Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
В статье рассматриваются новые возможности пакета darch (v.0.12.0). Описаны результаты обучения глубокой нейросети с различными типами данных, структурой и последовательностью обучения. Проанализированы результаты.
我又从这个 样本中删去了两年,考试的平均分已经变成了-485 分(原来是1214 分),通过 3000 分限制的模型数量变成了 884 个(上次 是 277 个)。
然而,测试样本的结果却从平均 2115 分下降到 186 分,即大幅下降。这是什么原因呢--难道与测试样本类似的训练样本中的例子减少了?
树的平均数量从 10 棵减少到 7 棵。
图表上的零点突破使平衡分布向中心偏移。
说结果应该与 测试 结果相似的依据是什么?我假定样本不是同质的--其中没有数量相当的相似例子,而且我认为量子的概率分布也有一些差异。
特雷纳 我说的是有良好模式的数据。如果将乘法表的 1000 个变体输入到训练中,那么从未与轨迹匹配(但在轨迹边界内)的新变体也会计算得很好。一棵树会给出最接近的变体,而随机森林会平均计算 100 个最接近的变体,并很可能给出比一棵树更准确的答案。
如果能为市场找到具有规律性的预测因子,那么 OOS 也将类似于跟踪。但不会像现在这样,一半以上的模型是负值,三分之一是正值。所有成功的模型都是随机种子偶然产生的。
种子只会稍微改变模型的成功率,一般来说,它们都应该是成功的。现在却没有发现任何模式(过度训练/训练不足)。
它只用于控制训练的停止,也就是说,如果在训练时测试模型没有改进,那么训练就会停止,树会被移除到测试模型最后一次改进的位置。
这样一来,测试也很好的原因就很清楚了。这本质上是对测试的拟合。在 1 次训练中,我不再这样做了。我向前进行估值,将所有 OOCs 粘合在一起,然后从粘合的 OOCs 的众多变体中选择最佳模型超参数(深度、树数等)。我认为,考试的结果将与选择粘合所有 OOC 的结果大致相同。在 5 年多的时间里,我每周都要重新训练一次,这相当于进行了数百次 OOS 训练和大块训练。
显然,我没有清楚说明我使用的样本--这是此处 所述实验的第六个(最后一个)样本,因此只有 61 个预测因子。
原始策略,尤其是在市场平坦的地区。你从 5000 多个样本中选出了这 61 个。我的总数少,选中的数量也少。而且每次增加 1 个时,在选中 3-4 个之后,再增加符号只会使 OOS 结果更糟。
一般来说,我可以添加更多的预测因子,因为现在只使用了 3 个 TF,只有少数例外--我认为可以再添加几千个预测因子,但考虑到 61 个预测因子的 10000 个种子变量会产生如此大的传播....,所有预测因子能否在训练中得到正确使用还是个问题。
当然,你还需要对预测因子进行预筛选,这将加快训练速度。
如果这些预测因子都差不多,就不太可能找到能明显改善结果的预测因子。您可以尝试全新的数据或独特的指标。
初步筛选也是一项漫长的工作,一次增加一个特征的时间要长很多倍,甚至要增加到 3 个特征,如果增加到 10 个,那就需要很多天。 但这样做没有意义,3-4 个特征之后通常就没有改进了。但偶尔也会有,但增幅很小。在那里没有发现突破(在我的实验中,可能有人会发现)。
异常值就是异常值,这是合乎逻辑的,我只是认为这些是低效率,应该通过去除白噪声来学习。在其他领域,简单原始的策略往往有效,尤其是在市场平坦的地区。
底图是盈利的,但 5 年中只有 2017 年有 2 个时期增长强劲(显然有很强的可预测趋势),模型在这 2 个时期赚的钱最多。而如果能在一段时间内有均匀的增长就更好了。
当然,您也可以制作一个 EA - 等待白天鹅。但我更喜欢主动交易。
从这个 样本中再减去两年,考试平均分已经变成了-485(上次 是-1214),突破 3000 分限制的机型数量变成了 884(上次 是 277)。
然而,测试样本的结果却从平均 2115 分大幅下降到 186 分。这是什么原因呢?难道是训练样本中与测试样本相似的例子少了吗?
