混乱中有规律可循吗?让我们试着找出它!以特定样本为例进行机器学习。 - 页 25 1...181920212223242526272829303132 新评论 Aleksey Vyazmikin 2023.02.27 09:30 #241 Forester #:TP=SL 时,约为 50%。当 TP=2*SL 时,则为 33%,等等。 一笔交易的平均利润总是很小。大约 0,00005。 而使用 TP=SL=0,00400 时,风险为 400,利润为 5 点,即优势为 1%。 我希望从 50 点的波动中至少获利 10 点,但所有选项都是梅花。 但这都是我的筹码和目标。也许还有更好的选择。从 2008 年到 2023 年,该 策略在欧元兑美元上的盈利交易占 43%,TP/SL 比率为 61.8,39% 的盈利交易足以实现盈亏平衡。我还没有核对过这些数字,可能哪里出错了,当然这些都是理想条件。不过,这里有一个学习的角度,这意味着你可以以牺牲 MO 为代价,拉出更高的百分比。关于预测因子,你是否从我的文章中摘录了我的预测因子? 它们 通常出现在我的模型中,还有其他模型。 补充:是的,我没有考虑到有盈利的交易,但没有按 TP 结清,当然利润就会减少。 Aleksei Kuznetsov 2023.02.27 09:40 #242 Aleksey Vyazmikin #:从 2008 年到 2023 年,该 策略在欧元兑美元交易中的盈利率为 43%,理想情况下的 TP/SL 比率为 61.8,39% 的盈利交易足以实现盈亏平衡。我还没有核对过这些数字,可能哪里出错了,当然这些都是理想情况。不过,这里有一个学习的角度,这意味着你可以以牺牲 MO 为代价,获得更高的百分比。关于预测因子,您是否从我的文章中摘录了我的预测因子? 它们 通常出现在我的模型以及其他模型中。 我不太清楚您的策略是什么。看起来你每天都会收到一次进场信号。 我在你的数据集上训练了你的 5000 多个预测因子。他们的预测结果不超过 5 个百分点,所以我认为他们并不比我的简单价格三角和之字形预测结果好,后者也是 5 个百分点。,我现在将检查其他想法。如果它们没有任何效果,我将尝试使用您的预测器来生成我自己的模型。 Aleksey Vyazmikin 2023.02.27 10:36 #243 Forester #:我不太明白你的策略是什么。它看起来像是每天输入一次的信号。 策略如下: 当日开盘时,我们计算价格变动的预期极限范围,为此我们可以使用上一日末的 ATR(3),我使用的公式略有不同。我们将这一范围推迟到当日(条)开盘之初--我们将其视为 100%。 当达到高于/低于开盘价的重要水平时(我止损于 23.6,因为根据我的观察,在不同的交易工具上经常出现这种情况),我们在下一个重要水平(我使用 61.8)建仓并设置 TP,在当天的开盘价上设置 SL。 如果我们在止盈价位平仓,则在出现信号时再次入场。 如果止盈不成功,最好在当日收盘时(23:45)平仓,但事实上我在等待 TP/SL。 现在,初始标记是这样工作的--如果我们获利平仓,就加 1,如果我们亏损平仓,就加 -1。 在拆分样本时,我将目标偏移了 300 点,因此如果利润小于 300 点,则为零。 if(N_Siganal==10)//сейчас работает на открытие позиции при пересечении +23,6/-23,6 iDelta D1 { if(CountMarketOrder_OS==0 && CountMarketOrder_OB==0) { double Open=iOpen(Symbol(),PERIOD_CURRENT,0); double Open_S1=iOpen(Symbol(),PERIOD_CURRENT,1); double iDelta=iDeltaf(Symbol(),PERIOD_D1,3,1,0); double Open_Day=iOpen(Symbol(),PERIOD_D1,0); double iD_Day_Up=0.0; double iD_Day_Dn=0.0; bool Signal_Buy=false; bool Signal_Sell=false; iD_Day_Up=Open_Day+iDelta; iD_Day_Dn=Open_Day-iDelta; if(Open_S1<=iD_Day_Up && Open>iD_Day_Up)Signal_Buy=true; if(Open_S1>=iD_Day_Dn && Open<iD_Day_Dn)Signal_Sell=true; if(Signal_Buy==true || Signal_Sell==true)break; if(Signal_Buy==true || Signal_Sell==true) { Print("Основной сигнал:"," T_Zero=",TimeToString(T_Zero,TIME_DATE|TIME_MINUTES)," T_Signal=",TimeToString(T_Signal,TIME_DATE|TIME_MINUTES)); if(T_Zero<T_Signal) { Signal_Buy=false; Signal_Sell=false; Print("Блокировка T_Zero<T_Signal - открыта виртуальная позиция"); } else { if(Signal_Sell==true)SellNow=true; if(Signal_Buy==true)BuyNow=true; } } } } Forester#: 我认为这还谈不上结果的统计意义。 我使用的是 2008 年的数据。是的,数据不多,但这取决于你如何看待它,因为如果你认为 23.6 的水平不是随机的,而且它的交叉对市场意义重大,那么它就会像类似事件一样,可以相互比较,而不像在每个条形图上生成条目时的情况--有很多类似事件,这只会使学习复杂化。 因此,我认为以这种方式进行训练是有意义的,但在不同的策略中,影响市场参与者决策的事件应该是不同的。而且,还要进一步交易成套模型。 Forester#: 我在您的数据集上训练了您的 5000 多个预测因子。它们的预测结果不超过 5 个点,所以我认为它们并不比我的简单价格三角和之字形预测更好,后者的预测结果也是 5 个点。,我将暂时检查其他想法。如果它们没有任何效果,我将尝试使用您的预测器来生成我自己的模型。 您说的是第一个样本还是第二个样本?如果是第一个样本,那么我有一个约 30 个点的期望矩阵来获得好的变体。 我可以尝试在 CatBoost 上训练您的样本,当然,如果您上传的话。 Aleksei Kuznetsov 2023.02.27 11:32 #244 Aleksey Vyazmikin #:策略是这样的当日开盘时,我们计算价格变动的预期极限范围,为此,我们可以使用上一日末的 ATR(3),我使用的公式略有不同。我们将这一范围推迟到当日(条形图)开盘之初--我们将其视为 100%。当我们到达高于/低于开盘价的重要水平时(我止损于 23.6,因为根据我的观察,在不同的交易工具上经常出现这种情况),我们在下一个重要水平(我使用 61.8)上以 TP 建仓,并在当天的开盘价上设置 SL。如果我们在止盈价位平仓,则在出现信号时再次入场。如果止盈不起作用,最好在当天结束时(23:45)平仓,但事实上我现在正在等待 TP/SL。现在的初始加价是这样的--如果获利平仓,我们加 1,如果亏损平仓,我们加 -1。在拆分样本时,我将目标偏移了 300 点,因此如果盈利小于 300 点,则为 0。我采集了 2008 年的数据。是的,数据不多,但这取决于你如何看待它,因为如果我们认为 23.6 的水平不是偶然的,而且它的交叉对市场意义重大,那么这些都是可以相互比较的类似事件。 现在目标大致明确了。 你有以点为单位的估计结果吗,还是只有赢/输?看起来是后者。最好以点为单位进行估算。 这样,给出 75% 的模型实际上就不会是 50/50。 Aleksey Vyazmikin#: 与每一栏都产生输入的情况不同--有很多这样的事件,这只会使学习复杂化。 我想添加 "减薄 "功能--类似的条形图,如果价格没有上涨 100...1000 点,则跳过。 Aleksey Vyazmikin#: 您说的是第一个样本还是第二个样本?如果您说的是第一个样本,那么我有一个约 30 点的期望矩阵,用于好的变体。 第二个样本在 H1 上,第一个样本并不是更好(但我研究得少,例如我没有选择特征)。 Aleksey Vyazmikin#: 我可以尝试在 CatBoost 上训练您的样本,当然,如果您上传的话。 我有几百个样本。我不喜欢将其中任何一个投入交易。我改变了 TP 或 SL 或其他东西,这就是新的变体。所以没有意义。 