Так уж сложилось, что сейчас мало кто из разработчиков помнит, как написать простую DLL библиотеку и в чем особенности связывания разнородных систем. Я постараюсь за 10 минут на примерах продемонстрировать весь процесс создания простых DLL библиотек и раскрою некоторые технические детали нашей реализации связывания. Покажу пошаговый процесс создания DLL библиотеки в Visual Studio с примерами передачи разных типов переменных (числа, массивы, строки и т.д.) и защиту клиентского терминала от падений в пользовательских DLL.
这就是问题所在,它比 5000+ 功能好 2 倍。
事实证明,所有其他 5000+ 芯片只会使结果更糟。
比较一下您的模型在这两种情况下显示的结果会很有趣。
我的 Mat.期望值略高于 1,利润在 5000 以内,准确率为 51% - 即结果明显更差。
是的,在测试样本中,我的 100 个模型都出现了亏损。我有垫子。期望值多一点,利润在 5000 以内,准确率为 51%--也就是说,结果明显更差。
是的,在测试样本中,所有 100 个模型都出现了亏损。但在第一个样本上,它也有损失。
第二个 H1 样本?我在那个样本上有进步。在第一个样本上,我也输了。
是的,我说的是 H1 样本。我最初在 train.csv 上进行训练,在 test.csv 上停止训练,在 exam.csv 上进行独立检查,因此有两列的变体在 test.csv 上失败了。昨天的变体也在脱落,但也有赚了一点钱的变体。
那么,你有什么样的奇迹图表呢?这就是在 10000 条生产线上对 20000 条生产线进行培训后的估价结果。也就是说,图表显示的不是 2 年,而是 5 年。其中 2 年将不得不处于缩水状态,然后又有一年没有盈利,平均盈利再次降至每笔交易 0.00002。
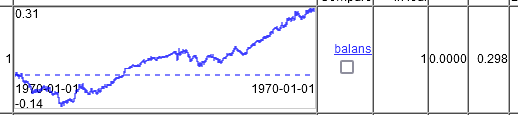
仅在 2 个时间列上显示。
在所有 5000 多个列上显示相同的设置。稍好一些。每笔交易 0.00003。
利润 0.20600,平均每笔交易 0.00004。与点差相称
是的,这个数字已经很可观了。但是,目标是标记为卖出,而且整个期间在一个大的 TF 上都是卖出,我认为这也人为地提高了结果。
所有列上都大于 0.00002,但正如我之前所说 "点差、滑点等会吞噬所有收益"。Teriminal 显示的是每栏(即整小时)的最小点差,但在交易时可能是 5 - 10 个点,而在新闻时可能是 20 个点甚至更高。
因此,我的标价是按分钟计算的,点差通常会在一段时间内扩大,也就是说,在一分钟内,点差可能会一直很大,或者现在不是这样?我甚至还没弄明白 5 中的点差是如何工作的 - 我觉得在 4 中进行测试更方便。
您应该寻找平均每笔交易赢利至少为 0.00020 的模型。那么在实际交易中,您可能会得到 0.00010。这是欧元兑美元的情况,其他货币对如澳元兑纽元,即使 50 点也不够,点差在 20-30 点。
我同意。本主题中的第一个样本给出了 30 点的预期垫值。这就是为什么我仍然坚持认为加价应该是明智的。
这又是考试样本中最好的图表。如何通过托盘选择设置,从而在考试中获得最佳平衡,这是一个无解的问题。您可以通过测试来选择。我在训练+测试。基本上,你有什么考试,我有一个测试。
我认为你应该先让大多数样本通过选择门槛。此外,选择训练最少的模型可能更有意义--它的拟合度更低。
这就是在 10000 行中对 20000 行进行训练的结果。也就是说,图表上的时间不是 2 年,而是 5 年。其中 2 年将不得不处于缩水状态,然后又有一年没有盈利,由于这个原因,每笔交易的平均赢利再次降至 0.00002。
仅在 2 个时间列上使用。
在所有 5000 多个列上使用相同设置。稍好一些。每笔交易 0.00003。
不过,事实证明其他预测因子也很有用。你可以尝试将它们分组添加,也可以先筛选相关性,然后稍微减少它们。
关于期望矩阵,也许在这个策略中,不是在蜡烛开盘时进场,而是在距离开盘价同样 30 点时进场更有利可图--没有尾部的蜡烛是很少见的。
因此,我所做的标记是以分钟为单位的,价差通常会在一段时间内扩大,也就是说,在一分钟内可能会一直有很大的价差,还是现在不是这样?我甚至还没弄明白 5 版中的点差是如何工作的 - 对我来说,在 4 版中进行测试更方便。
在 M1 中,也保留了条形图时间的最小点差。在 ECH 账户中,几乎所有 M1 条形图都是 0.00001...0.00002,很少超过 0.00001。所有高级条形图都是从 M1 开始的,即最小点差相同。每一轮要加 4 点佣金(其他经纪中心可能有其他佣金)。
然而,事实证明其他预测器也是有用的。您可以尝试将它们分组添加,也可以先筛选相关性,然后略微减少它们。
