Обсуждение статьи "Ядерная оценка неизвестной плотности вероятности"
Автору. Еще лучше результаты получатся, если оценивать не плотность распределения, а функцию распределения, т.е интеграл плотности: во-первых, ее проще строить на данных, а поскольку она всегда неубывающая, да еще и ограничена между 0 и 1, то чувствительность к выбору сглаживающего алгоритма, будь то ядро, сплайн, регрессия или все что угодно, гораздо ниже. Требования к количеству имеющихся данных также снижаются, причем на порядок.
Ну, а плотность при необходимости можно легко получить численным дифференцированием.
Ну, а плотность при необходимости можно легко получить численным дифференцированием.
Может быть. Ничего не могу сказать по этому поводу. Оценивать pdf через cdf я даже не пытался. Скорее всего, сработало предубеждение, что использование дифференцирования потребует существенного увеличения точности оценки cdf. Кроме того мне до сих пор не попадалось никаких публикаций с оценками метода cdf->pdf или его сравнением с другими методами. Если поделитесь ссылками, буду признателен.
Первоначальная идея заключалась в том, чтобы при этом не использовать никаких внешних средств, то есть предполагалось, что все должно быть реализовано только средствами MQL5.
Это идея всех без исключения изобретателей велосипедов.
Посмотрите, что имеют в этом плане соответствующие пакеты и сравните с тем, что Вы предоставили - бесконечно малую величину того, что необходимо при применении в трейдинге матстатистики и эконометрики.
Может быть. Ничего не могу сказать по этому поводу. Оценивать pdf через cdf я даже не пытался. Скорее всего, сработало предубеждение, что использование дифференцирования потребует существенного увеличения точности оценки cdf. Кроме того мне до сих пор не попадалось никаких публикаций с оценками метода cdf->pdf или его сравнением с другими методами. Если поделитесь ссылками, буду признателен.
Ссылок дать не могу по причине их отсутствия у меня. Приведу вместо этого такие соображения.
При оценке непосредственно pdf мы вынуждены заранее разбивать область определения на интервалы, и тут нас подстерегают две неприятности: во-первых мы не знаем, на какое количество интервалов лучше разбивать область, а во-вторых - не знаем, какой тип сетки (равномерная, ... ?) подойдет лучше всего. И если второй вопрос люди еще как-то пытались решать, например, используя поквантильное разбиение, то по первому, на мой взгляд, универсальных методов нет вообще: все известные мне имеют ограничения, которые делают их малополезными в задачах автоматизации, когда мы не можем позволить себе метод тыка.
Этих недостатков лишена оценка cdf. В этом случае ступеньки функции располагаются именно там, куда попадают входные данные, а значит проблема выбора сетки для интерполянта отпадает сама собой. После того как сетка составлена, не составляет труда и подобрать количество интервалов: мы уже знаем максимальное их число (и расположение!!!), следовательно, путем прореживания можем задать любую требуемую точность, причем каждый раз на естественной сетке, наиболее хорошо соответствующей структуре входных данных.
На практике я использовал эту методику для поиска локальных мод эмпирических распределений при количестве отсчетов данных не более 100, при этом получал весьма гладкие результаты, причем визуально точность поиска определяется как вполне качественная, по крайней мере, 2-4 главные моды находятся практически без отклонений. Но алгоритм сглаживания я использую другой, ядерные мне не нравятся по ряду причин.
Все абсолютно справедливо. Но как мне кажется за исключением одного момента, на который Вы, по-видимому, просто не обратили внимания.
Хорошо известное выражение для ядерного сглаживания (Kernel smoother)
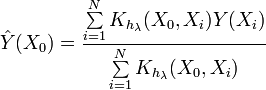
Основанный на таком сглаживании метод оценки pdf может выглядеть, например, следующим образом (упрощенно):
- Производим разбиение входной последовательности на интервалы (кластеризация, Binning)
- Полученную гистограмму сглаживаем.
Если не нравится ядерное сглаживание, то используем, например, p-spline. (Наверное, лучше сразу выбрать p-spline).
При таком подходе к оценке pdf все сказанное Вами оказывается абсолютно справедливым. Но даже в этом случае такой способ оценки для последовательностей большой длины (>1000000) дает прекрасные результаты. С уменьшением длинны входной последовательности все те прелести, о которых Вы упоминали, начинают проявляться все сильнее и сильнее.
