Что подать на вход нейросети? Ваши идеи... - страница 80
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Образцы, каждый количеством n чисел, подаваемые на входы X[0 ... n-1] в процессе обучения, должны быть предварительно подготовлены (нормированы) таким образом, чтобы они были РАВНОСИЛЬНЫ между собой, при прочих равных условиях.
В контексте того, что значение Y на выходе мат.нейрона это сумма X[0]*W[0] + X[1]*W[1] + X[2]*W[2] + ... + X[n-1]*W[n-1], такой равносильности можно достичь только одним способом :
Суммы значений |X[0]| + |X[1]| + |X[2]| + ... + |X[n-1]| у всех обучающих образцов должны быть одинаковы.
Где в качестве "прочего равного условия" принимается W[n] равное X[n].
То есть, уже с учётом "прочего равного условия", два образца являются численно равносильными, если их суммы X[0]^2 + X[1]^2 + X[2]^2 + ... + X[n-1]^2 одинаковы.
Например :
Если в качестве пакета обучающих образцов используются некие участки цены по её приращениям X[n][k]=close[n][k]-open[n][k], где n это номер значения X, а k это номер образца,
то сумма значений |X[0][k]| + |X[1][k]| + |X[2][k]| + ... + |X[n-1][k]| означает длину пути кривой проделанной ценой в пределах данного образца k.
То есть, обучающие образцы k должны быть предварительно нормированы друг к другу, в физическом смысле данного примера, буквально по их длине пути кривой цены.
И вот уже теперь можно (и нужно) выполнить для них ещё одну нормировку, под диапазон не менее / не более -+1, путём деления всех X[n][k] на max, где max это максимальное |X[n][k]| найденное из всех X[n][k].
А уже потом, в процессе обучения, эти нормированные образцы X[0 ... n-1][k] подаются как обучающие примеры, каждый имеющий собственную оценку d[k], которая и определяет вклад данного образца в совокупный результат обучения.
Опять же :
Полагаю, что обучение следует выполнять не всеми имеющимися образцами k, а только такими, которые имеют "достойную" (употреблю такое слово) оценку d[k].
Однако, чтобы сделать выборку "достойных", всё равно надо иметь на руках все образцы k с их оценками d[k].
Впрочем, это уже другая тема ...
Интересно пишете
Вот в этом месте диссонанс с теорией проблемных чисел:
Ведь прописать "силу" паттерну - это равносильно найти грааль, грубо говоря. Там и НС не требуется, просто бери паттерны с самым высоким силовым (числовым) показателем, ссоединяй с другим подобным паттерном - и открывай позицию, ведь по такой логике вероятность выигрыша якобы выше.
Поэтому и появилось желание уйти от чисел, либо найти метод, который как-то объективно (максимально возможно объективно) придавал бы некую силу паттерну, который в каком-то контексте (смеси с другими паттернами) давали высокую вероятность отработки.
Тогда есть смысл предобработки.
Проблема чисел.
...
...
Образцы, каждый количеством n чисел, подаваемые на входы X[0 ... n-1] в процессе обучения, должны быть предварительно подготовлены (нормированы) таким образом, чтобы они были РАВНОСИЛЬНЫ между собой, при прочих равных условиях.
...
Опять же :
Полагаю, что обучение следует выполнять не всеми имеющимися образцами k, а только такими, которые имеют "достойную" (употреблю такое слово) оценку d[k].
Однако, чтобы сделать выборку "достойных", всё равно надо иметь на руках все образцы k с их оценками d[k].
...
Один из вариантов (просто пример), как оформить информацию на графике в какое-то немусроное число (наделив его соответсвенно неким объективным силовым фактором относительно другой графической информации), это уровни поддержки и сопротивления. Допустим, они формализованы. И от них цена отскакивает или пробивает. Закрепляется за ними или игнорирует.
В таком случае числами, обозначающими каждую последовательную цену на графике - будет тоже самое окно МинМакс, только максимальным значением будет этот самый уровень С/П. Если цена возле него - то 0.9 (-0.9) и ближе к 1-це. Если далеко от него, то ближе к 0.
Если одна цена с одной сторны уровня, а другая с другой, — то меняем полярность каждой стороны: на одной стороне ближе к уровню - это минусовые максимизации, а с другой стороны - положительные числовые максимизации.
