"New Neural" ist ein Open-Source-Projekt für neuronale Netzwerke für die MetaTrader 5-Plattform. - Seite 56
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ja, das ist genau das, was ich wissen wollte.
An mql5
SZ Die Hauptsorge ist im Moment, ob die Daten in spezielle CPU-Arrays kopiert werden müssen oder ob die Übergabe eines Arrays als Parameter in einer normalen Funktion unterstützt wird. Diese Frage kann das gesamte Projekt grundlegend verändern.
ZZY können Sie in Ihren Plänen zu geben, nur OpenCL-API, oder planen Sie, um es in Ihrem eigenen Wrapper verpacken beantworten?
2) Es wird einen Wrapper geben, nur HW GPUs werden unterstützt (mit OpenCL 1.1 Unterstützung).
Die Auswahl mehrerer GPUs ist, wenn überhaupt, nur über die Terminaleinstellungen möglich.
OpenCL wird synchron verwendet.
Ja, das ist genau das, was ich wissen wollte.
An mql5
SZ Die Hauptsorge ist im Moment, ob die Daten in spezielle CPU-Arrays kopiert werden müssen oder ob die Übergabe eines Arrays als Parameter in einer normalen Funktion unterstützt wird. Diese Frage kann das gesamte Projekt grundlegend verändern.
ZZZY können Sie in Pläne zu geben, nur OpenCL-API oder planen Sie, es in Ihre eigenen Wrapper verpacken beantworten?
Beurteilung durch:
mql5:
Sie können die Funktionen der OpenCL.dll-Bibliothek direkt nutzen, ohne DLLs von Drittanbietern einbinden zu müssen.
OpenCL.dll-Funktionen werden so verfügbar sein, als wären sie native MQL5-Funktionen, während der Compiler die Aufrufe selbst umleitet.
Daraus lässt sich schließen, dass OpenCL.dll-Funktionen bereits jetzt festgelegt werden können (Dummy-Aufrufe).
Renat und mql5, habe ich die "Umgebung" richtig verstanden?
Beurteilung durch:
OpenCL.dll-Funktionen können so verwendet werden, als wären sie native MQL5-Funktionen, und der Compiler selbst wird die Aufrufe umleiten.
Daraus lässt sich schließen, dass OpenCL.dll-Funktionen bereits jetzt festgelegt werden können (Dummy-Aufrufe).
Renat und mql5, habe ich die "Situation" richtig verstanden?
Das ist der bisherige Plan des Projekts:
Objekte sind Rechtecke, Methoden sind Ellipsen.Die Verarbeitungsmethoden werden in 4 Kategorien unterteilt:
Diese vier Methoden beschreiben die gesamte Verarbeitung über alle Schichten hinweg. Die Methoden werden über Methodenobjekte in die Verarbeitung importiert, die von der Basisklasse geerbt und je nach Art des Neurons nach Bedarf überladen werden.
Nikolai, Sie kennen das Sprichwort: Vorschnelle Optimierung ist die Wurzel allen Übels.
Vergessen Sie OpenCL für den Moment, Sie werden etwas Anständiges ohne es machen müssen. Sie werden immer Zeit haben, sie umzusetzen, vor allem, wenn sie noch nicht verfügbar ist.
Nikolay, du kennst doch den beliebten Spruch: Vorzeitige Optimierung ist die Wurzel allen Übels.
Vergessen Sie OpenCL für den Moment; Sie hätten auch ohne es etwas Anständiges schreiben können. Außerdem gibt es noch keine interne Funktion.
Ja, das ist eine beliebte Phrase, und ich hätte ihr beim letzten Mal fast zugestimmt, aber nach der Analyse wurde mir klar, dass ich sie nicht einfach planen und dann für die GPU umgestalten kann, denn sie hat sehr spezifische Bedürfnisse.
Wenn wir ohne GPU planen, dann wäre es logisch, ein Neuron-Objekt zu erstellen, das sowohl für die Operationen innerhalb eines Neurons als auch für die Zuweisung von Berechnungsdaten in die erforderlichen Speicherzellen zuständig wäre, indem wir eine Klasse von einem gemeinsamen Vorfahren erben, könnten wir den erforderlichen Neurontyp leicht verbinden und so weiter,
Aber nachdem ich ein wenig mit meinem Gehirn gearbeitet hatte, verstand ich sofort, dass dieser Ansatz die Berechnungen von GPU völlig zerstören wird, das ungeborene Kind ist zum Kriechen verdammt.
Aber ich vermute, dass mein obiger Beitrag Sie verwirrt hat. Mit "paralleler Rechenmethode" meine ich dort eine ganz bestimmte Operation der Multiplikation von Eingaben mit Gewichten in*wg, mit sukzessiver Rechenmethode meine ich sum+=a[i] und so weiter.