Теперь посмотрим на выражение Ядерной оценки плотности (Kernel density estimation, KDE)
![]()
Это выражение отличается от приведенного ранее. Как видим, это выражение непосредственно определяет значение функции плотности вероятности в заданной точке. И что в данном случае важно, разбиения на интервалы не требуется. Используются непосредственно сами значения входной последовательности.
Во всяком случае, я именно так вижу ситуацию с KDE. Приведенный в статье алгоритм оценки pdf на первый взгляд неплохо справляется с последовательностями длиной 20-30 элементов. Иногда может возникнуть желание уменьшить степень сглаживания. Это легко сделать, заменив в коде
h=0.9*a/MathPow(N,0.2); // Silverman's rule of thumbна
h=0.7*a/MathPow(N,0.2); // Silverman's rule of thumb
Первоначальная идея заключалась в том, чтобы при этом не использовать никаких внешних средств, то есть предполагалось, что все должно быть реализовано только средствами MQL5.
Это идея всех без исключения изобретателей велосипедов.
Посмотрите, что имеют в этом плане соответствующие пакеты и сравните с тем, что Вы предоставили - бесконечно малую величину того, что необходимо при применении в трейдинге матстатистики и эконометрики.
Уважаемый Alex,
Вам легко рассуждать с высоты Вашего полета. Но задумайтесь на секунду над следующим:
Данный ресурс называется “www.mql5.com - Автоматический трейдинг и тестирование торговых стратегий”. Как видите, сайт называется mql5, а не EViews и даже не MQ, и не MT5. Поэтому легко предположить, что данный сайт в первую очередь ориентирован на популяризацию, отладку и развитие языка программирования MQL5. Что подтверждается наличием сервисдеска и размещением на сайте справочной информации по MQL5.
Если бы данный сайт назывался, например, “сборник торговых стратегий” и не принадлежал бы MQ. То в этом случае можно было бы ожидать появления на таком сайте публикаций с описанием решений на Exel, R, EVievs, Gauss, Stata и так далее.
Если бы я опубликовал данную статью на сайте EViews, то я бы может быть и попытался бы разобраться в сути вашего упрека. Но мы с Вами сейчас не на EViews.
На данный сайт заходят люди, имеющие совершенно различную подготовку. Это люди разного возраста имеющие разное образование и разные специальности. Мне кажется, большинство из них не имеют достаточного опыта работы с эконометрическими пакетами или вовсе не знакомы с таковыми. Вы считаете, что всех этих людей нужно прогнать с данного сайта, типа, пусть сначала выучат EViews?
Так как Вы сами публиковались, то Вы должны быть знакомы с процедурой публикации статей на данном сайте. Самостоятельно опубликовать какую угодно статью невозможно. Написанную статью можно только предложить для рассмотрения. Администрация сайта сама выбирает подходящие под их общую концепцию статьи. А в каких-то случаях администрация и самостоятельно заказывает статьи по интересующей их тематике. Как я уже говорил, у администрации имеется общая концепция и статистика по количеству обращений к той или иной публикации. В данной ситуации обращаться ко мне с претензиями по тематике статьи, считаю, не совсем правильно. Может быть, Вам следует обсудить эти вопросы с представителями MQ?
На данном сайте есть опубликованные статьи, которые для меня не интересны. Подчеркну, не плохие статьи, а просто для меня они не интересны. Я их обычно не читаю и не пишу к ним комментарии. Может быть, и Вам стоит выбрать для себя какую-нибудь подобную линию поведения? Хотя не смею давать советов, поступайте так, как Вам комфортнее.
Уважаемый Alex,
Вам легко рассуждать с высоты Вашего полета. Но задумайтесь на секунду над следующим:
Данный ресурс называется “www.mql5.com - Автоматический трейдинг и тестирование торговых стратегий”. Как видите, сайт называется mql5, а не EViews и даже не MQ, и не MT5. Поэтому легко предположить, что данный сайт в первую очередь ориентирован на популяризацию, отладку и развитие языка программирования MQL5. Что подтверждается наличием сервисдеска и размещением на сайте справочной информации по MQL5.