Это лишь набросок, пример того, какие должны быть числа. Не просто положение относительно других чисел в окне, а именно некое отражение какого-то рыночного контекста.
Другой вариант: выражаем паттерны через числа. И вот у нас свечной паттерн А из одной свечи, после которого цена 55 раз из 100 на истории идёт вверх. Следующего за ним паттерна АБ (свечной комбинации уже из 2-х свечей) на истории отработка 48 вверх и 52 вниз. Третья свечная комбинация АВС (комбинация уже из трех свечей) отрабатывает 53 вверх и 47 вниз.
И вот у нас у одного паттерна исторический перевес вверх, у другого перевес вниз, у третьего вверх: 5, -1, 3.
Соединяем в окно, нормируем в диапазон -1..1 и у нас на вход НС пойдут числа: 1, -1 и 0.4286.
Это пример того, что количественный фактор, являясь решающим для математической НС, несёт в себе объективную информацию о рынке и задача НС - выбрать, что из этой объективной информации может быть полезно для стабильной торговли.
А не судорожно вычленять что-то из абсолютного мусора, коим являются среднестатистический числовой сет на вход НС.
L1, L2 нормализации. (регуляризации) описаны. Обычно уже встроены в МО.
Если мусора значительно больше, чем хороших примеров (что храктерно для типичного датасета на форексе), то никакой подход не поможет.
Обязательно
Я же описывал теорию: смысл НС - фильтровать грубые ТС-ки, которые что-то показывают. А не искать грааль.
И подход описал: вручную ищешь любую ТС, которая хоть немного показывает результаты.
И фильтруешь её НС-кой.
Вот оригинал ТС
Непригодная к торговле, но проявляющая признаки жизни.
А вот она же, только отфильтрованная питоновской НС: LSTM-кой
Если в реале не показывает, а взято из тестера, то все равно оверфит ведь.
А вот как себя показывает свёртка (CNN)
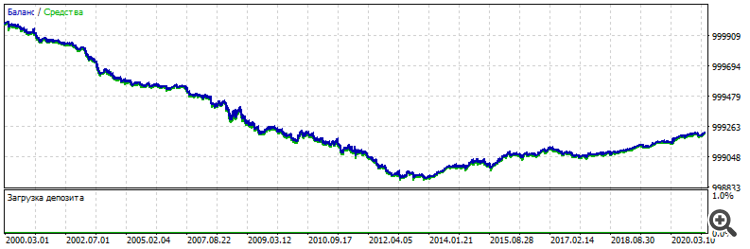
Бектест оригинальной грубой простой ТС:
2000-2021
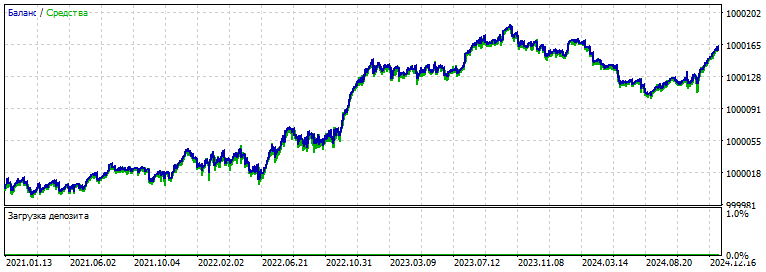
Её форвард
Метод работы:
— ищем какую-то ТС, проверяем её на форварде: должна хотя бы не сливать. Субъективно оцениваем её работу.
— перед открытием позиции записываем информацию с графика (эксперементально - любую) - во входной сет. (Я это делал скриптом)
— результат сделки записываем в целевую для ранее записанного входного сета.
— проходим по всему обучаемому периоду.
— подаём в НС и обучаем её
— добавляем в условие открытия позиции "if (.... && out > Open_level)"
— оптимизируем в МТ5: крутим-вертим реле порога (единственный параметр для оптимизации в оптимизаторе тестера МТ5)
— выбираем понравившийся сет, например ниже - тот же график, что и первый сверху, только "отфильтрованный" НС
— проверяем форвард 2021-2025
Для сравнение BiLSTM (предыдущая попытка)
На вход: 1000 (!) нормированных цен.
