混乱中有规律可循吗?让我们试着找出它!以特定样本为例进行机器学习。 - 页 18 1...111213141516171819202122232425...32 新评论 Aleksei Kuznetsov 2023.01.15 13:51 #171 Aleksey Vyazmikin #:随机是固定的)看来这个种子的计算方法很复杂,即 可能涉及到所有 允许用于建立模型的 预测因子,改变它们的数量也会改变选择结果。 起始种子是固定的。然后每次调用 HSC 时都会出现一个新的种子数。这就是为什么在预测因子数量和 DST 数量不同的情况下,预测因子的数量不会与预测因子数量相同。 Aleksey Vyazmikin#: 为什么会出现这种拟合 情况?我倾向于认为测试样本与考试的差异大于考试与训练的差异,即预测因子的概率分布不同。 好吧,你选取了最好的考试变体,希望它们在测试中表现出色。你根据最好的考试选择预测因子。但它们只在考试中是最好的。 Aleksey Vyazmikin#: 什么是 "err_"指标? err_ oob - OOB(考试)误差,err_trn - 火车误差。根据公式,我们将得到两个样本点的共同误差。 顺便说一下,在讨论中我们把测试和考试对调了一下。起初,我们计划在测试中进行中间检查,在考试中进行最终检查。不过,虽然名称变了,但上下文已经清楚地说明了什么是什么。 Aleksey Vyazmikin 2023.01.15 14:32 #172 elibrarius #:起始号码是固定的。然后每次调用 DST 都会出现一个新的数字。因此,在不同的预测数和 DST 次数下,不会出现预测数满时落到同一预测数上的情况。但是,如果用于训练的预测器数量保持不变,变体就会重现。elibrarius#: 好吧,你选取了最好的考试变体,希望它们在考试中表现出色。预测因子是由最好的考试选择出来的。但它们只有在考试中才是最好的。碰巧的是,这个变量是最平衡的--在测试和考试中都有不错的收益。下图是最初选择的模型--"Was "和经过 10k 训练后的最佳平衡模型--"Became"。总的来说,结果更好,使用的预测因子更少,因此噪音被消除了。这里的问题是如何在训练前避免噪音。 因此,我们的逻辑是,训练在测试中停止,因此在测试中出现积极结果的可能性应该比在完全不参与训练的样本中出现积极结果的可能性大,所以重点放在后者上。elibrarius#: err_ oob - OOB 上的错误(你已经进行了考试),err_trn - trn 上的错误。根据公式,我们将得到两个样本点的一些共同误差。我的意思是,我不知道 "err "是如何计算的--是精确度吗?还有,为什么是考试而不是测试,因为在基本方法中,考试我们是不知道的。elibrarius#: 顺便说一下,我们在讨论中把测试和考试对调了一下。最初的计划是在测试中进行中间测试,在考试中进行最终测试。但根据上下文,我们可以清楚地知道什么是什么,尽管他们更改了名称。我没有改变任何东西(也许我在什么地方描述过自己?)--它就是这样的--培训--培训,测试--停止培训的控制,考试--不参与任何培训的部分。我只是通过所有模型的平均值来评估这种方法的有效性,包括平均利润--它比具有良好结果的边缘更有可能获得。 Aleksei Kuznetsov 2023.01.15 15:53 #173 Aleksey Vyazmikin #: 还有一个问题是,在开始训练之前,如何避免这种噪音。 。 显然不能。这就是过滤噪音并从正确数据中学习的任务。 Aleksey Vyazmikin#: 我的意思是,我不知道 "错误 "是如何被考虑的--是准确性吗? 这是一种通过测试获得轨迹综合/汇总误差的方法。任何一种误差都可以汇总。还有 (1-accuracy) 和 RMS、AvgRel 和 AvgCE 等。 Aleksey Vyazmikin#: 我没有改变任何东西(也许我在什么地方描述了自己?)--就是这样--在火车上--训练,测试--停止训练的控制,考试--不参与任何训练的部分。 从图片上看,我觉得考试的意思就是测试 比如这里。 在上表中,考试成绩优于测试成绩。这当然有可能,但应该反过来。 Aleksey Vyazmikin 2023.01.15 16:07 #174 elibrarius #:显然不是。这就是如何穿过噪音,从正确的数据中学习的挑战。 不,一定有办法的,否则一切都是无用的/随机的。 elibrarius#: 这是一种通过测试获得轨迹综合/汇总误差的方法。任何一种误差都可以求和。还有 (1-accuracy) 和 RMS 以及 AvgRel 和 AvgCE 等。 明白了,但这对我的数据不起作用 - 至少应该有一些相关性:) elibrarius#: 从图片上看,我觉得考试的意思是测试 例如这里 在上表中,考试成绩比测试成绩好。 