abordagens que utilizam o modelo BP e não o utilizam de forma alguma.AJUDE A CALCULAR O INDICADOR DO CORAÇÃO!!! *
*como Peters
Li o fio condutor do começo ao fim: sim, não esperava que todos, desde os homens acadêmicos respeitados até os espectadores comuns, tivessem sua própria opinião sobre o que é Hirst, e como ela deve ser contada e interpretada. O mais próximo do original foi Eric Nyman em seu artigo e livro. Mas... nós (na Rússia, por assim dizer) ainda não temos uma ferramenta adequada para gerar gráficos, que são apresentados no livro de Peters.
Assim, tentei imitar o mais próximo possível a seqüência de passos que Peters descreveu em seu primeiro livro: "Chaos and Order in the Capital World", para calcular as estatísticas de R/S para o S&P 500.
1. Tomamos os gráficos mensais do S&P 500 de 01.01.1950 a 01.07.1988.
2. Nós os carregamos no programa de análise técnica (eu uso WealthLab e C#, aqui e mais adiante eu usarei o código WL/C#)
3. Converter preços em retornos usando a fórmula do livro de Peters: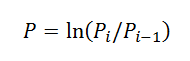
4. O próprio Peters não menciona que uma vez que os retornos são calculados, eles são convertidos de volta em uma série acumulada: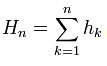 . No entanto, isto é óbvio, com base naqueles valores de difusão R/S que ele tem, além da fonte também o declara explicitamente, cito: "Para cada n natural, vamos compor os valores (ver fórmula acima) e calcular as seguintes características numéricas da subseqüência resultante".
. No entanto, isto é óbvio, com base naqueles valores de difusão R/S que ele tem, além da fonte também o declara explicitamente, cito: "Para cada n natural, vamos compor os valores (ver fórmula acima) e calcular as seguintes características numéricas da subseqüência resultante".
5. Dividimos a série resultante em k períodos, sendo a duração de cada período N de 6 a 231 meses ou observações.
6. Agora aqui está um ponto importante. Se o número inteiro de períodos não for obtido (os dados não utilizados permanecem), eles são descartados. Entretanto, se o restante for muito grande (por exemplo, 462 / 232 = 233 e 230 no restante), obtém-se um valor incorreto. Meu entendimento é que Peters usa turnos, no entanto, esta é uma opção muito trabalhosa em termos de programação e eu simplesmente descarto o período se seu residual for maior que 6. Como os períodos adjacentes têm quase o mesmo valor R/S, esta é a opção correta.
7. R é então calculado usando a fórmula:
8. R é dividido pelo desvio padrão (calculado pelo indicador WL) e logarítmico: log10(R/S).
9. O período atual é logarítmico: log10(N);
10. A relação log10(R/S) para log10(N) obtida é escrita no arquivo.
Se o otimizador passar por N de 6 (como Peters) a 231 (o número mínimo de experimentos é 2), então obtemos uma tabela de duas colunas em dupla escala logarítmica: 1. período 2. valor de R/S.
Agora começa a parte mais interessante. Se você traçar esta tabela em Excel, sairá o seguinte:
O original é apresentado à direita. Como você pode ver, existe alguma semelhança, mas ainda não a mesma. Em particular, o valor inicial acaba sendo ligeiramente superestimado (0,33 vs. cerca de 0,31) e, em segundo lugar, os valores finais começam a cair drasticamente de repente, o que não deveria ser o caso em princípio. De acordo com seu gráfico, apenas o ângulo de inclinação deve mudar no final da série, dizendo-nos que o efeito de memória é limitado.
Até agora, parei neste ponto. Ainda não decidi aplicar as estatísticas U/V, dada apenas a sobreposição parcial com o original.
A conversão das pontuações R/S para Hearst também dá resultados um pouco inflacionados. Se a pontuação do Hearst for: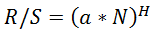 , então usando a fórmula Excel obtemos LOG(HERST(10;B1);C1*0,5), onde B1 é a pontuação atual R/S.
, então usando a fórmula Excel obtemos LOG(HERST(10;B1);C1*0,5), onde B1 é a pontuação atual R/S.
Abaixo está o código WL/C# que calcula as estatísticas R/S:
p.s. Engraçado, a MQL4 não tem palavras-chave como overide and using, mas a sintaxe ainda as destaca:)Existe um cálculo do índice Hurst no Matcad (precisa de fórmulas em forma discreta)?
Até agora, só encontrei isto
Arquivo com abordagens para análise de séries temporais em anexo. A partir daí, tomei estas fórmulas.
Desculpe, é claro.
É interessante? Olhando para estas fórmulas, não vejo o sentido em aplicá-las ao Forex.
É mais fácil elaborar uma série que descreve o forex. Já está por aí, as pessoas já ganharam prêmios Nobel por isso. Mas o resultado é muito médio. É necessário sempre estimar primeiro a média - o erro, e depois tentar remover os menos da probabilidade em conexão com os erros, e depois se preocupar com ele.
Desculpe, é claro.
Então, é interessante? Olhando para as fórmulas - não vejo qual o sentido de aplicá-las ao forex.
É mais fácil você mesmo lançar uma série que descreverá o forex. Ela já existe, as pessoas levaram um Prêmio Nobel por ela. Mas o resultado é muito, muito médio. Primeiro é necessário sempre estimar a média - o erro, e depois tentar remover os menos da probabilidade em conexão com os erros, e depois se preocupar com isso.
Desculpe. Mas, para o futuro, vamos concordar em não afixar musings ociosos neste tópico. Alguns estão interessados na "fila forex", outros nas estatísticas da Hearst. Que cada um tenha seu próprio fio condutor.
Estou colocando uma tabela tipo CSV em escala logarítmica dupla: estimativa R/S a período.