交易中的机器学习:理论、模型、实践和算法交易 - 页 1258 1...125112521253125412551256125712581259126012611262126312641265...3399 新评论 [删除] 2019.01.16 15:41 #12571 elibrarius。大量的公式((嗯)有一个R包的链接。我自己不使用R,我了解这些公式。 如果你使用R,可以试试 ) Aleksei Kuznetsov 2019.01.16 16:09 #12572 马克西姆-德米特里耶夫斯基。嗯)有一个R包的链接。我自己不使用R,我了解这些公式。 如果你使用R,可以试试 )今天上午的文章仍然开放:https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71 最令人失望的事实是,我找不到这种算法的Python实现。作者创建了一个R包(BayesTrees),该包有一些明显的问题--主要是缺乏 "预测 "功能--另一个更广泛使用的实现,名为bartMachine。如果你有实现这一技术的经验,或者知道一个Python库,请在评论中留下链接所以第一套方案是没有用的,因为它不能预测。 第二个链接又有公式。 这里有一棵普通的树,很容易理解。一切都很简单,符合逻辑。而且没有公式。 Aleksei Kuznetsov 2019.01.16 17:09 #12573 马克西姆-德米特里耶夫斯基。也许我还没有接触到解放军。树只是一个巨大的贝叶斯主题的一个特例,例如,这里有很多书籍和视频的例子 我根据Vladimir的文章,用贝叶斯法优化NS的超参数。它的效果很好。 但是,如果有很多变量需要优化,那就太长了。 马克西姆-德米特里耶夫斯基。 像什么树......有贝叶斯的神经网络 出乎意料的是! NS使用数学运算+和*,可以在其内部构建从MA到数字滤波器 的任何指标。 但树是通过简单的if(x<v){left branch}else{right branch}分成左右两部分。 还是说如果(x<v){左分支}else{右分支}? [删除] 2019.01.16 17:16 #12574 elibrarius。 但如果有很多变量需要优化,那就会很漫长。 出乎意料的是! NS使用数学运算+和*,可以在里面构建任何指标--从MA到数字滤波器。 树通过简单的if(x<v){left branch}else{right branch}分为左右两部分。 或者说,白岩松NS也是if(x<v){左分支}else{右分支}?是的,很慢,所以从那里拉出有用的知识,到目前为止,对一些事情有了一个了解。 不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。 也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。但训练后的输出将不是一个点估计,而是每个样本的概率分布。 Кеша Рутов 2019.01.16 17:25 #12575 马克西姆-德米特里耶夫斯基。是的,很慢,所以从那里拉出有用的知识,到目前为止,对一些事情有了一个了解。 不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。 也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。但训练后的输出将不是一个点估计,而是每个样本的概率分布。你像速度一样到处跑,一件事,另一件事......而这是没有用的。 你似乎有很多空闲时间,像一些绅士一样,你需要工作,努力工作,争取职业发展,而不是急于从神经网络到基础知识。 相信我,在任何正常的经纪公司,没有人会因为科学的言语或文章而给你钱,只有被世界主要经纪人确认的股权。 Кеша Рутов 2019.01.16 17:31 #12576 马克西姆-德米特里耶夫斯基。我不急于求成,但我坚持从简单到复杂的学习。 如果你没有工作,我可以提供给你,比如说,用mql重写一些东西。我和大家一样为地主工作,你不工作很奇怪,你自己是地主,是继承人,是金主,一个正常人如果在街上3个月就失去了工作,6个月就死了。 Кеша Рутов 2019.01.16 17:34 #12577 马克西姆-德米特里耶夫斯基。如果交易中根本没有关于MO的内容,那就去走走吧,你会认为你是这里唯一的乞丐)我在IR中给他们都看了,说实话,没有幼稚的秘密,没有废话,测试中的误差是10-15%,但市场在不断变化,交易没有进行,喋喋不休接近零 Кеша Рутов 2019.01.16 17:36 #12578 马克西姆-德米特里耶夫斯基。