是的,事实证明,考试更有可能为建模者赚取更多的钱 - 我自己也不完全了解情况。 不幸的是,现在我注意到,不知什么时候我把总样本(行)弄混了,现在 2022 年的例子都在火车上了:(......。 我将重做一切--我想几周后就会有结果--让我们看看总体情况是否会发生变化。 Aleksei Kuznetsov 2023.01.15 16:17 #175 Aleksey Vyazmikin #: 不幸的是,现在我注意到,不知什么时候我把总样本(行)弄混了,现在火车上包括了 2022 年的例子:( 我会重做的 - 我想几周后就会有结果 - 看看整体情况是否有变化。 是通过考试还是测验进行评估并没有什么区别。最重要的是,培训和初次评估都没有使用评估网站。 两个星期我对你的耐力感到惊讶。我对 3 个小时的计算感到厌烦.....。我在 MO 上总共花了 5 年时间,和你差不多。 总之,我们会在退休后开始赚点钱))))。也许吧 Aleksei Kuznetsov 2023.01.15 16:35 #176 Aleksey Vyazmikin #:不幸的是,我现在注意到,在某些时候我混淆了总体样本(行),现在火车上的例子都是 2022 年的:( 我将所有数据粘合到一个顺序数组中。然后我从中分离出适当的数量。这样就不会混淆了。 Aleksey Vyazmikin 2023.01.15 17:06 #177 elibrarius #:是通过考试还是测验进行评估并无区别。最重要的是,在培训或初次评估中都没有使用评估网站。 我在想,是像马克西姆那样做最终训练--取史前样本作为对照,还是像最好的模型那样,取全部可用样本并限制树木数量,这样做更好? elibrarius#: 2周...我对你的耐力感到惊讶。我觉得 3 个小时的计算也很烦人.....我在 MO 上总共花了 5 年时间,和你差不多。 当然,你总是想更快地得到结果。我尝试加载硬件,这样我的计算就不会干扰其他事情--我经常使用的不是主要工作电脑。与此同时,我还可以用代码实现其他想法--我想出想法的速度比用代码检查它们的时间还要快。 elibrarius#: 简而言之,我们将在退休后开始挣钱 ))))也许吧 我同意--前景很悲观。如果我没有看到我的研究取得进展(尽管进展缓慢),我可能早就完成工作了。 Aleksey Vyazmikin 2023.01.15 17:10 #178 elibrarius #:我把所有东西都粘在一个连续的阵列里。然后,我再从阵列中分离出适当的数量。这样就不会弄混了。 是的,我把样本转换成了二进制文件,在脚本中我不小心打了一个复选框,很明显,这个复选框负责混合样本--所以这不是问题,CatBoost 需要 3 个独立的样本--虽然他们有一个内置的交叉验证,但他们没有在行的范围内进行选择。 Aleksei Kuznetsov 2023.01.15 19:09 #179 Aleksey Vyazmikin #:我还在想,是像 Maxim 那样进行最终训练--抽取史前样本作为对照--更好,还是像最好的模型那样,抽取全部可用样本并限制树的数量更好。对我来说,预训练和测试是平均选择最佳超参数(树的数量等)和预测因子的机会。即使没有测试,您也可以对它们进行训练,然后立即投入交易。如果模式不发生变化,史前采样的想法或许可行。但有可能会发生变化。因此,我宁愿不冒风险,也要在未来的取样中进行测试。 另一个问题是,这个史前取样是在多久之前:六个月前还是 15 年前?六个月前可能可行,但 15 年前的市场与现在不同。但这并不确定。也许有些模式几十年来一直有效。 Aleksey Vyazmikin 2023.01.27 10:51 #180 我将描述使用我在这里 描述的相同算法所获得的结果,但样本未混合,即仍按时间顺序排列。我唯一改变的是,现在 10000 个模型的训练不是在有排除预测因子的整个样本上进行的,而是在一个重新形成的样本上进行的,在这个样本中,有排除预测因子的列被删除了,这加快了训练过程(显然,抽取一个大文件需要很多时间)。由于这些变化,我能够持续执行 6 步预测因子筛选。 图 1:对样本的所有预测因子训练 100 个模型后,样本考试的利润直方图。 图 2:对选定的样本预测因子训练 10k 个模型后考试样本的收益直方图--步骤 1。 图3:在选定样本预测因子上训练 10k 个模型后考试样本的收益直方图--步骤 2。 图 4:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 3。 图 5:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 4。 图 6:根据选定样本预测因子训练 10k 个模型后考试样本的利润直方图--步骤 5。 图 7:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 6。 