Diskussion zum Artikel "Random Decision Forest und Reinforcement-Learning"
if(ts<0.4 && CheckMoneyForTrade(_Symbol,lots,ORDER_TYPE_BUY)) { if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)) { updatePolicy(ts); }; }
Sie können sie durch diese ersetzen
if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts);
Übrigens wird Ihre Variante der if(OrderSend)-Prüfung immer funktionieren. Denn OrderSend gibt im Falle eines Fehlers nicht Null zurück.
Leider ist das genau das, was wir tun müssen. In diesem Artikel finden Sie eine interessante Möglichkeit, Daten an die Agenten zu "übergeben".

- 2018.02.27
- Aleksey Zinovik
- www.mql5.com
Leider ist dies genau das, was wir tun müssen. Schauen Sie sich diesen Artikel an, er bietet eine interessante Möglichkeit, Daten an Agenten zu "übergeben".
Ja, ich habe ihn gesehen, es ist ein toller Artikel. Ich habe mich entschlossen, nichts Ausgefallenes zu machen, weil die Leistung so, wie sie ist, in Ordnung ist, ich brauchte nicht viele Übergaben.
Respekt an den Autor für ein großartiges Beispiel einer ML-Implementierung mit nativen MQL-Tools und ohne jegliche Krücken!
Meine einzige IMHO-Meinung bezieht sich auf die Positionierung dieses Beispiels als Reinforcement Learning.
Erstens scheint es mir, dass Reinforcement einen dosierten Effekt auf das Gedächtnis des Agenten haben sollte, d.h. in diesem Fall auf RDF, aber hier filtert es nur die Proben der Trainingsstichprobe und es ist praktisch nicht viel anders als die Vorbereitung von Daten für das Training mit einem Lehrer.
Zweitens ist das Training selbst nicht streaming, kontinuierlich, sondern einmalig, denn nach jedem Durchlauf des Testers, während des Optimierungsprozesses, wird das gesamte System erneut trainiert, ganz zu schweigen von der Echtzeit.
Respekt an den Autor für ein großartiges Beispiel einer ML-Implementierung unter Verwendung nativer MQL-Tools und ohne jegliche Krücken!
Meine einzige IMHO, in Bezug auf die Positionierung dieses Beispiels als Reinforcement Learning.
Erstens scheint es mir, dass das Reinforcement den Speicher des Agenten, d.h. in diesem Fall RDF, dosiert beeinflussen sollte, aber hier filtert es nur die Proben der Trainingsstichprobe und es ist praktisch nicht viel anders als die Vorbereitung von Daten für das Training mit einem Lehrer.
Zweitens ist das Training selbst nicht streaming, kontinuierlich, sondern ad hoc, da nach jedem Durchlauf des Testers, während des Optimierungsprozesses, das gesamte System erneut trainiert wird, ich spreche nicht von Echtzeit.
Das stimmt, es handelt sich um ein einfaches, grobkörniges Beispiel, das eher darauf abzielt, Vertrautheit zu schaffen als Verstärkungslernen. Ich denke, es lohnt sich, das Thema weiterzuentwickeln und andere Möglichkeiten der Verstärkung zu untersuchen.
Informativ, vielen Dank!
Erstens scheint es mir, dass die Verstärkung das Gedächtnis des Agenten dosieren sollte, d.h. in diesem Fall RDF, aber hier filtert sie nur die Trainingsmuster und unterscheidet sich kaum von den Trainingsdaten beim Lernen mit einem Lehrer.
Zweitens ist das Training selbst kein kontinuierliches Streaming, sondern ein einmaliges, denn nach jedem Durchlauf des Testers wird im Zuge der Optimierung das gesamte System erneut trainiert, ich spreche nicht von Echtzeit.
Ich möchte Ihre Antwort noch ein wenig ergänzen. Diese 2 Punkte sind eng miteinander verbunden. Diese Version ist eine Abwandlung des Themas der Erfahrungswiederholung. Das würde die Tabelle nicht ständig aktualisieren und den Wald nicht neu trainieren (was ressourcenintensiver wäre), und nur am Ende auf eine neue Erfahrung umlernen. D.h. dies ist eine völlig legitime Variante der Verstärkung und wird z.B. in DeepMind für Atari-Spiele verwendet, aber dort ist alles komplizierter und es werden Mini-Batches verwendet, um Overfit zu bekämpfen.