Aleksey Vyazmikin 2023.02.27 16:32 #245 Forester #:现在目标大致明确了。 你有以积分计算的估计结果吗,还是只有输赢?看起来是后者。最好以点数来估算。 这样,75% 的模型就不能真正实现 50/50。 我的估价单位是钱:)加上目标,就像以前一样。如果您想要更多的点数,目标可以稍后移动。 在具体策略中,现在一切都是止盈。我做了一个计算的地段,事实上,它原来的传播恶化的比例显着,但没关系,但它将是稳定的,没有排放的超级有利可图的条目 - 风险几乎是相同的无处不在。如果您使用暂停,就有可能改善结果。 Forester#: 我想补充一点--类似的条形图,如果价格没有达到 100...1000 点,就跳过。 然后对每个条形图进行评估,以及应用模型? Forester#: H1 上的第二个。 嗯,第一个也好不到哪里去,(但我研究得少,例如我没有选择筹码)。我有几百个。没有一个是我喜欢投入交易的。我换了 TP 或 SL 或其他东西--这就是新的变体。所以没有意义。 我的观点是,如果有相同的算法来创建样本,就有可能比较预测因子。 Aleksei Kuznetsov 2023.02.27 17:59 #246 Aleksey Vyazmikin #:然后对每个条形图进行估算,以及应用什么模型? 是的,如果至少已过了 XX 个点,就像训练中那样。但会有失真--如果向上,只有从 100 到 120(200-220 等)的第一栏,999-979(899-979)会更频繁地工作。 Aleksey Vyazmikin#: 我的观点是,如果有相同的算法来创建样本,就有可能比较预测结果。 我并不真的想要 5000 个以上的样本,这需要很长的时间来计算。但作为寻找重要预测因子的一种方法,可能有必要对它们进行检查。 RomFil 2023.03.25 14:05 #247 下午好! 我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量(即第 5584 列)尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。对于所有三个文件,我得到了这些图表: 1) train: 2)测试 3)考试: 我不知道我做得对不对,但如果 topikstarter 在不使用预测器的情况下制作了新样本,我将在新数据上测试该方法,并告诉大家该方法。 那么,在训练完神经网络委员会(总共有 10 个)后,每个样本的实际利润是多少呢?利润以点数表示,点差=0,佣金=0: 1) 训练 2) 测试 3)考试: 我认为 60000+ 点的结果是可以接受的。 我建议 topikstarter 只制作最 "混乱 "信号的新样本。 该方法将应用于新的信号,结果将显示出来,并在一定程度上描述该方法。 致敬,RomFil! 附注:未来不可知,但总能找到控制未来的方法......:) Aleksey Vyazmikin 2023.03.25 14:43 #248 RomFil #:下午好!我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量,即第 5584 列尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。所有三个文件的图表如下: 我不明白你做了什么,如果你的方法适用于纯粹的价格,为什么还需要新的样本。 下面列表中的列是事件发生的结果,即它们不应该参与训练。至多 5582 - 但我认为这很容易预测,所以模型会恢复原状。 5581 辅助 5582 辅助 5583 标签 5584 辅助 5585 辅助 RomFil 2023.03.25 15:32 #249 Aleksey Vyazmikin #:我不明白你做了什么,如果你的方法适用于纯粹的价格,为什么还需要一个新的样本。下面列表中的列是已发生事件的结果,即它们不应参与训练。最多为 5582 - 但我认为这很容易预测,所以模型会恢复它。 5581 辅助 5582 辅助 5583 标签 5584 辅助 5585 辅助设备 "我做了什么? 样本列车的大小约为 1GB。将其加载到工作区需要很长时间。我的电脑是 i5-3570,拥有 24GB 内存和高速固态硬盘,Excel 打开这个文件需要几分钟时间。这就是我决定缩短文件的原因。我懒得去计算 5000 多列的上标。因此,这一列根据上述公式形成了一个图表。