图 8:模型特征表,被选中的模型将以预测因子(特征)数量递减的方式形成后续样本。让我们考虑一下在第 6 步预测因子选择中得到的具有以下特征的模型。图 9:模型特征。 图 10.模型在样本考试中的可视化分类概率分布 - x 轴 - 模型得出的概率,y 轴 - 所有样本的百分比。 图 11.模型在考试样本中的平衡。现在,让我们比较一下在第 6 步预测因子选择中得到的合理的好模型和极差模型中的预测因子。图 12.模型特征的比较。现在我们可以看到哪些预测因子对财务结果产生了如此糟糕的影响,并破坏了训练? 图 13.两个模型中预测因子的权重。图 13 显示,除了一个预测因子外,几乎所有可用的预测因子都被使用了,但我怀疑这是否是问题的根源。因此,问题并不在于使用情况,而在于建立模型时的使用顺序?我对两张表进行了比较,用一个序号代替指数来表示显著性,结果发现模型中的显著性排序有很大不同。 图 14:两个模型中预测因子的重要性(使用)比较表。为了更好地直观显示,图中的井和柱状图--负偏差表示第二个模型(无利可图)的预测因子使用较晚,而正偏差表示使用较早。 图 15.模型中预测因子的显著性偏差。可以看出偏差很大,也许就是这种情况,但如何发现/证明呢?也许需要一些将模型与基准进行比较的复杂方法--有什么想法吗?是否有某种混杂指数来描述总体偏差,或许可以考虑预测因子对第一个模型的重要 性--即系数递减?可以得出什么结论?我的猜测是这样的:1.过去样本的结果要好得多,我认为这是由于混合样本的时间顺序 "泄露 "了未来事件的信息。问题是,混合样本还是正常样本的模型会更稳定。2.2. 为了在模型中进一步应用预测因子,有必要建立预测因子的重要性结构,也就是说,除了数字之外,还有必要建立逻辑,否则,即使预测因子的数量很少,模型结果的分散性也会太大。 1...111213141516171819202122232425...32 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
随机是固定的)看来这个种子的计算方法很复杂,即 可能涉及到所有 允许用于建立模型的 预测因子,改变它们的数量也会改变选择结果。
起始种子是固定的。然后每次调用 HSC 时都会出现一个新的种子数。这就是为什么在预测因子数量和 DST 数量不同的情况下,预测因子的数量不会与预测因子数量相同。
为什么会出现这种拟合 情况?我倾向于认为测试样本与考试的差异大于考试与训练的差异,即预测因子的概率分布不同。
好吧,你选取了最好的考试变体,希望它们在测试中表现出色。你根据最好的考试选择预测因子。但它们只在考试中是最好的。
什么是 "err_"指标?
err_ oob - OOB(考试)误差,err_trn - 火车误差。根据公式,我们将得到两个样本点的共同误差。
顺便说一下,在讨论中我们把测试和考试对调了一下。起初,我们计划在测试中进行中间检查,在考试中进行最终检查。不过,虽然名称变了,但上下文已经清楚地说明了什么是什么。
起始号码是固定的。然后每次调用 DST 都会出现一个新的数字。因此,在不同的预测数和 DST 次数下,不会出现预测数满时落到同一预测数上的情况。
但是,如果用于训练的预测器数量保持不变,变体就会重现。
好吧,你选取了最好的考试变体,希望它们在考试中表现出色。预测因子是由最好的考试选择出来的。但它们只有在考试中才是最好的。
碰巧的是,这个变量是最平衡的--在测试和考试中都有不错的收益。下图是最初选择的模型--"Was "和经过 10k 训练后的最佳平衡模型--"Became"。总的来说,结果更好,使用的预测因子更少,因此噪音被消除了。这里的问题是如何在训练前避免噪音。
因此,我们的逻辑是,训练在测试中停止,因此在测试中出现积极结果的可能性应该比在完全不参与训练的样本中出现积极结果的可能性大,所以重点放在后者上。
err_ oob - OOB 上的错误(你已经进行了考试),err_trn - trn 上的错误。根据公式,我们将得到两个样本点的一些共同误差。
我的意思是,我不知道 "err "是如何计算的--是精确度吗?还有,为什么是考试而不是测试,因为在基本方法中,考试我们是不知道的。
顺便说一下,我们在讨论中把测试和考试对调了一下。最初的计划是在测试中进行中间测试,在考试中进行最终测试。但根据上下文,我们可以清楚地知道什么是什么,尽管他们更改了名称。
我没有改变任何东西(也许我在什么地方描述过自己?)--它就是这样的--培训--培训,测试--停止培训的控制,考试--不参与任何培训的部分。
我只是通过所有模型的平均值来评估这种方法的有效性,包括平均利润--它比具有良好结果的边缘更有可能获得。
还有一个问题是,在开始训练之前,如何避免这种噪音。 。
显然不能。这就是过滤噪音并从正确数据中学习的任务。
我的意思是,我不知道 "错误 "是如何被考虑的--是准确性吗?