Um das Lernen zu streamen, wäre es gut, ein NS mit zusätzlichem Lernen zu haben, ich schaue in Richtung Bayes'sche Netze. Wenn Sie oder jemand anderes Beispiele für solche Netze auf Plus hat - ich wäre dankbar :)
Nochmals, wenn es keine Möglichkeit für den Approximator gibt, sich neu zu trainieren - dann müsste ich für eine Echtzeitaktualisierung die gesamte Matrix der vergangenen Zustände ziehen, und einfach jedes Mal die gesamte Stichprobe neu zu trainieren ist keine sehr elegante und langsame Lösung (mit steigender Anzahl von Zuständen und Merkmalen)
Außerdem würde ich gerne Q-Phrase und NN mit mql kombinieren, aber ich verstehe nicht, warum ich es verwenden und mit Zustandsübergangswahrscheinlichkeiten zyklieren soll, wenn ich mich auf die übliche zeitliche Differenzschätzung beschränken kann, wie in diesem Papier. Daher ist actor-critic hier besser geeignet.
Ich möchte die Antwort noch ein wenig ergänzen. Diese 2 Punkte sind eng miteinander verbunden. Diese Version ist eine Variation des Themas der Erfahrungswiederholung. Das würde die Tabelle nicht ständig aktualisieren und den Wald nicht neu trainieren (was ressourcenintensiver wäre), und erst am Ende auf eine neue Erfahrung umlernen. D.h. dies ist eine völlig legitime Variante des Reenforcings und wird z.B. in DeepMind für Atari-Spiele verwendet, aber dort ist alles komplizierter und es werden Mini-Batches verwendet, um Overfitting zu bekämpfen.
Um das Lernen flüssiger zu machen, wäre es gut, ein NS mit zusätzlichem Lernen zu haben, ich denke da an Bayes'sche Netze. Wenn Sie oder jemand anderes hat Beispiele für solche Netze auf Pluspunkte - ich wäre dankbar :)
Nochmals, wenn es keine Möglichkeit für den Approximator gibt, sich neu zu trainieren - dann muss man für eine Echtzeitaktualisierung die gesamte Matrix der vergangenen Zustände ziehen, und einfach jedes Mal auf der gesamten Stichprobe neu zu trainieren ist keine sehr elegante und langsame Lösung (mit zunehmender Anzahl von Zuständen und Merkmalen)
Außerdem würde ich gerne Q-Phrase und NN mit mql kombinieren, aber ich verstehe nicht, warum ich es verwenden und mit Zustandsübergangswahrscheinlichkeiten zirkulieren soll, wenn ich mich auf die übliche zeitliche Differenzschätzung beschränken kann, wie in diesem Papier. Also ist actor-critic hier eher das Thema.
Ich bestreite nicht, dass die Variante mit der Reproduktion von Erfahrung, in Form von Batch-Lernen, eine legitime Implementierung von RL ist, aber sie ist auch eine Demonstration eines seiner Hauptnachteile - die langfristige Kreditvergabe, da die Belohnung (Verstärkung) in ihr mit einer Verzögerung erfolgt, was ineffizient sein kann.
Gleichzeitig gibt es einen weiteren bekannten Nachteil in Form einer Verletzung des Gleichgewichts - Exploration vs. Exploration, denn bis zum Ende des Durchgangs können alle Erfahrungen nur angesammelt werden und können in keiner Weise in der aktuellen Betriebssitzung verwendet werden. Daher ist es IMHO wahrscheinlich, dass im RL ohne Streaming Learning nichts Gutes passieren wird.
Was neue Beispiele von Netzwerken angeht, wenn wir über das P-Netz sprechen, das ich hier im Forum erwähnt habe, ist es immer noch NDA, also kann ich den Quellcode nicht teilen. Technisch gesehen gibt es natürlich seine Vor- und Nachteile, von den positiven - hohe Lerngeschwindigkeit, Arbeit mit verschiedenen Datenobjekten, zusätzliches Training in der Zukunft, vielleicht LSTM.
Im Moment gibt es eine Bibliothek für Python und nativen MT4 EA-Generator, alle in der Testphase. Für die direkte Kodierung gibt es eine Variante mit einem Python-Interpreter, der in die Engine eingebaut ist, mit dem man durch Codeblöcke arbeiten kann, die direkt vom EA durch benannte Kanäle übergeben werden.
