
Algorithmes d'optimisation de la population : Optimisation de la Lutte contre les Mauvaises Herbes Invasives (Invasive Weed Optimization, IWO)

Sommaire
1. Introduction
2. Description de l'algorithme
3. Résultats des tests
1. Introduction
L'algorithme métaheuristique des mauvaises herbes envahissantes est un algorithme d'optimisation basé sur la population qui trouve l'optimum global de la fonction optimisée en simulant la compatibilité et le caractère aléatoire d'une colonie de mauvaises herbes.
L'algorithme d'optimisation des mauvaises herbes fait référence à des algorithmes de population inspirés de la nature et reflète le comportement des mauvaises herbes dans une zone limitée dans la lutte pour la survie pendant une durée limitée.
Les mauvaises herbes sont des graminées puissantes qui, par leur croissance offensive, constituent une menace sérieuse pour les cultures. Elles sont très résistantes et s'adaptent aux changements environnementaux. Compte tenu de leurs caractéristiques, nous disposons d'un algorithme d'optimisation puissant. Cet algorithme tente d'imiter la robustesse, l'adaptabilité et le caractère aléatoire de la communauté des mauvaises herbes dans la nature.
Qu'est-ce qui rend les mauvaises herbes si spéciales ? Les mauvaises herbes ont tendance à être les premières à se répandre partout par le biais de divers mécanismes. Elles entrent donc rarement dans la catégorie des espèces menacées.
Vous trouverez ci-dessous une brève description de 8 façons dont les mauvaises herbes s'adaptent et survivent dans la nature :
1. Génotype universel. Les études ont révélé les changements évolutifs des mauvaises herbes en réponse au changement climatique.
2. Stratégies du cycle de vie, fertilité. Les mauvaises herbes présentent un large éventail de stratégies de cycle de vie. Au fur et à mesure que les systèmes de gestion du travail du sol évoluent, les mauvaises herbes qui n'étaient pas un problème majeur dans un système de culture donné deviennent plus résistantes. Par exemple, les systèmes de travail réduit du sol entraînent l'apparition d'herbes vivaces ayant des stratégies de cycle de vie différentes. Le changement climatique commence également à créer de nouvelles niches pour les espèces ou génotypes d'herbes dont le cycle de vie est mieux adapté aux conditions changeantes. En réponse à l'augmentation des émissions de dioxyde de carbone, les mauvaises herbes deviennent plus hautes, plus grandes et plus fortes, ce qui signifie qu'elles peuvent produire plus de graines et les disséminer plus loin à partir de plantes plus hautes grâce à leurs propriétés aérodynamiques. Leur fertilité est énorme. Par exemple, le laiteron des champs produit jusqu'à 19 000 graines.
3. Évolution rapide (germination, croissance sans prétention, compétitivité, système de sélection, production de semences et caractéristiques de distribution). La capacité accrue de dispersion des graines, la dispersion concomitante et la croissance sans prétention offrent des possibilités de survie. Les mauvaises herbes sont très peu sensibles aux conditions du sol et supportent sans broncher les fortes variations de température et d'humidité.
4. L'épigénétique. En plus d'une évolution rapide, de nombreuses plantes envahissantes ont la capacité de répondre rapidement à des facteurs environnementaux changeants en modifiant l'expression de leurs gènes. Dans un environnement en constante évolution, les plantes doivent être flexibles afin de résister aux stress, tels que les fluctuations de la lumière, de la température, de la disponibilité de l'eau et des niveaux de sel dans le sol. Pour être flexibles, les plantes sont capables de subir elles-mêmes des modifications épigénétiques.
5. Hybridation. Les espèces de mauvaises herbes hybrides présentent souvent une vigueur hybride, également connue sous le nom d'hétérosis. La progéniture présente une fonction biologique améliorée par rapport aux deux espèces parentales. En règle générale, un hybride présente une croissance plus agressive et une meilleure capacité à s'étendre à de nouveaux territoires et à concurrencer les territoires envahis.
6. Résistance et tolérance aux herbicides. Au cours des dernières décennies, la résistance aux herbicides a fortement augmenté dans la plupart des mauvaises herbes.