也就是说,第一步是 0,然后是 0.00007,然后是 0.00007-0.00002=0.00005,然后是 0.00005+0.00007=0.00012,等等。也就是说,从第5584 5586 列开始,我形成了一个没有绑定的运动图表,可以说是一个相对运动图表。就像收盘图一样,即在图表的每一步结束时,资产的价格都会发生相应的变化。 附:关于列数的问题......我选的是最近的 5586(我刚在 Excel 中查到),带有卖出信号。 "...为什么是新样本": 为了在一定程度上展示和说明其示例方法。如果您能说出您可以采用 OHLC 或只采用 Clause 价格的列数,那就足够了。 关于其他部分: 完全不使用样本文件中的数据。以每个文件中的5584 5586 列为基础,如上所述绘制图表。这种方法已经应用于这些得到的图形。 好吧,既然 topikstarter 不想提供新的样本,我建议有兴趣的人发布自己的样本......:) 致敬,RomFil! Aleksei Kuznetsov 2023.03.25 15:38 #250 RomFil #:下午好!我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量(即第 5584 列)尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。所有三个文件的图表如下: 目标函数的重复性是否经过训练?例如,如果成功了 20 次,还能成功 21 次吗? 以下是最简单的买入和卖出目标,TP/SL=50 点 M5,为期约 5 年。 加价是在每个 M5 柱上进行的,也就是说,很可能上一个信号(5 分钟前)的交易尚未完成。我不确定堆叠它们是否正确。对于在同一时刻只有 1 笔交易的目标,堆叠是可以的,但即使 100 笔交易同时进行,也不一定能在一夜之间完成。 附注 - 我让它们无法训练。它们在我的预测器上总是失败。 附加的文件: buy.csv 3516 kb sell.csv 3516 kb 1...181920212223242526272829303132 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
TP=SL 时,约为 50%。当 TP=2*SL 时,则为 33%,等等。
一笔交易的平均利润总是很小。大约 0,00005。
而使用 TP=SL=0,00400 时,风险为 400,利润为 5 点,即优势为 1%。
我希望从 50 点的波动中至少获利 10 点,但所有选项都是梅花。
但这都是我的筹码和目标。也许还有更好的选择。
从 2008 年到 2023 年,该 策略在欧元兑美元上的盈利交易占 43%,TP/SL 比率为 61.8,39% 的盈利交易足以实现盈亏平衡。我还没有核对过这些数字,可能哪里出错了,当然这些都是理想条件。不过,这里有一个学习的角度,这意味着你可以以牺牲 MO 为代价,拉出更高的百分比。
关于预测因子,你是否从我的文章中摘录了我的预测因子? 它们 通常出现在我的模型中,还有其他模型。
补充:是的,我没有考虑到有盈利的交易,但没有按 TP 结清,当然利润就会减少。从 2008 年到 2023 年,该 策略在欧元兑美元交易中的盈利率为 43%,理想情况下的 TP/SL 比率为 61.8,39% 的盈利交易足以实现盈亏平衡。我还没有核对过这些数字,可能哪里出错了,当然这些都是理想情况。不过,这里有一个学习的角度,这意味着你可以以牺牲 MO 为代价,获得更高的百分比。
关于预测因子,您是否从我的文章中摘录了我的预测因子? 它们 通常出现在我的模型以及其他模型中。
我不太清楚您的策略是什么。看起来你每天都会收到一次进场信号。
我在你的数据集上训练了你的 5000 多个预测因子。他们的预测结果不超过 5 个百分点,所以我认为他们并不比我的简单价格三角和之字形预测结果好,后者也是 5 个百分点。
,我现在将检查其他想法。如果它们没有任何效果,我将尝试使用您的预测器来生成我自己的模型。
我不太明白你的策略是什么。它看起来像是每天输入一次的信号。
策略如下:
当日开盘时,我们计算价格变动的预期极限范围,为此我们可以使用上一日末的 ATR(3),我使用的公式略有不同。我们将这一范围推迟到当日(条)开盘之初--我们将其视为 100%。