这是一种通过测试获得轨迹综合/汇总误差的方法。任何一种误差都可以汇总。还有 (1-accuracy) 和 RMS、AvgRel 和 AvgCE 等。
我没有改变任何东西(也许我在什么地方描述了自己?)--就是这样--在火车上--训练,测试--停止训练的控制,考试--不参与任何训练的部分。
从图片上看,我觉得考试的意思就是测试
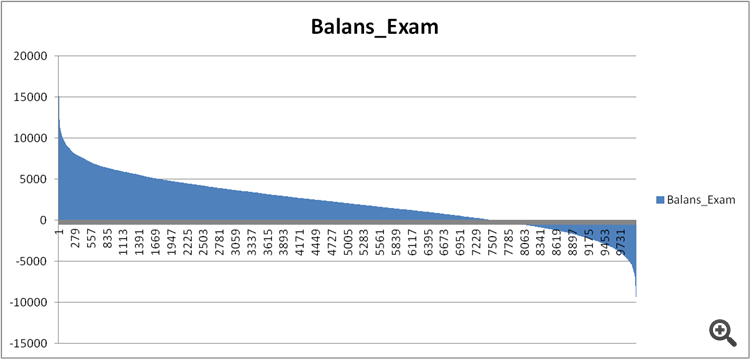
比如这里。
在上表中,考试成绩优于测试成绩。这当然有可能,但应该反过来。
显然不是。这就是如何穿过噪音,从正确的数据中学习的挑战。
不,一定有办法的,否则一切都是无用的/随机的。
这是一种通过测试获得轨迹综合/汇总误差的方法。任何一种误差都可以求和。还有 (1-accuracy) 和 RMS 以及 AvgRel 和 AvgCE 等。
明白了,但这对我的数据不起作用 - 至少应该有一些相关性:)
从图片上看,我觉得考试的意思是测试
例如这里
在上表中,考试成绩比测试成绩好。
是的,事实证明,考试更有可能为建模者赚取更多的钱 - 我自己也不完全了解情况。
不幸的是,现在我注意到,不知什么时候我把总样本(行)弄混了,现在 2022 年的例子都在火车上了:(......。
我将重做一切--我想几周后就会有结果--让我们看看总体情况是否会发生变化。
不幸的是,现在我注意到,不知什么时候我把总样本(行)弄混了,现在火车上包括了 2022 年的例子:(
我会重做的 - 我想几周后就会有结果 - 看看整体情况是否有变化。
是通过考试还是测验进行评估并没有什么区别。最重要的是,培训和初次评估都没有使用评估网站。
两个星期我对你的耐力感到惊讶。我对 3 个小时的计算感到厌烦.....。我在 MO 上总共花了 5 年时间,和你差不多。
总之,我们会在退休后开始赚点钱))))。也许吧
不幸的是,我现在注意到,在某些时候我混淆了总体样本(行),现在火车上的例子都是 2022 年的:(
我将所有数据粘合到一个顺序数组中。然后我从中分离出适当的数量。这样就不会混淆了。
是通过考试还是测验进行评估并无区别。最重要的是,在培训或初次评估中都没有使用评估网站。
我在想,是像马克西姆那样做最终训练--取史前样本作为对照,还是像最好的模型那样,取全部可用样本并限制树木数量,这样做更好?