总之,走开,瓦夏,我对抱怨不感兴趣。你所做的只是抱怨,没有结果,你在水中挖叉子,仅此而已,但你没有勇气承认你在浪费时间 你应该参军,或者至少在建筑工地上和男人一起做体力活,你会改善你的性格。 Aleksei Kuznetsov 2019.01.16 17:39 #12579 Maxim Dmitrievsky: 它很慢,这就是为什么到目前为止我从它身上拔出了一些有用的知识,它让人们了解了一些事情。不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。 是不是像例子中那样把贝叶斯曲线投射10个点,然后从这个曲线上取100或1000个点,用它们来教授NS/森林? 下面是来自https://www.mql5.com/ru/forum/226219 对Vladimir关于贝叶斯优化 的文章的评论,它是如何在多个点上绘制曲线的。但后来他们也不需要NS/森林了--你可以直接在这条曲线上寻找答案。另一个问题是--如果一个优化师不能学习,他就会教给NS一些难以理解的垃圾。 这里对于3个特征的贝叶斯工作 样本教学 Обсуждение статьи "Глубокие нейросети (Часть V). Байесовская оптимизация гиперпараметров DNN" 2018.01.31www.mql5.com Опубликована статья Глубокие нейросети (Часть V). Байесовская оптимизация гиперпараметров DNN: Автор: Vladimir Perervenko... Кеша Рутов 2019.01.16 17:42 #12580 马克西姆-德米特里耶夫斯基。是线程中的混蛋们让它变得毫无乐趣。 对自己发牢骚。有什么好谈的呢?你只是收集链接和不同的科学摘要来打动新人,桑桑尼茨在他的文章中已经写好了一切,没有什么可补充的,现在有不同的卖家和文章作者用干草叉抹去一切,让人感到羞愧和厌恶。他们自称为 "数学家",他们自称为 "量子"..... 想要数学尝试阅读这个http://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf。 而你不会明白你不是一个数学家,而是一个薄片。 1...125112521253125412551256125712581259126012611262126312641265...3399 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
大量的公式((
嗯)有一个R包的链接。我自己不使用R,我了解这些公式。
如果你使用R,可以试试 )
嗯)有一个R包的链接。我自己不使用R,我了解这些公式。
如果你使用R,可以试试 )
今天上午的文章仍然开放:https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
最令人失望的事实是,我找不到这种算法的Python实现。作者创建了一个R包(BayesTrees),该包有一些明显的问题--主要是缺乏 "预测 "功能--另一个更广泛使用的实现,名为bartMachine。
如果你有实现这一技术的经验,或者知道一个Python库,请在评论中留下链接
所以第一套方案是没有用的,因为它不能预测。
第二个链接又有公式。
这里有一棵普通的树,很容易理解。一切都很简单,符合逻辑。而且没有公式。
也许我还没有接触到解放军。树只是一个巨大的贝叶斯主题的一个特例,例如,这里有很多书籍和视频的例子
我根据Vladimir的文章,用贝叶斯法优化NS的超参数。它的效果很好。像什么树......有贝叶斯的神经网络
出乎意料的是!
NS使用数学运算+和*,可以在其内部构建从MA到数字滤波器 的任何指标。
但树是通过简单的if(x<v){left branch}else{right branch}分成左右两部分。
还是说如果(x<v){左分支}else{右分支}?
但如果有很多变量需要优化,那就会很漫长。
出乎意料的是!
NS使用数学运算+和*,可以在里面构建任何指标--从MA到数字滤波器。
树通过简单的if(x<v){left branch}else{right branch}分为左右两部分。
或者说,白岩松NS也是if(x<v){左分支}else{右分支}?