7. Coévolution des mauvaises herbes associées aux activités humaines. Les pratiques de lutte contre les mauvaises herbes, telles que l'application d'herbicides et le désherbage, ont permis aux mauvaises herbes de développer des mécanismes de résistance. Elles souffrent moins des dommages externes causés par le travail du sol que les plantes cultivées. Au contraire, ces dégâts sont souvent utiles pour la propagation des mauvaises herbes à multiplication végétative (par exemple, celles qui se propagent par des parties de la racine ou des rhizomes).
8. Les changements climatiques de plus en plus fréquents permettent aux mauvaises herbes d'être plus viables que les plantes cultivées en serre. Les mauvaises herbes causent de graves dommages à l'agriculture. Moins exigeantes en termes de conditions de culture, elles surpassent les plantes cultivées en termes de croissance et de développement. Absorbant l'humidité, les nutriments et la lumière du soleil, les mauvaises herbes réduisent fortement le rendement, rendent difficiles la récolte et le battage des cultures et détériorent la qualité des produits.
2. Description de l'algorithme
L'algorithme des mauvaises herbes envahissantes s'inspire du processus de croissance des mauvaises herbes dans la nature. Cette méthode a été introduite par Mehrabian et Lucas en 2006. Naturellement, les mauvaises herbes ont fortement poussé et cette forte croissance constitue une menace sérieuse pour les plantes utiles. Une caractéristique importante des mauvaises herbes est leur résistance et leur grande capacité d'adaptation dans la nature, ce qui constitue la base de l'optimisation de l'algorithme IWO. Cet algorithme peut être utilisé comme base pour des approches d'optimisation efficaces.
IWO est un algorithme numérique stochastique continu qui imite le comportement de colonisation des mauvaises herbes. Tout d'abord, la population initiale est distribuée de manière aléatoire sur l'ensemble de l'espace de recherche. Ces mauvaises herbes finiront par pousser et exécuter les étapes suivantes de l'algorithme. L'algorithme se compose de 7 étapes, qui peuvent être représentées sous forme de pseudo-code :
1. Semence des graines au hasard
2. Calcul de FF
3. Semence des graines des mauvaises herbes
4. Calcul de FF
5. Fusion des mauvaises herbes des enfants avec celles des parents
6. Tri de toutes les mauvaises herbes
7. Répétition à partir de l'étape 3 jusqu'à ce que la condition d'arrêt soit remplie.
Le diagramme de blocs représente le fonctionnement de l'algorithme à une itération. L'IWO commence son travail par le processus d'initialisation des semences. Les graines sont dispersées sur le "champ" de l'espace de recherche de manière aléatoire et régulière. Nous supposons ensuite que les graines ont germé et formé des plantes adultes, qui doivent être évaluées par la fonction d'aptitude.
Dans l'étape suivante, connaissant l'aptitude de chaque plante, nous pouvons permettre aux mauvaises herbes de se propager par le biais de graines, dont le nombre est proportionnel à l'aptitude. Nous combinons ensuite les graines germées avec les plantes mères et nous les trions. En général, l'algorithme de lutte contre les mauvaises herbes envahissantes peut être considéré comme simple à coder, à modifier et à utiliser avec des applications tierces.

Fig. 1 : Diagramme de blocs de l'algorithme IWO
Passons maintenant à l'examen des caractéristiques de l'algorithme des mauvaises herbes. Il présente un grand nombre des capacités de survie extrême des mauvaises herbes. Contrairement aux algorithmes génétiques, aux algorithmes d'abeilles et à d'autres, la colonie de mauvaises herbes se caractérise par le fait que toutes les plantes de la colonie, sans exception, sèment des graines. Cela permet même aux plantes les moins bien adaptées de laisser des descendants, puisqu'il existe toujours une probabilité non nulle que la plante la moins bien adaptée soit la plus proche de l'extrême global.
Comme je l'ai déjà dit, chacune des mauvaises herbes produit des graines dans une fourchette allant du minimum possible au maximum possible (paramètres externes de l'algorithme). Naturellement, dans de telles conditions, lorsque chaque plante laisse au moins une ou plusieurs graines, il y aura plus de plantes enfants que de plantes parents. Cette caractéristique est mise en œuvre de manière intéressante dans le code et sera examinée ci-dessous. L'algorithme général est présenté visuellement dans la figure 2. Les plantes mères dispersent les graines proportionnellement à leur aptitude.