(Меня всё грезит идея сформулировать и оформить рыночный контекст для НС. И первое, что в нём должно быть: это очень много единиц информации. )
Выше был простой метод эксплуатации НС, пока мы не придумали, как её научить искать ТС самостоятельно.
Походу придётся окунуться в раздел МО про обучение без учителя, датамайнинг и так далее. Истина зарыта где-то там.
Замечания по НС: переобучение — 99% работы. То есть, чтобы прийти к такому результату (выше), пришлось просидеть полдня, настраивая архитектуру. Вошлебной палочки по настройкам гиперпараметров нет. А способов "подкрутить" что-то - десятки и сотни, всё не выучить.
Но в процессе ковыряния примерно понимаешь или чувствуешь вектор направления мысли. Куда-чё тыкнуть, и что сварганить.
На текущий момент, оглядываясь на все многолетние потуги с этими сетями, одно могу сказать точно: не хватает функционала по отбору моделей.
1) Инициализируем веса случайным образом. Ок.
2) Запускается обучение и тут самое интересное:
3) Каждый сет весов должен проверяться на форварде по заданным пользователем критериям: например, по фактору восстановления.
4) Как только форвард улучшился - автозапись (автосохранение) модели с выводом графика прибыли на экран. Все сохранённые графики должны быть на виду и прлистываться, чтобы параллельно пользователь мог просматривать прогресс.
5) На следующей итерации если модель ухудшилась (началось переобучение или просто неудачный сет весов) - возвращаемся к предыдущей модели и меняем Learning rate. Продолжаем до тех пор, пока показатели не улучшатся.
6) Если показатели не улучшились или пользователю не нравится вектор прогресса результатов обучения - прерываем обучение и начинаем его заного с новой инициализацией весов.
7) Этот основной процесс как-то допиливаем дополнительным функционалом по требованию: например, внедряем автодобавление нейронов при новом обучении, слоёв, меняем как-то функции активации или функции потерь, функцции оптимизации (Адам на БФГ+моментум и прочие), и прочее и прочее.
То есть, создаём максимально полезную поисковую машину по поиску рабочей модели.
А не делаем всё это добро руками.
Пространство весов — это такая карта космоса, в которой бесконечное количество белых точек. С каждым новым весом количество возможных комбинаций результатов перемножения на таких же бесконечных комбинаций входных чисел переваливает за отметку количества звёзд на небе.
Каждая инициализация - это точка на этой карте, точка бесконечно малого размера. А обучение - это поход к соседним точкам. Если данный кластер точек находится далеко от "граального", то лучше сразу его вырубить и начать обучение заново. Новая инициализация весов - это другая, рандомная точка на этой огромной карте. И новое обученеие - это новое "прощупывание" пространства вокруг.
Идеальная формула (метод) нахождения необходимого сета для НС (как-то анализируя эту карту) - это что-то из раздела фантастики. И как пища к размышлению, как решить или как обойти эти количественные ограничения.
И постоянная переинициализация с новым запуском обучения - это как минимум самый простейший и доступный метод приблизиться к лучшей настройки нейросети.
На текущий момент, оглядываясь на все многолетние потуги с этими сетями, одно могу сказать точно: не хватает функционала по отбору моделей.
Ну да, это следующая ступенька проблемы - потом дрейф данных и критерий остановки ТС.
L1, L2 нормализации. (регуляризации) описаны. Обычно уже встроены в МО.
Ничем не отличается от беспочвенного наделения старых рандомных силовых значений - новыми рандомными силовыми значениями (лишь бы там что-то сводилось у нс-ки).
Ну да, это следующая ступенька проблемы - потом дрейф данных и критерий остановки ТС.
То есть, решение первостепенной проблемы решит по сути и второстепенную.
Математический метод тут только работает,то есть фильтрация входных значений по приоритету при этом без изменений самих значений и их количества.Две синхронные модели должны быть,одна фильтр вторая предсказатель.От того ,что вы эти шумы бесконечно гоняете толку никогда не добьётесь.Скармиливать в этот метод нужно всё,что только возможно и по больше.Без понятия как это правильно собрать в реализации но то ,что информация точная даже не обсуждается.Верить этому или нет дело ваше