当达到高于/低于开盘价的重要水平时(我止损于 23.6,因为根据我的观察,在不同的交易工具上经常出现这种情况),我们在下一个重要水平(我使用 61.8)建仓并设置 TP,在当天的开盘价上设置 SL。
如果我们在止盈价位平仓,则在出现信号时再次入场。
如果止盈不成功,最好在当日收盘时(23:45)平仓,但事实上我在等待 TP/SL。
现在,初始标记是这样工作的--如果我们获利平仓,就加 1,如果我们亏损平仓,就加 -1。
在拆分样本时,我将目标偏移了 300 点,因此如果利润小于 300 点,则为零。
我认为这还谈不上结果的统计意义。
我使用的是 2008 年的数据。是的,数据不多,但这取决于你如何看待它,因为如果你认为 23.6 的水平不是随机的,而且它的交叉对市场意义重大,那么它就会像类似事件一样,可以相互比较,而不像在每个条形图上生成条目时的情况--有很多类似事件,这只会使学习复杂化。
因此,我认为以这种方式进行训练是有意义的,但在不同的策略中,影响市场参与者决策的事件应该是不同的。而且,还要进一步交易成套模型。
我在您的数据集上训练了您的 5000 多个预测因子。它们的预测结果不超过 5 个点,所以我认为它们并不比我的简单价格三角和之字形预测更好,后者的预测结果也是 5 个点。
,我将暂时检查其他想法。如果它们没有任何效果,我将尝试使用您的预测器来生成我自己的模型。
您说的是第一个样本还是第二个样本?如果是第一个样本,那么我有一个约 30 个点的期望矩阵来获得好的变体。
我可以尝试在 CatBoost 上训练您的样本,当然,如果您上传的话。
策略是这样的
当日开盘时,我们计算价格变动的预期极限范围,为此,我们可以使用上一日末的 ATR(3),我使用的公式略有不同。我们将这一范围推迟到当日(条形图)开盘之初--我们将其视为 100%。
当我们到达高于/低于开盘价的重要水平时(我止损于 23.6,因为根据我的观察,在不同的交易工具上经常出现这种情况),我们在下一个重要水平(我使用 61.8)上以 TP 建仓,并在当天的开盘价上设置 SL。
如果我们在止盈价位平仓,则在出现信号时再次入场。
如果止盈不起作用,最好在当天结束时(23:45)平仓,但事实上我现在正在等待 TP/SL。
现在的初始加价是这样的--如果获利平仓,我们加 1,如果亏损平仓,我们加 -1。
在拆分样本时,我将目标偏移了 300 点,因此如果盈利小于 300 点,则为 0。
我采集了 2008 年的数据。是的,数据不多,但这取决于你如何看待它,因为如果我们认为 23.6 的水平不是偶然的,而且它的交叉对市场意义重大,那么这些都是可以相互比较的类似事件。
现在目标大致明确了。
你有以点为单位的估计结果吗,还是只有赢/输?看起来是后者。最好以点为单位进行估算。
这样,给出 75% 的模型实际上就不会是 50/50。
与每一栏都产生输入的情况不同--有很多这样的事件,这只会使学习复杂化。
我想添加 "减薄 "功能--类似的条形图,如果价格没有上涨 100...1000 点,则跳过。
您说的是第一个样本还是第二个样本?如果您说的是第一个样本,那么我有一个约 30 点的期望矩阵,用于好的变体。
第二个样本在 H1 上,第一个样本并不是更好(但我研究得少,例如我没有选择特征)。
我可以尝试在 CatBoost 上训练您的样本,当然,如果您上传的话。
我有几百个样本。我不喜欢将其中任何一个投入交易。我改变了 TP 或 SL 或其他东西,这就是新的变体。所以没有意义。
现在目标大致明确了。
你有以积分计算的估计结果吗,还是只有输赢?看起来是后者。最好以点数来估算。
这样,75% 的模型就不能真正实现 50/50。
我的估价单位是钱:)加上目标,就像以前一样。如果您想要更多的点数,目标可以稍后移动。
在具体策略中,现在一切都是止盈。我做了一个计算的地段,事实上,它原来的传播恶化的比例显着,但没关系,但它将是稳定的,没有排放的超级有利可图的条目 - 风险几乎是相同的无处不在。如果您使用暂停,就有可能改善结果。
我想补充一点--类似的条形图,如果价格没有达到 100...1000 点,就跳过。
然后对每个条形图进行评估,以及应用模型?
H1 上的第二个。 嗯,第一个也好不到哪里去,(但我研究得少,例如我没有选择筹码)。
我有几百个。没有一个是我喜欢投入交易的。我换了 TP 或 SL 或其他东西--这就是新的变体。所以没有意义。
我的观点是,如果有相同的算法来创建样本,就有可能比较预测因子。
然后对每个条形图进行估算,以及应用什么模型?