Ainsi, la meilleure plante au numéro 1 a semé 6 graines, et la plante au numéro 6 n'a semé qu'une seule graine (celle qui est garantie). Les graines germées produisent des plantes qui sont ensuite triées avec les parents. Il s'agit d'une imitation de la survie. À partir de l'ensemble du groupe trié, de nouvelles plantes mères sont sélectionnées et le cycle de vie est répété à l'itération suivante. L'algorithme comporte un mécanisme permettant de résoudre les problèmes de "surpopulation" et de réalisation incomplète de la capacité d'ensemencement.
Prenons par exemple le nombre de graines. L'un des paramètres de l'algorithme est 50, et le nombre de plantes parentales est 5. Le nombre minimum de graines est 1, et le nombre maximum est 6. Dans ce cas, 5 * 6 = 30, ce qui est inférieur à 50. Comme le montre cet exemple, les possibilités de semis ne sont pas pleinement exploitées. Dans ce cas, le droit de garder un descendant passe au suivant dans la liste jusqu'à ce que le nombre maximum de descendants autorisé soit atteint dans toutes les plantes parentales. Lorsque la fin de la liste est atteinte, le droit va au premier de la liste et il sera autorisé à laisser un descendant dépassant la limite.

Fig. 2 : Fonctionnement de l'algorithme IWO Le nombre de descendants est proportionnel à l'aptitude du parent.
La prochaine chose à laquelle il faut prêter attention est la dispersion de l'ensemencement. La dispersion de l'ensemencement dans l'algorithme est une fonction linéaire décroissante proportionnelle au nombre d'itérations. Les paramètres de dispersion externes sont les limites inférieure et supérieure de la dispersion des semences. Ainsi, avec l'augmentation du nombre d'itérations, le rayon d'ensemencement diminue et les extrema trouvés sont affinés. Selon la recommandation des auteurs de l'algorithme, la distribution normale des semis devrait être appliquée. Mais j'ai simplifié les calculs et appliqué la fonction cubique. La fonction de dispersion du nombre d'itérations est illustrée à la figure 3.

Fig. 3 : La dépendance de la dispersion par rapport au nombre d'itérations, où 2 est la limite minimale et 3 la limite maximale
Passons au code de l’algorithme IWO. Le code est simple et rapide à exécuter.
L'unité la plus simple (agent) de l'algorithme est la "mauvaise herbe". Elle décrira également les graines de la mauvaise herbe. Cela nous permettra d'utiliser le même type de données pour les tris suivants. La structure se compose d'un tableau de coordonnées, d'une variable pour stocker la valeur de la fonction d'aptitude et d'un compteur pour le nombre de graines (descendants). Ce compteur nous permettra de contrôler le nombre minimum et maximum de graines autorisé pour chaque plante.
//—————————————————————————————————————————————————————————————————————————————— struct S_Weed { double c []; //coordinates double f; //fitness int s; //number of seeds }; //——————————————————————————————————————————————————————————————————————————————
Nous aurons besoin d'une structure pour mettre en œuvre la fonction de probabilité de choisir les parents proportionnellement à leur aptitude. Dans ce cas, on applique le principe de la roulette, que nous avons déjà vu dans l'algorithme de la colonie d'abeilles. Les variables "start" et "end" sont responsables du début et de la fin du champ de probabilité.
//—————————————————————————————————————————————————————————————————————————————— struct S_WeedFitness { double start; double end; }; //——————————————————————————————————————————————————————————————————————————————
Déclarons la classe de l'algorithme de désherbage. À l'intérieur de celui-ci, déclarez toutes les variables nécessaires : les limites et le pas des paramètres optimisés, le tableau décrivant les mauvaises herbes, ainsi que le tableau des graines, le tableau des meilleures coordonnées globales et la meilleure valeur de la fonction d'aptitude obtenue par l'algorithme. Nous avons également besoin de l'indicateur "semis" (sowing) de la première itération et des variables constantes des paramètres de l'algorithme.