也许我们应该选择它们。但是,如果将 5000+ 添加到 2 只增加了一点点改进,那么通过模型训练完全蛮干选出 10 个可能会更快。我认为这比等待相关性 24 小时要快。只是有必要直接从终端自动循环重新训练。
katbusta 没有 DLL 版本吗?DLL 可以直接从终端调用。https://www.mql5.com/ru/articles/18 和https://www.mql5.com/ru/articles/5798。
也许我们应该选择。但是,如果将 5000 多件添加到 2 件中只能带来微小的改善,那么通过模型训练完全蛮力选择 10 件可能会更快。我认为这比等待相关性 24 小时要快。
是的,一开始最好分组进行--比如说,你可以做 10 个组,用它们的组合进行训练,评估模型,剔除最不成功的组,重新分组剩下的组,即减少组内预测因子的数量,然后再次训练。我以前用过这种方法--效果是有的,但同样不快。
只有你需要直接从终端自动循环重新训练。
catbust 没有 DLL 版本吗?DLL 可以直接从终端调用。https://www.mql5.com/ru/articles/18 和https://www.mql5.com/ru/articles/5798 。
如果能通过终端实现完全的学习控制就好了,但据我了解,目前还没有现成的解决方案。有一个只应用模型的catboostmodel.dll 库,但我不知道如何在 MQL5 中实现它。当然,从理论上讲,有可能以库的形式为训练提供一个接口--代码是开放的,但我负担不起。
是的,一开始最好分组--你可以建立比如说 10 个组,对它们进行组合训练,评估模型,剔除最不成功的组,然后对剩下的组进行重新分组,即减少组内预测因子的数量,并再次对它们进行训练。我以前用过这种方法--效果是有的,但同样不快。
我提出了另一种方法。我们将特征逐一添加到模型中,然后选择最好的特征。
1) 在一个特征上训练 5000+ 个模型:5000+ 个特征中的每个特征。
2) 在 2 个特征上训练 (5000+ -1) 个模型:第一个最佳特征和 ( 5000+ -1) 其余特征。找出第二个最佳特征。
3) 在 3 个特征上训练 (5000+ -2) 个模型:第 1 个、第 2 个最佳特征和 ( 5000+ -2) 其余特征。找出第三个最佳特征。
我通常在添加了 6-10 个特征后就不再改进模型了。您也可以添加到 10-20 个或更多特征。
但我认为,通过测试选择特征是将模型拟合到数据的测试部分。有一种变体是通过权重为 0.3 的 trayne 和权重为 0.7 的 test 进行选择。但我认为这也是一种拟合。
我想做向前滚动,那么拟合将针对许多测试部分,计算时间会更长,但在我看来这是最好的选择。
虽然您没有自动运行 catbusters....5 万多次,但要手动重新训练模型以获得 10 个特征是很难的。这大概就是为什么我更喜欢我的工艺而不是 catbust。尽管它的运行速度比 Cutbust 慢 5-10 倍。你有一个模型 3 分钟,而我有 22 分钟。
我不是这个意思。我们要逐一向模型中添加特征。
1) 在一个特征上训练 5000+ 个模型:5000+ 个特征中的每个特征。
2) 在两个特征上训练 (5000+ -1) 个模型:第一个最佳特征和 ( 5000+ -1) 其余特征。找出第二个最佳特征。
3) 在 3 个特征上训练 (5000+ -2) 个模型:第 1 个、第 2 个最佳特征和 ( 5000+ -2) 其余特征。找出第三个最佳特征。
我通常在添加了 6-10 个特征后就不再改进模型了。您也可以增加到 10-20 个,或者您想增加多少特征就增加多少特征。
方法可以不同,但本质是一样的,缺点当然也是一样的,那就是计算成本太高。
但我认为,通过测试进行特征选择是将模型拟合到数据的测试部分。有一种变体是通过权重为 0.3 的 trayne 和权重为 0.7 的 test 进行选择。但我认为这也是一种拟合。
我想让阀门前移,这样拟合将针对许多测试部分,计算时间会更长,但在我看来这是最好的选择。
这就是为什么我在寻找功能内部的一些合理纹理,以证明其选择的合理性。到目前为止,我已经确定了事件重复发生的频率和类概率的移动。平均来说,效果是正面的,但这种方法实际上是通过第一次分割来评估的,没有考虑到相关的预测因素。但我认为您也应该尝试用同样的方法进行第二次分割,从样本中剔除具有强烈负面倾向的预测因子得分行。
虽然你没有自动运行 catbusters....5 万多次,但要手动重新训练模型以获得 10 个特征是很难的。
这大概就是为什么我更喜欢我的工艺而不是 catbust。尽管它的运行速度要比卡特布斯特慢 5-10 倍。你有一个模型需要 3 分钟来计算,而我有 22 个。
不过,请阅读我的文章....现在,一切都以半自动形式运行--生成任务并启动 bootnik(包括用于训练的特征数量任务,即您可以一次性生成所有变体并启动它们)。从本质上讲,有必要教终端运行 bat 文件(我认为这是可能的),并控制训练结束,然后分析结果,并根据结果运行另一个任务。
只有通过改变学习率,它才能从 100 个模型中获得两个符合设定标准的模型。
第一个模型
第二个。
事实证明,没错,CatBoost 可以做很多事情,但似乎有必要更积极地调整设置。
您是通过测试中的佼佼者来选择这些模型吗?
还是在一组测试中的佼佼者--考试中的佼佼者中选择?