混乱中有规律可循吗?让我们试着找出它!以特定样本为例进行机器学习。 - 页 29 1...2223242526272829303132 新评论 RomFil 2023.03.25 21:27 #281 Aleksey Vyazmikin #:嗯,这纯粹是你的系统,与我提供的数据无关,因为你没有使用任何其他数据进行分析,不是吗?我现在附上一个文件--请在上面应用您之前训练过的模型--我对结果很感兴趣。 PR=183856 +trades=693 -trades=18 点差=0,佣金=0。 RomFil 2023.03.25 21:29 #282 Aleksey Vyazmikin #: 这么说,你的遗传学对输入网络的数据负责?而数据本身就是时间序列偏差? 我已经写出了第一个问题的答案...:)没有偏差。 致敬,RomFil。 Aleksei Kuznetsov 2023.03.25 21:34 #283 RomFil #:此外,对于图形的不同部分,我们需要向神经网络输入不同深度的样本。也就是说,不同采样深度的神经网络在图形的不同部分具有不同的准确性。因此,"正确的 "委员会可以对整个采样长度做出正确的响应。尤其是这个委员会本身决定了这种正确性。或许,这已经是人工智能的雏形了......:) 我自己也对 5000、10000、20000、50000 行进行了训练和比较,每个人的交易方式不同,结果也不同。将它们结合在一起是一个有趣的想法。你会平均吗? 通常情况下,如果把不同的交易模型平均起来,它们会相互矛盾,只有当大多数模型都同意时,才会开始减少交易次数。 5-10 个模型如何能自行决定正确性?你是说平均吗? Aleksey Vyazmikin 2023.03.25 21:36 #284 RomFil #: PR=183856 +trades=693 -trades=18点差=0,佣金=0。 试着在这些数据上应用模型,我就不再折磨你了:) 附加的文件: New_data_v_3.zip 21 kb RomFil 2023.03.25 21:39 #285 Aleksey Vyazmikin #:嗯,这纯粹是你的系统,与我提供的数据无关,因为你没有使用任何其他数据进行分析,不是吗?我附上一个文件--请在上面应用您之前训练过的模型--我对结果很感兴趣。 事实证明,使用什么数据并不重要... 实际上,该算法形成的图 是这样的(由于已知原因,每次运行都会得到不同的图): Traine 对前 10000 个值进行采样,剩下的 2000 个值进行测试。 结果如下 PR=406206 +trades=299 -trades=34 故事到此结束。祝一切顺利,梦想成真。 罗姆菲尔 RomFil 2023.03.25 21:42 #286 Aleksey Vyazmikin #:再试着在这些数据上应用该模型,我就不再折磨你了:) PR=116823 +trades=977 -trades=16 Aleksey Vyazmikin 2023.03.25 21:47 #287 RomFil #:第一个问题的答案已经写好了......:)没有偏移。致:RomFil. 您自己写道:"是的,几乎是纯数值、不同深度、不同窗口 等"。 RomFil#: 结果是这样的PR=406206 +trades=299 -trades=34 图表上有 2000 个信号,但您在描述中却写了 333 个 - 或者我又不明白了.... 好吧,如果这是最后一个样本的图表,那么事实证明,在欧元兑美元上训练的模型在 3 种不同的货币工具(包括交叉盘)上都能完美运行。我想是时候颁发诺贝尔奖了! RomFil#: 故事到此结束。祝一切顺利,梦想成真。再见,RomFil。 感谢您带来了一个有趣的夜晚,祝您一切顺利! Aleksey Vyazmikin 2023.03.25 21:48 #288 RomFil #: PR=116823 +trades=977 -trades=16 震惊,震惊。 Aleksey Vyazmikin 2023.03.25 21:49 #289 RomFil #:实际上,这种算法生成的图形是这样的(由于众所周知的原因,每次发射都会得到不同的图形): 在随机图上进行训练? RomFil 2023.03.25 22:00 #290 Forester #: 我自己在 5、10、20 和 50k 线进行教学和比较,每个人的交易方式不同,结果也不同。将它们结合在一起是一个有趣的想法。你会平均吗? 通常情况下,如果您将交易模型平均化,它们会相互矛盾,只有当大多数模型达成一致时,才会开始减少交易次数。5-10 个模型如何能自行决定正确性?你是说平均吗? 你问对问题了:) 但我不会透露这个秘密。:)但我要说的是,委员会本身的输出决定了这个或那个网络的 "正确性"。没有平均数。 1...2223242526272829303132 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
嗯,这纯粹是你的系统,与我提供的数据无关,因为你没有使用任何其他数据进行分析,不是吗?