//—————————————————————————————————————————————————————————————————————————————— class C_AO_IWO { //============================================================================ public: double rangeMax []; //maximum search range public: double rangeMin []; //manimum search range public: double rangeStep []; //step search public: S_Weed weeds []; //weeds public: S_Weed weedsT []; //temp weeds public: S_Weed seeds []; //seeds public: double cB []; //best coordinates public: double fB; //fitness of the best coordinates public: void Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP); //Maximum iterations public: void Sowing (int iter); public: void Germination (); //============================================================================ private: void Sorting (); private: double SeInDiSp (double In, double InMin, double InMax, double Step); private: double RNDfromCI (double Min, double Max); private: double Scale (double In, double InMIN, double InMAX, double OutMIN, double OutMAX, bool Revers); private: double vec []; //Vector private: int ind []; private: double val []; private: S_WeedFitness wf []; //Weed fitness private: bool sowing; //Sowing private: int coordinates; //Coordinates number private: int numberSeeds; //Number of seeds private: int numberWeeds; //Number of weeds private: int totalNumWeeds; //Total number of weeds private: int maxNumberSeeds; //Maximum number of seeds private: int minNumberSeeds; //Minimum number of seeds private: double maxDispersion; //Maximum dispersion private: double minDispersion; //Minimum dispersion private: int maxIteration; //Maximum iterations }; //——————————————————————————————————————————————————————————————————————————————
Dans la fonction d'initialisation, assignez une valeur aux variables constantes, vérifiez les paramètres d'entrée de l'algorithme pour des valeurs valides, de sorte que le produit des plantes parentales par la valeur minimale possible des graines ne peut pas dépasser le nombre total de graines. La somme des plantes parentales et des graines sera nécessaire pour déterminer le tableau de tri.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP) //Maximum iterations { MathSrand (GetTickCount ()); sowing = false; fB = -DBL_MAX; coordinates = coordinatesP; numberSeeds = numberSeedsP; numberWeeds = numberWeedsP; maxNumberSeeds = maxNumberSeedsP; minNumberSeeds = minNumberSeedsP; maxDispersion = maxDispersionP; minDispersion = minDispersionP; maxIteration = maxIterationP; if (minNumberSeeds < 1) minNumberSeeds = 1; if (numberWeeds * minNumberSeeds > numberSeeds) numberWeeds = numberSeeds / minNumberSeeds; else numberWeeds = numberWeedsP; totalNumWeeds = numberWeeds + numberSeeds; ArrayResize (rangeMax, coordinates); ArrayResize (rangeMin, coordinates); ArrayResize (rangeStep, coordinates); ArrayResize (vec, coordinates); ArrayResize (cB, coordinates); ArrayResize (weeds, totalNumWeeds); ArrayResize (weedsT, totalNumWeeds); ArrayResize (seeds, numberSeeds); for (int i = 0; i < numberWeeds; i++) { ArrayResize (weeds [i].c, coordinates); ArrayResize (weedsT [i].c, coordinates); weeds [i].f = -DBL_MAX; weeds [i].s = 0; } for (int i = 0; i < numberSeeds; i++) { ArrayResize (seeds [i].c, coordinates); seeds [i].s = 0; } ArrayResize (ind, totalNumWeeds); ArrayResize (val, totalNumWeeds); ArrayResize (wf, numberWeeds); } //——————————————————————————————————————————————————————————————————————————————
Considérons la première méthode publique appelée à chaque itération : Sowing(). Elle contient la logique principale de l'algorithme. Pour faciliter la perception, je diviserai la méthode en plusieurs parties.
Lorsque l'algorithme en est à sa première itération, il est nécessaire de semer des graines dans tout l'espace de recherche. Cela se fait généralement de manière aléatoire et régulière. Après avoir généré des nombres aléatoires dans la plage des valeurs acceptables des paramètres optimisés, vérifiez que les valeurs obtenues ne sortent pas de la plage et définissez le degré de discrétisation défini par les paramètres de l'algorithme. Nous y assignerons également un vecteur de distribution, dont nous aurons besoin lors de l'ensemencement des graines plus loin dans le code. Initialisez les valeurs d'aptitude des semences à la valeur double minimale et réinitialisez le compteur de semences (les semences deviendront des plantes qui utiliseront le compteur de semences).