是的,如果至少已过了 XX 个点,就像训练中那样。但会有失真--如果向上,只有从 100 到 120(200-220 等)的第一栏,999-979(899-979)会更频繁地工作。
我的观点是,如果有相同的算法来创建样本,就有可能比较预测结果。
我并不真的想要 5000 个以上的样本,这需要很长的时间来计算。但作为寻找重要预测因子的一种方法,可能有必要对它们进行检查。
下午好!
我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量(即第 5584 列)尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。对于所有三个文件,我得到了这些图表:
1) train: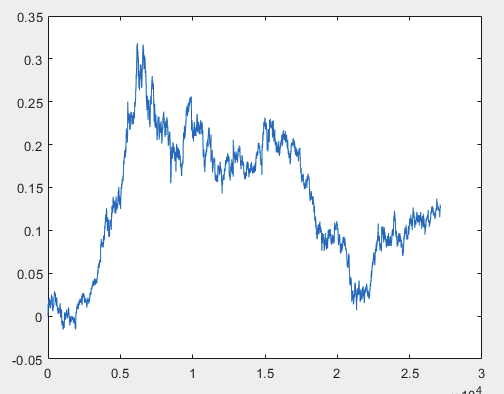
2)测试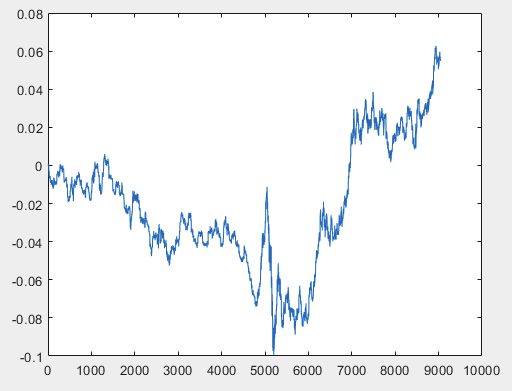
3)考试: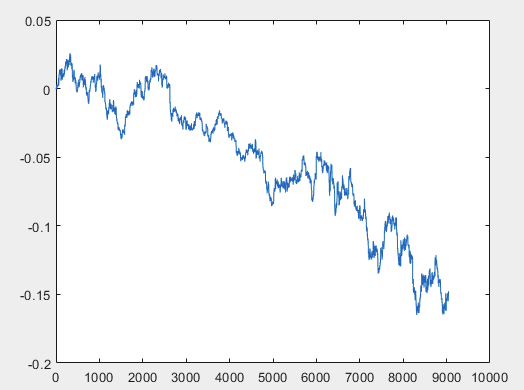
我不知道我做得对不对,但如果 topikstarter 在不使用预测器的情况下制作了新样本,我将在新数据上测试该方法,并告诉大家该方法。
那么,在训练完神经网络委员会(总共有 10 个)后,每个样本的实际利润是多少呢?利润以点数表示,点差=0,佣金=0:
1) 训练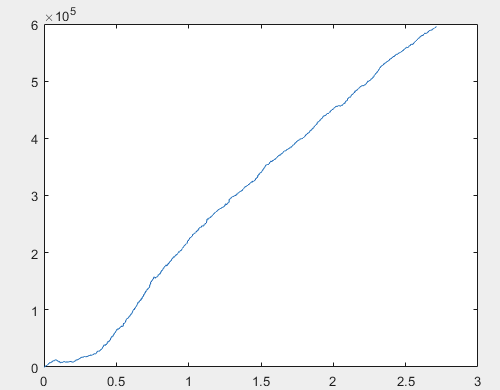
2) 测试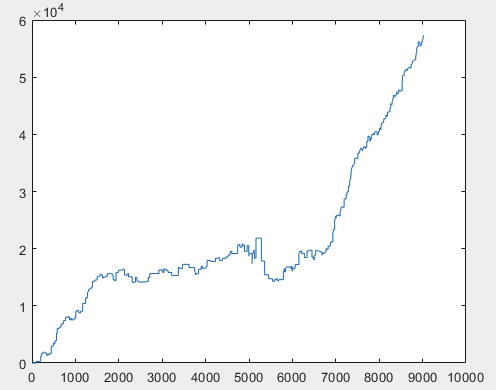
3)考试: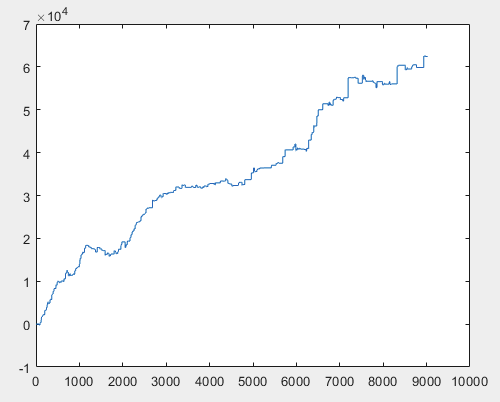
我认为 60000+ 点的结果是可以接受的。
我建议 topikstarter 只制作最 "混乱 "信号的新样本。
该方法将应用于新的信号,结果将显示出来,并在一定程度上描述该方法。
致敬,RomFil!