Если бы данный сайт назывался, например, “сборник торговых стратегий” и не принадлежал бы MQ. То в этом случае можно было бы ожидать появления на таком сайте публикаций с описанием решений на Exel, R, EVievs, Gauss, Stata и так далее.
Если бы я опубликовал данную статью на сайте EViews, то я бы может быть и попытался бы разобраться в сути вашего упрека. Но мы с Вами сейчас не на EViews.
На данный сайт заходят люди, имеющие совершенно различную подготовку. Это люди разного возраста имеющие разное образование и разные специальности. Мне кажется, большинство из них не имеют достаточного опыта работы с эконометрическими пакетами или вовсе не знакомы с таковыми. Вы считаете, что всех этих людей нужно прогнать с данного сайта, типа, пусть сначала выучат EViews?
Так как Вы сами публиковались, то Вы должны быть знакомы с процедурой публикации статей на данном сайте. Самостоятельно опубликовать какую угодно статью невозможно. Написанную статью можно только предложить для рассмотрения. Администрация сайта сама выбирает подходящие под их общую концепцию статьи. А в каких-то случаях администрация и самостоятельно заказывает статьи по интересующей их тематике. Как я уже говорил, у администрации имеется общая концепция и статистика по количеству обращений к той или иной публикации. В данной ситуации обращаться ко мне с претензиями по тематике статьи, считаю, не совсем правильно. Может быть, Вам следует обсудить эти вопросы с представителями MQ?
На данном сайте есть опубликованные статьи, которые для меня не интересны. Подчеркну, не плохие статьи, а просто для меня они не интересны. Я их обычно не читаю и не пишу к ним комментарии. Может быть, и Вам стоит выбрать для себя какую-нибудь подобную линию поведения? Хотя не смею давать советов, поступайте так, как Вам комфортнее.
Принять Ваш ответ я не могу, так как он совершенно не по существу моего поста. Постараюсь пояснить свою точку зрения.
1. Метаквоты вообще не при чем - они предоставили очень приличный инструмент и им занимаются.
2. Каких-либо ограничений на тематику статей мне не известно. Конечно, в пределах трейдинга. На данном сайте вообще имеется раздел "Статистика", т.е. они понимают тематику сайта гораздо шире Вас в полном соответствии с содержанием и проблематикой трейдинга. Не будем ссылаться на Метаквотов и перейдем к существу.
3. Мой пост не о том ЧТО развивать, а КАК развивать. Для меня именно это является принципиальным в связи с Вашей статьей. Я не агитировал за EViews, о котором у меня низкое мнение - его хорошо применять в демонстрационных целях и целях обучения, торговать на нем, по-моему нельзя. Моя ссылка на пакеты для демонстрации ширины проблемы.
4. Я давно в программировании. 40 лет назад появились первые библиотеки программ и сразу же, 40 лет назад, критиковали любителей повторно написать какую-либо программу из существующего пакета. Не Вы первый. Но этом сайте полно любителей еще раз построить велосипед - отсюда моя гипертрофированная реакция.
5. Вопрос ядерной оценки - жеванный и пережеванный. И если бы Вы взяли чужую библиотеку, то у Вас бы появилась возможность приподняться над техническими сложностями, которые Вы решили в своей статье и, возможно, предложить решение вопросов, поднятых практиком alsu, или вспомнить, что визуальная оценка распределений играет очень важную роль при их формальной оценке, или расширить функционально и т.д. - в любом случае Вы бы были на ступеньку выше.
У меня не было желания высказать что-либо обидное в Ваш адрес. Ваша статья и разработка вызывает уважение, но я не могу согласиться с методической направленностью техники реализации Ваших идей.
Мой пост на Вашу статью продиктован надеждой, что кто-либо системно дополнит терминал Метаквотов средствами статистики и эконометрики. Вас я отношу именно к таким людям.
Чрезвычайно интересно. Просто очень.
А пожелания принимаете?
Желателен не просто открытый код, а код, ориентированный на статистику. Прошу обратить внимание на R.
Чрезвычайно интересно. Просто очень.
А пожелания принимаете?
Желателен не просто открытый код, а код, ориентированный на статистику. Прошу обратить внимание на R.
Пожелания принимаются вот здесь: https://www.mql5.com/ru/forum/6505. Пишите всё, что Вы желаете. :)
- www.mql5.com
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Ядерная оценка неизвестной плотности вероятности:
Автор: Victor