是的,很慢,所以从那里拉出有用的知识,到目前为止,对一些事情有了一个了解。
不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。
也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。但训练后的输出将不是一个点估计,而是每个样本的概率分布。
是的,很慢,所以从那里拉出有用的知识,到目前为止,对一些事情有了一个了解。
不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。
也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。但训练后的输出将不是一个点估计,而是每个样本的概率分布。
你像速度一样到处跑,一件事,另一件事......而这是没有用的。
你似乎有很多空闲时间,像一些绅士一样,你需要工作,努力工作,争取职业发展,而不是急于从神经网络到基础知识。
相信我,在任何正常的经纪公司,没有人会因为科学的言语或文章而给你钱,只有被世界主要经纪人确认的股权。我不急于求成,但我坚持从简单到复杂的学习。
如果你没有工作,我可以提供给你,比如说,用mql重写一些东西。
我和大家一样为地主工作,你不工作很奇怪,你自己是地主,是继承人,是金主,一个正常人如果在街上3个月就失去了工作,6个月就死了。
如果交易中根本没有关于MO的内容,那就去走走吧,你会认为你是这里唯一的乞丐)
我在IR中给他们都看了,说实话,没有幼稚的秘密,没有废话,测试中的误差是10-15%,但市场在不断变化,交易没有进行,喋喋不休接近零
总之,走开,瓦夏,我对抱怨不感兴趣。
你所做的只是抱怨,没有结果,你在水中挖叉子,仅此而已,但你没有勇气承认你在浪费时间
你应该参军,或者至少在建筑工地上和男人一起做体力活,你会改善你的性格。它很慢,这就是为什么到目前为止我从它身上拔出了一些有用的知识,它让人们了解了一些事情。
不,在贝叶斯NS中,只是通过对分布中的权重进行抽样优化,而输出也是一个包含一堆选择的分布,但有一个平均值、方差等。换句话说,它某种程度上捕捉了很多实际上不在训练数据集中的变体,但它们是先验的,是假设的。越多的样本被送入这样的NS,它就越接近于正常的收敛,也就是说,贝叶斯方法最初是用于不是很大的数据集。这是我目前所知的情况。
也就是说,这样的NS不需要非常大的数据集,结果会收敛到传统的数据集。
下面是来自https://www.mql5.com/ru/forum/226219 对Vladimir关于贝叶斯优化 的文章的评论,它是如何在多个点上绘制曲线的。但后来他们也不需要NS/森林了--你可以直接在这条曲线上寻找答案。
另一个问题是--如果一个优化师不能学习,他就会教给NS一些难以理解的垃圾。
 样本教学
样本教学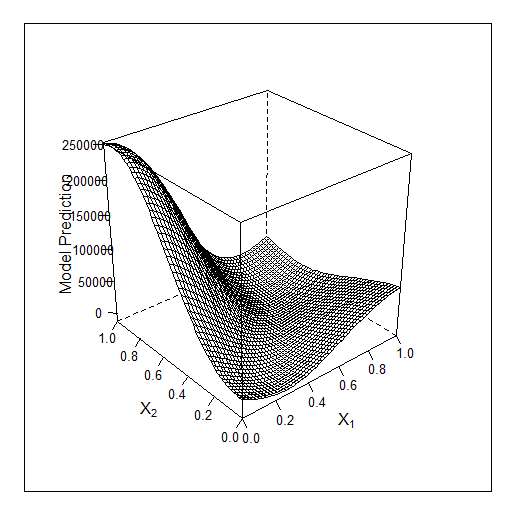
这里对于3个特征的贝叶斯工作
是线程中的混蛋们让它变得毫无乐趣。
对自己发牢骚。
有什么好谈的呢?你只是收集链接和不同的科学摘要来打动新人,桑桑尼茨在他的文章中已经写好了一切,没有什么可补充的,现在有不同的卖家和文章作者用干草叉抹去一切,让人感到羞愧和厌恶。他们自称为 "数学家",他们自称为 "量子".....
想要数学尝试阅读这个http://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf。
而你不会明白你不是一个数学家,而是一个薄片。