Мы запускаем облачный сервис MQL5 Cloud Network! - страница 183
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Нет рикаких проблем с рейтингом PR, так как он на 100% коррелирует с мощностью CPU.
Тогда как объяснить результаты оптимизации и рейтинг
Форум по трейдингу, автоматическим торговым системам и тестированию торговых стратегий
Хочу собрать ПК для работы с МТ 5, что посоветуете и почему?
Aleksey Vyazmikin, 2019.03.28 13:02
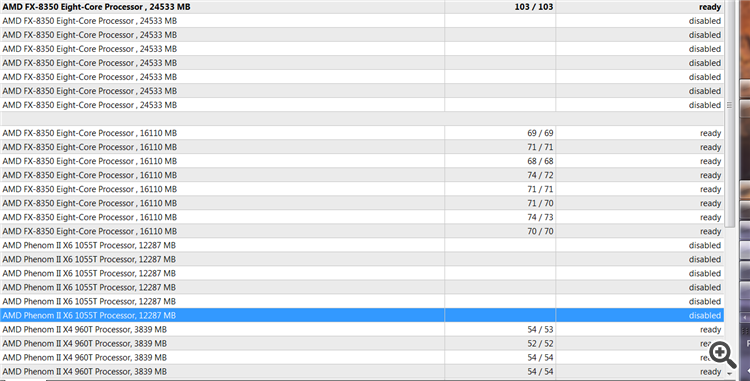
А вот результаты оптимизации, дабы оценить реальную разницу в производительности
Видно, что базовый мой ПК FX-8350, который PR 101 получил, на 20-25% быстрей, чем другой FX-8350, который получил рейтинг PR125.
В то же время Phenom II 960T медленней уже на 35% при лучшем PR рейтинге 119.
Время на оптимизацию ушло 1 час 23 минуты, это что бы не смущало число проходов, просто в каждом проходе по 1000 фреймов - режим Математические вычисления. Агенты запустились почти синхронно, ну максимум 0,3 прохода разницы.
От этого PR рейтинга зависит, в общем то доход и расход пользователей клауд, поэтому хотелось бы получить действительно комментарии @Renat Fatkhullin .
Тогда как объяснить результаты оптимизации и рейтинг
При таком малом количестве проходов нельзя такие грязные выводы делать.
Добавил проходов для объективности - картина не изменилась
Если тест не правильный, то дайте правильный тест, а то появляются сомнения в справедливой оценки, а значит и в размере оплаты услуги и вознаграждении.Добавил проходов для объективности - картина не изменилась
Если тест не правильный, то дайте правильный тест, а то появляются сомнения в справедливой оценки, а значит и в размере оплаты услуги и вознагражденииЕсть мысль, что локальная машина имеет преимущество, так как ее время не тратится на прием передачу заданий. Запустите тест на втором компе. Потом можно уже можно будет что то оспаривать
Есть мысль, что локальная машина имеет преимущество, так как ее время не тратится на прием передачу заданий. Запустите тест на втором компе. Потом можно уже можно будет что то оспаривать
Вы точно уверены, что хотите заявить о сверх плохой работе агентов с трафиком?
И в таком состоянии может висеть часами
А в чём проблемма, что нельзя использовать впс агентов в качестве не для продажи а локальных сетевых агентов?
Ранее вроде так и было ведь?