树的平均数量从 10 棵减少到 7 棵。
图表上的零点突破使平衡分布向中心偏移。
你能不能把第一个帖子中的文件发布出来,我也想试试一个想法。
Traine 我说的是有良好模式的数据。如果你提交 1000 个乘法表的变体进行训练,那么从未与轨迹重合(但在轨迹边界内)的新变体也会被很好地计算出来。一棵树会给出最接近的变体,而随机森林会平均计算 100 个最接近的变体,并很可能给出比一棵树更准确的答案。
如果能为市场找到具有规律性的预测因子,那么 OOS 也将与追踪相似。但不会像现在这样,一半以上的模型是负值,三分之一是正值。所有成功的模型都是随机种子偶然产生的。
种子只会稍微改变模型的成功率,一般来说,它们都应该是成功的。现在却没有发现任何模式(过度训练/训练不足)。
没有人认为,只要有好的数据,一切都很可能完美运行。但是,你不可能获得这样的数据,所以你必须想办法从现有的数据中挤出些什么。
事实上,随机获得有效模型是有可能的,而这些模型在新数据上也会有效,这让我想知道如何减少这种随机性,也就是说,是否有任何量子片段的常规度量标准,而模型正是建立在这些标准之上的。也就是说,我们谈论的是目标上的贪婪之外的额外指标。如果能建立起这种依赖关系,那么建立模型的成功概率也会更高。当然,这应该适用于不同的样本。
那我就明白为什么测试也很好了。这本质上是对测试的拟合。我在 1 项研究中已经停止这样做了。我先做估值,将所有 OOCs 粘合在一起,然后从粘合 OOCs 的许多变体中选择最佳模型超参数(深度、树数等)。我认为,考试的结果将与选择粘合所有 OOC 的结果大致相同。在 5 年多的时间里,我每周都会对该变体进行一次重新训练--这就是数以百计的 OOS 训练和分块。
最主要的是不要分开最后的考试部分。
拟合超参数并根据什么评估结果?如果按照你的逻辑,我认为这就是带有平均因素的拟合。
CatBoost 的逻辑是,如果不可能改进模型(通过 Logloss),那么就没有必要继续训练。在这种情况下,当然不能保证模型一定是好的。
你从 5000 多人中选出的 61 人。我既有总数,也有选中的数量。在每次添加 1 个特征时,在选中 3-4 个特征后,进一步添加特征只会使 OOS 结果更糟。
不,我没有选择它们--我是在对所有预测因子进行训练时将它们从模型中删除的。
听着,我通常将预测因子视为一组量子片段。因此,我选择了量子片段,一般来说,我甚至可以将所有预测器分解为二进制预测器--结果会稍差一些,但也不相上下。对于二进制排放预测器,也许需要一种特殊的训练方法。
如果它们都差不多,那就不太可能找到任何能严重改善结果的方法。您可以尝试全新的数据或独特的指标。
你说的 "差不多 "是什么意思,我猜你是指指标还是什么?当然,您可以尝试不同的数据,比如使用不同的工具。
预筛选也是一项漫长的工作,一个一个地添加需要很多时间,即使添加到 3 个功能也是如此,如果添加到 10 个功能,则需要很多天。但偶尔也会有改进,但幅度很小。在那里没有发现突破(在我的实验中,可能有人会发现)。
你说的变体是一个漫长的游戏,这也是我不玩它的原因(好吧,我没有完全自动化)。但是,我并不同意没有影响的说法--我曾在小组中进行过弃权,并减少了小组--结果是积极的。但我仍将这些行为归因于拟合或随机性--没有理由选择预测因子。