2周...我对你的耐力感到惊讶。我觉得 3 个小时的计算也很烦人.....我在 MO 上总共花了 5 年时间,和你差不多。
当然,你总是想更快地得到结果。我尝试加载硬件,这样我的计算就不会干扰其他事情--我经常使用的不是主要工作电脑。与此同时,我还可以用代码实现其他想法--我想出想法的速度比用代码检查它们的时间还要快。
简而言之,我们将在退休后开始挣钱 ))))也许吧
我同意--前景很悲观。如果我没有看到我的研究取得进展(尽管进展缓慢),我可能早就完成工作了。
我把所有东西都粘在一个连续的阵列里。然后,我再从阵列中分离出适当的数量。这样就不会弄混了。
是的,我把样本转换成了二进制文件,在脚本中我不小心打了一个复选框,很明显,这个复选框负责混合样本--所以这不是问题,CatBoost 需要 3 个独立的样本--虽然他们有一个内置的交叉验证,但他们没有在行的范围内进行选择。
我还在想,是像 Maxim 那样进行最终训练--抽取史前样本作为对照--更好,还是像最好的模型那样,抽取全部可用样本并限制树的数量更好。
对我来说,预训练和测试是平均选择最佳超参数(树的数量等)和预测因子的机会。即使没有测试,您也可以对它们进行训练,然后立即投入交易。
如果模式不发生变化,史前采样的想法或许可行。但有可能会发生变化。因此,我宁愿不冒风险,也要在未来的取样中进行测试。
另一个问题是,这个史前取样是在多久之前:六个月前还是 15 年前?六个月前可能可行,但 15 年前的市场与现在不同。但这并不确定。也许有些模式几十年来一直有效。我将描述使用我在这里 描述的相同算法所获得的结果,但样本未混合,即仍按时间顺序排列。
我唯一改变的是,现在 10000 个模型的训练不是在有排除预测因子的整个样本上进行的,而是在一个重新形成的样本上进行的,在这个样本中,有排除预测因子的列被删除了,这加快了训练过程(显然,抽取一个大文件需要很多时间)。由于这些变化,我能够持续执行 6 步预测因子筛选。
图 1:对样本的所有预测因子训练 100 个模型后,样本考试的利润直方图。
图 2:对选定的样本预测因子训练 10k 个模型后考试样本的收益直方图--步骤 1。
图3:在选定样本预测因子上训练 10k 个模型后考试样本的收益直方图--步骤 2。
图 4:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 3。
图 5:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 4。
图 6:根据选定样本预测因子训练 10k 个模型后考试样本的利润直方图--步骤 5。
图 7:在选定样本预测因子上训练 10k 个模型后考试样本的利润直方图--步骤 6。
图 8:模型特征表,被选中的模型将以预测因子(特征)数量递减的方式形成后续样本。
让我们考虑一下在第 6 步预测因子选择中得到的具有以下特征的模型。
图 9:模型特征。
图 10.模型在样本考试中的可视化分类概率分布 - x 轴 - 模型得出的概率,y 轴 - 所有样本的百分比。
图 11.模型在考试样本中的平衡。
现在,让我们比较一下在第 6 步预测因子选择中得到的合理的好模型和极差模型中的预测因子。
图 12.模型特征的比较。
现在我们可以看到哪些预测因子对财务结果产生了如此糟糕的影响,并破坏了训练?
图 13.两个模型中预测因子的权重。
图 13 显示,除了一个预测因子外,几乎所有可用的预测因子都被使用了,但我怀疑这是否是问题的根源。因此,问题并不在于使用情况,而在于建立模型时的使用顺序?
我对两张表进行了比较,用一个序号代替指数来表示显著性,结果发现模型中的显著性排序有很大不同。
图 14:两个模型中预测因子的重要性(使用)比较表。
为了更好地直观显示,图中的井和柱状图--负偏差表示第二个模型(无利可图)的预测因子使用较晚,而正偏差表示使用较早。
图 15.模型中预测因子的显著性偏差。
可以看出偏差很大,也许就是这种情况,但如何发现/证明呢?也许需要一些将模型与基准进行比较的复杂方法--有什么想法吗?
是否有某种混杂指数来描述总体偏差,或许可以考虑预测因子对第一个模型的重要 性--即系数递减?
可以得出什么结论?
我的猜测是这样的:
1.过去样本的结果要好得多,我认为这是由于混合样本的时间顺序 "泄露 "了未来事件的信息。问题是,混合样本还是正常样本的模型会更稳定。
2.2. 为了在模型中进一步应用预测因子,有必要建立预测因子的重要性结构,也就是说,除了数字之外,还有必要建立逻辑,否则,即使预测因子的数量很少,模型结果的分散性也会太大。