附注:未来不可知,但总能找到控制未来的方法......:)
下午好!
我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量,即第 5584 列尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。所有三个文件的图表如下:
我不明白你做了什么,如果你的方法适用于纯粹的价格,为什么还需要新的样本。
下面列表中的列是事件发生的结果,即它们不应该参与训练。至多 5582 - 但我认为这很容易预测,所以模型会恢复原状。
5581 辅助
5582 辅助
5583 标签
5584 辅助
5585 辅助
我不明白你做了什么,如果你的方法适用于纯粹的价格,为什么还需要一个新的样本。
下面列表中的列是已发生事件的结果,即它们不应参与训练。最多为 5582 - 但我认为这很容易预测,所以模型会恢复它。
5581 辅助
5582 辅助
5583 标签
5584 辅助
5585 辅助设备
"我做了什么?
样本列车的大小约为 1GB。将其加载到工作区需要很长时间。我的电脑是 i5-3570,拥有 24GB 内存和高速固态硬盘,Excel 打开这个文件需要几分钟时间。这就是我决定缩短文件的原因。我懒得去计算 5000 多列的上标。因此,这一列根据上述公式形成了一个图表。也就是说,第一步是 0,然后是 0.00007,然后是 0.00007-0.00002=0.00005,然后是 0.00005+0.00007=0.00012,等等。也就是说,从第5584 5586 列开始,我形成了一个没有绑定的运动图表,可以说是一个相对运动图表。就像收盘图一样,即在图表的每一步结束时,资产的价格都会发生相应的变化。
附:关于列数的问题......我选的是最近的 5586(我刚在 Excel 中查到),带有卖出信号。
"...为什么是新样本":
为了在一定程度上展示和说明其示例方法。如果您能说出您可以采用 OHLC 或只采用 Clause 价格的列数,那就足够了。
关于其他部分:
完全不使用样本文件中的数据。以每个文件中的5584 5586 列为基础,如上所述绘制图表。这种方法已经应用于这些得到的图形。
好吧,既然 topikstarter 不想提供新的样本,我建议有兴趣的人发布自己的样本......:)
致敬,RomFil!
下午好!
我有一种方法可以解决这个问题,但样本文件最好不带预测器。也就是说,不需要 5000 多个预测器,只需要运动图本身。至于是由 OHLC 组成还是只有一个变量并不重要。不过,我对样本中的一个变量(即第 5584 列)尝试了现有方法,并使用公式 D(i)=D(i-1)+ Target_100_Buy 将其转换为图表。所有三个文件的图表如下:
目标函数的重复性是否经过训练?例如,如果成功了 20 次,还能成功 21 次吗?
以下是最简单的买入和卖出目标,TP/SL=50 点
M5,为期约 5 年。
加价是在每个 M5 柱上进行的,也就是说,很可能上一个信号(5 分钟前)的交易尚未完成。我不确定堆叠它们是否正确。对于在同一时刻只有 1 笔交易的目标,堆叠是可以的,但即使 100 笔交易同时进行,也不一定能在一夜之间完成。
附注 - 我让它们无法训练。它们在我的预测器上总是失败。