//the first sowing of seeds--------------------------------------------------- if (!sowing) { fB = -DBL_MAX; for (int s = 0; s < numberSeeds; s++) { for (int c = 0; c < coordinates; c++) { seeds [s].c [c] = RNDfromCI (rangeMin [c], rangeMax [c]); seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); vec [c] = rangeMax [c] - rangeMin [c]; } seeds [s].f = -DBL_MAX; seeds [s].s = 0; } sowing = true; return; }
Dans cette section du code, la dispersion est calculée en fonction de l'itération en cours. Le nombre minimum garanti de graines pour chaque adventice parentale que j'ai mentionné précédemment est mis en œuvre ici. La garantie du nombre minimum de semences sera assurée par 2 boucles. Dans la première, nous trierons les plantes parentales, et dans la seconde nous générerons effectivement de nouvelles semences, tout en augmentant le compteur de semences. Comme vous pouvez le constater, la création d'un nouveau descendant a pour but d'incrémenter un nombre aléatoire avec la distribution d'une fonction cubique avec la dispersion calculée précédemment à la coordonnée parentale. Vérifiez que la valeur obtenue de la nouvelle coordonnée est acceptable et attribuez la discrépance.
//guaranteed sowing of seeds by each weed------------------------------------- int pos = 0; double r = 0.0; double dispersion = ((maxIteration - iter) / (double)maxIteration) * (maxDispersion - minDispersion) + minDispersion; for (int w = 0; w < numberWeeds; w++) { weeds [w].s = 0; for (int s = 0; s < minNumberSeeds; s++) { for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [pos].c [c] = weeds [w].c [c] + r * vec [c] * dispersion; seeds [pos].c [c] = SeInDiSp (seeds [pos].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } pos++; weeds [w].s++; } }
Avec ce code, nous fournirons des champs de probabilité pour chacune des plantes parentales, proportionnellement à leur aptitude, selon le principe de la roulette. Le code ci-dessus a fourni un nombre garanti de graines pour chacune des plantes à un moment où le nombre de graines obéit ici à une loi aléatoire, de sorte que plus la mauvaise herbe est adaptée, plus elle peut laisser de graines et vice versa. Moins la plante est adaptée, moins elle produira de graines.
//============================================================================ //sowing seeds in proportion to the fitness of weeds-------------------------- //the distribution of the probability field is proportional to the fitness of weeds wf [0].start = weeds [0].f; wf [0].end = wf [0].start + (weeds [0].f - weeds [numberWeeds - 1].f); for (int f = 1; f < numberWeeds; f++) { if (f != numberWeeds - 1) { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f].f - weeds [numberWeeds - 1].f); } else { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f - 1].f - weeds [f].f) * 0.1; } }
Sur la base des champs de probabilité obtenus, nous sélectionnons la plante mère qui a le droit de laisser un descendant. Si le compteur de semences a atteint la valeur maximale autorisée, le droit passe au suivant dans la liste triée. Si la fin de la liste est atteinte, le droit ne passe pas au suivant, mais au premier de la liste. Une plante fille est ensuite formée selon la règle décrite ci-dessus avec la dispersion calculée.