Nur für eine bessere zukünftige GPU-Kompatibilität schlage ich vor, Operationen von Neuronen abzuleiten und sie in einem einzigen Zug in einem Layer-Objekt zu kombinieren, und die Neuronen würden nur die Informationen liefern, von wo aus sie zu nehmen sind, wo sie zu setzen sind.
Vorlesung 1 hier https://www.mql5.com/ru/forum/4956/page23
Vortrag 2 hier https://www.mql5.com/ru/forum/4956/page34
Vortrag 3 hier https://www.mql5.com/ru/forum/4956/page36
Vortrag 4 hier https://www.mql5.com/ru/forum/4956/page46
Vorlesung 5 (letzte). Sparsame Kodierung
Dieses Thema ist das interessanteste. Ich werde diesen Vortrag nach und nach schreiben. Vergessen Sie also nicht, diesen Beitrag von Zeit zu Zeit zu lesen.
Im Allgemeinen besteht unsere Aufgabe darin, die Kursnotierung (Vektor x) der letzten N Bars als lineare Zerlegung in Basisfunktionen (Reihen der Matrix A) darzustellen:
wobei s die Koeffizienten unserer linearen Transformation sind, die wir finden und als Eingaben für die nächste Schicht des neuronalen Netzes (z. B. SVM) verwenden wollen. In den meisten Fällen kennen wir die Basisfunktionen A , d. h. wir wählen sie im Voraus. Sie können Sinus und Kosinus verschiedener Frequenzen (wir erhalten die Fourier-Transformation), Gabor-Funktionen, Hammotons, Wavelets, Curlets, Polynome oder beliebige andere Funktionen sein. Wenn diese Funktionen vorher bekannt sind, dann reduziert sich die spärliche Kodierung darauf, einen Vektor von Koeffizienten s so zu finden, dass die meisten dieser Koeffizienten Null sind (spärlicher Vektor). Die Idee dahinter ist, dass die meisten Informationssignale eine Struktur haben, die durch eine geringere Anzahl von Basisfunktionen beschrieben wird als die Anzahl der Signalproben. Diese Basisfunktionen, die in der spärlichen Beschreibung des Signals enthalten sind, sind seine notwendigen Merkmale, die für die Signalklassifizierung verwendet werden können.
Das Problem, die entladene lineare Transformation der ursprünglichen Information zu finden, wird Compressed Sensing (http://ru.wikipedia.org/wiki/Compressive_sensing) genannt. Im Allgemeinen wird das Problem wie folgt formuliert:
Minimierung der L0-Norm von s, vorbehaltlich As = x
wobei die L0-Norm gleich der Anzahl der von Null verschiedenen Werte des Vektors s ist. Die gebräuchlichste Methode zur Lösung dieses Problems ist die Ersetzung der L0-Norm durch die L1-Norm, die die Grundlage der Basis-Pursuit-Methode(https://en.wikipedia.org/wiki/Basis_pursuit) bildet:
Minimierung der L1-Norm von s, vorbehaltlich As = x
wobei die L1-Norm berechnet wird als |s_1|+|s_2|+...+|s_L|. Dieses Problem lässt sich auf eine lineare Optimierung reduzieren
Ein weiteres beliebtes Verfahren zum Auffinden des spärlichen Vektors s ist das Matching Pursuit(https://en.wikipedia.org/wiki/Matching_pursuit). Bei diesem Verfahren geht es im Wesentlichen darum, die erste Basisfunktion a_i einer gegebenen Matrix A so zu finden, dass sie mit dem größten Koeffizienten s_i im Vergleich zu anderen Basisfunktionen in den Eingangsvektor x passt.Nachdem wir a_i*s_i vom Eingangsvektor subtrahiert haben, addieren wir die nächste Basisfunktion zum resultierenden Restwert, und so weiter, bis wir den vorgegebenen Fehler erreichen. Ein Beispiel für das Matching-Pursuit-Verfahren ist der folgende Indikator, der einen Sinus nach dem anderen in den Eingangsvektor mit dem kleinsten Rest einträgt: https://www.mql5.com/ru/code/130.
Wenn uns die BasisfunktionenA(Wörterbuch) nicht vorher bekannt sind, müssen wir sie aus den Eingabedatenx mit Methoden finden, die man Wörterbuchlernen nennt. Dies ist der schwierigste (und für mich der interessanteste) Teil der Sparse-Coding-Methode. In meiner vorherigen Vorlesung habe ich gezeigt, wie diese Funktionen z. B. mit der Ogi-Regel gefunden werden können, die diese Funktionen zu Hauptvektoren von Eingangsanführungszeichen macht. Leider führt diese Art von Basisfunktionen nicht zu einer disjunkten Beschreibung der Eingabedaten (d.h. der Vektor s ist unvollständig).