下图是盈利的,但 5 年中只有 2017 年有 2 个时期增长强劲(显然有很强的可预测趋势),模型在这 2 个时期盈利最多。而如果能在一段时间内实现均匀增长就更好了。我会在一个月不活动后关闭这样的模型。
当然,你也可以制作一个 Expert Advisor - 等待白天鹅。但我更喜欢活跃的交易。
这就是为什么我赞成使用成套模型,因为我知道每套模型都能捕捉到自己不常见的模式。
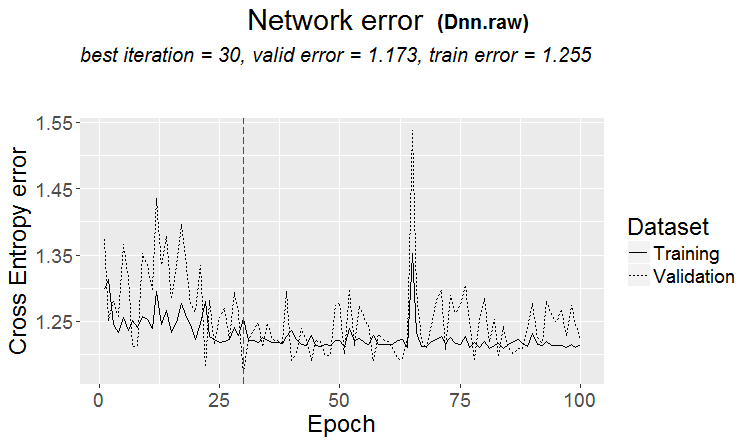
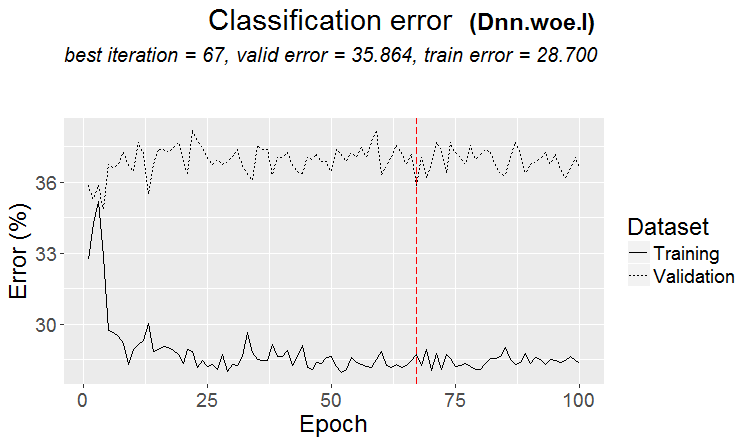
一般来说,我们的目标是使追踪和测试的误差大致相同。在这里,您的考试正朝着训练线和测试的方向移动,即向上,而它们正朝着测试的方向移动,即向下。过度训练会降低误差。
从哪个角度看它们是相似的?
举例来说,我们用精确度指标,从训练中减去测试样本上的这一指标,- 我们就得到了 delta(y 轴),然后用 x 来表示考试样本上的利润。
这两者之间是否存在特殊的依赖关系?
以下是每个样本的两个指标--数据是在模型中添加新树时获取的。
以下是该模型的特征
以下是另一个模型的指标,损失了两个样本
以下是该模型的特征
用论坛方式回复很不方便,要多次点击回复。下面我的回答用颜色标出。
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> 很久以前就看过量子是如何构建的,基本变体。首先,对列进行排序。
1) 按范围、偶数步长(例如,从 0 到 1,数值步长正好为 0.1,共 10 个量子 0.1、0.2、0.3 ...0.9)
2) 百分位数--即按示例数。如果我们除以 10 个量子,那么在每个量子中我们都要放入所有行数的 10%,如果有很多双倍数,那么有些量子将超过 10%,因为双倍数不应该落入其他量子中,例如,如果双倍数占样本的 30%,那么在这个量子中它们将全部落入。根据每个量子的样本数,分布可能是 0.001,0.12,0.45,0.51,0.74,....。0.98.
3) 有两种类型的组合
因此,构造量子并没有什么高明之处。这两种量子化方法都是我自己做的。我总是用我认为更好的方法来做事。也许我犯了一个错误。我通常不使用量化方法,而是使用浮动数据进行计算。
如果将所有预测因子都设为二进制,那么就只有两个量子,一个是全部为 0 的量子,另一个是全部为 1 的量子。
你拟合超参数,然后根据什么来评估结果?如果按照你的逻辑,我认为这和使用平均元素进行拟合是一样的。
> 我看的是平衡图和缩减图。我还不能自动选择。是的,拟合是为了更好地粘合 OOS。但不是模型本身(即不是跟踪),而是选择模型的最佳超参数。
你说的 "差不多 "是什么意思,我猜你是在说一些指标还是什么?当然,您也可以尝试其他数据,比如使用其他工具。
> 所有这些都是根据价格和混搭制作的。
关于一个老问题。
说结果应该与 火车 相似的依据是什么?我假设样本不是同质的--没有可比数量的相似例子,而且我认为量子的概率分布略有不同。
> 这里的例子https://www.mql5.com/ru/articles/3473
一个很好的变体是当发现一种模式时:三元组和测试的误差几乎相同
在市场上更经常发生这样的情况:测试结果很好,但在经过某一步训练后(图中第三步后)开始重新训练,测试误差开始增长。这些图片指的是神经网络,但森林和 boost 也会出现类似情况,即模型训练过度。
它们相似的指标是什么?