bool seedingLimit = false; int weedsPos = 0; for (int s = pos; s < numberSeeds; s++) { r = RNDfromCI (wf [0].start, wf [numberWeeds - 1].end); for (int f = 0; f < numberWeeds; f++) { if (wf [f].start <= r && r < wf [f].end) { weedsPos = f; break; } } if (weeds [weedsPos].s >= maxNumberSeeds) { seedingLimit = false; while (!seedingLimit) { weedsPos++; if (weedsPos >= numberWeeds) { weedsPos = 0; seedingLimit = true; } else { if (weeds [weedsPos].s < maxNumberSeeds) { seedingLimit = true; } } } } for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [s].c [c] = weeds [weedsPos].c [c] + r * vec [c] * dispersion; seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } seeds [s].s = 0; weeds [weedsPos].s++; }
La deuxième méthode ouverte doit obligatoirement être exécutée à chaque itération et est requise après le calcul de la fonction d'aptitude pour chaque enfant adventice. Avant d'appliquer le tri, placez les graines germées dans le tableau commun avec les plantes mères à la fin de la liste, remplaçant ainsi la génération précédente, qui pourrait inclure à la fois des descendants et des parents de l'itération précédente. Nous détruisons ainsi les mauvaises herbes faiblement adaptées, comme c'est le cas dans la nature. Il faut ensuite appliquer le tri. La première mauvaise herbe de la liste résultante méritera d'être mise à jour en tant que meilleure solution obtenue au niveau mondial si elle est réellement meilleure.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Germination () { for (int s = 0; s < numberSeeds; s++) { weeds [numberWeeds + s] = seeds [s]; } Sorting (); if (weeds [0].f > fB) fB = weeds [0].f; } //——————————————————————————————————————————————————————————————————————————————
3. Résultats des tests
Les résultats du banc d'essai se présentent maintenant de la façon suivante :
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) C_AO_IWO:50;12;5;2;0.2;0.01
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) 5 Rastrigin ; Func exécute 10000 résultats : 79,71791976868334
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) Score : 0,98775
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) 25 Rastrigin ; Func exécute 10000 résultats : 66,60305588198622
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) Score : 0,82525
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) 500 Rastrigin ; Func exécuté 10000 résultats : 45,4191288396659
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) Score : 0,56277
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) 5 Forest ; Func exécute 10000 résultats : 1,302934874807614
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) Score : 0,73701
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) 25 Forest ; Func exécute 10000 résultats : 0,5630336066477166
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) Score : 0,31848
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) 500 Forest ; Func exécute 10000 résultats : 0,11082098547471195
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) Score : 0,06269
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) 5 Megacity ; Func exécute 10000 résultats : 6,640000000000001
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) Score : 0,55333
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) 25 Megacity ; Func exécute 10000 résultats : 2,6
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) Score : 0,21667
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) 500 Megacity ; Func exécute 10000 résultats : 0,5668
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) Score : 0,04723
Un coup d'œil rapide suffit pour constater les bons résultats de l'algorithme sur les fonctions de test. Il y a une préférence notable pour les fonctions lisses, bien que jusqu'à présent aucun des algorithmes considérés n'ait montré une meilleure convergence sur les fonctions discrètes que sur les fonctions lisses, ce qui s'explique par la complexité des fonctions Forest et Megacity pour tous les algorithmes sans exception. Il est possible que nous obtenions un jour un algorithme pour les tests qui résoudra les fonctions discrètes mieux que les fonctions lisses.

IWO sur la fonction de test de Rastrigin

IWO sur la fonction de test Forest

IWO sur la fonction de test Megacity
L'algorithme des mauvaises herbes envahissantes a montré des résultats impressionnants dans la plupart des tests, en particulier sur la fonction de Rastrigin lisse avec 10 et 50 paramètres. Sa performance n'a légèrement baissé que pour le test avec 1000 paramètres, ce qui indique en général une bonne performance pour les fonctions lisses. Cela me permet de recommander l'algorithme pour les fonctions lisses complexes et les réseaux neuronaux. En ce qui concerne les fonctions Forest, l'algorithme a obtenu de bons résultats lors du premier test avec 10 paramètres, mais les résultats sont restés globalement moyens. Sur la fonction discrète Megacity, l'algorithme invasif des mauvaises herbes a obtenu des résultats supérieurs à la moyenne, montrant en particulier une excellente évolutivité sur le test avec 1000 variables, perdant sa première place uniquement au profit de l'algorithme firefly, mais le surpassant de manière significative sur les tests avec 10 et 50 paramètres.
Bien que l'algorithme des mauvaises herbes envahissantes comporte un nombre relativement important de paramètres, cela ne doit pas être considéré comme un inconvénient, car les paramètres sont très intuitifs et peuvent être facilement configurés. Le réglage fin de l'algorithme n'affecte généralement que les résultats des tests d'une fonction discrète, alors que les résultats sur une fonction lisse restent bons.