Was die reine MQL-Implementierung von RL betrifft, weiß ich nicht, intuitiv scheint es, dass es in der dynamischen Konstruktion von Entscheidungsbäumen (Policy Trees) oder Manipulationen mit Arrays von Gewichten zwischen MLPs liegen sollte, vielleicht Modifikationen auf der Grundlage entsprechender Klassen aus Alglib....
Gut gemacht, Mikhail! Sie haben 20 % des Weges zum Erfolg zurückgelegt. Das ist ein Lob, die anderen 3 % sind geschafft. Und Sie gehen in die richtige Richtung.
Viele Leute fügen einem Expert Advisor mit 37 Indikatoren 84 weitere Indikatoren hinzu und denken "jetzt wird es bestimmt funktionieren". Das ist naiv.
Und nun zur Sache. Sie haben nur einen Dialog zwischen Maschine und Maschine. Meiner Meinung nach sollten Sie Maschine - Mensch - Maschine hinzufügen.
Ich werde es erklären. In der Spieltheorie haben strategische Spiele folgende Eigenschaften: eine große Anzahl von zufälligen, regelmäßigen und psychologischen Faktoren.
Psychologisch - das ist wie: Es gibt gute Filme, es gibt schlechte Filme, und es gibt indische Filme. Verstehen Sie, was ich meine?
Wenn Sie daran interessiert sind, fragen Sie dann, wie es weitergehen soll und wie man es realisieren kann? Ich werde antworten - ich weiß es noch nicht, ich versuche selbst, eine Antwort zu finden.
Aber wenn man sich nur auf Autos fixiert, ist es wie mit 84 Blinkern: hinzufügen oder nicht hinzufügen, man wird sich im Kreis drehen.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Random Decision Forest und Reinforcement-Learning :
Random Forest (RF) mit dem Einsatz von Bagging ist eine der leistungsfähigsten maschinellen Lernmethoden, die dem Gradienten-Boosting etwas unterlegen ist. Dieser Artikel versucht, ein selbstlernendes Handelssystem zu entwickeln, das Entscheidungen basierend auf den Erfahrungen aus der Interaktion mit dem Markt trifft.
Man kann sagen, dass ein Zufallswald ein Sonderfall des Baggings ist, bei dem Entscheidungsbäume als Basisfamilie verwendet werden. Gleichzeitig wird, anders als bei der konventionellen Entscheidungsbaum-Konstruktion, auf das Pruning (Beschneiden) verzichtet. Die Methode ist dafür gedacht, aus großen Datenmengen so schnell wie möglich eine Stichprobe zu konstruieren. Jeder Baum ist auf eine bestimmte Art und Weise aufgebaut. Ein Merkmal (Attribut) zum Aufbau eines Baumknotens wird nicht aus der Gesamtzahl der Merkmale ausgewählt, sondern aus deren zufälliger Untermenge. Beim Aufbau eines Regressionsmodells ist die Anzahl der Merkmale n/3. Im Falle einer Klassifizierung ist es √n. All dies sind empirische Empfehlungen und werden Dekorrelation genannt: Unterschiedliche Merkmale fallen in verschiedene Bäume, und die Bäume werden an verschiedenen Proben trainiert.
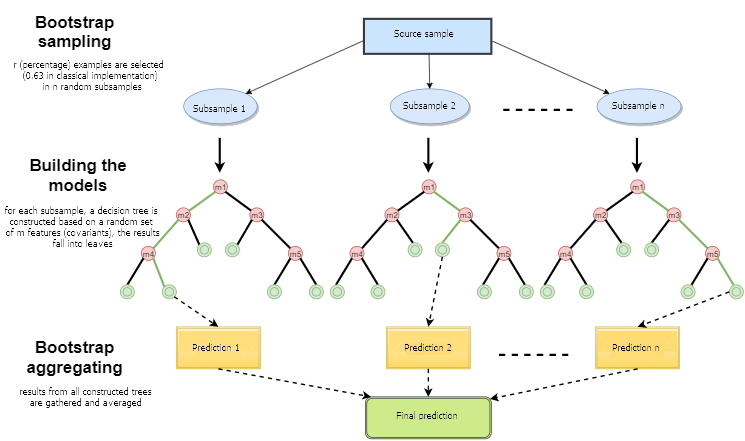
Abb. 1. Schema des Random ForestAutor: Maxim Dmitrievsky