我现在附上一个文件--请在上面应用您之前训练过的模型--我对结果很感兴趣。
PR=183856 +trades=693 -trades=18
点差=0,佣金=0。
这么说,你的遗传学对输入网络的数据负责?而数据本身就是时间序列偏差?
我已经写出了第一个问题的答案...:)没有偏差。
致敬,RomFil。
此外,对于图形的不同部分,我们需要向神经网络输入不同深度的样本。也就是说,不同采样深度的神经网络在图形的不同部分具有不同的准确性。因此,"正确的 "委员会可以对整个采样长度做出正确的响应。尤其是这个委员会本身决定了这种正确性。或许,这已经是人工智能的雏形了......:)
我自己也对 5000、10000、20000、50000 行进行了训练和比较,每个人的交易方式不同,结果也不同。将它们结合在一起是一个有趣的想法。你会平均吗?
通常情况下,如果把不同的交易模型平均起来,它们会相互矛盾,只有当大多数模型都同意时,才会开始减少交易次数。
5-10 个模型如何能自行决定正确性?你是说平均吗?
PR=183856 +trades=693 -trades=18
点差=0,佣金=0。
试着在这些数据上应用模型,我就不再折磨你了:)
嗯,这纯粹是你的系统,与我提供的数据无关,因为你没有使用任何其他数据进行分析,不是吗?
我附上一个文件--请在上面应用您之前训练过的模型--我对结果很感兴趣。
事实证明,使用什么数据并不重要...
实际上,该算法形成的图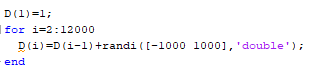 是这样的(由于已知原因,每次运行都会得到不同的图):
是这样的(由于已知原因,每次运行都会得到不同的图):
Traine 对前 10000 个值进行采样,剩下的 2000 个值进行测试。
结果如下
PR=406206 +trades=299 -trades=34
故事到此结束。祝一切顺利,梦想成真。
罗姆菲尔
再试着在这些数据上应用该模型,我就不再折磨你了:)
PR=116823 +trades=977 -trades=16
第一个问题的答案已经写好了......:)没有偏移。
致:RomFil.
您自己写道:"是的,几乎是纯数值、不同深度、不同窗口 等"。
结果是这样的
PR=406206 +trades=299 -trades=34
图表上有 2000 个信号,但您在描述中却写了 333 个 - 或者我又不明白了....
好吧,如果这是最后一个样本的图表,那么事实证明,在欧元兑美元上训练的模型在 3 种不同的货币工具(包括交叉盘)上都能完美运行。我想是时候颁发诺贝尔奖了!
故事到此结束。祝一切顺利,梦想成真。
再见,RomFil。
感谢您带来了一个有趣的夜晚,祝您一切顺利!
PR=116823 +trades=977 -trades=16
震惊,震惊。
实际上,这种算法生成的图形是这样的(由于众所周知的原因,每次发射都会得到不同的图形):
在随机图上进行训练?
我自己在 5、10、20 和 50k 线进行教学和比较,每个人的交易方式不同,结果也不同。将它们结合在一起是一个有趣的想法。你会平均吗?
通常情况下,如果您将交易模型平均化,它们会相互矛盾,只有当大多数模型达成一致时,才会开始减少交易次数。
5-10 个模型如何能自行决定正确性?你是说平均吗?
你问对问题了:)
但我不会透露这个秘密。:)但我要说的是,委员会本身的输出决定了这个或那个网络的 "正确性"。没有平均数。