Sur la visualisation des fonctions de test, la capacité de l'algorithme à isoler et à explorer certaines parties de l'espace de recherche est clairement visible, comme c'est le cas pour l'algorithme de l'abeille et d'autres algorithmes. Pourtant, plusieurs publications indiquent que l'algorithme a tendance à se bloquer et que ses capacités de recherche sont faibles. Bien que l'algorithme ne fasse pas référence à l'extremum global, ni aux mécanismes permettant de "sortir" des pièges locaux, l'IWO parvient à fonctionner de manière adéquate sur des fonctions aussi complexes que Forest et Megacity. Lorsque l'on travaille sur une fonction discrète, plus les paramètres sont optimisés, plus les résultats sont stables.
Étant donné que la dispersion des semences diminue linéairement à chaque itération, le raffinement de l'extremum augmente davantage vers la fin de l'optimisation. À mon avis, ce n'est pas tout à fait optimal, car les capacités exploratoires de l'algorithme sont inégalement réparties dans le temps, ce que l'on peut constater sur la visualisation des fonctions de test sous forme de bruit blanc constant. L'irrégularité de la recherche peut également être évaluée par les graphiques de convergence dans la partie droite de la fenêtre du banc d'essai. Une certaine accélération de la convergence est observée au début de l'optimisation, ce qui est typique de presque tous les algorithmes. Après un démarrage rapide, la convergence se ralentit pendant la majeure partie de l'optimisation. Ce n'est qu'à l'approche de la fin que l'on peut constater une accélération significative de la convergence. Le changement dynamique de la dispersion justifie des études et des expériences plus détaillées. Puisque nous voyons que la convergence pourrait reprendre si le nombre d'itérations était plus grand. Toutefois, les tests comparatifs effectués dans un souci d'objectivité et de validité pratique présentent des limites.
Passons maintenant au tableau de classement final. Le tableau montre que l'IWO est actuellement un leader. L'algorithme a obtenu les meilleurs résultats dans 2 tests sur 9. Dans les autres tests, les résultats sont bien meilleurs que la moyenne, de sorte que le résultat final est de 100 points. L'algorithme des colonies de fourmis modifié (ACOm) vient en 2ème position. Il reste le meilleur dans 5 tests sur 9.
| AO | Description | Rastrigin | Rastrigin final | Forest | Forest final | Megacity (discrète) | Megacity final | Résultat final | ||||||
| 10 paramètres (5 F) | 50 paramètres (25 F) | 1.000 paramètres (500 F) | 10 paramètres (5 F) | 50 paramètres (25 F) | 1.000 paramètres (500 F) | 10 paramètres (5 F) | 50 paramètres (25 F) | 1.000 paramètres (500 F) | ||||||
| IWO | Optimisation des mauvaises herbes envahissantes | 1,00000 | 1,00000 | 0,33519 | 2,33519 | 0,79937 | 0,46349 | 0,41071 | 1,67357 | 0,75912 | 0,44903 | 0,94088 | 2,14903 | 100,000 |
| ACOm | optimisation par colonies de fourmis M | 0,36118 | 0,26810 | 0,17991 | 0,80919 | 1,00000 | 1,00000 | 1,00000 | 3,00000 | 1,00000 | 1,00000 | 0,10959 | 2,10959 | 95,996 |
| COAm | algorithme d'optimisation coucou M | 0,96423 | 0,69756 | 0,28892 | 1,95071 | 0,64504 | 0,34034 | 0,21362 | 1,19900 | 0,67153 | 0,34273 | 0,45422 | 1,46848 | 74,204 |