但这并不意味着你的指标不好。
因此,量子结构并没有什么高明之处。这两种量子化方法都是我自己做的。我总是用我认为更好的方法来做事。也许我犯了一个错误。我通常不使用量化方法,而是使用浮动数据进行计算。
当然也有不同的方法,我现在用了大约 900 个量子表。
重点不在于方法,而在于选择预测器的范围,在这个范围内,二进制目标的平均值要高于样本(现在我把最小值定为 5%,再加上实例数量的标准--也是最小值 5%),这表明预测器中存在有用的信息。如果没有此类信息,您可以希望它在几次分割中出现,但我认为这种可能性较小。
事实上,有 1-2 个这样的图的情况时有发生,很少有很多这样的图。在这里,你可以只取这些图,也可以只取有这些图的预测因子,选择最好的量子表。
就我个人而言,我发现预测器(至少我的预测器)的概率并不是平稳过渡的,而是不连续的,会向相反的偏差变化,即原来是+5,马上就变成了-5。我甚至认为,如果这些概率是有序的,模型就会更容易训练,因为它们是根据范围来训练的。这就是为什么要排除无信息的区域并将有冲突的区域分开的原因。
如果将所有预测因子都设为二进制,那么就只有 2 个量子,一个是全部为 0 的量子,一个是全部为 1 的量子。
实际上只有一个 - 0,5 :)但是,这样你就可以把预测器分解成有用的(包含潜在有用信息的)范围。
> 查看平衡图表和缩减。自动选择还没有成功。是的,拟合--为了获得最佳的 OOS 粘合效果。但不是模型本身(即不是跟踪),而是选择模型的最佳超参数。
嗯,这可以理解,但并不规范--我认为模型度量也很重要。
> 所有这些都是在价格和混搭的基础上完成的。
理论上是的,如果你使用神经网络,但事实上--不--太复杂的依赖关系应该用不同的计算方法来搜索,普通用户根本没有这种计算能力。
关于一个老问题。
> 这里的例子https://www.mql5.com/ru/articles/3473
一个很好的变体是当发现一种模式时:三元组和测试的误差几乎相同
在市场上,更常见的情况是这样的:测试很好,但在某个训练步骤之后(图中第三步之后)开始重新训练,测试误差开始增长。这些图片指的是神经网络,但森林和 boost 也会出现类似情况,即模型训练过度。
规律性总会被发现--这就是原理--问题是这种规律性是否会继续出现。
我不知道你有什么样的样本。我曾经遇到过测试比训练学得更快的情况,但更常见的情况是相反,两者之间存在明显的差距。当然,在理想情况下,两者的差距会很小。
我可以肯定地说,模型训练不足只是因为样本不是很相似,当没有改进时,训练就会停止。
有一天,我会向您展示重新训练的样本的图形外观--它是两个用角分隔的凸起....
将训练样本再减半。
只有 306 个模型,考试的平均收益为-2791 分。
但我得到了这个模型
具有这些特征
Mat 期望值确实下降了,但 Recall 却增长了一倍--原因就在于此,以及这样一张具有大量交易的图表。
使用了这样的预测因子:
而且比样本中少 9 个--我将尝试只使用它们,并对整个样本(所有列车线路)进行训练。
分割只在量子范围内进行。量子内部的一切都被认为是相同的值,不会被进一步拆分。我不明白你为什么要在量子中寻找什么,它的主要作用是加快计算速度(次要作用是加载/概 化模型,以便不再分割,但你可以限制浮动数据的深度)。我对 65000 个部分进行了量化--结果与没有量化的模型完全一样。
就我个人而言,我发现预测器(至少是我的预测器)的概率并不是平滑过渡的,而是突然发生变化,变成相反的偏差,即原来是 +5,马上变成 -5。
我还注意到类似的情况。深度增加 1 会极大地改变收益率,有时是 +,有时是 -。
事实上,会有一个 - 0.5 :)但是,这样就可以将预测器分割成有用的(包含潜在有用信息的)范围。
有一种分割方法可以将数据分成两个部分--一个部分的数据全部为 0,另一个部分的数据全部为 1。我不知道什么叫量子,我认为量子就是量化后得到的扇区数。也许就像你说的,是分割的数量。