Bestehende Methoden zum Lernen von Wörterbüchern, die zu disjunkten linearen Transformationen führen, werden unterteilt in
Probabilistische Methoden zur Ermittlung von Basisfunktionen werden auf die Maximierung der Wahrscheinlichkeit reduziert:
P(x|A) über A zu maximieren.
In der Regel wird angenommen, dass der Approximationsfehler eine Gaußsche Verteilung hat, was uns dazu führt, das folgende Optimierungsproblem zu lösen:
(1)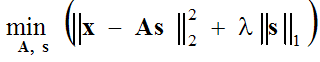 ,
,
die in zwei Schritten gelöst wird: (1 - Schritt der spärlichen Kodierung) mit festen Basisfunktionen A wird der Ausdruck in Klammern in Bezug auf den Vektor s minimiert, und (2 - Schritt der Aktualisierung des Wörterbuchs) der gefundene Vektors wird festgelegt und der Ausdruck in Klammern wird in Bezug auf die Basisfunktionen A unter Verwendung der Gradientenabstiegsmethode minimiert:
(2)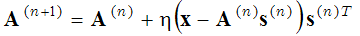
wobei (n+1) und (n) im Hochkomma die Iterationszahlen bezeichnen. Diese beiden Schritte (Sparse-Coding-Schritt und Wörterbuch-Lernschritt) werden so lange wiederholt, bis ein lokales Minimum erreicht ist. Diese probabilistische Methode zur Ermittlung von Basisfunktionen wird z. B. verwendet in
Olshausen, B. A., & Field, D. J. (1996). Entstehung von Eigenschaften des rezeptiven Feldes einfacher Zellen durch Lernen eines spärlichen Codes für natürliche Bilder. Natur, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Lernen von überkompletten Repräsentationen. Neural Comput, 12(2), 337-365.
Die Methode der optimalen Richtungen (MOD) verwendet dieselben zwei Optimierungsschritte (Schritt der Sparse-Codierung und Schritt des Wörterbuchlernens), aber im zweiten Optimierungsschritt (Schritt der Wörterbuchaktualisierung) werden die Basisfunktionen berechnet, indem die Ableitung des Ausdrucks in Klammern (1) in Bezug auf A mit Null gleichgesetzt wird:
wo wir
(3)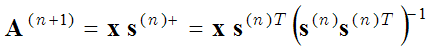 ,
,
wobei s+ eine pseudo-inverse Matrix ist. Dies ist eine genauere Berechnung der Basismatrix als die Methode des Gradientenabstiegs (2). Die MOD-Methode wird hier ausführlicher beschrieben:
K. Engan, S.O. Aase, und J.H. Hakon-Husoy. Methode der optimalen Richtungen für die Rahmenkonstruktion. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, S. 2443-2446, 1999.
Die Berechnung von pseudo-inversen Matrizen ist mühsam. Die k-SVD-Methode vermeidet dies. Ich habe es noch nicht herausgefunden. Sie können es hier nachlesen:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: Ein Algorithmus für den Entwurf von überkompletten Wörterbüchern für die spärliche Repräsentation. IEEE Trans. Signalverarbeitung, 54(11), November 2006.
Auch das Clustering und die Online-Methoden zum Auffinden des Wörterbuchs habe ich noch nicht herausgefunden. Interessierte Leser können sich auf die nächste Umfrage beziehen:
R. Rubinstein, A. M. Bruckstein, and M. Elad, "Dictionaries for sparse representation modeling," Proc. of IEEE , 98(6), pp. 1045-1057, June 2010.
Hier finden Sie einige interessante Videovorträge zu diesem Thema:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
Das ist alles für den Moment. Ich werde dieses Thema in künftigen Beiträgen vertiefen, wenn ich dazu in der Lage bin und wenn die Besucher dieses Forums daran interessiert sind.
Nikolai, Sie kennen ja den Spruch: Vorzeitige Optimierung ist die Wurzel allen Übels.
Es ist eine so gängige Phrase für Entwickler, um ihre Nutzlosigkeit zu verschleiern, dass man jedes Mal, wenn man sie benutzt, eine Ohrfeige bekommt.
Der Satz ist grundsätzlich schädlich und absolut falsch, wenn es um die Entwicklung von Qualitätssoftware mit langem Lebenszyklus und direkter Ausrichtung auf hohe Geschwindigkeit und hohe Belastungen geht.
Das habe ich in meiner langjährigen Projektmanagement-Praxis immer wieder feststellen können.
Der Begriff ist so gebräuchlich, um die Fehler der Entwickler zu vertuschen, dass man jedes Mal, wenn man ihn verwendet, einen Klaps auf die Finger bekommen kann.
Sie müssen also einige Funktionen berücksichtigen, die wer weiß wann mit wer weiß welcher Schnittstelle im Voraus erscheinen werden, weil sie Ihnen einen Leistungsschub geben?
Das habe ich in meiner langjährigen Projektmanagementpraxis schon oft getestet.