| FAm | algorithme firefly M | 0,62430 | 0,50653 | 0,18102 | 1,31185 | 0,55408 | 0,42299 | 0,64360 | 1,62067 | 0,21167 | 0,28416 | 1,00000 | 1,49583 | 71,024 |
| BA | algorithme des chauves-souris | 0,42290 | 0,95047 | 1,00000 | 2,37337 | 0,17768 | 0,17477 | 0,33595 | 0,68840 | 0,15329 | 0,07158 | 0,46287 | 0,68774 | 59,650 |
| ABC | colonie d'abeilles artificielles | 0,81573 | 0,48767 | 0,22588 | 1,52928 | 0,58850 | 0,21455 | 0,17249 | 0,97554 | 0,47444 | 0,26681 | 0,35941 | 1,10066 | 57,237 |
| FSS | recherche d'un banc de poissons | 0,48850 | 0,37769 | 0,11006 | 0,97625 | 0,07806 | 0,05013 | 0,08423 | 0,21242 | 0,00000 | 0,01084 | 0,18998 | 0,20082 | 20,109 |
| PSO | optimisation par essaims de particules | 0,21339 | 0,12224 | 0,05966 | 0,39529 | 0,15345 | 0,10486 | 0,28099 | 0,53930 | 0,08028 | 0,02385 | 0,00000 | 0,10413 | 14,232 |
| RND | aléatoire | 0,17559 | 0,14524 | 0,07011 | 0,39094 | 0,08623 | 0,04810 | 0,06094 | 0,19527 | 0,00000 | 0,00000 | 0,08904 | 0,08904 | 8,142 |
| GWO | optimiseur du loup gris | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,18977 | 0,04119 | 0,01802 | 0,24898 | 1,000 |
L'algorithme "invasive weed" est excellent pour la recherche globale. Cet algorithme présente de bonnes performances, bien que le meilleur membre de la population ne soit pas utilisé et qu'il n'y ait pas de mécanismes de protection contre le collage potentiel dans les extrêmes locaux. Il n'y a pas d'équilibre entre la recherche et l'exploitation de l'algorithme, mais cela n'a pas eu d'incidence négative sur la précision et la vitesse de l'algorithme. Cet algorithme présente également d'autres inconvénients. La performance inégale de la recherche tout au long de l'optimisation suggère que la performance de l'IWO pourrait potentiellement être plus élevée si les problèmes exprimés ci-dessus pouvaient être résolus.
Histogramme des résultats des tests de l'algorithme dans la figure 4
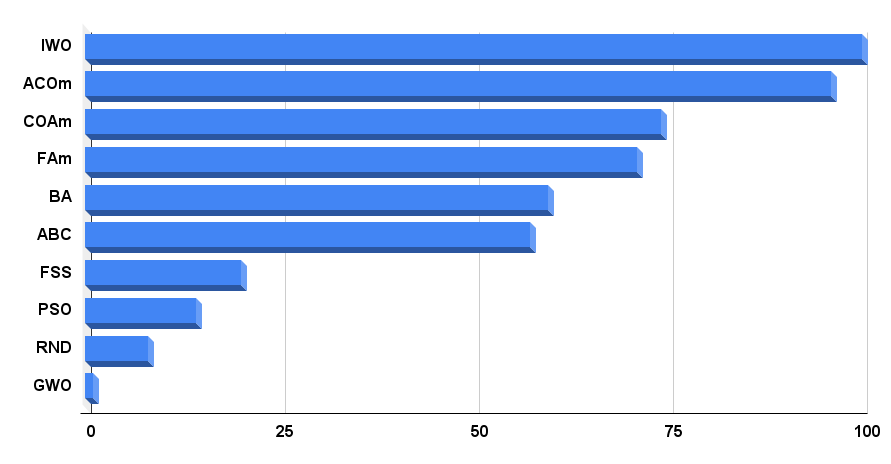
Fig. 4 : Histogramme des résultats finaux des algorithmes de test
Conclusions sur les propriétés de l'algorithme d'Optimisation des Mauvaise Herbes Envahissantes (Invasive Weed Optimization - IWO) :
Avantages :
1. Grande vitesse
2. L'algorithme fonctionne bien avec différents types de fonctions, à la fois lisses et discrètes.
3. Bonne évolutivité
Inconvénients :
1. De nombreux paramètres (bien qu'ils soient explicites)
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/11990
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Apprendre à concevoir un système de trading basé sur les Fractales
Apprendre à concevoir un système de trading basé sur les Fractales
 Développer un Expert Advisor de trading à partir de zéro (Partie 25) : Assurer la robustesse du système (II)
Développer un Expert Advisor de trading à partir de zéro (Partie 25) : Assurer la robustesse du système (II)
 Développer un Expert Advisor de trading à partir de zéro (Partie 26) : En route vers le futur (1)
Développer un Expert Advisor de trading à partir de zéro (Partie 26) : En route vers le futur (1)
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Que signifient les chiffres du tableau ?